”Hive“ 的搜索结果
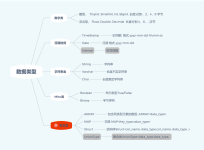
学习笔记—Hive创建表 1. Hive语句的特点 HQL 语言大小写不敏感,但内容分大小写(where ,if/ case when,如:数据表内容某人名叫Tom,则条件后不能写tom,HDFS 路径名(NameNode)分大小写) ; HQL 可以写在一行...
hive选择题总结

1、开启hive 1.1 进入 hive/bin [root@hadoop0001 bin]#cd /opt/software/apache-hive-1.2.1-bin/bin/ 1.2执行 hive 命令,开启hive [root@hadoop0001 bin]#hive 1.3若开启正常跳过,若报Cannot create ...

文章目录hive入门介绍1、什么是Hive2、Hive的优缺点3、Hive的架构原理4、Hive与数据库进行比较查询语言数据存储位置数据更新索引执行执行延迟可扩展性数据规模 1、什么是Hive hive:由Facebook开源用于解决海量结构...
拷贝hadoop/share/hadoop/common/lib目录中的 guava-27.0-jre.jar 到 hive/lib 目录。不要使用图形化 不然每次保存后3215行都会有个 特殊字符 如果产生删除即可 具体报错信息 后面有单独的描述。删除原有的 protobuf...
在hive中,没有直接的update语句,可以使用insert overwrite来覆盖原有表数据达到更新的效果。
hive数据类型转换规则及转换原则,日期类型转换
1. Hive简介 hive的定位是数据仓库,其提供了通过 sql 读写和管理分布式存储中的大规模的数据,即 hive即负责数据的存储和管理(其实依赖的是底层的hdfs文件系统或s3等对象存储系统),也负责通过 sql来处理和分析...
Hive3.1.2安装教程前言初始准备安装Hive的具体步骤1、下载hive安装包2、解压3、添加Hive核心配置,选择远程MySQL模式4、下载连接MySQL的驱动包到hive的lib目录下5、在MySQL上创建Hive的元数据存储库6、执行Hive的...

目录一定要先看的前言1 安装Hadoop1.1 下载并解压资源1.2 配置系统变量和环境...Hive MySQL版本2.1 下载并解压资源2.2 配置系统变量和环境变量2.2.1 系统变量2.2.2 环境变量2.3 Hive config配置2.4 创建目录2.5 修改...
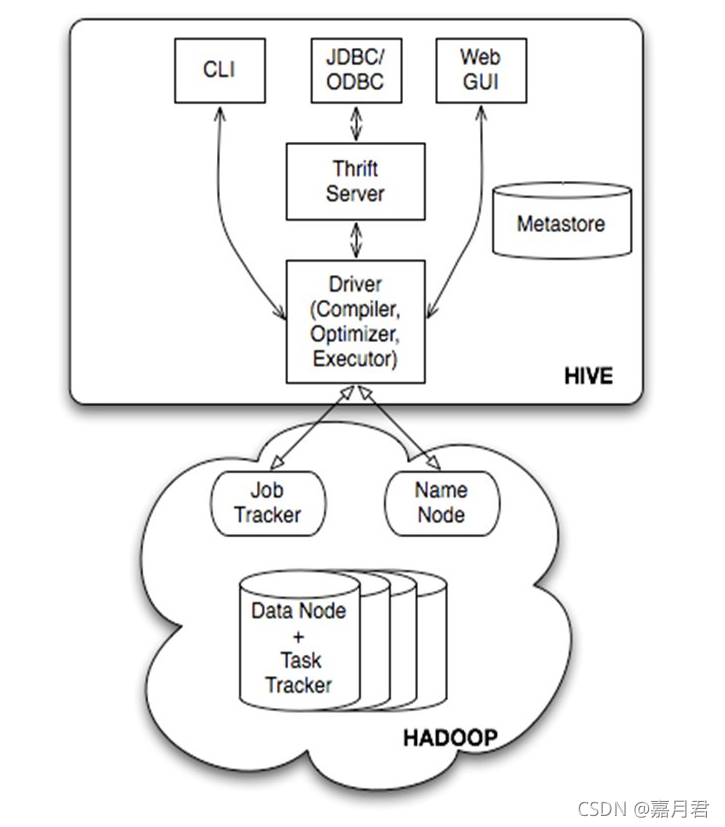
要知道两种sql的区别,先要知道什么是hive,什么是spark 一、什么是hive,什么是spark (一)hive 1、hive在hadoop中承担了多种角色,每种角色承担特定的功能。 定语 角色 作用 优点 基于Hadoop的数仓工具 ...
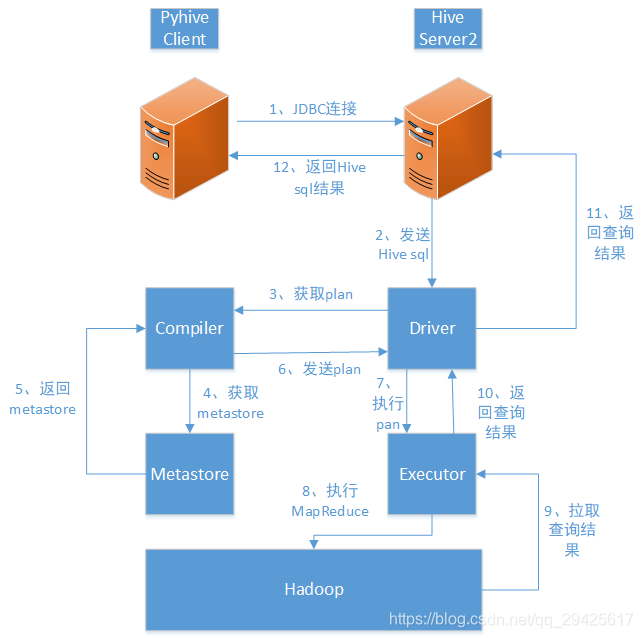
python读取hive方案对比 引言 最近接到一项任务–开发python工具,方便从HDFS读取文件和Hive表数据。当前网上的方案大多是通过第三方python包实现,只需导入指定pypi包即可完成,这种方案虽然在功能上具有可行性,...
hive
问题描述 执行语句 create table test(id int); 然后 向新创建的表中插入数据 insert into test values(1); 控制台 报错 ... at org.apache.hadoop.hive.ql.metadata.Hive.setPartitionColumnSta
二、hive的安装 1)hive-site.xml配置文件 三、启动hiveserver2 四、idea连接hive,按照以下步骤 一、mysql的安装 #卸载Centos7自带mariadb rpm -qa|grep mariadb mariadb-libs-5.5.64-1.el7.x86_64 ...
启动hive
Hive自定义UDF函数详解一、UDF概述二、UDF种类三、如何自定义UDF四、自定义实现UDF和UDTF4.1 需求4.2 项目pom文件4.3 Hive建表测试及数据4.4 UDF函数编写4.5 UDTF函数编写 一、UDF概述 UDF全称:User-Defined ...
使用hive sql 为hive增加或者创建自增列,自增id的五种方式
一、Hive优化目标在有限的资源下,提高执行效率二、Hive执行HQL——> Job——> Map/Reduce三、执行计划查看执行计划explain [extended] hql四、Hive表优化1、分区静态分区动态分区set hive.exec....
Spark on Hive 是Hive只作为存储角色,Spark负责sql解析优化,执行。这里可以理解为Spark 通过Spark SQL 使用Hive 语句操作Hive表 ,底层运行的还是 Spark RDD。具体步骤如下:【总结】Spark使用Hive来提供表的...
一、下载hive 下载hive——地址:http://mirror.bit.edu.cn/apache/hive/ 二、安装mysql 执行以下几个命令安装mysql su - root yum -y install mysql mysql-server mysql-devel wget ...
Hive的两种部署方法(教学版)
什么是Hive Catalog 我们知道,Hive使用Hive Metastore(HMS)存储元数据信息,使用关系型数据库来持久化存储这些信息。所以,Flink集成Hive需要打通Hive的metastore,去管理Flink的元数据,这就是Hive Catalog的功能...

文章目录内置Hive外部的 Hive代码操作 Hive运行 Spark SQL CLI运行 Spark beeline Apache Hive 是 Hadoop 上的 SQL 引擎,Spark SQL 编译时可以包含 Hive 支持,也可以不包含。包含 Hive 支持的 Spark SQL 可以支持 ...
Hive支持索引,但是Hive的索引与关系型数据库中的索引并不相同,比如,Hive不支持主键或者外键。 Hive索引可以建立在表中的某些列上,以提升一些操作的效率,例如减少Map Reduce任务中需要读取的数据块的数量。 在...
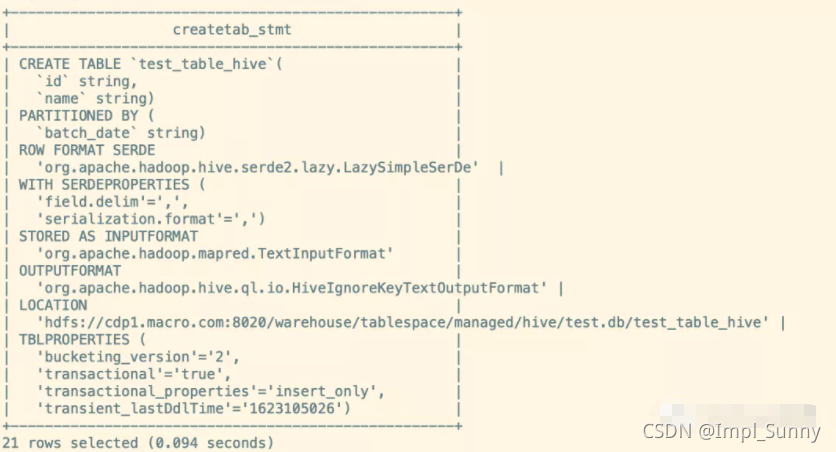
0、前言 HDFS不适合大量小文件的存储,因namenode将文件系统的元数据存放在内存中,因此...本篇文章主要介绍在CDP7.1.6集群中如何对Hive表小文件进行合并。 测试环境: 1.操作系统Redhat7.6 2.CDP7.1.6 3.使用ro.

Spark sql读写hive需要hive相关的配置,所以一般将hive-site.xml文件放到spark的conf目录下。代码调用都是简单的,关键是源码分析过程,spark是如何与hive交互的。 1. 代码调用 读取hive代码

hive中的索引功能是有限的,hive中没有关系数据库中的建的概念,但是还是可以对某一些字段建立索引。 Hive索引的目标是提高对表的某些列进行查询查找的速度。如果没有索引,则使用类似于“WHERE tab1.col1
Hive正则表达式

Hive on Spark VS Spark on Hive 两者概述 Hive on Spark Hive on Spark是由Cloudera发起,由Intel、MapR等公司共同参与的开源项目,其目的是把Spark作为Hive的一个计算引擎,将Hive的查询作为Spark的任务提交到...