”PDFpLUMBER“ 的搜索结果

利用Python中的PDFPLUMBER包从Pdf中读取表格
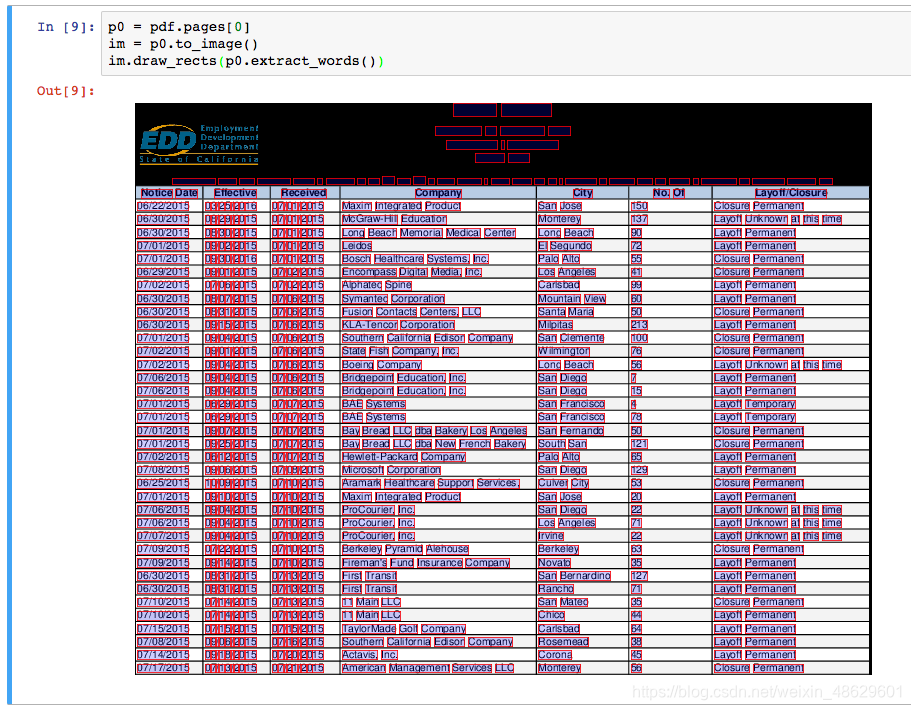
pdfplumber还可以获得页面上的所有单词、直线、方格、乃至曲线的位置信息,具体可以看看官网的说明:https://github.com/jsvine/pdfplumber。
pdfplumber是一个用于从PDF文档中提取文本和表格数据的Python库,它可以帮助用户轻松地从PDF文件中提取有用的信息,例如表格、文本、图表、尺寸等。其中有两个基础类分别为PDF和Page,前者用来处理文档,后者用来...
使用 extract_text() 方法会返回一个字符串,其中包含页面中的所有文本。如果你只想提取页面的一部分文本,可以将提取的区域作为参数传递给 extract_text() 方法。extract_tables() 方法将返回一个列表,其中包含每...
pdfplumber是一个用于从PDF文档中提取文本和表格数据的Python库。它可以帮助用户轻松地从PDF文件中提取有用的信息,例如表格、文本、元数据等。
从ju-chao网站收集财务数据并可以从中下载pdf文件的python脚本,更重要的是它可以使用pdfplumber从pdf文件中解析您想要的数据。 平台: win10 anaconda python3.7 pdfplumber == 0.5.12 (如果您已经安装了...
专门用于测试的资源,Python用pdfplumber第三方库读取pdf文件写入到Excel表中 定期会分布一些优质文章,希望大家多多关注,一键三连 博客地址:https://tianlingqun.blog.csdn.net/
pdf水暖工 插入PDF以获取有关每个文本字符,矩形和行的详细信息。...pdfplumber < background> background-checks.csv 输出将是CSV,其中包含有关PDF中每个字符,行和矩形的信息。 选项 争论 描述 --format [fo
在数据处理和信息提取的过程中,PDF文档是一种常见的格式。然而,要从PDF中提取信息并进行进一步...本文将介绍如何使用Python库中的pdfplumber库来读取PDF文档,并通过实际代码示例演示如何将提取的信息写入Excel文件。
pdfplumber说明文档翻译
pdf格式存在的,比如:论文,技术文档...pdf的文本和表格处理用多种方式可以实现, 本文介绍pdfplumber对文本和表格提取。这个库在GitHub上星600多,不过使用起来很方便, 效果也很好,可以满足对pdf中信息的提取需求。
pdfplumber是一个Python库,用于从PDF文件中提取信息。它提供了一个PDF类,表示单个PDF文件,并具有两个主要属性。metadata属性从PDF的Info中获取元数据键/值对字典,通常包括创建日期、修改日期、制作商等信息。...


通过python-pdfplumber提取pdf文件表格中的文本与划线。
python使用pdfplumber从pdf文件中获取表格信息,
问题遇到的现象和发生背景 用pdfplumber读取pdf文件,出现cid,观察一看pdf中这一部分是公式 问题相关代码,请勿粘贴截图 import pdfplumber # 读取pdf并选择对应的页数 pdf = pdfplumber.open('30.pdf') page = pdf...
与其他 Python PDF 处理库(如 PyPDF2、PDFMiner 等)相比,pdfplumber 提供了更简洁的 API 和更好的性能,使其成为 Python 开发者的首选库。在这个示例中,我们首先打开一个名为 "example.pdf" 的 PDF 文件,然后...

pdfplumber Original Website:https://github.com/jsvine/pdfplumber#visual-debugging Plumb a PDF for detailed information about each text character, rectangle, and line. Plus: Table extraction and visual...

使用pdfplumber包转换excel,注意转换后pdf的换号符会保留。 import pdfplumber from openpyxl import Workbook from tqdm import tqdm data_folder = './pdf/' # file_name = data_folder+'医保药品分类与代码数据库...
在虚拟环境下运行 python -m pip install --upgrade pip 升级后,pip的版本变成 pip 23.1.2,与系统的相同,然后再在虚拟环境下 pip install pdfplumber就可以了。如果这种情况下运行 pip -V 与系统的pip版本不同,...
通过Python的pdfplumber库提取pdf中表格数据。
PDFPlumber学习
标签: 学习
含义:pdfplumber.Page.filter(test_function)是pdfplumber库中Page对象的方法,用于根据指定的条件过滤页面中的文本元素,并返回一个新的Page对象。(可以使用这个过滤简历当中的特定关键字如“java”"前端"“算法...
安装成功pdfplumber了但是在spyder里import时报错No module named 'pdfplumber' 为啥,应该如何解决


推荐文章
- I2C知识大全系列六 —— I2C应用之Linux下的I2C_linux控制i2c应用编程-程序员宅基地
- 微擎URL路由_noloading: true, noredirect: true-程序员宅基地
- 关于arduino程序编译成功但上传失败的情况_arduino编译完成但上传错误-程序员宅基地
- 机器学习中的数据预处理_机器学习数据预处理顺序-程序员宅基地
- 谈一次java web系统的重构思路_java web 如何做系统重构-程序员宅基地
- 如何一文认识 AngularJS_angularjs理解-程序员宅基地
- 编写C语言程序,输入每个学生的学号和身高,保存在二进制文件中,并统计每个身高的人数打印出来...-程序员宅基地
- R语言 最优子集选择与K折交叉验证_最优子集法做交叉验证-程序员宅基地
- antd From 中 Form.Item里含有自己封装的组件,获取不到值的解决方法_from.item 拿到组件无法获取参数-程序员宅基地
- 爬虫的基本原理-程序员宅基地