基于数据密度自动计算最佳K聚类中心,对数据进行聚类
”K-means“ 的搜索结果


基于改进的K-means算法的彩色图像分割
Color quantization using the fast K-means algorithm Color Quantization Using the Fast K-Means Algorithm Hideo Kasuga Graduate School of Engineering, Shinshu University, Nagano, Japan 380-8553 ...
基于改进人工蜂群算法的K均值聚类算法-喻金平-郑杰-梅宏标,matlab
1. K-means K值的选取方法: 值得一提的是关于聚类中心数目(K值)的选取,的确存在一种可行的方法,叫做Elbow Method(肘部法则): 通过绘制K-means代价函数与聚类数目K的关系图,选取直线拐点处的K值作为最佳...
机器学习算法主要分为两大类:有监督学习和无监督学习,它们在算法思想上存在本质的区别。有监督学习,主要对有标签的数据集(即有“参考答案”)去构建机器学习...常见的无监督学习算法,包括 K-means 聚类算法、均
针对初始聚类中心对传统K-means算法的聚类结果有较大影响的问题,提出一种依据样本点类内距离动态调整中心点类间距离的初始聚类中心选取方法,由此得到的初始聚类中心点尽可能分散且具代表性,能有效避免K-means算法...
K-means聚类算法的三种改进(K-means++,ISODATA,Kernel K-means)介绍与对比

人工智能-项目实践-机器学习
K-Means算法又称K均值算法,属于聚类(clustering)算法的一种,是应用最广泛的聚类算法之一。所谓聚类,即根据相似性原则,将具有较高相似度的数据对象划分至同一类簇,将具有较高相异度的数据对象划分至不同类簇。...
K均值(K-means)是一种基于距离度量的聚类算法,其主要思想是将数据集划分为k个不同的簇,每个簇代表一个相似度较高的数据组。该算法通过迭代优化来最小化所有数据点与其所属簇的欧氏距离之和,从而找到最佳的簇...
k-均值聚类和层次聚类 电影评分的k均值聚类 层次聚类
k均值K-means算法案例,包括K=2和肘部法则及图形展示
k-means训练,数据,停用词,代码
Kmeansplusplus 带有可选 k-means++ 初始化的 K-means 实现,基于 John Aleshunas 的 k-means 多属性实现。 需要 C++11; 没有其他依赖。 通过在源目录中运行make编译。用法运行k-means++ [control file name]控制...
K-means聚类PPT,讲课实用课件。共包括算法原理、算法流程、实例讲解、应用场景、算法总结、改进算法几个内容。
K-Means聚类算法研究综述_杨俊闯.pdf
K-means算法实现的IDL源码,可直接分类遥感影像

一种基于k-means的分布式k-anonymity算法,张琦颖,程祥,随着的大数据时代的到来,数据分享、数据发布的需求日益增加。然而未经处理发布或共享原始数据,将引起隐私泄露问题。k-anonymity匿�
本节用Python实现K-Means算法,对未标注的数据进行聚类。主要参考《机器学习实战》—— Peter Harrington著。 导航K-Means简介代码实现(一)数据集读入(二)距离计算(三)构建随机质心(四)数据聚类(五)完整...
Users_Clustering根据用户的行为模型,使用k-means算法对用户进行聚类
一、聚类分析 1.1 聚类分析 聚类: 把相似数据并成一组(group)的方法。‘物以类聚,人以群分’ 不需要类别标注的算法,直接从数据中学习模式 所以,聚类是一种 数据探索 的分析方法,他帮助我们在大量数据中...
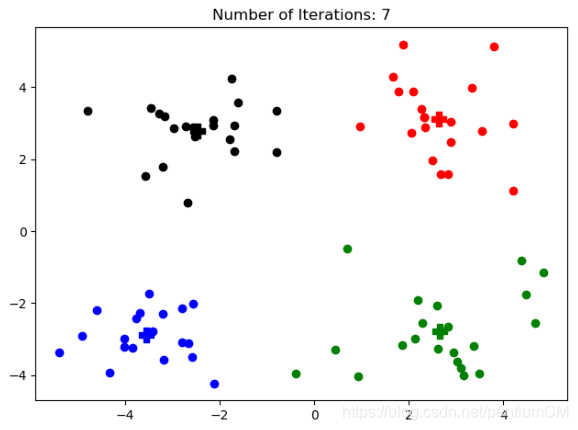
K-means算法 matlab 确保运行成功
基于K-means的印刷品图像前景提取算法研究,陆金鑫,周亚建,前景提取是印刷品检测系统模板图像生成的关键技术。考虑到印刷品图像特性和其所处环境的颜色特性,在HSV彩色模式下将K-means聚类用��
推荐文章
- Unity3D 导入资源_unity怎么导入压缩包-程序员宅基地
- jqgrid 服务器端验证,javascript – jqgrid服务器端错误消息/验证处理-程序员宅基地
- 白山头讲PV: 用calibre进行layout之间的比对-程序员宅基地
- java exit方法_Java:如何测试调用System.exit()的方法?-程序员宅基地
- 如何在金山云上部署高可用Oracle数据库服务_rman target sys/holyp#ssw0rd2024@gdcamspri auxilia-程序员宅基地
- Spring整合Activemq-程序员宅基地
- 语义分割入门的总结-程序员宅基地
- SpringBoot实践(三十五):JVM信息分析_怎样查看springboot项目的jvm状态-程序员宅基地
- 基于springboot+vue的戒毒所人员管理系统 毕业设计-附源码251514_戒毒所管理系统-程序员宅基地
- 【LeetCode】面试题57 - II. 和为s的连续正数序列_leet code 和为s的正数序列 java-程序员宅基地