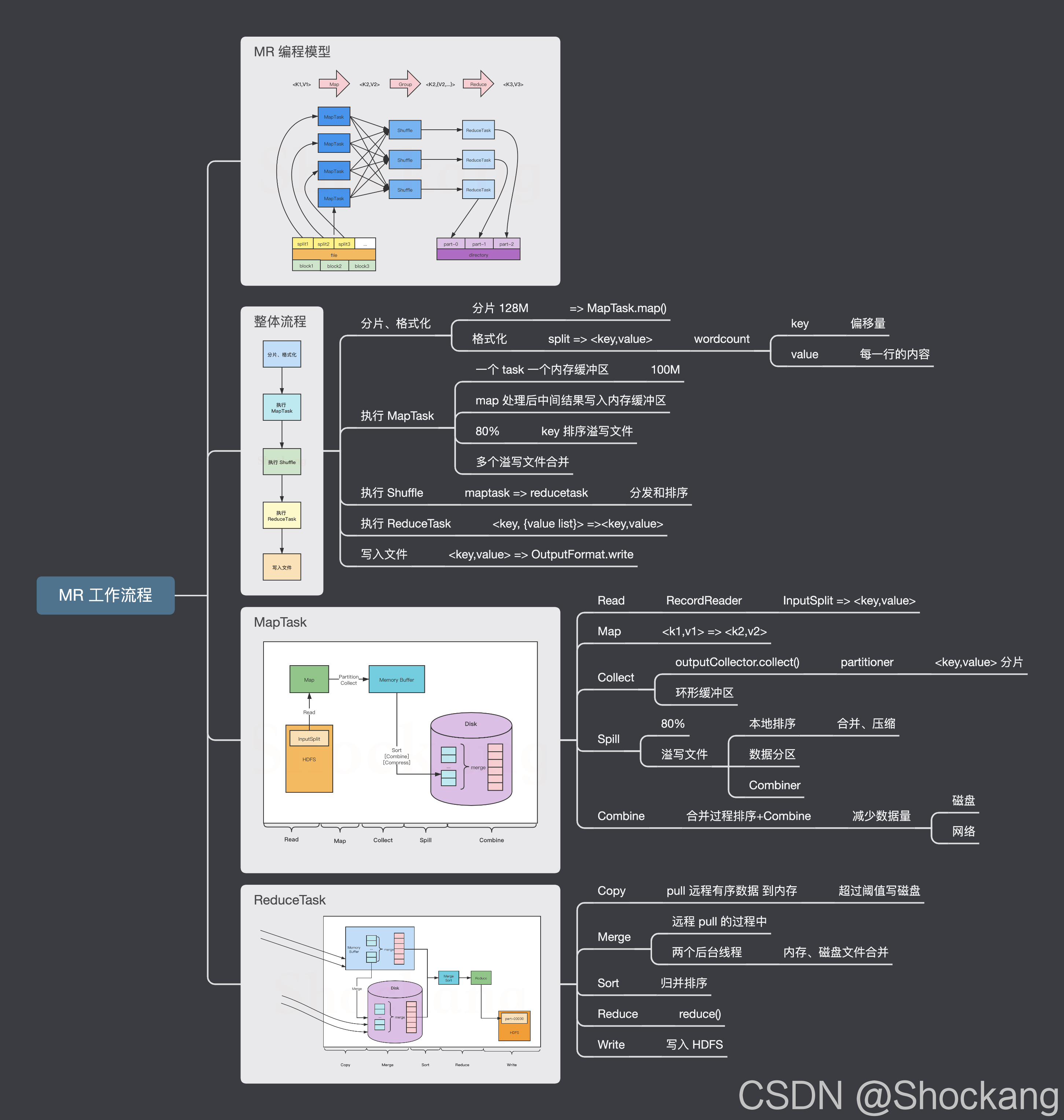
下面详细介绍MapReduce中Map任务Reduce任务以及MapReduce的执行流程。 Map任务: 读取输入文件内容,解析成key,value对。对输入文件的每一行,解析成key,value对。每一个键值对调用一次map函数。 写自己的逻辑,对...
”MapReduce“ 的搜索结果
大数据mapreduce案例
标签: s'd'
大数据mapreduce案例介绍,包括代码解释,详解MRS工作流程
实现KNN算法和K-means算法,的详细过程。
本文首先对MapReduce和Spark的基本信息做了对比性介绍,接着分别对 MapReduce和Spark进行基础性知识讲解,然后在单台Linux服务器上安装了Spark,并以实际代码演示了从 MapReduce转换代码到Spark时需要注意的事项。...
基于mapreduce的小型电影推荐系统,使用javaweb的方式实现,
单词计数是最简单也是最能体现 MapReduce 思想的程序之一,可以称为 MapReduce 版“Hello World”。单词计数的主要功能是统计一系列文本文件中每个单词出现的次数。本节通过单词计数实例来阐述采用 MapReduce 解决...
本文将以对访问网页用户的日志进行分析,进而挖掘出用户兴趣点这一完整流程为例,详尽解释MapReduce模型的对应实现,涵盖MapReduce编程中对于特殊问题的处理技巧,比如机器学习算法、排序算法、索引机制、连接机制等...
大数据分析技术基础PPT课件(共9单元)4-MapReduce 编程.pdf大数据分析技术基础PPT课件(共9单元)4-MapReduce 编程.pdf大数据分析技术基础PPT课件(共9单元)4-MapReduce 编程.pdf大数据分析技术基础PPT课件(共9单元)4-...
GFS、MapReduce 和 BigTable。作为 Google 早期三驾马车,这三项革命性的技术不仅在大数据领域广为人知,更直接或间接性的推动了大数据、云计算、乃至如今火爆的人工智能领域的发展。
本文介绍了用Java编写并运行第一个mapreduce作业的步骤及遇到的问题和解决方案。
随着海量图像数据的增加,使得需要处理的数据规模越来越大,为了解决在处理海量数据信息时所面临的存取容量和处理速度的问题,在深入研究MapReduce大规模数据集分布式计算模型的基础之上,本文设计了基于MapReduce...
MapReduce 谷歌实验室论文--大规模集群下的数据处理,英文版
对应博客:MapReduce 运行原理(万字长篇 原理 + 案例) 链接:https://blog.csdn.net/weixin_47243236/article/details/121581689?spm=1001.2014.3001.5501
Counters represent global counters, defined either by the MapReduce framework or applications. Each Counter can be of any Enum type. Counters of a particular Enum are bunched into groups of type ...
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,MapReduce则为海量的数据提供了计算。 HDFS是GoogleFileSystem(GFS)的开源实现。MapReduce是GoogleMapReduce的开源实现。HDFS和...
为评估云计算编程模型MapReduce对于石油勘探领域应用算法的适用性,设计并实现了基于MapReduce的三维Fresnel层析成像算法,实验发现MapReduce版本的性能比MPI版本慢3倍,而且对MapReduce作业调优的难度相当大。...
mapreduce 编程 此示例程序将让您提取有用的统计数据,例如排名前 10 的平均评分电影、使用 Hadoop map-reduce 框架以及链接多个映射器和化简器对 200 万条记录进行基于流派的过滤
这是谷歌三大论文之一的 MapReduce: Simplified Data Processing on Large Clusters 英文原文。我的翻译可以见https://blog.csdn.net/m0_37809890/article/details/87830686
MapReduce实现单元最短路径算法.doc
谷歌三大论文,bigtable,File-system, mapreduce的中文版论文
var MapReduce = require ( 'node-mapreduce' ) ; var mapReduce = MapReduce ( ) ; var article = 'A very long string' ; function map ( str ) { var ret = { } ; str . match ( / [ a-zA-Z ] + / g ) . ...
主要介绍了MongoDB中的MapReduce简介,MapReduce是一种计算模型,简单的说就是将大批量的工作(数据)分解(MAP)执行,然后再将结果合并成最终结果(REDUCE),需要的朋友可以参考下
这是MapReduce的小例子,计算单词量,其中就只是用到小框架,只不过每个人的算法不一样而已。 对应博客地址: https://blog.csdn.net/magic_ninja/article/details/80071394
mapreduce.md
标签: mdb文件
关于Hadoop中MapReduce的Wordcount以及数据去重的一点概括,不是太准确,我也还只是个初学者,不足之处请指正
需要反射调用空参构造函数,所以必须有空参构造(3)重写序列化和反序列化方法,同时要求顺序一致(4)如果需要将自定义的bean放在key中传输,则还需要实现Comparable接口,因为MapReduce框中的Shuffle过程要求对key...
CrystalBall - Apache Hadoop MapReduce 中的朴素贝叶斯文本分类器 创建者:徐敏 日期:2015年6月1日 如何使用该程序 构建程序 ./build.sh 将在bin/创建一个 jar 文件 crystal.jar。 使用MapReduce建立分类模型 ....
使用python写微博关注者之间,相似度最高的十个用户的mapreduce,代码有点粗糙,主要是给大家提供思路的,不同的问题是需要修改的。
MapReduce天气源数据和计算类 1901年和1902的天气数据源,通过mr计算,找出最大温度和最小问题
使用hadoop-streaming运行Python编写的MapReduce程序.rar
推荐文章
- withRouter,非根组件获取路由参数_withrouter 只能取到路由中的一个参数-程序员宅基地
- ubuntu环境下QT5操作摄像头报错,cannot find -lpulse-mainloop-glib cannot find -lpulse cannot find -lglib-2.0_cannot find–lpulse-程序员宅基地
- 用jbpm_bpel学jwsdp的ant方式使用-程序员宅基地
- 输入数字判断星期几_html获取当前星期几-程序员宅基地
- SpringBoot整合Activiti7——实战之放假流程(会签)_activit7中会签-程序员宅基地
- 阿里云服务器收到挖矿病毒的攻击,导致基础的文件被病毒污染的问题和对应的处理解决方法-程序员宅基地
- 北京东城区空调维修办法,格力变频空调出现ph,到底是怎么回事?_格力变频空调ph代码-程序员宅基地
- vscode编辑器使用拓展插件background添加背景图片改变外观_background vscode-程序员宅基地
- android 简单打电话程序_android拨打电话的程序-程序员宅基地
- 第二届中国(泰州)国际装备高层次人才创新创业大赛_泰州市双创人才计划2022-程序员宅基地