爬取代码: lg.py ...import scrapy from sjqx.items import SjqxItem class Sjqxpider(scrapy.Spider): name = 'lg' allowed_domains = ['www.lagou.com'] base_url = 'https://www.lagou.com/beij..
”Scrapy%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD%EF%BF%BD“ 的搜索结果
1. Scrapy 的 Xpath 简介 (1)使用xpath查找HTML中的元素 2. Xpath 查找 html 元素 (2)"//"与"/"的使用 (3)使用"."进行Xpath连续调用 (4)extract与extract_first函数使用 (5)获取元素属性值 (6)获取节点...
bd:在百度上抓取名人图片
标签: Python
bd爬取百度图库上的名人图片... 在 bd/settings.py 的 PeopleNames 中设置名人txt文件路径,在 bd/settings.py 的 Pages 中选择爬取的页数Crawl$ scrapy crawl BaiduStoppingCtrl+C 来停止爬取,可能要等一会才会停止
目录 一、什么是Ajax 二、Ajax的来由 三、Ajax如何分析页面 四、案例(基于Ajax和requests的的微博采集器) 五、selenium的使用 ...Ajax(Asynchronous JavaScript and XML)异步的JS和XML。原理是: 利用JS在保证...
文章目录1. unicode二进制转UTF-8字符 1. unicode二进制转UTF-8字符 当我们爬虫`print(response.body)时,会出现无法阅读的字符,如下图所示: 从图中可以看出打印出来的字符内容为b'......'二进制这种格式的内容,...
使用Scrapy框架开发爬取中国知网专利信息的爬虫,可以提供以下500字的说明: Scrapy是一个功能强大、高效的Python网络爬虫框架,非常适合用于爬取中国知网这样的专业学术资源网站。利用Scrapy可以快速开发一个高质量的...
scrapy startproject tutorialscrapy crawl dmoz -o dmoz.jsonscrapy crawl dmoz -o dmoz.jlscrapy crawl dmoz -o dmoz.csv----------------------------------------------------------------------scrapy shell "h...
诊断篇已经讲了(链接在上面),如何分析出自己的scrapy出了什么问题!一般来说,如果不是网络ip问题,大部分都是内存泄漏问题~而在内存泄漏里面,普遍的现象就是request和item的处理,在一开始就出现了设计问题;本章,就来讲...
第一种:pip install scrapy。直接报错! 第二种:半天都没有下载好! 网上寻找解决办法: 下载所需模块的.whl文件,然后再以pip的形式安装 常用模块whl文件得下载地址:https://www.lfd.uci.edu/~gohlke/python...
【图片来源于网络,如果侵权请联系我删除】将当前页面所有符合我们要求的链接提取出来。基本操作与之前类似,在这里不过多叙述。链接提取器【crawlspider】爬取读书网【多页面爬取】直接上代码【电影天堂】pipelines...
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片。 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存储起来。也是就是我们项目...
Scrapy 是采用Python 开发的一个快速可扩展的抓取WEB 站点内容的爬虫框架。Scrapy,Python开发的一个快速,高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于...
{"_meta": {"hash": {"sha256": "a3da9e690730187f1f586c462e29b83d551a33e3fa7185718aac30c04a687b53"},"pipfile-spec": 6,"requires": {"python_version": "3.6"},"sources": [{"name": "pypi","url": ...
关键词:Scrapy spider pipeline xpath 参考文档 Scrapy 0.24中文版官方文档(PDF格式) csdn下载 Xpath教程 W3school-XPath 目标:将亚马逊的上的手机信息爬取下来,包括价格、描述信息、URL 。 新建一个项目:...
1. Cookie原理HTTP是无状态的面向连接的协议, 为了保持连接状态, 引入了Cookie机制Cookie是http消息头中的一种属性,包括:Cookie名字(Name)Cookie的值(Value)Cookie的过期时间(Expires/Max-Age)Cookie作用...

首先要安装Python环境,Python环境搭建见:... 接下来讲如何搭建Scrapy环境 1、安装Scrapy,在终端使用pip install Scrapy(注意最好是国外的环境) 进度提示如下: alicedeMacBook-Pro:~ alice$ pip install S...
一,创建项目:scrapy startproject 项目名称 》cd 项目目录 手动或者命令(scrapy genspider 爬虫名称 域名)创建spider文件 tree结构图如下:│ main.py│ scrapy.cfg│ __init__.py│├─zhilian│ │ ...
文章目录下载文件与图片(一)FilesPipeline 和 ImagesPipeline1. FilesPipeline 使用说明2. ImagesPipeline 使用说明(二)项目实例:下载 matplotlib 例子源码文件1. 页面分析2. 编码实现(1)创建项目文件(2)...
内容:详情岗位url + 岗位详情信息 + Excel文件和Mysql数据存储 bugger:拉勾网反爬虫能力强,无法持续爬取。由于没有使用IP池,爬取20个左右岗位,则不能爬取。 作者:Irain QQ:2573396010 微信:18802080892 ...
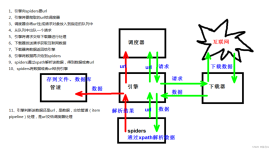
01. Scrapy 链接 https://scrapy-chs.readthedocs.io/zh_CN/1.0/intro/overview.html 02. Scrapy 的爬虫流程 Scrapy Engine(引擎) 总指挥: 负责数据和信号的在不同模块之间的传递(Scrapy已经实现) ...
下载方式 根据你的操作系统下载不同的 BiliDrive 二进制。 执行: bilidrive download <link> 链接 文档 链接 Webpack 中文指南.epub (409.01 KB) ...OpenIntro Statistics 3e.pdf (...
首先安装scrapy是没问题的,但是当导入模块时就报错了,具体如下: root@ubuntu:/usr/bin# pip3 install scrapy Collecting scrapy Downloading ...
在前面的章节中都介绍了scrapy如何爬取网页数据,今天介绍下如何爬取图片。 下载图片需要用到ImagesPipeline这个类,首先介绍下工作流程: 1 首先需要在一个爬虫中,获取到图片的url并存储起来。也是就是我们项目...
C:\WINDOWS\system32&...pip install scrapy Collecting scrapy Downloading https://files.pythonhosted.org/packages/5d/12/a6197eaf97385e96fd8ec56627749a6229a9b3178ad73866a0b1fb377379/Scrapy-1.5.1-py2....
scrapy安装 在windows下,在dos中运行pip install Scrapy报错 采用pip安装,安装时可能会出现安装错误Microsoft Visual C++ 14.0 is required, 解决方案 http://www.lfd.uci.edu/~gohlke/pythonlibs/#...
安装scrapy报错 win10 pycharm virtualenvpython3.5 (env) C:\Users\lg\PycharmProjects\untitled>pip3 install scrapy You are using pip version 7.1.0, however version 18.0 ...
一不小心把Linux服务器...刚开始一起正常,在使用pip install安装scrapy的时候遇到了经常出现的问题: Collecting Twisted&gt;=13.3.0 (from scrapy) Could not find a version that satisfies the requirem...
推荐文章
- 【解决报错】java.sql.SQLException: Access denied for user 'root'@'localhost' (using password: YES)-程序员宅基地
- echart y轴显示小数或整数_echarts y轴显示16位小数-程序员宅基地
- Android客户端和Internet的交互_android与internet-程序员宅基地
- linux新建分区步骤_linux创建基本分区的步骤-程序员宅基地
- 信号处理-小波变换4-DWT离散小波变换概念及离散小波变换实现滤波_dwt离散小波变换进行滤波-程序员宅基地
- Ubuntu 10.10中成功安装ns-allinone-2.34_进入/home/ubuntu1/ns-allinone-2.34目录cd /home/ubuntu1-程序员宅基地
- 使用AES算法对字符串进行加解密_java 判断aes加密 与否-程序员宅基地
- DFS深度优先搜索(前序、中序、后序遍历)非递归标准模板_深度优先搜索 无递归-程序员宅基地
- 程序员面试字节跳动,被怼了~_字节跳动java什么技术站-程序员宅基地
- 嵌入式软考备考(五)安全性基础知识-程序员宅基地