python scrapy爬起招聘网站+可视化_scrapy框架爬取网页并且可视化-程序员宅基地
技术标签: python爬虫
推荐使用插件XPath Helper:
XPath Helper可以支持在网页点击元素生成xpath,整个抓取使用了xpath、正则表达式、消息中间件、多线程调度框架的chrome插件。
最主要的是分析xpath,这是一切的灵魂.
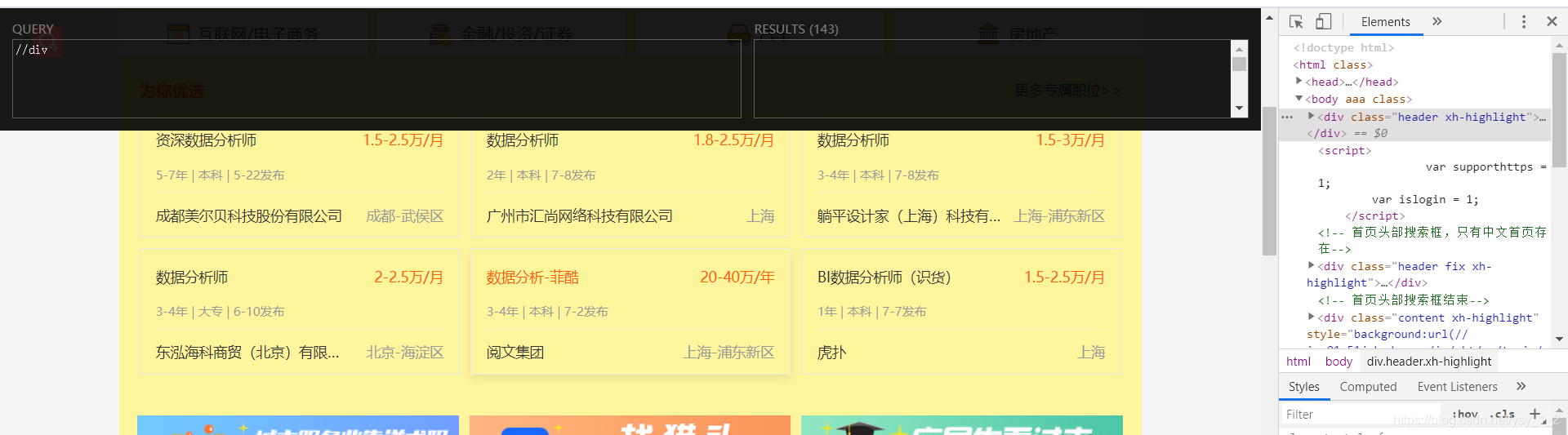
1.创建爬虫项目
scrapy startproject[项目名]
使用命令创建一个爬虫:
scrapy genspider yingcaiwang "域名"
运行爬虫命令
scrapy crawl knowlegde (name名)
创建启动start.py
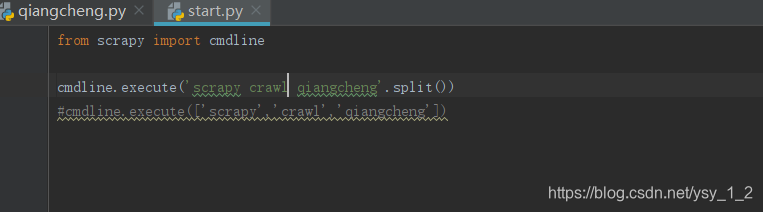
2.目录结构介绍
2.1 items.py:用于存放爬虫爬取下来数据的模型
2.2 middlewares.py: 用于存放各种中间件的文件
2.3 pipelines.py: 用于将items的模型存储到本地磁盘中.
2.4 settings.py:本爬虫的一些配置文件信息(比如请求头、多久发送一次请求、ip代理池等)
2.5 scrapy.cfg: 项目中的配置文件
2.6 spiders包:以后所有的爬虫,都是存在这个里面.
3.开始我的爬虫
先看我的项目结构
直接代码
# -*- coding: utf-8 -*-
import scrapy
from qianchengwuyou.items import QianchengwuyouItem
class QiangchengSpider(scrapy.Spider):
name = 'qiangcheng'
allowed_domains = ['51job.com']
start_urls = ["https://search.51job.com/list/000000,000000,0000,00,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="]
def parse(self, response):
job_list = response.xpath("//div[@class='dw_table']//div[@class='el']/p[1]//span/a/@href").getall()
for i_items in job_list:
yield scrapy.Request(url=i_items,callback=self.jiexi_content,dont_filter=True)
#获取下一页的href
next_pages = response.xpath("//div[@class='p_in']//li[last()]/a/@href").get()
if next_pages:
yield scrapy.Request(url=next_pages,callback=self.parse,dont_filter=True)
def jiexi_content(self,response):
item = QianchengwuyouItem()
item['job_name'] = response.xpath("//div[@class='cn']/h1/text()").extract_first()
try:
item['job_money'] = response.xpath("//div[@class='cn']/strong/text()").extract_first()
except:
item['job_money'] = "面议"
item['job_company'] = response.xpath("//div[@class='cn']//a[1]/text()").extract_first()
#抓取所有工作地点和教育程度
job_all = response.xpath("//div[@class='cn']//p[2]/text()").getall()
#对抓取的列表进行分割取出,列表中包含了工作地点和工作经历和教育程度.
try:
item['job_place'] = job_all[0].strip()
except:
item['job_place'] = ""
# try:
# item['jineng'] = response.xpath("//div[@class='mt10']/p[2]/a/text()").extract()
# except:
# item['jineng'] =""
try:
item['job_experience'] = job_all[1].strip()
except:
item['job_experience'] = '无要求'
try:
item['job_education'] = job_all[2].strip()
except:
item['job_education'] = '不要求'
# try:
# item['import_zi'] = response.xpath('//div[@class="bmsg job_msg inbox"]/div[@class="mt10"]/p[2]/text()').get()
# print(item['import_zi'])
# except:
# item['import_zi'] = '不做要求'
#对所有岗位职责和任务进行提取,都爬取了的,爬取的岗位职责和任职要求
job_content = response.xpath("//div[@class='bmsg job_msg inbox']/p/text()").getall()
job_nz = []
#遍历循环取得岗位职责和任职要求的数据添加到job_nz[]中,在取出数据.
for job_nzs in job_content:
job_nz.append(job_nzs)
try:
item['job_nz'] = job_nz
except:
item['job_nz'] = "上岗安排"
yield item
在setting设置存入数据库和设置请求头:
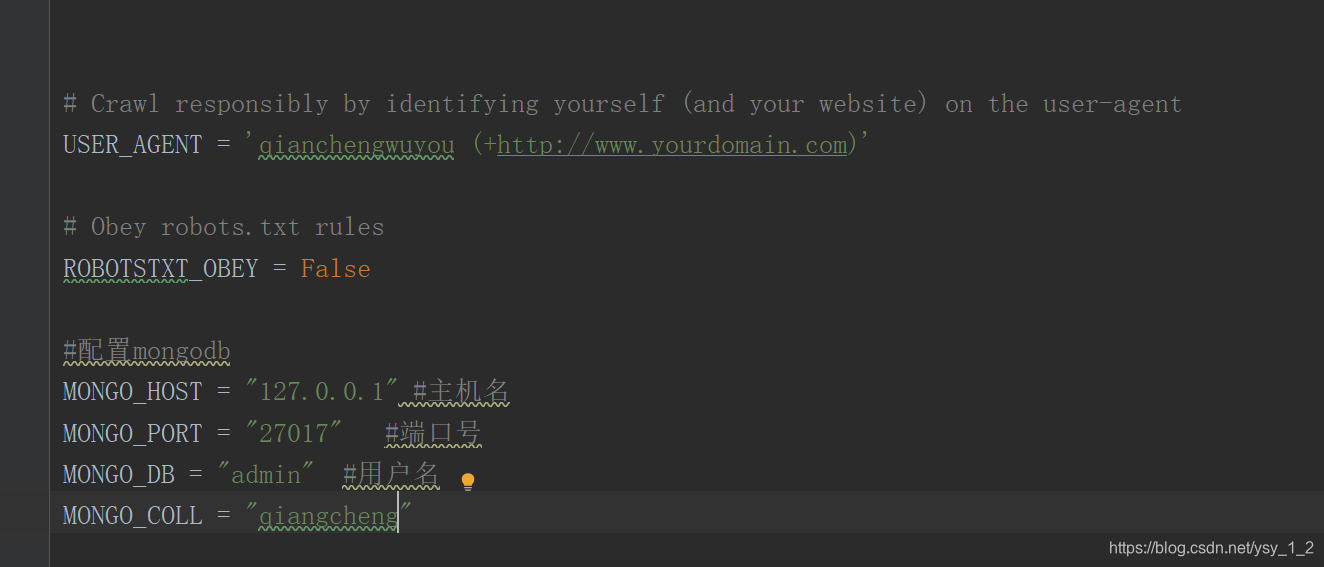

在pipelines.py 存入数据库
import pymongo
from scrapy.utils.project import get_project_settings
settings = get_project_settings()
class QianchengwuyouPipeline:
def init(self):
pass
# 链接数据库
client = pymongo.MongoClient(host=settings[‘MONGO_HOST’], port=settings[‘27017’])
self.db = client[settings[‘MONGO_DB’]] # 获得数据库的句柄
self.coll = self.db[settings[‘MONGO_COLL’]] # 获得collection的句柄
#数据库登录需要账号密码的话
#self.db.authenticate(settings[‘MONGO_USER’], settings[‘MONGO_PSW’])
def process_item(self, item, spider):
pass
postItem = dict(item) # 把item转化成字典形式
self.coll.insert(postItem) # 向数据库插入一条记录
return item # 会在控制台输出原item数据,可以选择不写
def close(self):
close.client.close()
正在爬取数据

存入Mongodb
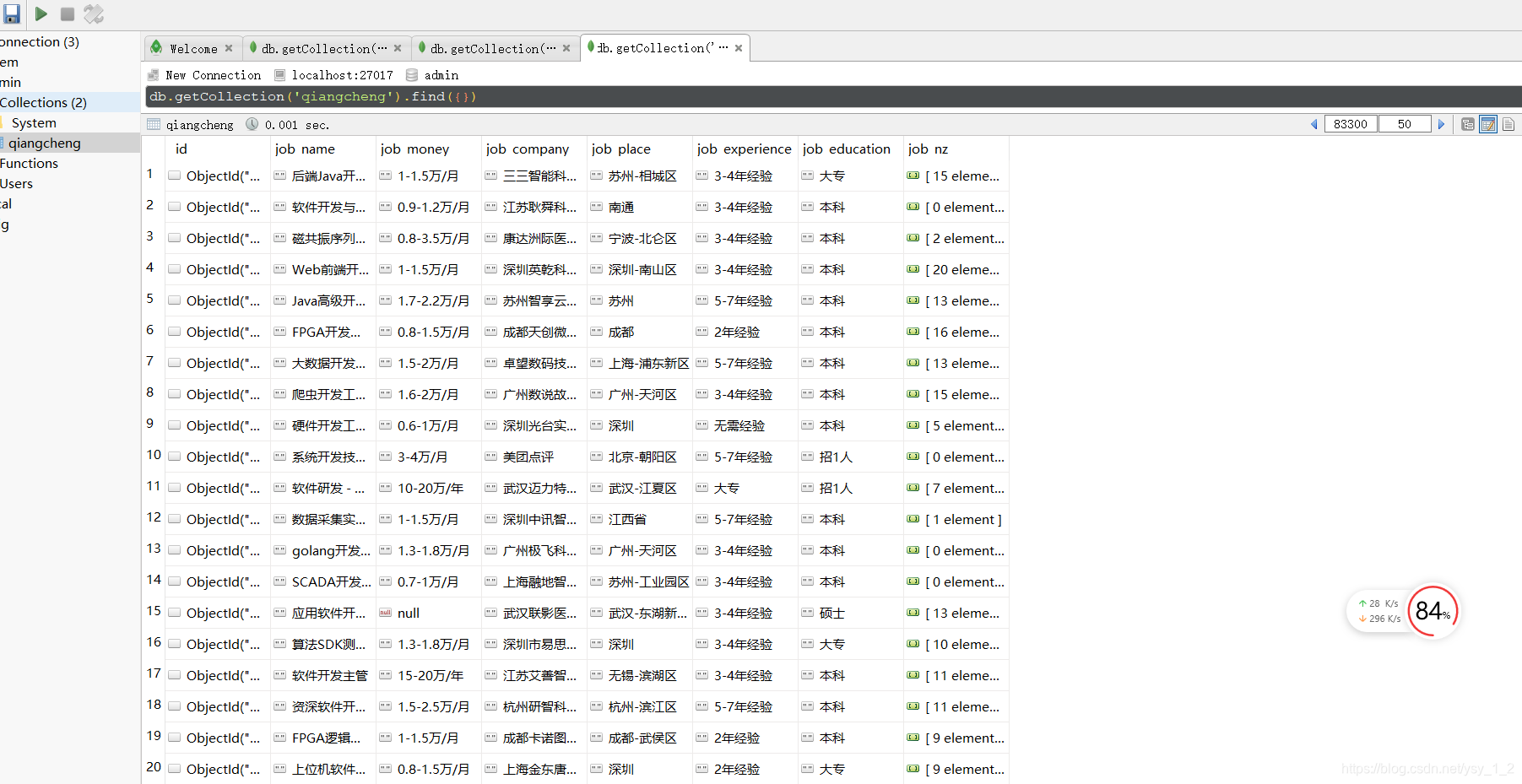
4.对数据做可视化
from pyecharts import options as opts
from pyecharts.charts import Pie
import pymongo
#连接mongodb
client = pymongo.MongoClient("127.0.0.1",port=27017)
#连接数据库
db = client['admin']
#连接表
mytable =db['qiangcheng']
#提取mogodb数据
chengdu ={
"$and": [{
"job_place":{
"$regex":"成都"}},{
"job_name":{
"$regex":"数据采集"}}]}
beijing ={
"$and": [{
"job_place":{
"$regex":"北京"}},{
"job_name":{
"$regex":"数据采集"}}]}
shanghai ={
"$and": [{
"job_place":{
"$regex":"上海"}},{
"job_name":{
"$regex":"数据采集"}}]}
guangzhou ={
"$and": [{
"job_place":{
"$regex":"广州"}},{
"job_name":{
"$regex":"数据采集"}}]}
shengzheng ={
"$and": [{
"job_place":{
"$regex":"深圳"}},{
"job_name":{
"$regex":"数据采集"}}]}
num1 = 0
num2 =0
num3 =0
num4 = 0
num5 =0
for a in mytable.find(chengdu):
if "成都" in a["job_place"]:
num1 += 1
print(num1)
# print("***6***")
for b in mytable.find(beijing):
if "北京" in b["job_place"]:
num2 += 1
# print(num2)
# print("***6***")
for c in mytable.find(shanghai):
if "上海" in c["job_place"]:
num3 += 1
# print(num3)
# print("***6***")
for d in mytable.find(guangzhou):
if "广州" in d["job_place"]:
num4 += 1
# print(num4)
# print("***6***")
for f in mytable.find(shengzheng):
if "深圳" in f["job_place"]:
num5 += 1
# print(num5)
# print("***6***")
x_data =["成都","北京","上海","广州","深圳"]
y_data =[num1,num2,num3,num4,num5]
data_pir = list(zip(x_data,y_data))
pie =Pie()
pie.add(series_name="数据采集地区岗位",data_pair=data_pir)
pie.render("数据采集饼图.html")
5.分析数据饼图
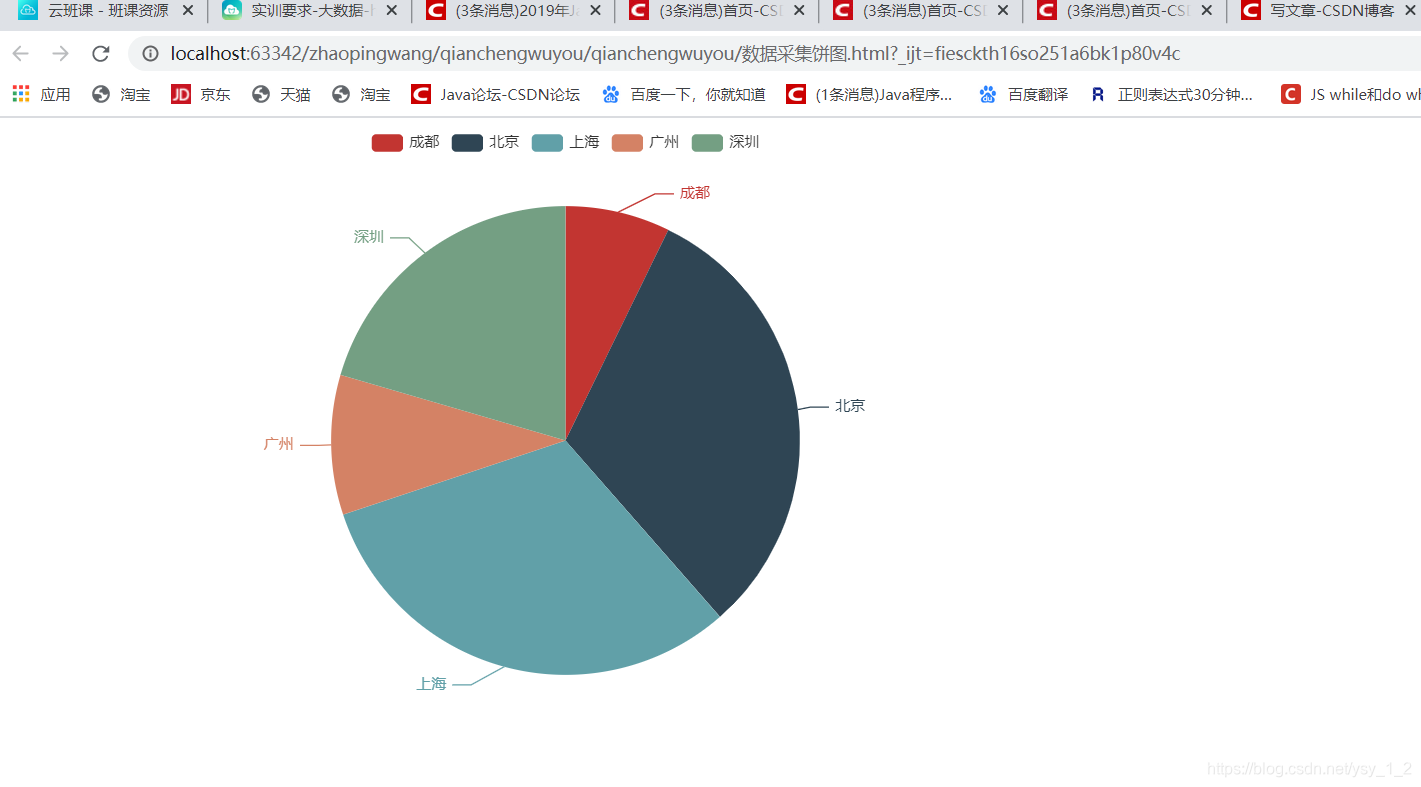
6.分析大数据、数据采集、数据分析、平均工资,最大工资和最小工资分析图
from pyecharts import options as opts
from pyecharts.charts import Bar
import re
import pymongo
#连接mongodb
client = pymongo.MongoClient("127.0.0.1",port=27017)
#连接数据库
db = client['admin']
#连接表
mytable =db['qiangcheng']
#获取mogodb中的数据
#提取mogodb数据
def one_shujufenxi(shujufenxi):
#最高工资
slaray_high = []
for i in mytable.find(shujufenxi):
a = i["job_money"].split("-")[0]
slaray_high.append(float(a))
max_b = max(slaray_high)
min_c = min(slaray_high)
#设置初始值
avg1 = "{:.1f}".format(sum(slaray_high)/len(slaray_high))
ls = [max_b,min_c,float(avg1)]
return ls
def two_dashujugongchengshi(dashujugongchengshi):
# 最高工资
slaray_high = []
for i in mytable.find(dashujugongchengshi):
a = i["job_money"].split("-")[0]
slaray_high.append(float(a))
max_b = max(slaray_high)
min_c = min(slaray_high)
# 设置初始值
avg1 = "{:.1f}".format(sum(slaray_high) / len(slaray_high))
ls = [max_b, min_c, float(avg1)]
return ls
def three_shujucaiji(shujucaiji):
# 最高工资
slaray_high = []
for i in mytable.find(shujucaiji):
a = i["job_money"].split("-")[0]
try:
slaray_high.append(float(a))
except:
continue
slaray_high = sorted(slaray_high,reverse=True)
max_b = slaray_high[0]
min_c = slaray_high[-1]
# 设置初始值
avg1 = "{:.1f}".format(sum(slaray_high) / len(slaray_high))
ls = [max_b, min_c, float(avg1)]
return ls
def tu(y1,y2,y3):
gongzi = ['数据分析','大数据开发','数据采集']
bar = Bar()
bar.add_xaxis(xaxis_data=gongzi)
# 第一个参数是图例名称,第二个参数是y轴数据
bar.add_yaxis(series_name= "最高工资",y_axis=y1)
bar.add_yaxis(series_name="最低工资",y_axis=y2)
bar.add_yaxis(series_name="平均工资",y_axis=y3)
# 设置表的名称
bar.set_global_opts(title_opts=opts.TitleOpts(title='工资分析图',subtitle='工资单位:/月'),toolbox_opts=opts.ToolboxOpts(),)
bar.render("三个地区的数据分析.html")
if __name__ == '__main__':
shujufenxi = {
"$and": [{
"job_money": {
"$regex": "/月"}}, {
"job_name": {
"$regex": "数据分析"}}]}
# print(one_shujufenxi(shujufenxi))
dashujugongchengshi = {
"$and": [{
"job_money": {
"$regex": "/月"}}, {
"job_name": {
"$regex": "大数据工程师"}}]}
# print(two_dashujugongchengshi(dashujugongchengshi))
shujucaiji = {
"$and": [{
"job_money": {
"$regex": "/月"}}, {
"job_name": {
"$regex": "数据采集"}}]}
# print(three_shujucaiji(shujucaiji))
# 最高
y1 = [one_shujufenxi(shujufenxi)[0],two_dashujugongchengshi(dashujugongchengshi)[0],three_shujucaiji(shujucaiji)[0]]
# 最低
y2 = [one_shujufenxi(shujufenxi)[1],two_dashujugongchengshi(dashujugongchengshi)[1],three_shujucaiji(shujucaiji)[1]]
# 平均
y3 = [one_shujufenxi(shujufenxi)[2],two_dashujugongchengshi(dashujugongchengshi)[2],three_shujucaiji(shujucaiji)[2]]
tu(y1,y2,y3)
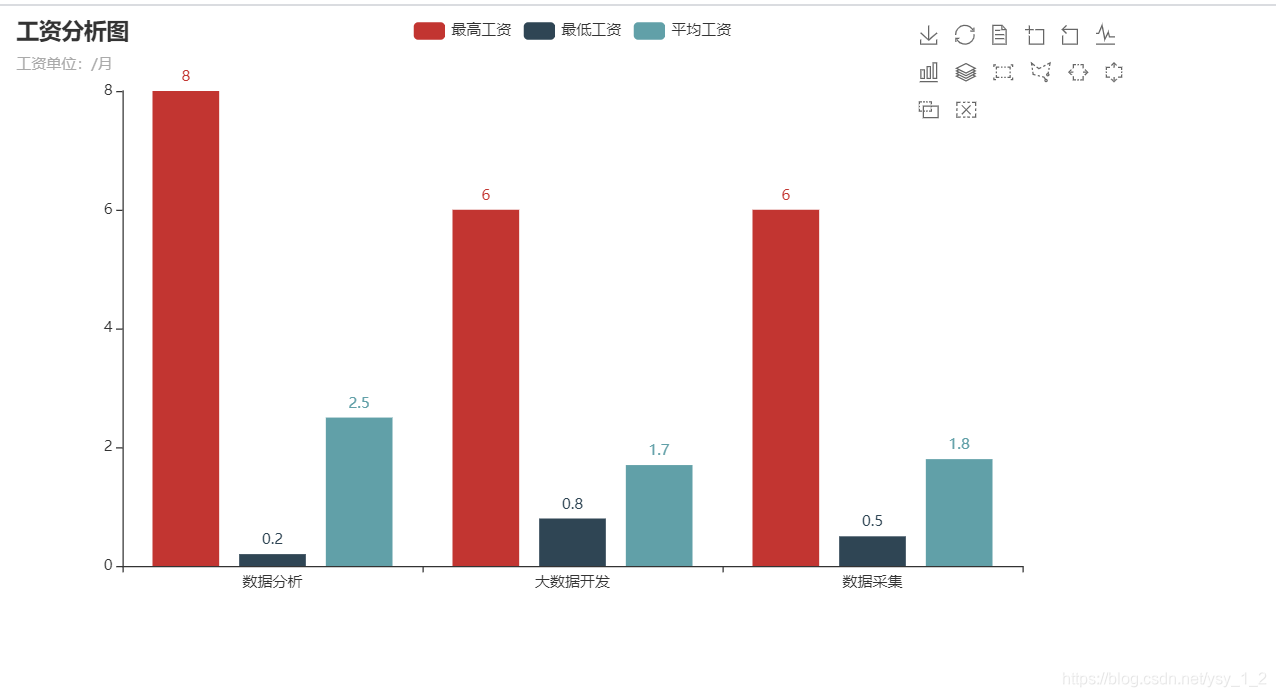
还有分析哪一年的工资薪资图,其实思路都差不多.
最后把数据展示在网页上,我展示的是静态的网页.
智能推荐
Crosstool-NG 编译 riscv64-unknown-elf-gcc-程序员宅基地
文章浏览阅读1.4k次。How to build toolchainenv setup主机环境: ubuntu-20.04.3-desktop-amd64.iso安装包 : sudo apt-get install net-tools openssh-server git vim make gcc gawk bison flex texinfo automake libtool-bin cvs libncurses5-dev ninja-build libglib2.0-dev libpixman-1-dev help_riscv64-unknown-elf-gcc
Python大数据之Python爬虫学习总结——day16 数据可视化_以色列 网络爬虫-程序员宅基地
文章浏览阅读183次。注意: 模块的名称不要以数字开头,不要是关键字,一般都是小写,可以字母数字下划线汉字组成(不建议)举例: 当前模块定义名称为:文件操作# 读取文件中的列表,并且把字符串类型转为列表本身# 写列表数据到文件中。_以色列 网络爬虫
CRM 客户管理系统(SpringBoot+MyBatis)-程序员宅基地
文章浏览阅读6.1k次,点赞10次,收藏90次。点击关注公众号,回复“1024”获取2TB学习资源!一.对CRM的项目的简单描述1.什么是CRMCRM系统即客户关系管理系统,是指企业用CRM技术来管理与客户之间的关系。他的目标是缩减销售..._高净值crm项目 投入产出
HTML5期末大作业:在线电影网站设计——我不是药神电影介绍(4页) HTML+CSS+JavaScript 大二实训大作业HTML源码...-程序员宅基地
文章浏览阅读931次。常见网页设计作业题材有 个人、 美食、 公司、 学校、 旅游、 电商、 宠物、 电器、 茶叶、 家居、 酒店、 舞蹈、 动漫、 明星、 服装、 体育、 化妆品、 物流、 环保、 书籍、 婚纱、 军事、 游戏、 节日、 戒烟、 电影、 摄影、 文化、 家乡、 鲜花、 礼品、 汽车、 其他 等网页设计题目, A..._电影网站设计代码
Gitee Pages个人简历部署(上)-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏7次。利用Gitee Pages服务快速部署个人简历_gitee pages
月入过万的外卖CPS红包小程序源码分享(附搭建教程)_红包封面小程序源码-程序员宅基地
文章浏览阅读2.6k次,点赞3次,收藏11次。大家好,我是老扬,喜欢分享干货。前不久做淘客社群的时候意外发现外卖的收有时会超过做淘客的收入,所以就研究了一下。今天就大概来讲一讲我做外卖推广这段时间的一些经验分享!其实外卖cps和做淘客是同样的原理,你推广,用户下单,你拿佣金,所以简单来说这个项目就可以说是一个淘客项目,而且还需要引流。外卖cps带分销返利源码源代码地址http://www.mybei.cn搭建步骤下载以上源代码到本地http://www.mybei.cn成品展示截图步骤下载以上源代码到本地http://_红包封面小程序源码
随便推点
Spark and Hadoop碎片知识点-程序员宅基地
文章浏览阅读140次。Spark and Hadoop碎片知识点合集
vue自定义指令-程序员宅基地
文章浏览阅读72次。vue自定义指令vue中除了核心功能内置的指令外,也允许注册自定义指令。有的情况下,对普通DOM元素进行底层操作,这时候就会用到自定义指令。自定义指令又分为全局的自定义指令和局部自定义指令。全局自定义指令全局注册主要是用过Vue.directive方法进行注册Vue.directive第一个参数是指令的名字(不需要写上v-前缀),第二个参数可以是对象数据。// 注册一个全局自定义指令 `v-focalize`Vue.directive('focalize', { // 当被绑定的元素插入
小程序的前期学习_一个app包括json js和dll-程序员宅基地
文章浏览阅读407次。根目录下自定义组件新建custom-tab-bar/index把点击的active定义为共享的数据store.js// 创建store实例// 定义共享数据 数据字段activeTabBarIndex:0, //点击的下标})})wxmljsstore,},}},})}},/*** 组件的初始数据*/data: {{"text": "首页",},{"text": "消息",},{"text": "联系我们",},{_一个app包括json js和dll
3、数据类型转换、引用传值(可变类型、不可变类型)-程序员宅基地
文章浏览阅读217次,点赞3次,收藏5次。数据类型转换、引用传值(可变类型、不可变类型)
第十二章:预处理命令-程序员宅基地
文章浏览阅读628次,点赞23次,收藏8次。第十二章:预处理命令宏定义、文件包含处理
SecretFlow安装,10天拿到阿里网络安全岗offer-程序员宅基地
文章浏览阅读343次,点赞5次,收藏8次。虫、UE5、UI设计、Unity3D、Web前端开发、产品经理、车载开发、大数据、鸿蒙、计算机网络、嵌入式物联网、软件测试、数据结构与算法、音视频开发、Flutter、IOS开发、PHP开发、.NET、安卓逆向、云计算**对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。,朋友们如果有需要全套《网络安全入门+黑客进阶学习资源包》,可以扫描下方二维码领取(如遇扫码问题,可以在评论区留言领取哦)~还有大家最喜欢的黑客技术。