”Attention“ 的搜索结果
@inproceedings{wiegreffe-pinter-2019-attention, title = "Attention is not not Explanation", author = "Wiegreffe, Sarah and Pinter, Yuval", booktitle = "Proceedings of the 2019 Conference on ...

简单来说,Attention的目的就是要得到所有query和所有key的相关性矩阵,过程的关键是把两者映射到同一个空间,因此映射矩阵W的选取就十分重要了,在深度学习中,这个W是通过参数更新来实现的。
我环境python版本是3.10。
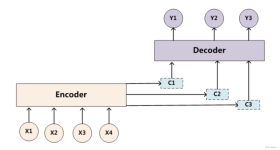
Attention的原理和实现 目标 知道Attention的作用 知道Attention的实现机制 能够使用代码完成Attention代码的编写 1. Attention的介绍 在普通的RNN结构中,Encoder需要把一个句子转化为一个向量,然后在Decoder中...

cnn+lstm+attention对时序数据进行预测 博客链接: https://blog.csdn.net/qq_30803353/article/details/121875376 1、摘要 本文主要讲解:bilstm-cnn-attention对时序数据进行预测 主要思路: 对时序数据进行分块,...
1.由来 在Transformer之前,做翻译的时候,一般用基于RNN的...输入的x1,x2x_{1},x_{2}x1,x2,共同经过Self-attention机制后,在Self-attention中实现了信息的交互,分别得到了z1,z2z_{1},z_{2}z1,z2,将z1,z2
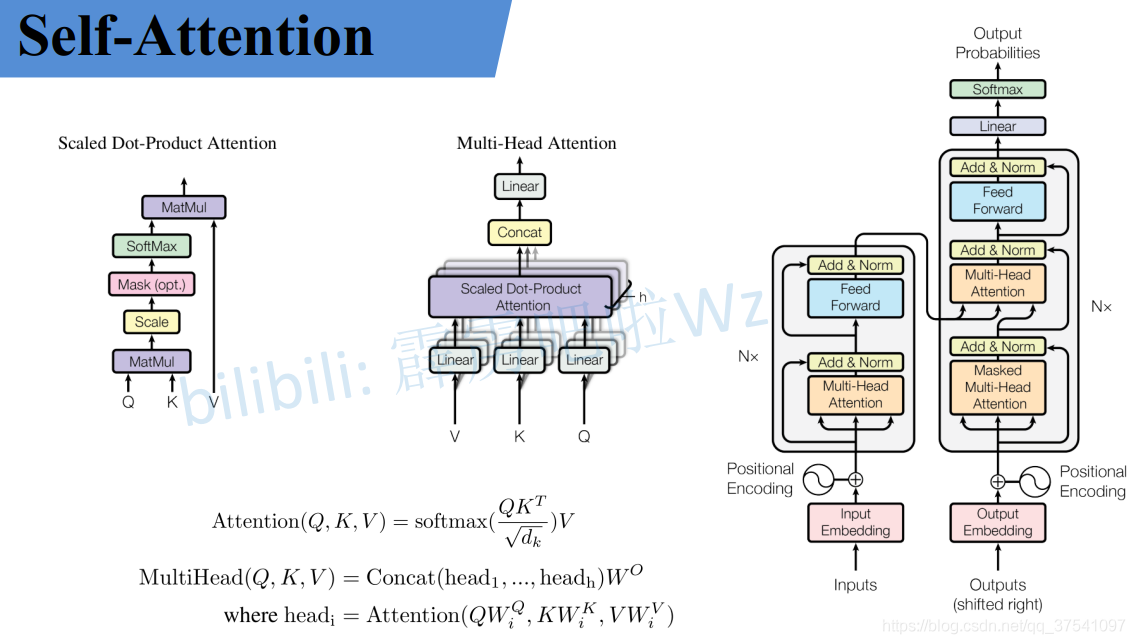
Attention、Self-Attention、Multi-Head Attention概念、代码
这里的attention不是transformer那个,作者的attention是指attention map展示了哪些输入对输出的影响更大,理所当然feature map里值大的对输出影响大,所以这个就是模型对这块输入位置的attention。
Attention 正在被越来越广泛的得到应用。尤其是 BERT 火爆了之后。 Attention 到底有什么特别之处?他的原理和本质是什么?Attention都有哪些类型?本文将详细讲解Attention的方方面面。 Attention 的本质是...
论文“具有自适应Attention-GRU模型的品牌级排名系统[C]”的代码。 (接受IJCAI 2018) 运行命令:python train.py --buckets“ ./data/” --checkpointDir ./log/ --exp debug --m1 1 --m2 0 --m3 1 参数:“ ...
Grouped-Query Attention (GQA) 是对 Multi-Head Attention (MHA) 和 Multi-Query Attention (MQA) 的扩展。通过提供计算效率和模型表达能力之间的灵活权衡,实现了查询头的分组。GQA将查询头分成了G个组,每个组...
探索前沿OCR: Attention OCR的Chinese Version 项目地址:https://gitcode.com/A-bone1/Attention-ocr-Chinese-Version 项目简介 在数字化时代,自动识别并转换图像中的文本(OCR,Optical Character Recognition)...
Attention-BiLSTM模型结构及所有核心代码: 1.model中实验的模型有BiLSTM、ATT-BiLSTM、CNN-BiLSTM模型; Attention与BiLSTM模型首先Attention机制增强上下文语义信息,并获取更深层次特征,最后通过Softmax进行回归...
Attention Is All You Need
SMA-CNN-LSTM-Mutilhead-Attention黏菌算法优化卷积长短期记忆神经网络注意力机制多变量时间序列预测
探索创新的机器学习模型:Multi-Scale Attention 项目地址:https://gitcode.com/sinAshish/Multi-Scale-Attention 在深度学习的世界里,注意力机制(Attention Mechanism)已成为理解和处理复杂数据的关键技术之一。...
为了更准确地提取文本特征并提高化工事故分类的准确性,该文提出了一种基于Attention机制的双向LSTM (BLSTM-Attention)神经网络模型对化工新闻文本进行特征提取并实现文本分类.BLSTM-Attention神经网络模型能够...
基于attention文本分类代码基于attention文本分类代码基于attention文本分类代码
即每个token都会有4个注意力分数,分别对应于其他4个token。...这是Transformer模型中Self-Attention机制的核心部分。如果输入共有5个token,那么对于任意一个token来说,它会有与其他4个token相对应的4个注意力分数。
自关注与文本分类 本仓库基于自关注机制实现文本分类。...$ python imdb_attention.py 比较结果 算法 训练时间(每纪元) Val准确率 Val损失 所需Epoch数 LSTM 116秒 0.8339 0.3815 2 双向LSTM
各种Unet模型用于图像分割的实现-Unet,RCNN-Unet,注意力Unet,RCNN-Attention Unet,嵌套式Unet细分Unet细分-Pytorch-Nest-of-Unets各种Unet模型用于图像分割的实现UNet- U-Net:用于生物医学图像分割的卷积网络...
安装$ pip install local-attention用法 import torchfrom local_attention import LocalAttentionq = torch . randn ( 8 , 2048 , 64 )k = torch . randn ( 8 , 2048 , 64 )v = torch . randn ( 8 , 2048 , 64 )...
基于torch实现cnn+lstm+attention 模型时间序列预测代码模板 通用
$ pip install axial_attention 用法 图像 import torch from axial_attention import AxialAttention img = torch . randn ( 1 , 3 , 256 , 256 ) attn = AxialAttention ( dim = 3 , # embedding dimension
ResNet_Attention(CBAM,SE) 官方说明: , 所需环境Ubuntu20.04 GTX 1080Ti Python3.7 PyTorch 1.7.0 CUDA10.2 CuDNN7.0使用方法(带有CIFAR10的trian) 该模型的主干是ResNet。 在我们的培训中,我们使用CIFAR10...
推荐文章
- C++零碎知识点(一)-程序员宅基地
- 【Python学习笔记】Coursera课程《Python Data Structures》 密歇根大学 Charles Severance——Week5 Dictionary课堂笔记...-程序员宅基地
- v-html 解析字符串到 html 换行显示_html字符串 v-html-程序员宅基地
- 招收跨专业考计算机的学校,跨专业考研,接受跨专业考研的学校。-程序员宅基地
- 数学模型预测模型_改进著名的nfl预测模型-程序员宅基地
- ELK-FileBeat入门_filebeat 6.5.4 - windows-程序员宅基地
- 微信小程序架构图与开发_微信小程序框架图-程序员宅基地
- Node.js 下载与安装教程_node下载-程序员宅基地
- MySQL报错:The server time zone value '�й���ʱ��' is unrecognized or represents more than one time zone_连接失败! the server time zone value ' й ' is-程序员宅基地
- 数学与生活——读书笔记-程序员宅基地