Spark是什么Apache Spark是用于。
”Pyspark“ 的搜索结果

一、安装 PySpark 1、使用 pip 安装 PySpark 2、国内代理镜像 3、PyCharm 中安装 PySpark 二、PySpark 数据处理步骤 三、构建 PySpark 执行环境入口对象 四、代码示例
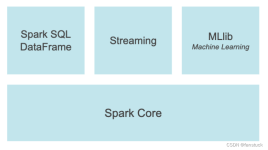
pyspark基础知识学习第一篇,介绍了spark的基础概念以及PySpark的环境搭建,包括local,standAlone以及spark on yarn

一、PySpark 简介 1、Apache Spark 简介 2、Spark 的 Python 语言版本 PySpark 3、PySpark 应用场景 4、Python 语言使用场景
在现代信息时代,数据是最宝贵的财富之一,如何处理和分析这些数据...而pyspark作为一个强大的分布式计算框架,为大数据处理提供了一种高效的解决方案。本文将详细介绍pyspark的基本概念和使用方法,并给出实际案例。
PySpark有关PySpark / Spark的一些信息: PySpark是适用于Spark的Python API Spark不是一种编程语言PySpark允许您编写在分布式集群上并行执行的基于python的数据处理应用程序Apache Spark是一个分析处理引擎,用于大...
大数据的Python和火花 适用于Python的课程笔记本和适用于大数据的Spark 课程大纲: 课程介绍 促销/介绍视频 课程大纲 Spark,RDD和Spark 2.0简介 课程设置 设置概述 EC2安装指南 ...带有PySpark示例
pyspark 该存储库专用于pyspark的代码段。 该代码已针对为Hadoop 2.7.3构建的Spark 2.4.6进行了测试。 注意:为了通过pyspark连接到Mongodb,您需要其他jar文件,具体取决于您使用的spark版本。 有用链接:
PySpark DataFrame示例PySpark –创建一个DataFrame PySpark –创建一个空的DataFrame PySpark –将RDD转换为DataFrame PySpark –将DataFrame转换为PandasPySpark – StructType和StructField 在DataFrame和RDD上...
(157条消息) 以集群方式运行pyspark_pyspark 集群_私奔到月球2023的博客-程序员宅基地.mhtml
MachineLearningLibrary和PySpark来解决一个文本多分类问题,内容包括:数据提取、Model Pipeline、训练/测试数据集划分、模型训练和评价等,具体细节可以参考下面全文。ApacheSpark受到越来越多的关注,主要是因为...
pyspark 数据处理样例数据
pyspark_db_utils 它可以帮助您在Spark中完成数据库交易文献资料使用例您需要jdbc驱动程序才能使用此库! 只需从 获取驱动程序并将其放在项目的jars /目录中设置示例: settings = { "PG_PROPERTIES": { "user": ...
使用Python和PySpark进行数据分析可以帮助您解决使用PySpark进行数据科学的日常挑战。您将了解如何在从任何源(Hadoop集群、云数据存储或本地数据文件)获取数据的同时,在多台机器上扩展处理能力。一旦您了解了这些...
波士顿房屋价格与Pyspark 使用PySpark和MLlib建立波士顿房价预测的线性回归Apache Spark已成为机器学习和数据科学中最常用和受支持的开源工具之一。 该项目是使用Apache Spark的spark.ml线性回归预测波士顿房价的...
PySpark2PMML 用于将Apache Spark ML管道转换为PMML的Python库。 特征 该软件包为库提供了Python包装器类和函数。 有关受支持的Apache Spark ML Estimator和Transformer类型的完整列表,请参考JPMML-SparkML文档。 ...
case_pyspark 基于Python语言的Spark数据处理分析案例集锦(PySpark) 实验环境 1) Linux: Ubuntu 20.04 2) Python: 3.7.x 3) Spark: 2.4.5(安装教程: 4) Jupyter Notebook: (安装教程和使用方法: 案例 ...
PySpark教程 PySpark是用于Spark的Python API。 PySpark教程的目的是提供使用PySpark的基本分布式算法。 PySpark具有用于基本测试和调试的交互式外壳程序( $SPARK_HOME/bin/pyspark ),不应将其用于生产环境。 ...
from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1', '...
Python大数据处理库 PySpark实战PPT课件
学习PySpark 这是Packt发布的的代码库。 它包含从头到尾完成本书所必需的所有支持项目文件。 关于这本书 Apache Spark是用于高效集群计算的开放源代码框架,具有用于数据并行性和容错性的强大接口。 本书将向您展示...
前言:前两天准备用 Python 在 Spark 上处理量几十G的数据,熟料在利用PyCharm进行PySpark远程调试时掉入深坑,特写此博文以帮助同样深处坑中的bigdata&machine learning fans早日出坑。 Version :Spark 1.5.0、...
Python大数据处理库 PySpark实战-源代码
主要是的 PySpark 端口。 先决条件 火花 1.2+ Python 2.7+ SciPy 0.15+ NumPy 1.9+ 实施细则 该项目遵循 spark-hash Scala LSH 实现的主要工作流程。 它的核心lsh.py模块接受 RDD 支持的密集 NumPy 数组或 ...
对数据探索分析,进行模型训练,测试数据集评估结果,建立可预测客户流失的模型,获取可能流失的用户名单。
PySpark示例项目本文档旨在与pyspark-template-project存储库中的代码并行阅读。 这些共同构成了我们认为是使用Apache Spark及其Python('PySpark')API编写ETL作业的“最佳实践”方法。 该项目解决以下主题: 如何...
本地开发和运营依存关系确保您已将Python 2.7和pip一起安装。 然后运行: pip install -r requirements.txt正在运行的工作使用中央作业运行程序模块src/index.py运行所有作业。 您完全不需要编辑此文件。...
推荐文章
- YOLO V8车辆行人识别_yolov8 无法识别路边行人-程序员宅基地
- jpa mysql分页_Spring Boot之JPA分页-程序员宅基地
- win10打印图片中间空白以及选择打印机预览重启_win10更新后打印图片中间空白-程序员宅基地
- 【加密】SHA256加盐加密_sha256随机盐加密-程序员宅基地
- cordys 启动流程_cordys服务重启-程序员宅基地
- net中 DLL、GAC-程序员宅基地
- (一看就会)Visual Studio设置字体大小_visual studio怎么调整字体大小-程序员宅基地
- Linux中如何读写硬盘(或Virtual Disk)上指定物理扇区_dd写入确定扇区-程序员宅基地
- python【力扣LeetCode算法题库】面试题 17.16- 按摩师(DP)_一个有名的讲师,预约一小时为单位,每次预约服务之间要有休息时间,给定一个预约请-程序员宅基地
- 进制的转换技巧_10111100b转换为十进制-程序员宅基地