icassp2020--TEXT-INDEPENDENT SPEAKER VERIFICATION WITH ADVERSARIAL LEARNING ON SHORT UTTERANCES_graph attentive feature aggregation for text-indep-程序员宅基地
技术标签: icassp2020
TEXT-INDEPENDENT SPEAKER VERIFICATION WITH ADVERSARIAL LEARNING ON SHORT UTTERANCES
Kai Liu, Huan Zhou
Artificial Intelligence Application Research Center, Huawei Technologies Shenzhen, PRC
ABSTRACT
摘要
A text-independent speaker verification system suffers severe performance degradation under short utterance condition. To address the problem, in this paper, we propose an adversari- ally learned embedding mapping model that directly maps a short embedding to an enhanced embedding with increased discriminability. In particular, a Wasserstein GAN with a bunch of loss criteria are investigated. These loss functions have distinct optimization objectives and some of them are less favoured for the speaker verification research area. Dif- ferent from most prior studies, our main objective in this study is to investigate the effectiveness of those loss criteria by con- ducting numerous ablation studies. Experiments on Voxceleb dataset showed that some criteria are beneficial to the veri- fication performance while some have trivial effects. Lastly, a Wasserstein GAN with chosen loss criteria, without fine- tuning, achieves meaningful advancements over the baseline, with 4% relative improvements on EER and 7% on minDCF in the challenging scenario of short 2second utterances.
与文本无关的说话人验证系统在短语音条件下性能严重下降。为了解决这一问题,本文提出了一种敌方学习的嵌入映射模型,该模型直接将短嵌入映射到具有更高可分辨性的增强嵌入。特别地,研究了具有一系列损耗准则的Wasserstein GAN。这些损失函数具有明显的优化目标,其中一些函数不太适合于说话人验证领域。与以往的研究不同,本研究的主要目的是通过大量的消融研究来探讨这些丧失标准的有效性。在Voxceleb数据集上的实验表明,一些准则有利于验证性能的提高,而一些准则的影响较小。最后,一个Wasserstein GAN在没有微调的情况下选择了损耗标准,在较短的2秒话语的挑战性场景中,与基线相比取得了有意义的进步,EER相对提高了4%,minDCF相对提高了7%。
- INTRODUCTION
一。导言
Text-independent Speaker Verification (SV) aims to automat- ically verify the identity of a speaker, given enrolled speaker record and some test speech signal (with no special constraint on phonetic content). The most important step in the SV pipeline is to map speech of arbitrary duration into speaker representation of fixed dimension. It’s desirable for such a speaker representation to be compact, discriminative and ro- bust to extrinsic and intrinsic variations.
文本无关说话人验证(SV)的目的是自动验证说话人的身份,给定注册的说话人记录和一些测试语音信号(对语音内容没有特殊限制)。SV管道中最重要的一步是将任意持续时间的语音映射成固定维数的说话人表示。这样一个说话人的表现形式应该是紧凑的,有区别的,并且是外部和内在变化的。
Several types of speaker representations have been de- veloped over the past decades. The well-known i-vector [3] has been the state-of-the-art speaker representation, usually associated with a simple cosine-scoring strategy or more powerful probability linear discriminant analysis (PLDA) [12, 4] as verifier. With the advent of deep neural networks (DNNs), a variety of DNN frameworks and loss functions have been developed to learn deep speaker representations, known as embeddings. By training these networks with either
在过去的几十年里,有几种类型的说话人表征已经发展出来。众所周知的i向量[3]是最先进的说话人表示,通常与简单的余弦评分策略或更强大的概率线性判别分析(PLDA)[12,4]作为验证器相关联。随着深度神经网络(DNNs)的出现,人们开发了各种DNN框架和损失函数来学习深度说话人表示,称为嵌入。通过训练这些网络
the cross-entropy loss, or some form of contrastive loss on large amount of data, the resulting embeddings are speaker- discriminative. Compared to the i-vector, those embeddings, such as x-vector[2] and GhostVLAD-aggregated embedding [18] (or G-vector for short), are promising, demonstrating competitive performance for long speeches and distinct ad- vantage for short speeches. Furthermore, the recently devel- oped G-vector further shows considerable gains over x-vector for noisy test conditions, which makes it more favorable for a practical SV system.
交叉熵损失,或者对大量数据的某种形式的对比损失,导致的嵌入是说话人识别的。与i-向量相比,x-向量[2]和ghostflad聚合嵌入[18]等嵌入技术具有广阔的应用前景,表现出了长语音的竞争性和短语音的独特优势。此外,最近发展起来的G矢量在噪声测试条件下比x矢量有更大的增益,这使得它更适合于实际的SV系统。
[18] Weidi Xie, Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Utterance-level aggregation for speaker recognition in the wild. In ICASSP, pages 5791– 5795, 2019. 牛津的
However, the performance of a SV system usually de- grades in real scenarios, due to prevalent mismatches between development and test condition, such as channel, domain or duration mismatch [11, 5, 18]. For instance, it has been ob- served [5] that on NIST-SRE 2010 test set (female part), the performance of i-vector/PLDA system drops from 2.48% to 24.78% when the verification trial was shortened from full- duration to 5 seconds long.
然而,由于开发和测试条件之间普遍存在不匹配,例如通道、域或持续时间不匹配,SV系统的性能在实际场景中通常会降低[11、5、18]。例如,在NIST-SRE 2010测试集(女性部分)上,当验证试验从完整持续时间缩短到5秒时,i-vector/PLDA系统的性能从2.48%下降到24.78%。
Numerous research studies have been proposed to miti- gate the short duration effect. An early family of researches aimed to modify different aspects of i-vector based SV sys- tem, e.g., feature extraction techniques, intermediate param- eter estimation, speaker model generation, score normaliza- tion techniques, as summarized in [11]. Recently, more novel deep learning technologies are explored. For instance, in- sufficient phonetic information is compensated by a teacher- student learning framework [17] and scoring scheme is cal- ibrated by transfer learning [13]. Another research strategy is to design duration robust speaker embeddings to dealing with utterances of arbitrary duration. By applying different neural network architectures and alternative loss functions, the discriminability of embeddings is further enhanced. For example, Inception Net with triplet loss is depolyed in [20], Inception-ResNet with joint softmax and center loss in [8] and ResCNN with novel speaker identity subspace loss in [14].
许多研究已经提出方法来缓解这种短时效应。早期的一系列研究旨在修改基于i-向量的SV系统的不同方面,例如特征提取技术、中间参数估计、说话人模型生成、分数规范化技术,如[11]所述。近年来,越来越多的新型深度学习技术被开发出来。例如,充分的语音信息由师生学习框架[17]进行补偿,评分方案由迁移学习[13]进行校准。另一种研究策略是设计持续时间鲁棒的说话人嵌入来处理任意持续时间的话语。通过采用不同的神经网络结构和交替损耗函数,进一步提高了嵌入的可分辨性。例如,在[20]中,具有三重态损失的起始网被去分解,在[8]中,具有联合软最大值和中心损失的起始ResNet和在[14]中具有新的说话人身份子空间损失的ResCNN。
[11] A. Poddar, M. Sahidullah, and G. Saha. Performance comparison of speaker recognition systems in presence of duration variability. In 2015 Annual IEEE India Conference (INDICON), pages 1–6, Dec 2015.
[13] Lihong Wan Jun Zhang Qingyang Hong, Lin Li and Feng Tong. Transfer learning for speaker verification on short utterances. In Interspeech, pages 1848–1852, 2016.
[20] Chunlei Zhang and Kazuhito Koishida. End-to-end text-independent speaker verification with triplet loss on short utterances. In Interspeech, pages 1487–1491, 2017.
[8] Na Li, Deyi Tuo, Dan Su, Zhifeng Li, and Dong Yu. Deep discriminative embeddings for duration robust speaker verification. In Interspeech, pages 2262–2266, 2018.
[14] Xinyuan Cai Ruifang Ji and Bo Xu. An end-to-end text- independent speaker identification system on short ut- terances. In Interspeech, pages 3628–3632, 2018.
Generative Adversarial Networks (GANs) [6] are one of the most popular deep learning algorithm developed recently. GANs have the potential to generate realistic instances and provide a solution to problems that require a generative so- lution, most notably in various image-to-image translation tasks.
生成性对抗网络(GANs)[6]是近年来发展起来的最流行的深度学习算法之一。GANs有可能生成真实的实例,并为需要生成解决方案的问题提供解决方案,尤其是在各种图像到图像的翻译任务中。
[6] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Sys- tems 27, pages 2672–2680. 2014. 这个是GAN的提出论文,是Ian Goodfellow搞出来的。
In this study, we aim to investigate the short duration is-sue presented in a practical SV system. Contrary to the most techniques mentioned above, our proposed approach works directly on the speaker embeddings. In particular, given short and long embedding pairs extracted from same speaker and session, we propose to use adversarial learning of Wasser- stein GAN to learn a new embedding with enhanced discrim- inability. To test our approach, G-vector is chosen as the em- bedding benchmark in our experiments due to its promising performance on short speeches. This put forward a challenge to our study than those prior studies which benchmarked with the i-vectors.
在本研究中,我们的目的是探讨在实际的SV系统中所呈现的短持续时间。与上述大多数技术相反,我们提出的方法直接作用于说话人嵌入。特别是,在给定从同一说话人和会话中提取的短嵌入对和长嵌入对的情况下,我们提出利用Wasser-stein-GAN的对抗性学习来学习一种新的嵌入方法。为了测试我们的方法,在我们的实验中选择了G-vector作为embedding的基准,因为它在短语音中有很好的表现。这对我们的研究提出了一个挑战,比以前的那些以i-向量为基准的研究提出了挑战。
The remainder of this paper is organized as follows: Sec- tion 2 briefly introduces the related works of our methods. Section 3 details our proposed Wassertein GAN based ap- proach. Section 4 presents experimental results and discus- sions. Finally, our conclusions are given in Section 5.
本文的其余部分安排如下:第二节简要介绍了本文方法的相关工作。第三节详细介绍了我们提出的基于Wassertein-GAN的ap-proach。第四节介绍了实验结果和讨论。最后,第5节给出了我们的结论。
- RELATEDWORKS
2.1. Wasserstein-GAN
GANs [6] are deep generative models comprised of two net- works, a generator and a discriminator. The discriminator D tries to learn the difference between real sample y and fake sample g generated from noise η, and the generator G tries to fool the discriminator. That is, the following minimax loss function is optimized through alternating optimization, until equilibrium is reached.
GANs[6]是由两个网络、一个生成器和一个鉴别器组成的深度生成模型。鉴别器D试图学习噪声η产生的真样本y和假样本g之间的差别,而生成器g试图愚弄鉴别器。也就是说,通过交替优化来优化下面的极大极小损失函数,直到达到平衡。公式(1)
However, training a GAN model is difficult due to well- known diminishing or exploding gradients issue. The issues has been addressed by Wasserstein GAN (WGAN) [1], where the discriminator is designed to find a good fw and a new loss function is configured as measuring the Wasserstein distance:
然而,由于众所周知的梯度递减或爆炸问题,训练GAN模型是困难的。Wasserstein GAN(WGAN)[1]已经解决了这些问题,其中鉴别器被设计成寻找良好的fw,并且新的损耗函数被配置成测量Wasserstein距离:公式如下:
[1] Mart ́ın Arjovsky, Soumith Chintala, and Le ́on Bot- tou. Wasserstein gan. ArXiv, 2017. URL: https://arxiv.org/pdf/1701.07875.pdf.
2.2. Deployments of GANs inSV
SV中GANS的部署

Motivated by the remarkable success in image-to-image translation, GANs have been actively deployed in SV re- search community, mainly to handle domain-mismatch issue, like transforming i-vectors [15] and x-vectors [19]. In con- trast, there are few works to use GANs to handle the short du- ration issue. To authors’ best knowledge, the only published work is to propose compensating the i-vectors via conditional GAN [7]. However, limited performance improvements were observed. The proposed system alone failed to outperform the baseline system, and only score-wise fusion based system showed better performance than the baseline.
由于在图像到图像转换方面取得了显著的成功,GANs被积极地部署在SV搜索社区中,主要用于处理域失配问题,如转换i-向量[15]和x-向量[19]。相反,很少有作品使用GANs来处理短语音问题。据作者所知,唯一发表的工作是提出通过条件GAN补偿i-向量[7]。然而,观察到的性能改进有限。单系统的性能没有优于基线系统,只有融合系统的性能优于基线系统。
[19] Man-Wai Mak Youzhi Tu and Jen-Tzung Chien. Varia- tional domain adversarial learning for speaker verifica- tion. In Interspeech, pages 4315–4319, 2019.
[7] Nakamasa Inoue Jiacen Zhang and Koichi Shinoda. I- vector transformation using conditional generative ad- versarial networks for short utterance speaker verifica- tion. In Interspeech, Hyderabad, pages 3613–3617, 2018.
In authors’ opinion, training GAN is non-trivial, the rea- son behind such results might be the oversight on effects of loss functions of conditional GAN. As such, in this study, we investigate the problem and seek to reveal some guidelines on choosing beneficial loss functions to make the model perform better.
在作者看来,训练GAN是非常重要的,这种结果背后的原因可能是对条件GAN损失函数的影响的疏忽。因此,在本研究中,我们探讨了这个问题,并试图揭示一些选择有利损失函数的准则,以使模型表现得更好。
- PROPOSED APPROACH
The architecture of our proposed approach is illustrated in Fig.1. Here x and y are D-dimensional G-vectors correspond- ing to short and long utterance embedding from same speaker session, z is speaker identity labels. With given x, y, z, the proposed system is trained to learn a D-dimensional embed- ding g, with the expectation that the g-based SV system can outperform the one based on x.
我们提出的方法的架构如图1所示。这里x和y是D维G-vectors,对应于同一说话人会话中嵌入的短、长话语,z是说话人身份标签。在给定x,y,z的情况下,训练系统学习D维的嵌入g,期望基于g的SV系统能优于基于x的SV系统。
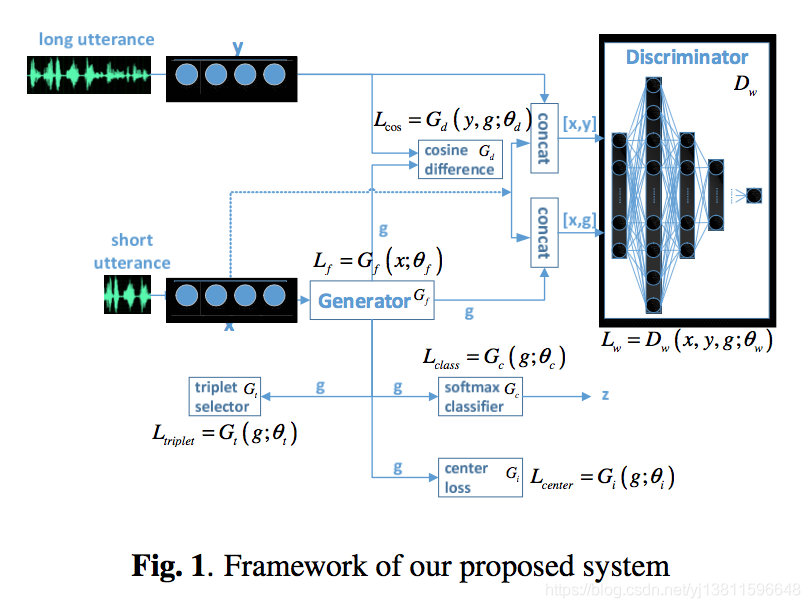
Overall, the proposed architecture can be decomposed into four core components: embedding generator Gf , speaker label predictor Gc, distance calculator Gd and Wasserstine discriminator Dw . All components are jointly trained in order to generate enhanced embeddings with carefully handcraft optimization objects, as described as follows.
总体而言,该架构可以分解为四个核心组件:嵌入生成器Gf、说话人标签预测器Gc、距离计算器Gd和Wasserstine鉴别器Dw。所有组件都经过联合训练,以便使用精心设计的手工优化对象生成增强的嵌入,如下所述。
3.1. Proposed Discriminator-Related Loss Functions
我们提出的判别性相关的损失函数
As aforementioned, the primary task of the proposed ap- proach is to learn embedding with enhanced discriminability. Let P denote the data distribution, we propose to achieve the task by mapping Pg from initial Px to the target Py by adver- sarial learning of WGAN. To this end, in the discriminative model, several loss criteria are investigated with different optimization objectives.
如前所述,所提出的方法的主要任务是学习增强过的具有判别性的嵌入。假设P表示数据分布,我们建议通过WGAN的adver-sarial学习将Pg从初始Px映射到目标Py来完成任务。为此,在判别模型中,研究了具有不同优化目标的几种损失准则。
Following the conventional definition of min-max function, the loss function of WGAN is:
根据最小最大功能的传统定义,WGAN的损失函数为:
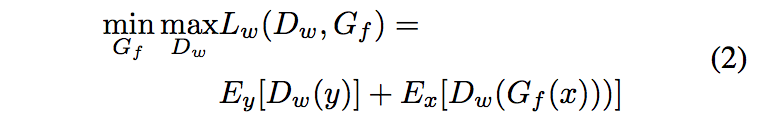
Inspired by the idea of conditional GAN [10], in this study, we investigate a novel loss function by optimizing the Wassertein distance between joint data distributions. That is, to control the data to be discriminated by concatenating short embedding x with the conventional discriminator input. The corresponding min-max function is updated as:
[10] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. ArXiv, 2014. URL: https://arxiv.org/pdf/1411.1784.pdf.
在本研究中,受条件GAN的启发,我们通过优化联合数据分布之间的Wassertein距离,研究了一种新的损失函数。也就是说,通过将短嵌入x与传统的鉴别器输入串联来控制要鉴别器化的数据。相应的min max函数更新为:
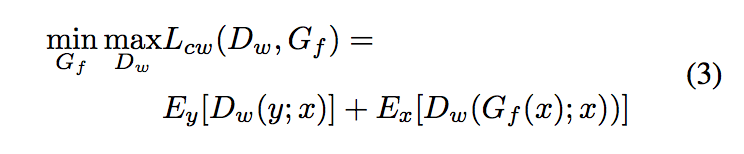
In addition, to seek more discriminability, the Fre ́chet In- ception Distance (FID) [9], as a popular metric to calculate the distance between feature vectors of real and generated im- ages, is also explored herein. Assuming Py and Pg as normal distributions with means μy , μg and co-variance matrices Cy , Cg , FID loss can be calculated by:
此外,为了寻求更高的可分辨性,本文还探讨了Fréchet-In-ception Distance(FID)[9]作为计算真实图像和生成图像特征向量之间距离的常用度量。假设Py和Pg为正态分布,平均值为μy,μg,协方差矩阵为Cy,Cg,FID损失可通过以下公式计算:
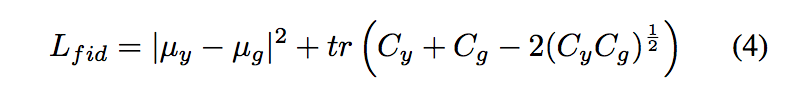
3.2. Proposed Generator-Related Loss Functions
我们提出的Generator相关的损失函数
In order to guide GAN training with the objective of feature discriminability, four loss criteria are investigated herein as extra training guides for the GAN training.
为了以特征判别性为目的指导GAN训练,本文研究了四种loss准则作为GAN训练的附加训练准则。
To verify the speaker label, the widely adopted multiclass cross-entropy (CE) loss is investigated with formulation of:
为了验证说话人标签,研究了广泛采用的多类交叉熵(CE)损失,公式如下:
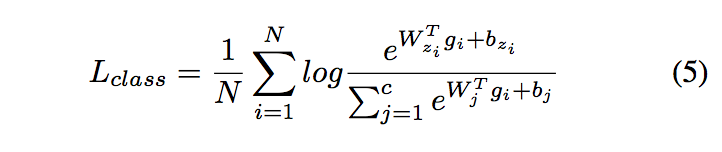
where N is the batch size, c is the number of classes. gi de- notes the i-th generated embedding sample and zi is the cor- responding label index. W ∈ RD∗c and b ∈ Rc denotes the weight matrix and bias in the project layer.
其中N是批处理大小,c是类的数量。gi 表示第i个生成的嵌入样本和zi是对应的标签索引。W∈RD*c和b∈Rc表示项目层中的权重矩阵和偏差。
To explicitly penalize the class-related classification error, triplet loss is deployed as well, where a baseline (anchor) in- put is compared to a positive (truthy) input and a negative (falsy) input. Let Γ be the set of all possible embedding triplets γ = (ga , gp , gn ) in the training set, the loss is defined as:
为了显式地惩罚与类相关的分类错误,还采用了三元组loss,其中基线(锚)输入与正(truthy)输入和负(falsy)输入进行比较。设Γ为训练集中所有可能嵌入三元组的集合γ=(ga,gp,gn),其损失定义为:
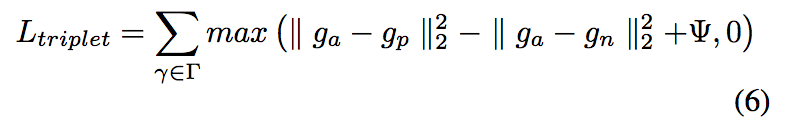
where ga is an anchor input, gp is a positive input from the same class and gn is a negative input from a different class, Ψ ∈ R+ is safety margin between positive and negative pairs.
其中ga是锚输入,gp是同一类的正输入,gn是不同类的负输入,Ψ∈R+是正负对之间的安全角度。
Apart from the above, to minimize intra-class variation, center loss [16] is also adopted. It can be formulated as:
除此之外,为了最小化类内变化,还采用了中心损失[16]。它可以表述为:
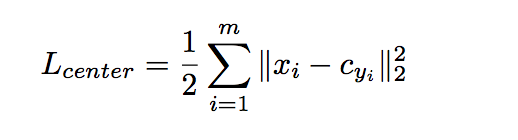
where c
其中c
denotes the ith deep feature belonging to the yith class and m is the size of mini-batch.
表示属于yith类的第i个深特征,m是小批量的大小。
To better guide the training process, the similarity be- tween enhanced embedding and its target is explicitly con- sidered. It’s measured by the cosine distance and evaluated as a dot product as follow:
为了更好地指导训练过程,明确考虑了增强嵌入与目标之间的相似性。它是由余弦距离测量的,并作为点积计算,如下所示:
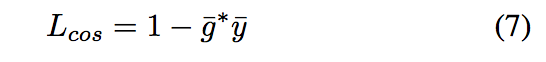
where g ̄ and y ̄ are normalized version of embedding g and y, respectively.
其中ḡ和ȳ分别是嵌入g和y的规范化版本。
In all, we propose to train the generator Gf with the total loss defined as:
总之,我们建议训练generator Gf时的total loss 定义为:
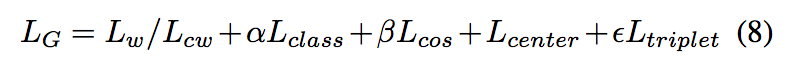
and discriminator Dw with:
和鉴别器Dw:
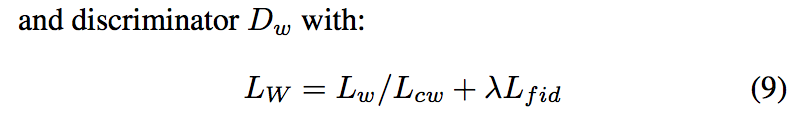
After the training of WGAN, the generative model Gf is retained. At the SV test stage, a short embedding x for any given test short utterance, can be easily mapped to its enhanced version (g) by directly applying the feed-forward model of Gf on the x.
经过WGAN训练后,保留了生成模型Gf。在SV测试阶段,通过直接在x上应用Gf的前向模型,可以很容易地将任意给定测试短句的短嵌入x映射到其增强版本(g)。
- EXPERIMENTS AND RESULTS
四。实验和结果
This section details our experimental setups and investigation results on the effectiveness of the above proposed loss criteria.
本节详细介绍了我们的实验装置和对上述loss准则有效性的调查结果。
4.1. Experimental Setup
We use a subset of the Voxceleb2 to train our proposed sys- tem, where 1,057 speakers are chosen with total 164,716 ut- terances. Those utterances are randomly cut to 2 seconds as short utterance. Similarly, a subset of Voxceleb1 with 40 speakers is sampled and total 13,265 utterance pairs are used for testing.
我们使用Voxceleb2的一个子集来训练我们提出的系统,其中1057个说话人被选择,总共164716个话语。这些话语被随机缩短为2秒作为简段语音。类似地,对40个说话人的Voxceleb1子集进行采样,并使用总共13265个话语对进行测试。
The VGG-Restnet34s network is used to extract G-vectors as our baseline system. Regarding the GAN training, the learning rates for both Gf and Dw are 0.0001; Adam op timization is adopted; weight clipping is employed for Dw with threshold setting from -0.01 to 0.01 and batch size is set as 128.
使用VGG-Restnet34s网络提取G向量作为我们的基线系统。对于GAN训练,Gf和Dw的学习率均为0.0001;采用Adam-op优化;Dw采用权值剪裁,阈值设置为-0.01到0.01,批设置为128。
4.2. Ablation Studies on Various Loss Functions
不同损失函数的ablation消融研究
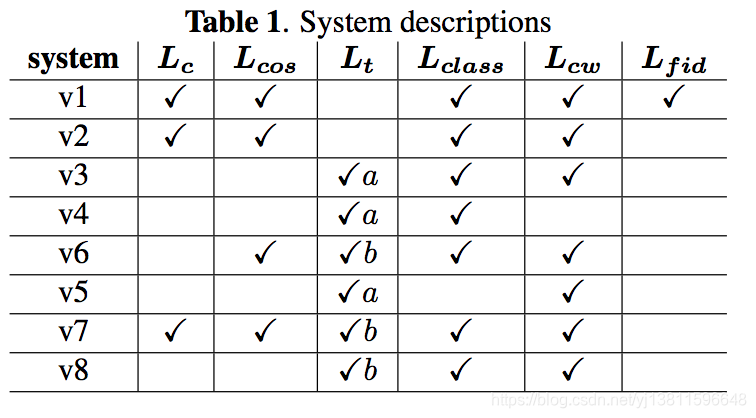
To verify the importance of proposed loss criteria, a bunch of ablation studies are conducted by choosing different com- binations of them. The overall results are illustrated in Tab.1, where Lc, Lt denote Lcenter and Ltriplet, respec- tively. Triplet a means that inputs are sampled from both y and g and b means from g only.
为了验证提出的ablation准则的重要性,我们选择了不同的ablation准则组合进行了大量的ablation研究。总体结果如表1所示,其中Lc,Lt分别表示Lcenter和Ltriplet。三元组a表示输入同时从y和g采样,b表示仅从g采样。
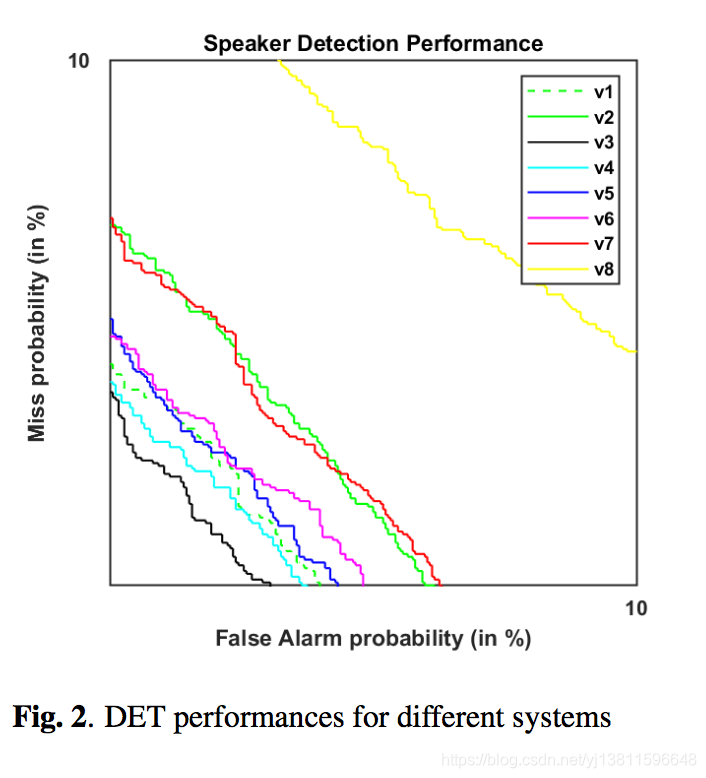
In our study, total 8 systems (v1 − v8), by combining different loss criteria with Watterstein GAN, are evaluated. Their corresponding detection error trade-off (DET) curves are plotted in Fig.2.
在我们的研究中,通过将不同的损失标准与Watterstein GAN相结合,对总共8个系统(v1-v8)进行了评估。相应的检测误差权衡(DET)曲线如图2所示。
From the above experimental results, the following con-
从以上实验结果来看,下面是-
clusions could be drawn:
可以得出结论:
• FID loss has positive effect (v1 vs. v2);
• Conditional WGAN outperforms WGAN (v3 vs. v4);
• Triplet loss is preferred (v7 vs. v2);
• Triplet a greatly outperforms triplet b (v3 vs. v8);
• softmax has positive effect (v3 vs. v5);
• Center loss has negative effect (v6 vs. v7);
• Cosine loss has significant positive effect (v6 vs. v8).
The above findings are very interesting with a twofold out- come. Firstly, it demonstrates that additional training func- tions (e.g. traditional softmax, cosine loss and triplet loss) all have positive contribution to the performance, which verifies our earlier statement that extra training guides might be help- ful for feature discriminability. Secondly, some less-favoured
以上的发现非常有趣,有两个方面。首先,证明了附加的训练函数(如传统的softmax、余弦损失和三重态损失)对性能都有积极的贡献,这验证了我们之前的观点,即附加的训练指南可能有助于提高特征的可分辨性。其次,一些不太受欢迎的
loss criteria to a typical SV system (e.g. FID loss and con- ditional WGAN loss) are surprisingly helpful, which are un- usual findings and might be worthy of further investigation.
典型SV系统的损失标准(如FID损失和常规WGAN损失)出人意料地有用,这是不常见的发现,可能值得进一步研究。
4.3. Comparison with the Baseline System
In the end, we make a performance comparison between our best system (v3) and the G-vector baseline system. Herein the comparison is measured in terms of equal error rate (EER) and minDCF. The results are reported in Tab.2.
最后,我们对最佳系统(v3)和G矢量基线系统进行了性能比较。在此,以等错误率(EER)和minDCF来测量比较。结果见表2。
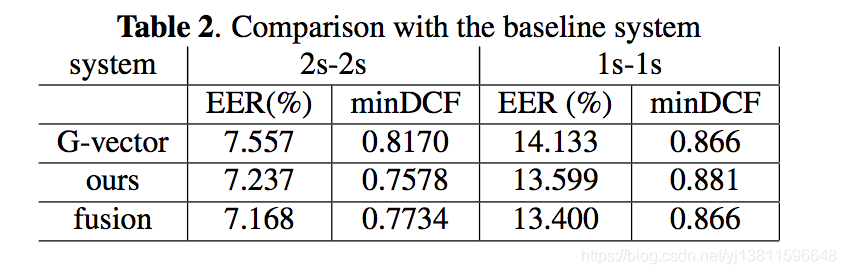
From the table, we can see that our proposed system also has the merit for generalization and behave consistently for different short duration over the baseline system. In detail, for verification with 2 second enroll-test utterances, our proposed system shows 4.2% relative EER improvement and 7.2% rela- tive minDCF improvement. For shorter utterances with dura- tion of 1 second, it shows comparable EER (3.8%) improve- ment.
从表中可以看出,我们提出的系统也具有泛化的优点,并且在不同的短时间内与基线系统保持一致。详细地说,对于2秒注册测试话语的验证,我们提出的系统显示了4.2%的相对EER改进和7.2%的相对minDCF改进。对于持续1秒的较短的话语,它显示出可比的EER(3.8%)提高。
It’s worth noting that due to time constraint, the FID loss function has not been added to our final system; besides, there is no any fine-tuning on hyper-parameters, loss weights α, β, γ, λ, ε and triplet margin η. This means there are still a lot of room for improvements in our system.
值得注意的是,由于时间的限制,最终系统中没有加入FID损失函数;此外,对超参数、损失权重α、β、γ、λ、ε和三重态裕度η也没有任何微调。这意味着我们的系统还有很大的改进空间。
-
CONCLUSIONS
5个。结论
In this paper, we have successfully applied WGAN to learn enhanced embedding for speaker verification application with short utterances. Our main contributions are twofold: pro- posed WGAN-based kernel system; and on top of it, validated the effectiveness of a bunch of loss criteria on the GAN train- ing. Our final proposed system outperforms the baseline sys- tem for the challenging short speaker verification scenarios. In all, our experiments show both decent advancement and a potential direction where our further research goes forward.
本文成功地将WGAN应用于短语音说话人验证应用中的增强嵌入学习。我们的主要贡献有两方面:提出了基于WGAN的核系统;在此基础上,验证了一系列损失准则在GAN训练中的有效性。我们最后提出的系统在挑战性的短小说话人验证情形下,表现优于基线系统。总之,我们的实验既显示了良好的进展,也显示了我们进一步研究的潜在方向。 -
REFERENCES
[1] Mart ́ın Arjovsky, Soumith Chintala, and Le ́on Bot- tou. Wasserstein gan. ArXiv, 2017. URL: https://arxiv.org/pdf/1701.07875.pdf.
[2] D. Povey D. Snyder, D. Garcia-Romero and S. Khu- danpur. Deep neural network embeddings for text-independent speaker verification. In Interspeech, page 999, 2017.
[3] N. Dehak, P. J. Kenny, R. Dehak, P. Dumouchel, and P. Ouellet. Front-end factor analysis for speaker verifi- cation. IEEE Transactions on Audio, Speech, and Lan- guage Processing, 19(4):788–798, May 2011.
[4] Daniel Garcia-Romero and Carol Espy-Wilson. Analy- sis of i-vector length normalization in speaker recogni- tion systems. In Interspeech, pages 249–252, 2011.
[5] JahangirAlamGautamBhattacharyaandPatrickKenny. Deep speaker embeddings for short duration speaker verification. In Interspeech, Stockholm, pages 1517– 1521, 2017.
[6] Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, and Yoshua Bengio. Generative adversarial nets. In Advances in Neural Information Processing Sys- tems 27, pages 2672–2680. 2014.
[7] Nakamasa Inoue Jiacen Zhang and Koichi Shinoda. I- vector transformation using conditional generative ad- versarial networks for short utterance speaker verifica- tion. In Interspeech, Hyderabad, pages 3613–3617, 2018.
[8] Na Li, Deyi Tuo, Dan Su, Zhifeng Li, and Dong Yu. Deep discriminative embeddings for duration robust speaker verification. In Interspeech, pages 2262–2266, 2018.
[9] Thomas Unterthiner Bernhard Nessler Martin Heusel, Hubert Ramsauer and Sepp Hochreiter. GANs trained by a two time-scale update rule converge to a local nash equilibrium. In NIPS, pages 6626–6637, 2017.
[10] Mehdi Mirza and Simon Osindero. Conditional generative adversarial nets. ArXiv, 2014. URL: https://arxiv.org/pdf/1411.1784.pdf.
[11] A. Poddar, M. Sahidullah, and G. Saha. Performance comparison of speaker recognition systems in presence of duration variability. In 2015 Annual IEEE India Con- ference (INDICON), pages 1–6, Dec 2015.
[12] S. J. D. Prince and J. H. Elder. Probabilistic linear dis- criminant analysis for inferences about identity. In 2007 IEEE 11th International Conference on Computer Vi- sion, pages 1–8, Oct 2007.
[13] Lihong Wan Jun Zhang Qingyang Hong, Lin Li and Feng Tong. Transfer learning for speaker verification on short utterances. In Interspeech, pages 1848–1852, 2016.
[14] Xinyuan Cai Ruifang Ji and Bo Xu. An end-to-end text- independent speaker identification system on short ut- terances. In Interspeech, pages 3628–3632, 2018.
[15] Qing Wang, Wei Rao, Sining Sun, Leib Xie, Eng Chng, and Haizhou Li. Unsupervised domain adaptation via domain adversarial training for speaker recognition. In ICASSP, pages 4889–4893, 2018.
[16] Yandong Wen, Kaipeng Zhang, Zhifeng Li, and Yu Qiao. A discriminative feature learning approach for deep face recognition. In ECCV, pages 499–515, 2016.
[17] Jee weon Jung, Hee-Soo Heo, Hye jin Shim, and Ha-Jin Yu. Short utterance compensation in speaker verification via cosine-based teacher-student learn- ing of speaker embeddings. ArXiv, 2018. URL: https://arxiv.org/pdf/1810.10884.pdf.
[18] Weidi Xie, Arsha Nagrani, Joon Son Chung, and Andrew Zisserman. Utterance-level aggregation for speaker recognition in the wild. In ICASSP, pages 5791– 5795, 2019.
[19] Man-Wai Mak Youzhi Tu and Jen-Tzung Chien. Varia- tional domain adversarial learning for speaker verifica- tion. In Interspeech, pages 4315–4319, 2019.
[20] Chunlei Zhang and Kazuhito Koishida. End-to-end text-independent speaker verification with triplet loss on short utterances. In Interspeech, pages 1487–1491, 2017.
智能推荐
稀疏编码的数学基础与理论分析-程序员宅基地
文章浏览阅读290次,点赞8次,收藏10次。1.背景介绍稀疏编码是一种用于处理稀疏数据的编码技术,其主要应用于信息传输、存储和处理等领域。稀疏数据是指数据中大部分元素为零或近似于零的数据,例如文本、图像、音频、视频等。稀疏编码的核心思想是将稀疏数据表示为非零元素和它们对应的位置信息,从而减少存储空间和计算复杂度。稀疏编码的研究起源于1990年代,随着大数据时代的到来,稀疏编码技术的应用范围和影响力不断扩大。目前,稀疏编码已经成为计算...
EasyGBS国标流媒体服务器GB28181国标方案安装使用文档-程序员宅基地
文章浏览阅读217次。EasyGBS - GB28181 国标方案安装使用文档下载安装包下载,正式使用需商业授权, 功能一致在线演示在线API架构图EasySIPCMSSIP 中心信令服务, 单节点, 自带一个 Redis Server, 随 EasySIPCMS 自启动, 不需要手动运行EasySIPSMSSIP 流媒体服务, 根..._easygbs-windows-2.6.0-23042316使用文档
【Web】记录巅峰极客2023 BabyURL题目复现——Jackson原生链_原生jackson 反序列化链子-程序员宅基地
文章浏览阅读1.2k次,点赞27次,收藏7次。2023巅峰极客 BabyURL之前AliyunCTF Bypassit I这题考查了这样一条链子:其实就是Jackson的原生反序列化利用今天复现的这题也是大同小异,一起来整一下。_原生jackson 反序列化链子
一文搞懂SpringCloud,详解干货,做好笔记_spring cloud-程序员宅基地
文章浏览阅读734次,点赞9次,收藏7次。微服务架构简单的说就是将单体应用进一步拆分,拆分成更小的服务,每个服务都是一个可以独立运行的项目。这么多小服务,如何管理他们?(服务治理 注册中心[服务注册 发现 剔除])这么多小服务,他们之间如何通讯?这么多小服务,客户端怎么访问他们?(网关)这么多小服务,一旦出现问题了,应该如何自处理?(容错)这么多小服务,一旦出现问题了,应该如何排错?(链路追踪)对于上面的问题,是任何一个微服务设计者都不能绕过去的,因此大部分的微服务产品都针对每一个问题提供了相应的组件来解决它们。_spring cloud
Js实现图片点击切换与轮播-程序员宅基地
文章浏览阅读5.9k次,点赞6次,收藏20次。Js实现图片点击切换与轮播图片点击切换<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title></title> <script type="text/ja..._点击图片进行轮播图切换
tensorflow-gpu版本安装教程(过程详细)_tensorflow gpu版本安装-程序员宅基地
文章浏览阅读10w+次,点赞245次,收藏1.5k次。在开始安装前,如果你的电脑装过tensorflow,请先把他们卸载干净,包括依赖的包(tensorflow-estimator、tensorboard、tensorflow、keras-applications、keras-preprocessing),不然后续安装了tensorflow-gpu可能会出现找不到cuda的问题。cuda、cudnn。..._tensorflow gpu版本安装
随便推点
物联网时代 权限滥用漏洞的攻击及防御-程序员宅基地
文章浏览阅读243次。0x00 简介权限滥用漏洞一般归类于逻辑问题,是指服务端功能开放过多或权限限制不严格,导致攻击者可以通过直接或间接调用的方式达到攻击效果。随着物联网时代的到来,这种漏洞已经屡见不鲜,各种漏洞组合利用也是千奇百怪、五花八门,这里总结漏洞是为了更好地应对和预防,如有不妥之处还请业内人士多多指教。0x01 背景2014年4月,在比特币飞涨的时代某网站曾经..._使用物联网漏洞的使用者
Visual Odometry and Depth Calculation--Epipolar Geometry--Direct Method--PnP_normalized plane coordinates-程序员宅基地
文章浏览阅读786次。A. Epipolar geometry and triangulationThe epipolar geometry mainly adopts the feature point method, such as SIFT, SURF and ORB, etc. to obtain the feature points corresponding to two frames of images. As shown in Figure 1, let the first image be and th_normalized plane coordinates
开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先抽取关系)_语义角色增强的关系抽取-程序员宅基地
文章浏览阅读708次,点赞2次,收藏3次。开放信息抽取(OIE)系统(三)-- 第二代开放信息抽取系统(人工规则, rule-based, 先关系再实体)一.第二代开放信息抽取系统背景 第一代开放信息抽取系统(Open Information Extraction, OIE, learning-based, 自学习, 先抽取实体)通常抽取大量冗余信息,为了消除这些冗余信息,诞生了第二代开放信息抽取系统。二.第二代开放信息抽取系统历史第二代开放信息抽取系统着眼于解决第一代系统的三大问题: 大量非信息性提取(即省略关键信息的提取)、_语义角色增强的关系抽取
10个顶尖响应式HTML5网页_html欢迎页面-程序员宅基地
文章浏览阅读1.1w次,点赞6次,收藏51次。快速完成网页设计,10个顶尖响应式HTML5网页模板助你一臂之力为了寻找一个优质的网页模板,网页设计师和开发者往往可能会花上大半天的时间。不过幸运的是,现在的网页设计师和开发人员已经开始共享HTML5,Bootstrap和CSS3中的免费网页模板资源。鉴于网站模板的灵活性和强大的功能,现在广大设计师和开发者对html5网站的实际需求日益增长。为了造福大众,Mockplus的小伙伴整理了2018年最..._html欢迎页面
计算机二级 考试科目,2018全国计算机等级考试调整,一、二级都增加了考试科目...-程序员宅基地
文章浏览阅读282次。原标题:2018全国计算机等级考试调整,一、二级都增加了考试科目全国计算机等级考试将于9月15-17日举行。在备考的最后冲刺阶段,小编为大家整理了今年新公布的全国计算机等级考试调整方案,希望对备考的小伙伴有所帮助,快随小编往下看吧!从2018年3月开始,全国计算机等级考试实施2018版考试大纲,并按新体系开考各个考试级别。具体调整内容如下:一、考试级别及科目1.一级新增“网络安全素质教育”科目(代..._计算机二级增报科目什么意思
conan简单使用_apt install conan-程序员宅基地
文章浏览阅读240次。conan简单使用。_apt install conan