需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key...
”MapReduce学习“ 的搜索结果
MapReduce学习文档
标签: 源码 工具
NULL 博文链接:https://woodbird456.iteye.com/blog/472545
Hadoop基础学习---5、MapReduce概述和WordCount实操(本地运行和集群运行)、hadoop序列化
资源内容:Hadoop_MapReduce教程.doc;Hadoop_Mapreduce云计算_技术手册.pdf;Hadoop及Mapreduce入门.pptx;改进型MapReduce(第二版).pdf;
Java MapReduce是一种基于Java编程语言的大数据处理框架,它实现了MapReduce编程模型,允许开发者编写能够在大量数据上并行运行的分布式算法。以下是Java MapReduce的核心内容概述: 1. **MapReduce框架**:Java ...
去官网下载Hadoop的安装包,在windows上解压src的也要下载,上面的链接提供了2.6.5的,需要更高版本自行下载下载好压缩包,在windows上解压,并新建一个hadoop-lib的文件夹将下载好的plugin包,放在你的eclipse的...
(1) 需求过滤输入的 log 日志,包含atguigu的网站输出到 atguigu.log,不包含 atguigu 的网站输出到 other.log。log.txt(2)代码编写@Override// 直接写出@Override// 遍历直接写出自定义/\*\*\* 自定义的...
大数据从入门到实战 - 第3章 MapReduce基础实战 一、关于此次实践 1、实战简介 2、全部任务 二、实践详解 1、第 1 关:成绩统计 2、第 2 关:文件内容合并去重 3、第 3 关:信息挖掘 - 挖掘父子关系 叮嘟!这里是小...

1 序列化概述1.1 什么是序列化和反序列化1.2 为什么要序列化1.3 为什么不用java序列化1.4 hadoop序列化特点2 实现hadoop的Writable接口2.1 hadoop的基本序列化类型2.2 接口实现基本步骤3 序列化案例实操 ...
通常在Map Task任务完成MOF输出进度到约3%时启动Reduce,从各个Map Task获取MOF文件。Reduce Task个数由客户端决定,Reduce Task 个数决定MOF文件分区数。因此Map Task输出的MOF文件都能找到对应的Reduce Task来处理...
简单来说数据倾斜就是数据的key 的分化严重不均,造成一部分数据很多,一部分数据很少的局面。举个 word count 的入门例子,它的map 阶段就是形成 (“aaa”,1)的形式,然后在reduce 阶段进行 value 相加,得出 ...



MapReduce学习问题记录
标签: 学习
第一行数据是字段名不需要处理,我们知道第一行偏移量是0(行记录的时候是从数组首地址开始,到了行标识符进行一次计数,这个计数就是行偏移量,从0开始),我们根据偏移量值进行判断,然后用中断方法把第一行数据跳...
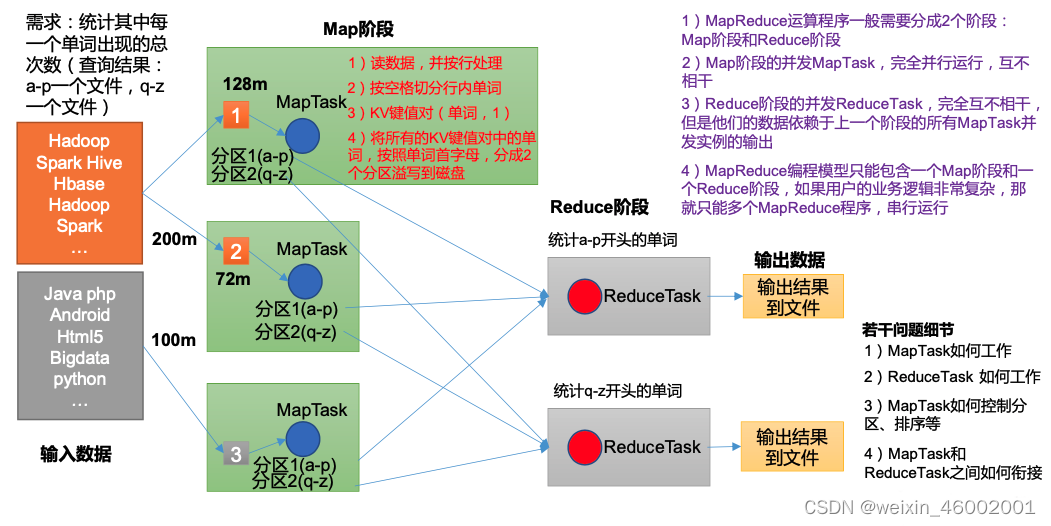
MapReduce是一种可用于数据处理的编程模型,我们现在设想一个场景,你接到一个任务,任务是:挖掘分析我国气象中心近年来的数据日志,该数据日志大小有3T,让你分析计算出每一年的最高气温,如果你现在只有一台计算机...
hadoop2.7MongoDB 有两种聚合函数:aggregate 与 mapreduce。
MapReduce学习笔记,做项目用
MapReduce学习笔记,呕心沥血写出来的,里面有很多经验 MapReduce学习笔记,呕心沥血写出来的,里面有很多经验 MapReduce学习笔记,呕心沥血写出来的,里面有很多经验


Mapreduce是一种分布式并行编程:借助一个集群通过多台机器同时并行处理大规模数据集。 Mapreduc模型简介 Mapreduce采用分而治之的方法实现,把非常庞大的数据集,切分成非常多的独立的小片,然后单独的启动一个Map...

适合入门的hadoop学习者,这是一个MapReduce入门的学习代码,主要实现的功能是词的拆分和统计,使用分布式计算



推荐文章
- 1N5819-ASEMI轴向肖特基二极管1N5819-程序员宅基地
- 把maven的setting配置文件改为需要jdk版本_<profile> <id>jdk-1.4</id> <activation> <jdk>1.4</-程序员宅基地
- 使用matlab进行DBscan聚类_dbscan聚类分析图用什么软件-程序员宅基地
- 探秘技术新星:BBS_admin - 一个现代化的论坛后台管理系统-程序员宅基地
- 【译】JavaScript 开发者年度调查报告-程序员宅基地
- 神仙级渗透测试入门教程(非常详细),从零基础入门到精通,从看这篇开始!_网络渗透技术自学-程序员宅基地
- 多个protocbuf版本切换_protobuf调整版本-程序员宅基地
- msf+cobaltstrike联动(一):把msf的session发给cobaltstrike-程序员宅基地
- C语言--编写程序,输入一个整数,判断它能否被3,5,7整除_编程序实现功能:输入一个整数,判断其是否能同时被3、5、7整除。能被整除则输出“y-程序员宅基地
- 数据技术之Hadoop(HFDS文件系统)-程序员宅基地