文章目录前言一、安装Hive1. 下载压缩包并解压2. 安装Hive3. 配置环境变量4. 修改配置文件二、MySQL安装与配置1. 安装MySQL2. 安装MySQL jdbc包3. 为Hive创建MySQL账号三、验证Hive安装及错误处理1. 启动Hadoop2. ...
”Hive“ 的搜索结果
测试代码:确保有可查询的表存在。连接数据库需要导入jar包。
Hive常用操作,增删改查语句
一、修改hive配置文件 vim hive-site.xml <property> <name>hive.files.umask.value</name> <value>0002</value> </property> <property> <name>hive....
对数据进行统计分析,SQL是目前最为方便的编程工具,大数据体系中充斥着非常多的统计分析场景,所以使用SQL去处理数据,在大数据中也是有极大的需求的。它将每一个文件储存以西开裂 的数据块,这个数据块被称为block...
Hive是一个开源的数据仓库工具,用于在Hadoop平台上进行数据查询和分析。它是基于Hadoop的。因此,从本质上来看,Hive是将SQL转换为MapReduce程序的工具。因为,比直接用MapReduce开发效率更高,Hive的主要作用就是...

转载自 https://blog.csdn.net/u010003835/article/details/80804425在Hive 安装后... hive 主要的配置文件为 conf 中 hive-site.xml那该文件中那么多的配置选项都是什么含义呢。下面这篇文章带你解密这...
为临时存储层,是接口数据的临时存储区域,为后一步的数据处理做准备。数据仓库层(DW):也称为细节层,DW层的数据应该是一致的、准确的、干净的数据,即对源系统数据进行了清洗(去除了杂质)后的数据。...
Hive最初由Facebook开源,用于解决海量结构化日志的数据统计分析,是建立在Hadoop集群的HDFS上的数据仓库基础框架,其本质是将类SQL语句转换为MapReduce任务运行。Hive是基于Hadoop的一个数据仓库工具,用来进行数据...
hive查看分区
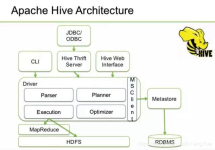
Hive有关介绍Hive是什么使用Hive的好处Hive的特点Hive架构Hive工作原理Hive中表的分类Hive与HBase的联系和区别Hive与HBase的联系Hive与HBase的区别 Hive是什么 (1)由Facebook开源,最初用于解决海量结构化的日志...
搭建Hive环境请看这篇文章:Hive介绍与环境搭建-程序员宅基地。
Fetch 抓取是指,Hive 中对某些情况的查询可以不必使用 MapReduce 计算。例如:SELECT * FROM emp;在这种情况下,Hive 可以简单地读取 emp 对应的存储目录下的文件,然后输出查询结果到控制台。在文件中默认是more,...
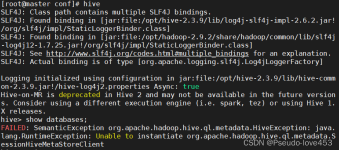
解决Hive启动后报错FAILED:HiveException java.lang.RuntimeException和MetaException(message:Required table missing : “DBS” in Catalog “” Schema “”. DataNucleus requires this table to perform its ...
本文章主要描述了GaussDB(DWS)与HiveMetaStore对接配置与指导。
将以下信息填写到configuration中。java_home填写自己安装的路径。三台机器配置环境变量。
安装Hive 3.1.2版本对应的Hadoop3.x,也就是Hive On MapReduce , Hive类似于Hadoop集群的一个客户端,本身没有集群的概念。简单来说Hive的功能就是可以将SQL转化成MR的任务,从而简化了MR的开发。 本文在Hadoop3....
在运行hive命令时传入参数,使用-hivevar 和 -hiveconf 两种参数选项,来给此次的执行脚本传入参数 -hivevar : 传参数 ,专门提供给用户自定义变量。 -hiveconf : 传参数,包括了hive-site.xml中配置的hive全局变量...
在大数据学习当中,尤其...Hive简介根据官方文档的定义,Hive是一种用类SQL语句来协助读写、管理那些存储在分布式存储系统上大数据集的数据仓库软件1、进入hive数据库:hive2、查看hive中的所有数据库:show databa...

除了上述常见的数据类型,Hive还提供了更多的数据类型和复杂数据类型Binary类型等。结构体类型(Structs):用于存储不同类型的字段组成的记录。数组类型(Arrays):用于存储多个相同类型的元素的集合。
hive
文章目录一、安装 Hive1. 解压安装包2. 配置环境变量二、配置 Hive1. 配置 hive-site.xml 文件2. 复制 mysql 驱动程序3. 初始化 Hive 元数据四、运行 一、安装 Hive 1. 解压安装包 将 Hive 安装包解压并移动到 /usr/...

开始了!
推荐文章
- 【vue-treeselect+vxe-table】数据量大的时候懒加载,数据回显,输入框绑值,末级节点不要前面的箭头等问题详解_treeselect显示加载中-程序员宅基地
- 【从0入门JVM】-01Java代码怎么运行的_代码如何在jvm中运行-程序员宅基地
- TreeViewer应用实例(ITreeContentProvider与LabelProvider的使用)-程序员宅基地
- 如何将别人Google云端硬盘中的数据进行保存_谷歌网盘怎么保存别人的资源-程序员宅基地
- java中查看数据类型_java查看数据类型-程序员宅基地
- Scrapy-redis分布式+Scrapy-redis实战-程序员宅基地
- web播放H.264/H.265,海康,大华监控摄像头RTSP流方案_海康api hls怎么取265的流-程序员宅基地
- HTML详解连载(7)-程序员宅基地
- PHP使用多线程-程序员宅基地
- 由excel一键生成json的小工具(基于python,仅支持单层嵌套)_excel转json github-程序员宅基地