
”Hive“ 的搜索结果

Hive正则表达式
hive是Hadoop的客户端,启动hive前必须启动hadoop,同时hive的元数据存储在mysql中,是由于hive自带的derby数据库不支持多客户端访问。 2.开启metastore服务的参数 hive-site.xml中打开metastore的连接地址。 <!-...
一.Hive安装 1、下载安装包:apache-hive-3.1.1-bin.tar.gz 上传至linux系统/opt/software路径 2、解压软件 cd /opt/software tar -zxvf apache-hive-3.1.1-bin.tar.gz -C /opt/module/ 3、修改系统环境变量 vi /...


文章目录一、Hive 数据仓库的操作1、创建数据仓库2、查看 db 数据仓库的信息及路径3、删除 db 数据仓库二、Hive 数据表的操作1、创建内部表2、创建内部表3、修改表结构4、删除表5、创建同结构表三、Hive 中数据的...
1.SparkSQL 整合 Hive 导读 开启Hive的MetaStore独立进程 整合SparkSQL和Hive的MetaStore 和一个文件格式不同,Hive是一个外部的数据存储和查询引擎, 所以如果Spark要访问Hive的话, 就需要先整合Hive ...
1,执行#hive命令进入Hive CLI时报如下错误: Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata....
Apache Flink 从 1.9.0 版本开始增加了与 Hive 集成的功能,用户可以通过 Flink 来访问 Hive 的元数据,以及读写 Hive 中的表,Hive 是大数据领域最早出现的 SQL 引擎,发展至今有着丰富的功能和广泛的用户基础。...
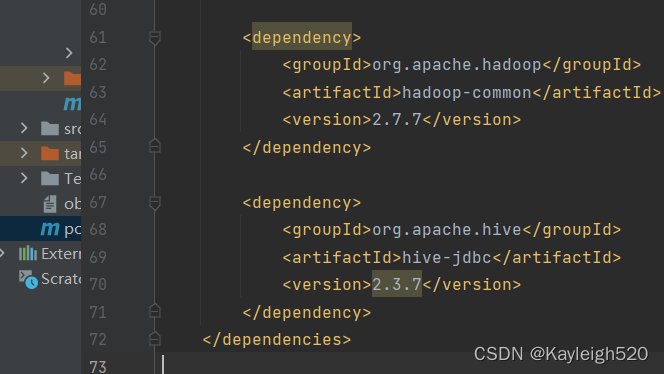
jdbc连接Hive
标签: hive
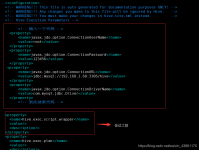
jdbc连接Hive 1.使用sqoop将stu表导入到hive中 数据库表位于hadoop102上的test数据库 bin/sqoop import \ --connect jdbc:mysql://hadoop102:3306/test \ --username root \ --password 000000 \ --table stu ...
hive报错Error: Error while processing statement: FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask (state=08S01,code=2)
hive是facebook开源,并捐献给了apache组织,作为apache组织的顶级项目(hive.apache.org)。 hive是一个基于大数据技术的数据仓库(DataWareHouse)技术,主要是通过将用户书写的SQL语句翻译成MapReduce代码,然后发布...

1、分区表1)创建分区表hive> create table dept_partitions()> partition by()> row format> delimited fields> terminated by '';例:hive> create table dept_partitions(deptno int, dept ...
Hive与Hadoop的关系3. Hive中的命令3.1 创建数据库并指定hdfs存储位置3.2 修改数据库3.3 查看数据库信息3.4 创建表并指定字段之间的分隔符4. Hive中的四种表结构4.1 内部表4.2 外部表4.3 分区表4.4 分桶表 1. 概念 ...
1.1 Hive引擎简介 Hive引擎包括:默认MR、tez、spark Hive on Spark:Hive既作为存储元数据又负责SQL的解析优化,语法是HQL语法,执行引擎变成了Spark,Spark负责采用RDD执行。 Spark on Hive : Hive只作为存储元...
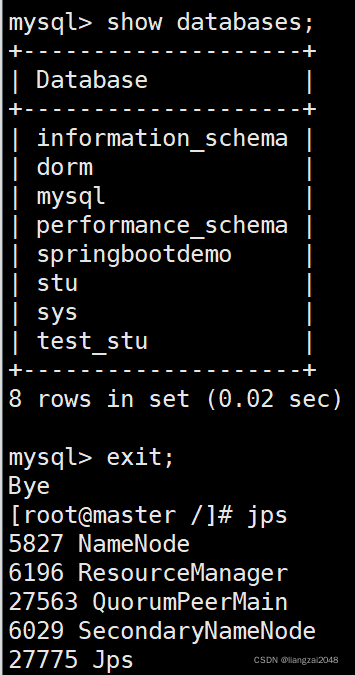
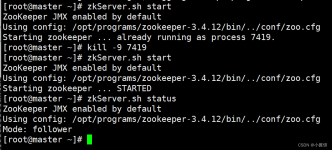
Hive的安装和配置-安装步骤: 1.配置Hadoop环境 2.安装MySQL数据库 3.配置MySQL相关 4.上传hive安装包,解压,重命名 5.设置环境变量 6.修改hive配置文件 7.上传MySQL连接驱动 8.初始化元数据 9.启动Hive 下面开始:...
使用 Hive 表时由于数据的变换经常需要调整 Hive 表字段结构,这里记录一下常用方法。先创建一个测试表 tmp_change_column,包含两个字段 a,b 和分区标识 dt : function createTable() { hive -e " create table ...

Hive分区应用实战
Running Hive Hive CLI $HIVE_HOME/bin/hive(连接命令) HiveServer2 and Beeline $HIVE_HOME/bin/hiveserver2(h2的启动命令) $HIVE_HOME/bin/beeline -u jdbc:hive2://$H2_HOST:$H2_PORT(连接命令) HCatalog $...


推荐文章
- com.netflix.discovery.shared.transport.TransportException: Cannot execute request on any known serve-程序员宅基地
- PAT乙级练习题1010 一元多项式求导_pat 乙级 1010-程序员宅基地
- You can also run `php --ini` inside terminal to see which files are used by PH P in CLI mode_you can also run `php --ini` in a terminal to see -程序员宅基地
- 对UDP校验和的理解_udp 数据包 校验和 checksum=0-程序员宅基地
- 递归遍历文件夹,以c:/windows为例-程序员宅基地
- git 本地与远程的链接_git如何本地和网页链接-程序员宅基地
- ArrayList与HashMap遍历删除元素,HashMap与ArrayList的clone体修改之间影响_在arraylist和hashmap遍历的同时删除元素,可能会导致一些问题发生-程序员宅基地
- Chapter2-软件构造过程和生命周期_iterative and agile systems development lifecycle -程序员宅基地
- 4.6 浮动定位方式float_c语言中float的左右浮动属性示例-程序员宅基地
- OSS上传【下载乱码问题】_阿里云oss文件名乱码-程序员宅基地