”Python爬虫“ 的搜索结果
Python爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdfPython爬虫总结材料.pdf
精品基于Python的智能家居环境感知的设计与可视化-爬虫[包运行成功精品基于python的旅游导览系统-爬虫-可视化大屏[包运行成功+免费答疑
Python爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学提纲.pdfPython爬虫总结教学...
上七月算法 Python爬虫班 第一课示例代码
爬虫去爬取网站数据的数据的时候,如果单位时间内爬取频次过高,或者其他的原因,被对方识别出来,ip可能会被封禁。这种情况下,通过使用代理ip来解决,作为反爬的策略。 代理ip匿名度: 透明的: 服务器知道了你...
98 Internet Application 互联网 + 应用 引言:如今,大数据已经进入我们的各个领域,我们的工作及应用越来越需要获取大量的数据。我们可以想象在一张蜘蛛网上沿着我们所需的方向...爬虫,应该称为网络爬虫,也叫...
爬虫遇到验证码的问题,如何完善代码,以及遇到的问题
python京东评论爬虫
Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。利用Beautiful Soup可以对网页进行解析,提取所有的超链接。Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。...
爬虫指的是一种自动化程序,能够模拟人类在互联网上的浏览行为,自动从互联网上抓取、预处理并保存所需要的信息。爬虫运行的过程一般是先制定规则(如指定要抓取的网址、要抓取的信息的类型等),紧接着获取该网址的...
这是一份同学的爬虫的毕业论文,完整的。需要的赶紧拿走
Python爬虫数据入库
标签: 大数据
本篇 Python 爬虫教程主要讲解以下5部分内容,请按照顺序进行学习。 1. 爬虫概述:介绍什么是爬虫,爬虫的目的和应用。 2. 爬虫基础知识:介绍爬虫的基本概念,例如网络协议,HTML 结构,CSS 样式表等。 3. Python ...
基于Python的网络爬虫摘要随着计算机技术的不断发展,新的编程语言层出不穷,Python,Html正是其中的佼佼者。相比较早期普及的高级语言(Java,C语言)等,Python有着更加实用的模块和库,虽然牺牲了底层性,但却更加...
本文介绍了5个常见的Python爬虫框架,并分析了它们的优缺点。每个框架都有其独特的特点,可以根据具体的需求选择合适的框架。需要注意的是,不同的框架适用的场景不同,选择框架时需要充分考虑数据的规模爬虫的性能...
实现对豆瓣电影网站的所有电影爬取的爬虫实例,
在使用python爬虫进行网络页面爬取的过程中,第一步肯定是要爬取url,若是面对网页中很多url,,又该如何爬取所以url呢?本文介绍Python爬虫爬取网页中所有的url的三种实现方法:1、使用BeautifulSoup快速提取所有...
你可以使用Python中的pandas库将爬虫数据保存为Excel文件。以下是一些示例代码,可以帮助你完成这项任务: import pandas as pd # 创建DataFrame,存储你的爬虫数据 data = {'Name': ['Alice', 'Bob', 'Charlie'], ...

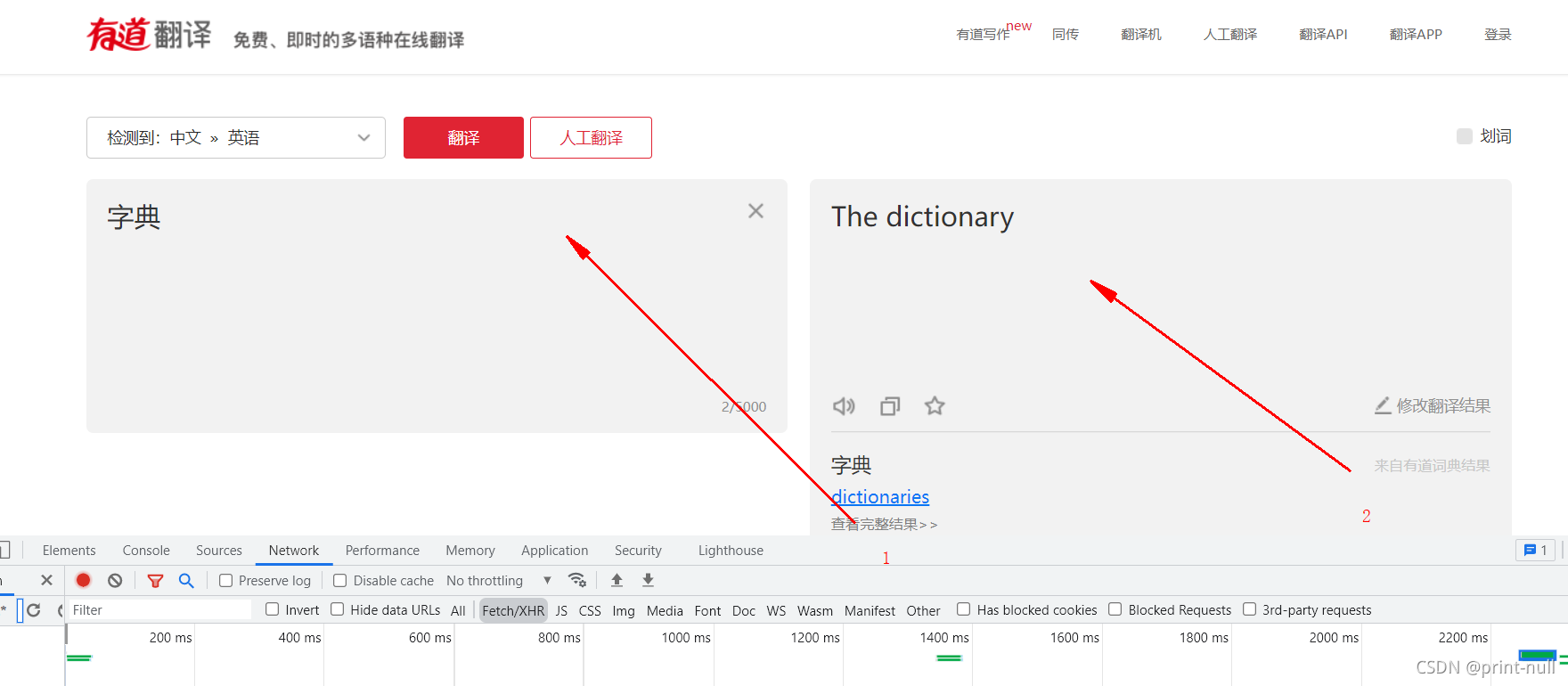
1. 首先第一步我们先找到自己抓取的网站网址以及内容 在这里我使用的是https://m.douban.com/group/729027/ 抓取的内容是这个网页下的: 所有的讨论 ...使用F12对当前页面进行解析: ... div:nt...
使用requests爬虫就会失败,所以得使用httpx包 import httpx client = httpx.Client(http2=True) # 之后的使用方式和requests一样 # post result = client.post(url,json=data, headers=headers, cookies=cookies )...

python爬虫——https请求 from urllib.request import Request,urlopen from fake_useragent import UserAgent import ssl url = "https://www.12306.cn/index/" headers = { "User-Agent":UserAgent().random } ...
推荐文章
- SMT的基本知识介绍_smt行业基础知识-程序员宅基地
- 43.基于SSM的口腔护理网站|基于SSM框架+ Mysql+Java设计与实现(可运行源码+数据库+lw)-程序员宅基地
- HTML中Table表格的使用与漂亮的表格模板_html table 样式-程序员宅基地
- Linkage Mapper中的局部和全局地图比较实践指南(含实例分析)-程序员宅基地
- 线性筛求欧拉函数-程序员宅基地
- 初中几何题_初中几何题解-程序员宅基地
- jQuery 放大镜效果_jquery放大效果-程序员宅基地
- Python构建快速高效的中文文字识别OCR_中文ocr python-程序员宅基地
- SQL语句用case when实现if-else条件逻辑_case when里面可以加if else吗-程序员宅基地
- 数据结构实验课程设计报告求工程的最短完成时间_(1)用字符文件提供数据建立aoe网络邻接表存储结构; (2)编写程序,实现图中顶点的-程序员宅基地