异常检测系列:高斯混合模型(GMM)_gmm故障诊断 java-程序员宅基地

(A) 什么是高斯混合模型(GMM)?
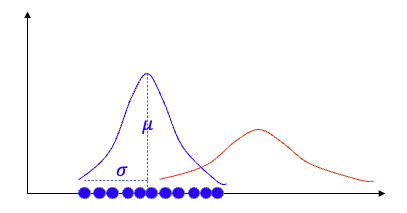
假设数据点分为四个组,如图(A.1)所示。有两种或更多种解释数据的方式。图(A.1)是K-means的方式。它假设有固定数量的簇,本例中为四个簇。然后将每个数据点分配给一个簇。图(A.2)是GMM的方式。它假设有固定数量的具有不同均值和标准差的高斯分布。在我们的例子中,它假设有四个分布。
我将图(A.1)和图(A.2)垂直对齐,以比较GMM和K-means。GMM用四个分布的概率描述一个数据点,而K-means将一个数据点识别为一个且仅一个簇。假设一个数据点在最左端。K-means会说它属于簇1,而GMM可能会说它有90%的概率来自红色分布,9%的概率来自橙色分布,0.9%的概率来自蓝色分布,0.1%的概率来自绿色分布,或者[90%,9%,0.9%,0.1%]的概率来自[红色,橙色,蓝色,绿色]分布。K-means可以被认为是GMM的一个特例,因为一个数据点属于一个簇的概率为1,而其他概率为0。或者我们可以说K-means执行硬分类,而高斯执行软分类。
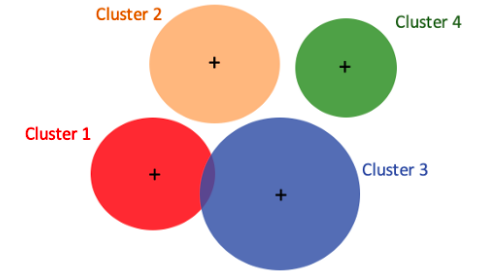
图 (A.1)
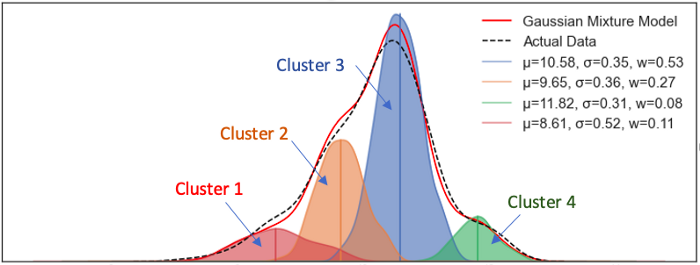
图 (A.2)
(B) GMM相对于K-means的优势是什么?
虽然K-Means是一种简单且快速的聚类方法,但它可能会将数据点强行分配到一个簇中,而不能真正捕捉到数据中的模式。GMM在描述底层数据模式方面更加直观。例如,如果被问及明天的天气,我们会谨慎地说“51%的冰雹和49%的雨”,而不会说“绝对是100%的冰雹”。
从高斯分布到GMM
使用GMM的另一个动机是当实例的分布是多峰的,即数据分布中存在多个“峰值”。多峰分布看起来像是一种混合了单峰分布的分布。高斯分布是单峰的,并且具有许多良好的性质,因此在混合模型中是一个很好的选择。
(D) 我们试图解决的问题
我们不知道GMM中的概率z = [90%,9%,0.9%,0.1%],我们甚至不知道每个高斯分布的均值µ和方差⍴。此刻我们唯一知道的是有四个高斯分布。好消息是,概率z,均值µ和方差⍴都可以通过我即将介绍的期望最大化算法进行估计。有了这个解决方案,我们可以说一个数据点有[90%,9%,0.9%,0.1%]的机会来自这四个分布之一。
如果z是已知的,我们可以预测一个数据点x。它表示为p(x|z),并且读作“给定z,x的概率是p(x|z)”。但是我们想要知道的是相反的情况:给定一个数据点x,它属于哪个分布的概率是多少。它表示为p(z|x),并且读作“给定一个数据点x,它属于z的概率是p(z|x)”。我想提醒读者条件概率p(x|z)并不是新的。它是任何机器学习模型的本质。让我们以逻辑回归Y = a + bX为例。a和b是类似于z的参数,或者z=(a,b)。对于Y的预测是“给定参数a和b,当X的值为x时的预测”,或者p(X=x|a,b)。
我们如何得到p(z|x)?这就是贝叶斯定理的作用。英国长老会牧师、统计学家和哲学家托马斯·贝叶斯(约1701年-1761年)通过数学方法找到了p(z|x)和p(x|z)之间的关系。
(E) 使用贝叶斯定理进行帮助
贝叶斯定理如方程(1)所示:
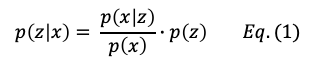
在这里,p(z)被称为先验概率。它指的是任何先前的信念或已知概率。p(z|x)被称为后验概率。它是考虑了关于z的先前信息和新数据(给定z的新预测)的概率。最后,p(x|z)/p(x)的比值被称为似然比。使用这些术语,贝叶斯定理可以重新表述为“后验概率等于先验概率乘以似然比”。如果有新的信息到达,后验概率随后可以成为新的更新后验概率的先验。这个迭代过程是期望最大化建立在其上的。
(F) GMM如何获得其参数估计?
有三组未知参数需要估计:(z, µ, σ*)。为了估计标准高斯分布中的(µ, σ*),我们可以使用最大对数似然估计(MLE)。您可能已经在线性回归中学过MLE。现在有一个额外的未知参数z,我们可以先猜测z的任何值,并应用MLE来估计(µ, σ*)。然后,θ = (µ, σ*)被反馈回来计算和更新z。更新后的z在MLE中用于估计θ = (µ, σ*)。这个迭代过程被称为期望最大化算法。让我在(F.1)和(F.2)中进一步解释。
(F.1) 最大对数似然估计(MLE)
我将通过采用许多教科书和在线资源中的传统符号来解释MLE的直觉。传统符号使用未知参数θ,该参数最大化我们观察到的数据的似然性。
在高斯分布中,θ是未知的均值和方差,即θ = (µ, σ*)。假设有独立同分布(i.i.d.)的随机样本x1、x2、⋯、xn,每个xi的概率密度函数(p.d.f)是f(xi;θ),这意味着在参数θ = (µ, σ*)的高斯分布中样本xi的概率。所有观察到的样本x1、x2、⋯、xn的联合概率密度函数称为L(θ):
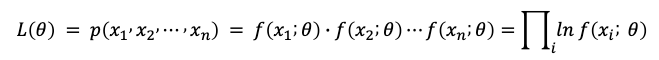
MLE是一种算法,用于找到最大化上述联合密度概率的θ。或者我们可以说MLE找到了这些样本最有可能来自的最优θ。在图(F.1)中,有蓝色的点和所有可能的高斯分布以及它们的(µ, σ)。哪个高斯分布最有可能是蓝色点来自的?MLE是找到(µ, σ)的算法。
图(F.1): 最大对数似然估计 (作者提供的图片)
上述方程中的第二个等式表明,由于独立同分布性质,联合密度概率可以表示为各个密度函数的乘积。独立同分布性质是一个很好的假设,使得许多优化问题变得可处理。它意味着样本xi的抽取与其他样本无关。在许多应用中,这个假设并不太离谱。
最后,通过分别对(µ, σ*)求导并将每个导数设为零,我们可以解出(µ, σ)*的值。
(F.2) 期望最大化算法
但是,如果我们不知道数据点来自多个分布中的哪一个,估计就变得更加复杂。即便如此,我们仍然可以使用一种称为期望最大化 (Expectation-Maximization, E-M) 的算法来推导参数。EM算法使用贝叶斯统计学。它有以下两个步骤(E-M)。
**E步骤:**为数据点属于某个分布的概率分配一个初始“猜测”。给定这个猜测,可以制定MLE。例如,在图(A.2)中,数据点来自红色、橙色、蓝色和绿色分布的概率的初始猜测可以是z = (0.25, 0.25, 0.25, 0.25)。数据点属于分布的概率是后验概率。E步骤只需将值代入方程(1)以获得p(z|x)。我们知道单个高斯分布的MLE。因为z是已知的,多个高斯分布的MLE实际上是z中的概率乘以每个高斯分布的MLE。它是MLE的加权和,权重是z中的值。
**M步骤:*这一步是用于估计参数(µ,⍴)*的标准MLE。新的参数被输入到E步骤中再次分配后验概率。E步骤和M步骤将迭代重复直到收敛。
(G) GMM如何定义异常值分数?
GMM输出数据点属于不同高斯分布的概率。这个输出成为定义异常值的一种自然方式。那些具有非常低拟合值的数据点被认为是异常值。有关定义,请参见[2]。因为其他算法为异常值定义高异常值分数,为了保持一致,低拟合值被反转为高值作为异常值分数。
(H) 建模过程
在本书中,我采用以下建模过程进行模型开发、评估和结果解释。
-
模型开发
-
阈值确定
-
正常组和异常组的描述性统计
通过异常值分数,您可以选择一个阈值来将具有高异常值分数的异常观测与正常观测分开。如果任何先前的知识表明异常值的百分比不应超过1%,您可以选择一个导致异常值约为1%的阈值。
两组之间特征的描述性统计(如均值和标准差)对于传达模型的合理性非常重要。如果预期异常组中某个特征的均值高于正常组的均值,如果结果相反,那将是违反直觉的。在这种情况下,您应该调查、修改或删除该特征,并重新进行建模。
(H.1) 第一步 — 构建模型
和之前一样,我将使用PyOD的generate_data()实用函数来生成百分之十的异常值。为了使情况更有趣,数据生成过程(DGP)将创建六个变量。虽然这个模拟数据集有目标变量Y,但无监督模型只使用X变量。Y变量仅用于验证。我将异常值的百分比设置为5%,即“contamination=0.05”。
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from pyod.utils.data import generate_data
contamination = 0.05 # percentage of outliers
n_train = 500 # number of training points
n_test = 500 # number of testing points
n_features = 6 # number of features
X_train, X_test, y_train, y_test = generate_data(
n_train=n_train,
n_test=n_test,
n_features= n_features,
contamination=contamination,
random_state=123)
X_train_pd = pd.DataFrame(X_train)
X_train_pd.head()
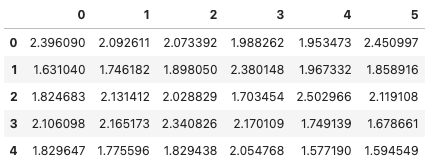
六个变量的前五条记录如下所示:
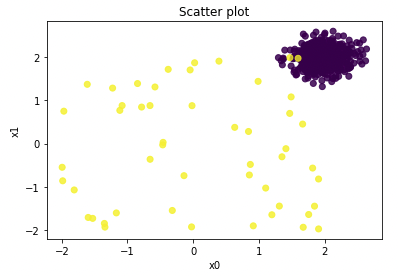
让我在散点图中绘制前两个变量。散点图中的黄色点是10%的异常值。正常观测值是紫色点。
# Plot
plt.scatter(X_train_pd[0], X_train_pd[1], c=y_train, alpha=0.8)
plt.title('Scatter plot')
plt.xlabel('x0')
plt.ylabel('x1')
plt.show()
使用PyOD构建模型非常容易,这要归功于其统一的API。下面我们声明并拟合模型,然后使用函数decision_functions()为训练和测试数据生成异常值分数。
参数contamination=0.05声明了一个5%的污染率。污染率是异常值的百分比。在大多数情况下,我们不知道异常值的百分比,所以可以根据任何先前的知识分配一个值。PyOD默认的污染率为10%。这个参数不影响异常值分数的计算。PyOD使用它来推导出异常值分数的阈值,并应用函数predict()来分配标签(1或0)。我在下面的代码中编写了一个名为count_stat()的简短函数来显示预测的“1”和“0”的计数。语法.threshold_显示了分配的污染率下的阈值。任何高于阈值的异常值分数都被视为异常值。
from pyod.models.gmm import GMM
gmm = GMM(n_components=4, contamination=0.05)
gmm.fit(X_train)
# Training data
y_train_scores = gmm.decision_function(X_train)
y_train_pred = gmm.predict(X_train)
# Test data
y_test_scores = gmm.decision_function(X_test)
y_test_pred = gmm.predict(X_test) # outlier labels (0 or 1)
def count_stat(vector):
# Because it is '0' and '1', we can run a count statistic.
unique, counts = np.unique(vector, return_counts=True)
return dict(zip(unique, counts))
print("The training data:", count_stat(y_train_pred))
print("The training data:", count_stat(y_test_pred))
# Threshold for the defined comtanimation rate
print("The threshold for the defined comtanimation rate:" , gmm.threshold_)

gmm.get_params()

(H.2) 第二步 — 确定一个合理的阈值
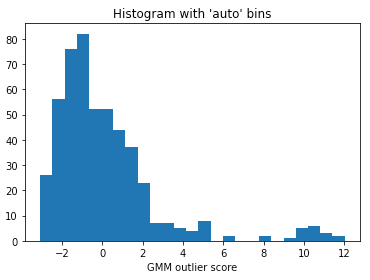
在大多数情况下,我们并不知道异常值的百分比。我们可以使用异常值得分的直方图来选择一个合理的阈值。阈值决定了异常组的大小。如果有任何先前的知识表明异常值的百分比不应超过1%,那么您可以选择一个导致大约1%异常值的阈值。图(H.2)展示了异常值得分的直方图。看起来我们可以将阈值设置为200.0,因为直方图中有一个自然的分割点。如果我们选择一个较低的阈值,异常值的计数将会很高,反之亦然。
import matplotlib.pyplot as plt
plt.hist(y_train_scores, bins='auto') # arguments are passed to np.histogram
plt.title("Histogram with 'auto' bins")
plt.xlabel('GMM outlier score')
plt.show()
(H.3) 第三步 — 展示正常组和异常组的汇总统计信息
如第1章所述,两组之间特征的描述性统计信息(例如均值和标准差)对于证明模型的可靠性非常重要。我创建了一个名为descriptive_stat_threshold()的简短函数,用于根据阈值显示正常组和异常组的特征大小和描述性统计信息。下面我简单地使用了5%的阈值。您可以测试一系列阈值,以找到合理的异常组大小。
threshold = gmm.threshold_ # Or other value from the above histogram
def descriptive_stat_threshold(df,pred_score, threshold):
# Let's see how many '0's and '1's.
df = pd.DataFrame(df)
df['Anomaly_Score'] = pred_score
df['Group'] = np.where(df['Anomaly_Score']< threshold, 'Normal', 'Outlier')
# Now let's show the summary statistics:
cnt = df.groupby('Group')['Anomaly_Score'].count().reset_index().rename(columns={
'Anomaly_Score':'Count'})
cnt['Count %'] = (cnt['Count'] / cnt['Count'].sum()) * 100 # The count and count %
stat = df.groupby('Group').mean().round(2).reset_index() # The avg.
stat = cnt.merge(stat, left_on='Group',right_on='Group') # Put the count and the avg. together
return (stat)
descriptive_stat_threshold(X_train,y_train_scores, threshold)

表格(H.3)
上表展示了正常组和异常组的特征。它显示了正常组和异常组的计数和计数百分比。"Anomalous_Score"是平均异常分数。请记住,在有效的展示中,您需要使用特征名称标记特征。该表告诉我们几个重要的结果:
-
**异常组的大小:**异常组约占总体的5%。请记住,异常组的大小由阈值决定。如果您选择更高的阈值,异常组的大小将会缩小。
-
**平均异常分数:**异常组的平均异常分数远高于正常组的分数(9.12 > -0.34)。您不需要过多解释分数。
-
**每个组中的特征统计:**上表显示,异常组中的特征均值小于正常组。异常组中的特征均值应该更高还是更低取决于业务应用。重要的是,所有均值都应与领域知识保持一致。
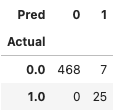
由于我们在数据生成中有真实值,我们可以生成一个混淆矩阵来了解模型的性能。该模型表现良好,并成功识别出了所有25个异常值。
Actual_pred = pd.DataFrame({
'Actual': y_test, 'Anomaly_Score': y_test_scores})
Actual_pred['Pred'] = np.where(Actual_pred['Anomaly_Score']< threshold,0,1)
pd.crosstab(Actual_pred['Actual'],Actual_pred['Pred'])
(I) 通过聚合多个模型实现模型稳定性
基于分布的方法在训练数据中很容易受到噪声和过拟合的影响。GMM假设数据具有特定的分布,然后尝试学习该分布的参数。如果对于分布的假设不准确(不是高斯分布),数据将无法很好地适应模型,模型将产生许多异常值。此外,如果假设存在太多的高斯分布(混合成分的数量),则容易过拟合数据。
过拟合的模型会产生不稳定的结果。解决方案是使用一系列超参数训练模型,然后聚合得分。这样可以大大降低过拟合的可能性,并提高预测准确性。
为了不假设大量的混合成分,我为一系列聚类产生了七个GMM模型。这些模型的平均预测将成为最终的模型预测。
from pyod.models.combination import aom, moa, average, maximization
from pyod.utils.utility import standardizer
from pyod.models.gmm import GMM
# Standardize data
X_train_norm, X_test_norm = standardizer(X_train, X_test)
# Test a range of clusters from 2 to 8. There will be 7 models.
n_clf = 7
k_list = [2, 3, 4, 5, 6, 7, 8]
# Just prepare data frames so we can store the model results
train_scores = np.zeros([X_train.shape[0], n_clf])
test_scores = np.zeros([X_test.shape[0], n_clf])
train_scores.shape
# Modeling
for i in range(n_clf):
k = k_list[i]
gmm = GMM(n_components = k)
gmm.fit(X_train_norm)
# Store the results in each column:
test_scores[:, i] = gmm.decision_function(X_test_norm)
# Decision scores have to be normalized before combination
train_scores_norm, test_scores_norm = standardizer(train_scores,test_scores)
预测结果被归一化并存储在数据框“train_scores_norm”中。PyOD模块提供了四种聚合方法,您只需要使用一种方法来生成结果。
# Combination by average
# The test_scores_norm is 500 x 7. The "average" function will take the average of the 7 columns.
# The result "y_by_average" is a single column:
y_train_by_average = average(train_scores_norm)
y_test_by_average = average(test_scores_norm)
import matplotlib.pyplot as plt
plt.hist(y_train_by_average, bins='auto') # arguments are passed to np.histogram
plt.title("Combination by average")
plt.show()
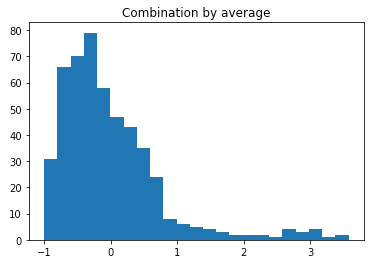
图 (I):训练数据的平均预测直方图
图 (I) 绘制了异常值得分的直方图。它建议将2.0作为阈值。然后我在表 (I) 中生成了描述性统计表。它确定了19个数据点为异常值。读者应该对表 (H.3) 进行类似的解释。
descriptive_stat_threshold(X_train,y_train_by_average, 2.0)

表格(I)
(J) GMM算法摘要
-
GMM用于描述数据点来自不同分布的概率,而K-means将数据点识别为一个且仅一个簇。
-
条件概率p(z|x)的含义是“给定一个数据点x,它属于z的概率是p(z|x)”。通过使用贝叶斯定理,我们可以得到后验概率p(z|x)。
-
GMM使用期望最大化算法来找到后验概率p(z|x)的最优值。E步骤为数据点属于某个分布的概率分配一个初始“猜测”。给定这个猜测,可以进行最大似然估计。M步骤是标准的最大似然估计来估计参数。新的参数被传递给E步骤再次分配后验概率。E步骤和M步骤将迭代重复直到收敛。
-
那些与基础高斯分布拟合值较低的数据点被认为是异常值。
参考文献
-
[1] Duda, R. O. & Hart, P. E. (1973), Pattern Classification and Scene Analysis, Wiley, New York
-
[2] Charu C. Aggarwal. 2016. Outlier Analysis (2nd. ed.). Springer Publishing Company, Incorporated.
异常检测系列文章导航
异常检测系列:Histogram-based Outlier Score_HBOS算法
智能推荐
爬取豆瓣 TOP250 电影排行榜-程序员宅基地
文章浏览阅读3.4k次,点赞3次,收藏21次。很多朋友在看一部电影前都喜欢先找一下网友们对该片的评价。国内的电影评分网站,要数豆瓣最出名。接下来我们将爬取豆瓣至今TOP250的电影的详细信息。豆瓣有专门一个 TOP250 的电影链接 -> https://movie.douban.com/top250首先我们模拟浏览器发送请求,将数据保存为html网页格式,查看返回数据是否正常。import requestsfrom bs4 ...
什么是物联网(IoT)?-程序员宅基地
文章浏览阅读1.1w次,点赞4次,收藏32次。IoT(即物联网)一词是指互联设备的集合网络,以及促进设备与云之间以及设备自身之间通信的技术。由于价格低廉的计算机芯片和高带宽电信的出现,我们现在已有数十亿台设备连接到互联网。也就是说,牙刷、吸尘器、汽车、机器等日常设备可以利用传感器收集数据,智能地为用户服务。 物联网将日常“事物”与互联网相结合。90 年代以来,计算机工程师一直在为日常用品添加传感器和处理器。但是,这项工作最初进展十分缓慢,因为芯片又大又笨重。名为 RFID 标签的低功耗计算机芯片是首个用于跟踪昂贵设备的芯片。随着计算设备尺寸不断缩小,_iot
浏览器多线程和js单线程_浏览器点击事件是单线程吗-程序员宅基地
文章浏览阅读1.4w次,点赞11次,收藏55次。0.前言开发过程中遇到js线程和ui渲染线程互斥问题。导致ui无法正常更新等问题。这些问题的根源就是因为浏览器的多线程和js的单线程引起的。看本篇博客之前,应该充分理解消息队列,事件循环,同步异步任务等概念。 这些概念以前都知道,也了解多线程的概念。但是当遇到问题的时候,这些东西都被抛到脑后,值得深思。1.知识点补充js单线程js运作在浏览器中,是单线程的,js代码始终在一个线程上执行,此线程被称_浏览器点击事件是单线程吗
代码学习记录25---回溯算法最后一天-程序员宅基地
文章浏览阅读833次,点赞22次,收藏15次。N皇后,数独
Alcohol 120%刻录教程-程序员宅基地
文章浏览阅读261次。Alcohol 120%刻录教程 【虎.无名】由于非正版的Nero可能刻出废盘,所以我改用“Alcohol 120%”了,它不但可用来虚拟光驱,刻录功能似乎也不弱。参考:Nero刻出废盘的秘密(待考证)[url]http://zeroliu.blogdriver.com/zeroliu/..._利用alcohol 120%制作音乐cd
细数【SD-WEBUI】的模型:谁是最适合的模型&从哪里找到它们_sd模型网站-程序员宅基地
文章浏览阅读8.4k次,点赞6次,收藏27次。神奇的模型在哪儿?谁才是最适合我的模型?村口大黄狗为何连夜嚎叫?……_sd模型网站
随便推点
php数组转请求参数,学习猿地-php 数组如何转为url参数-程序员宅基地
文章浏览阅读176次。php数组转为url参数的实现方法:首先创建一个PHP示例文件;然后定义一个数组;最后通过“http_build_query( $array )”方法将数组转为URL参数即可。php 将数组转换网址URL参数$array =array ( 'id' =123, 'name' = 'dopost' );echo http_build_query( $array );//得到结果id=123name=..._php 数组转reqeust
Linux | nslookup详细介绍一下这指令的作用以及用法_nslookup命令的作用和使用方法-程序员宅基地
文章浏览阅读4.3k次。nslookup是一个网络工具,通常用于查询域名系统(DNS)服务器以获取主机名或IP地址相关的信息。它可以用于查找主机名的IP地址,反向查找IP地址的主机名,以及查询DNS记录的其他信息。_nslookup命令的作用和使用方法
lucene、lucene.NET详细使用与优化详解-程序员宅基地
文章浏览阅读1.1k次。2019独角兽企业重金招聘Python工程师标准>>> ..._n n ___': - _* . &; v. 7_ 'v & .
用python和pygame写游戏_用Python和Pygame写游戏-从入门到精通(6)-程序员宅基地
文章浏览阅读138次。掌握了小小的像素,我们可以使用更加复杂一点的东西了,对,就是图像,无数的像素的集合~还记得上次我们为了生成的一张图片,花了无数时间,还好一般游戏不会在游戏的过程中动态生成图像,都是将画好的作为资源封装到游戏中。对2D游戏,图像可能就是一些背景、角色等,而3D游戏则往往是大量的贴图。虽然是基础,这里还是要罗嗦一下,之前说的RBG图像,在游戏中我们往往使用RGBA图像,这个A是alpha,也就是表示透..._pygame 中 screen.set_clip
TCP/IP协议_tcp/ip包内容-程序员宅基地
文章浏览阅读1.6k次。笔记_tcp/ip包内容
javaweb基础_创建一个savelogin.java文件,该页面作用-程序员宅基地
文章浏览阅读1.4k次。静态网站:在tomcat的webapps目录下创建一个目录(命名必须不包含中文和空格),这个目录称之为项目目录在项目目录下创建一个html文件动态网站:在tomcat的webapps目录下创建一个项目目录在项目目录下创建如下内容WEB-INF目录在WEB-INF目录下创建web.xml文件创建静态或动态页面http协议:无状态协议,仅连接一次(ftp_创建一个savelogin.java文件,该页面作用