
”DataFrame“ 的搜索结果

series是一个一维的列数据,其中每一个元素都有一个标签。 import pandas as pd s = pd.Series([2, 4, 6, 8]) print(s) 结果为,2468为一组列数据,左边的0123是数据的对应标签。
Pandas是Python的数据分析利器,DataFrame是Pandas进行数据分析的基本结构,可以把DataFrame视为一个二维数据表,每一行都表示一个数据记录。本文将介绍创建Pandas DataFrame的6种方法。创建Pandas数据帧的六种方法...



pymysql读取数据库转换为dataframe时报错:ValueError: DataFrame constructor not properly called!
dataframe删除某一行
标签: 经验分享
dataframe**删除某一行 data = data.drop(index=16)
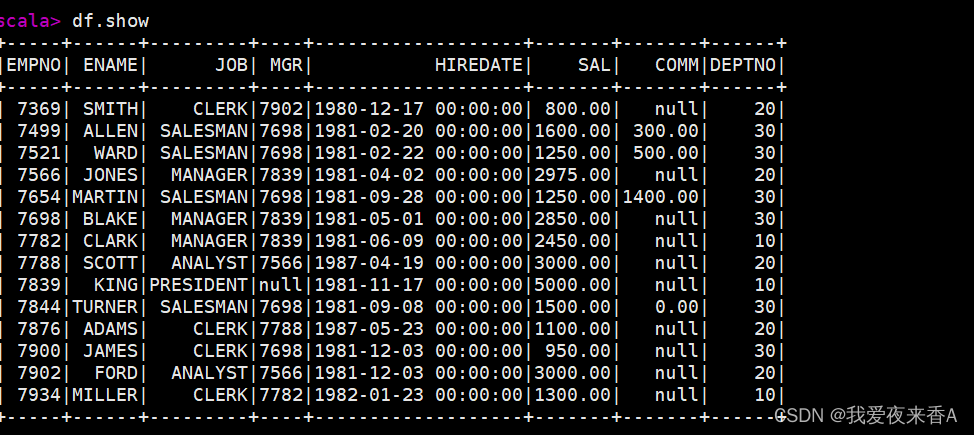
1.按列取、按索引/行取、按特定行列取import numpy as npfrom pandas import DataFrameimport pandas as pddf=DataFrame(np.arange(12).reshape((3,4)),index=['one','two','thr'],columns=list('abcd'))df['a']#取a...

python Dataframe获取n个最大值/n个最小值 在python中,dataframe自身带了nlargest和nsmallest用来求解n个最大值/n个最小值,具体案例如下: 案例1 求最大前3个数 data = pd.DataFrame(np.array([[1,2],[3,4],[5,6],...
1、从RDD创建DataFrame (1)利用元组创建 object _01_SparkSession { def main(args: Array[String]): Unit = { //1、创建spark session val spark: SparkSession = SparkSession.builder().master("local[*]")....

介绍一下 pyspark 的 DataFrame 基础操作。
主要讲述python语言中如何在Pandas的DataFrame中添加一行或者一列。
本文概述我们可以通过以下几种有效地在DataFrame中执行排序:按标签按实际值在解释这两种排序之前, 首先我们必须将数据集用于演示:import pandas as pdimport numpy as npinfo=pd.DataFrame(np.random.randn(10, 2)...

方法修改行索引、列,默认修改行索引,可以指定columns参数修改列索引。使用iloc[row_index, column_index]DataFrame对象提供了rename()先指定某个位置,然后进行赋值即可修改。
本文章向大家介绍Python Pandas DataFrame.values实例讲解,主要分析其语法、参数、返回值和注意事项,并结合实例形式分析了其使用技巧,希望通过本文能帮助到大家理解应用这部分内容。
1、DataFrame数据结构的解释说明 index表示的是行索引,column表示的是列索引,values表示的是数值,其实不管是行索引,还是列索引都可以看作是索引Index。从每一行来看,DataFrame可以看作是一行行的Series...
通过pyqt5的QTableView显示dataframe数据
文章目录前言一、Dataframe排序1. 索引的排序2. 值的排序二、Dataframe去重 前言 本篇文章主要介绍了Python数据分析Pandas Dataframe排序与去重操作: 1、DataFrame 的排序分为两种,一种是对索引进行排序,另一种...
从DAtaFrame的字符串中把数据提取出来

dataframe删除数据的基本操作
spark dataframe派生于RDD类,但是提供了非常强大的数据操作功能。当然主要对类SQL的支持。 在实际工作中会遇到这样的情况,主要是会进行两个数据集的筛选、合并,重新入库。 首先加载数据集,然后在提取数据集的...
【代码】一次性删除DataFrame中为空的各个列。
推荐文章
- javafx预览PDF_javafx pdf-程序员宅基地
- ipv4与ipv6访问_纯ipv4访问纯ipv6-程序员宅基地
- css强制换行-程序员宅基地
- 链霉亲和素修饰的CdSe–ZnS量子点-程序员宅基地
- 饿了么4年 + 阿里2年:研发路上的一些总结与思考-程序员宅基地
- vue的sync语法糖的使用(组件父子传值)_sync传值-程序员宅基地
- 最大流最小割_网络最大流量与割的容量的关系-程序员宅基地
- queryString模块_querystring模块安装-程序员宅基地
- 安卓电量检测工具Battery Historian的使用记录_battery-historian 电量测试-程序员宅基地
- 基于QPSK的载波同步和定时同步性能仿真,包括Costas环的gardner环_qpsk符号同步-程序员宅基地