Python机器学习——朴素贝叶斯_python 贝叶斯-程序员宅基地
Python机器学习——朴素贝叶斯
朴素贝叶斯(Naive Bayes)是一种简单经典的分类算法,它的经典应用案例为人所熟知:文本分类(如垃圾邮件过滤)。
朴素贝叶斯——贝叶斯定理
假设一个场景:面前有一位顾客,此时你需要做的是,推测该顾客究竟是“来买东西的人”,还是“随便逛逛的人”,只有做出正确的判断,才能采取正确的接待方法。
先验概率
**先验概率:**即基于统计的概率,是基于以往历史经验和分析得到的结果,不需要依赖当前发生的条件。
例:假定店员知道每5位顾客中就有一位是"来买东西的";那么就可以得出,P(来买东西的人) = 0.2
由于这部分判断是否来买东西是通过对以前数据的统计得出的结论,所以与他相对的一方面"随便逛逛的人"正好就成相对关系。对于这类的概率,我们称为先验概率
条件概率
**条件概率:**记事件A发生的概率为P(A),事件B发生的概率为P(B),则在B事件发生的前提下,A事件发生的概率即为条件概率,记为P(A|B)。
例:假定顾客会在“过来询问”或“不过来询问”做出选择;分别设定两类顾客“过来询问”的概率
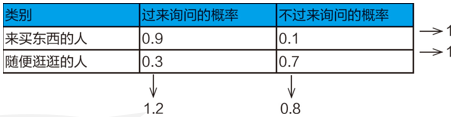
由图可见,相对于先验概率,对象范围包含了两个不同类别的顾客则分别对应的情况以及概率为
- P(过来询问|来买东西的人)=0.9
- P(过来询问|随便逛逛的人)=0.3
- P(不过来询问|来买东西的人)=0.1
- P(不过来询问|随便逛逛的人)=0.7
后验概率
**后验概率:**则是从条件概率而来,由因推果,是基于当下发生了事件之后计算的概率,依赖于当前发生的条件。
例:进一步假定顾客上前询问,估计该顾客是“来买东西的人”的概率
上前询问,派出了四种可能中的两种,只剩下两种可能性。
同时,为了保证两种概率的和为1,我们需要对剩余的两部分做比例对比,及P(来买东西的人) x P(过来询问|来买东西的人) = 0.2x0.9 = 0.18 : P(随便逛逛的人) x P(过来询问|随便逛逛的人) = 0.8x0.3 = 0.24 = 3:4 = 3/7:4/7
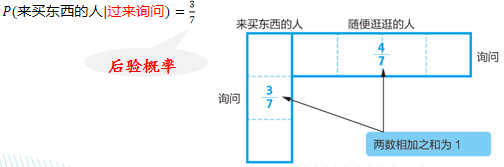
- 在没有观察到任何行为时,面前的顾客是“来买东西的人”的概率为0.2(先验概率)
- 但观察到“上前询问”这一行为之后,数值便更新为约0.43(后验概率)
- 虽然并不能断定这位顾客就是“来买东西的人”,但这一结果的可能性提高到了以前的2倍
所以根据以上的推导:
- 先验概率:P(来买东西的人)=0.2
- P(过来询问|来买东西的人)=0.9
- P(来买东西的人|过来询问)=3/7
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-e8N8B7t9-1684760648931)(C:/Users/Yuchen/AppData/Roaming/Typora/typora-user-images/image-20230522195828807.png)]
朴素贝叶斯——贝叶斯分类
贝叶斯公式
**贝叶斯公式:**贝叶斯公式便是基于条件概率,通过P(B|A)来求P(A|B),如下:
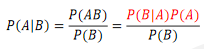
贝叶斯公式中的A和B分别代表标签和特征,也就是

-
分母P(特征)与标签无关,只与所给样本特征有关,因此对所有标签相同
-
分类规则:将样本归到后验概率最大的那个类
因为与标签无关,因此不需要计算准确的概率值,只需要知道属于哪个类的概率最大忽略分母P(特征),问题转化为求

朴素贝叶斯的定理就是:假定每个特征独立对分类结果影响
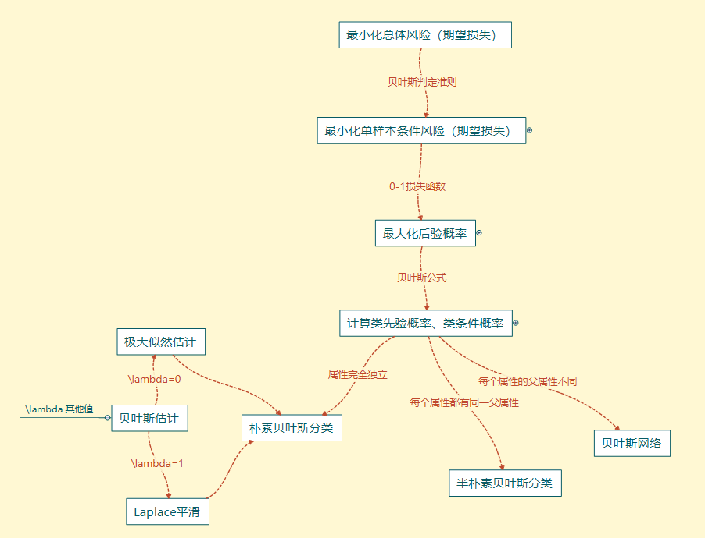
流程
-
目标转化1
-
利用贝叶斯判定准则
-
最小化总体风险 ⟹最小化单样本条件风险
-
-
目标转化2
-
利用0-1损失函数
-
最小化单样本条件风险 ⟹ 最大化后验概率
-
-
后验概率计算再转化
- 利用贝叶斯公式
- 计算类先验概率、类条件概率
-
样本属性关联性假设不同
- 不同的分类器
- 朴素贝叶斯分类
- 半朴素贝叶斯分类
- 贝叶斯网络
- 不同的分类器
总体的流程图:
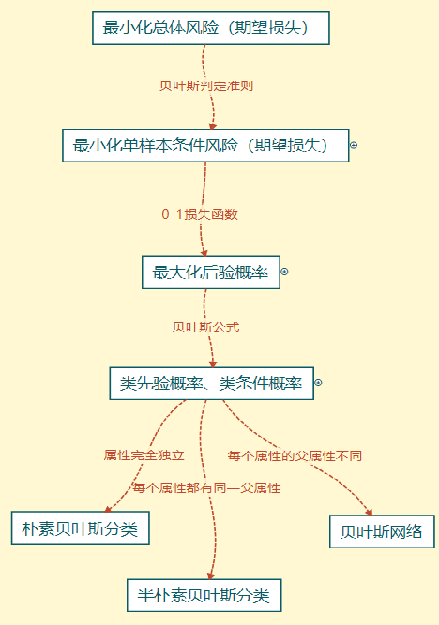
因为涉及到的算法比较多且细,这里就不在详细写了,大家有兴趣可以自行检索
朴素贝叶斯——朴素贝叶斯算法的原理
**特征条件假设:**假设每个特征之间没有联系,给定训练数据集,其中每个样本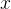 都包括
都包括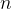 维特征,即),类标记集合含有
维特征,即),类标记集合含有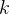 种类别,即)。
种类别,即)。
对于给定的新样本,判断其属于哪个标记的类别,根据贝叶斯定理,可以得到x属于yk类别的概率:
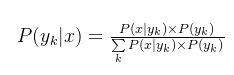
后验概率最大的类别记为预测类别,即: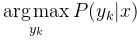
朴素贝叶斯算法对条件概率分布作出了独立性的假设,通俗地讲就是说假设各个维度的特征x1,x2,x3,x4…,xn互相独立,在这个假设的前提上,条件概率可以转化为:
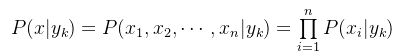
代入上面贝叶斯公式中,得到:
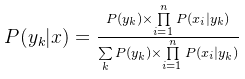
于是,朴素贝叶斯分类器可表示为:
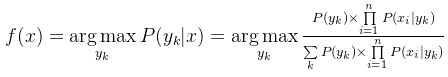
因为对所有的yk,上式中的分母的值都是一样的,所以可以忽略分母部分,朴素贝叶斯分类器最终表示为:
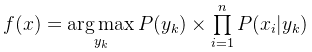
朴素贝叶斯常用的三个模型有:
- 高斯模型:处理特征是连续型变量的情况。
- 多项式模型:最常见,要求特征是离散数据。
- 伯努利模型:要求特征是离散的,且为布尔类型,即true和false,或者1和0。
那么朴素贝叶斯分类器的总结流程图可以写成:
朴素贝叶斯的应用场景
- 在医疗领域,用于医疗诊断
- 在工业领域,用于对工业制品的故障检测和性能分析
- 在金融领域可用于构建风控模型
- 在企业管理上可用于决策支持
- 在自然语言处理方面可用于文本分类、中文分词、机器翻译
#!/usr/bin/env python
# encoding: utf-8
"""
思路:
1、数据集读取,数据处理及训练集和测试集划分
2、选取不同分布的朴素贝叶斯模型进行分类模型训练与测试、评价
"""
import pandas as pd
import warnings
from sklearn.feature_extraction.text import TfidfVectorizer # 文本型数据处理
from sklearn.preprocessing import LabelEncoder # 字符串型数据编码
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn.naive_bayes import GaussianNB, BernoulliNB, MultinomialNB
from sklearn.metrics import roc_curve, auc
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
from matplotlib import rcParams
import matplotlib
# matplotlib.use("Agg") # 输出时不显示绘图
import matplotlib.pyplot as plt # matplotlib.use('agg')必须在本句执行前运行
rcParams['font.family'] = 'simhei' # 可以让图像中显示中文(黑体),无需引用
rcParams['axes.unicode_minus'] = False # 解决负数坐标显示问题
warnings.filterwarnings('ignore')
# #############################################################################################
# 公共部分:分类模型评价体系evaluation
# todo: 构建分类模型的评价体系并存储在evaluation中,方便对比查看,全局变量
evaluation = pd.DataFrame({
'Model': [],
'准确率': [],
'精确率': [],
'召回率': [],
'F1 值': [],
'AUC值': [],
'5折交叉验证的score': []})
# #############################################################################################
# 步骤1 todo: 数据读取、单词文本处理及标签数值化处理、数据集划分
def data_preprocess(train_size):
# 步骤1.1 todo: 读取数据并统计数据类别信息
df = pd.read_csv('./data/SMSSpamCollection', delimiter='\t', header=None) # 利用pandas直接读取已有数据,数据以tab分割
print(df.describe()) # 了解数据的基本信息
print('为spam短信数量:', df[df[0] == 'spam'][0].count())
print('为ham短信数量:', df[df[0] == 'ham'][0].count())
# 步骤1.2 todo: 对数据集中单词文本进行处理
# 由于数据集为单词文本数据,构建TfidfVectorizer来计算每个单词的TF-IDF权重
tfidf_vectorizer = TfidfVectorizer()
X = tfidf_vectorizer.fit_transform(df[1])
X = X.toarray() # 将数据矩阵转化为数组
voc = tfidf_vectorizer.get_feature_names_out() # 构建的词汇表
print(len(voc))
# 步骤1.3 todo: 目标变量中为字符串型数据,使用labelEncoder处理(spam-1,ham-0)
le = LabelEncoder() # 对定型特征多值化
y = le.fit_transform(df[0])
# 步骤1.4 todo: 对整体数据按照train_size进行划分,得到训练集和测试集, random_state确保结果的一致性
X_train, X_test, y_train, y_test = train_test_split(X, y, train_size=train_size, random_state=0)
return X_train, y_train, X_test, y_test, df
# #############################################################################################
# 步骤2 todo: 进行朴素贝叶斯分类模型训练与测试、评价
# 由于选取的不同分布的朴素贝叶斯分类器,写成函数形式,便于引用
def naive_bayes_with_diff_distribution(model, model_name, X_train, y_train, X_test, y_test):
# 步骤2.1 todo: 调用不同分布的朴素贝叶斯分类实例,进行训练测试
NB_model = model
NB_model.fit(X_train, y_train)
y_test_predict = NB_model.predict(X_test)
# 步骤2.2 todo: 计算分类评价指标:测试集的准确率accuracy、精确率precision、召回率recall和综合评价指标 F1 值
# 精确率是指分类器预测出的垃圾短信中真的是垃圾短信的比例
# 召回率是所有真的垃圾短信被分类器正确找出来的比例
# F1 值是精确率和召回率的调和均值
acc_test = accuracy_score(y_test, y_test_predict) # 和模型自带的score一致
precision_test = precision_score(y_test, y_test_predict)
recall_test = recall_score(y_test, y_test_predict)
f1score_test = f1_score(y_test, y_test_predict)
# 步骤2.3 todo: 绘制ROC曲线,计算auc,度量分类模型的预测能力
# ROC曲线以召回率为纵轴,以假正例率为横轴,ROC曲线下的面积为AUC值
y_test_predict_proba = NB_model.predict_proba(X_test)
false_positive_rate, recall, thresholds = roc_curve(y_test, y_test_predict_proba[:, 1])
roc_auc = auc(false_positive_rate, recall) # 计算auc的值
plt.figure()
plt.title('%s 模型的 ROC-AUC 图' % model_name)
plt.plot(false_positive_rate, recall, 'r', label='AUC = %0.3f' % roc_auc)
plt.legend(loc='best')
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.0])
plt.ylabel('真正例率(召回率)')
plt.xlabel('假正例率')
plt.savefig('./results/ROC_AUC_with_model_{}.png'.format(model_name))
plt.show()
# 步骤2.4 todo: 计算测试集的5折交叉验证的score
cv_test = float(format(cross_val_score(NB_model, X_test, y_test, cv=5).mean(), '.3f'))
# 步骤2.5 todo: 将朴素贝叶斯分类模型计算的相关评价信息存入evaluation中
r = evaluation.shape[0]
evaluation.loc[r] = ['{}分类模型'.format(model_name), acc_test,
precision_test, recall_test, f1score_test, roc_auc, cv_test]
# 步骤2.6 todo: 将评价指标写入csv文件中,便于查看
evaluation.to_csv('./results/evaluation.csv', sep=',', header=True, index=True,
encoding='utf_8_sig') # encoding防止中文乱码
# #############################################################################################
# 程序入口
if __name__ == '__main__':
# 步骤1 todo: 读取数据集,并给出训练集和测试集
train_size = 0.67
X_train, y_train, X_test, y_test, df = data_preprocess(train_size)
# 步骤2 todo: 进行朴素贝叶斯分类模型训练与测试、评价
# 'GaussianNB':Gauss朴素贝叶斯
# 'BernoulliNB':伯努利朴素贝叶斯
# 'MultinomialNB':多项式朴素贝叶斯
models = [GaussianNB(), BernoulliNB(), MultinomialNB()]
model_names = ['GaussianNB', 'BernoulliNB', 'MultinomialNB']
for i, model in enumerate(models):
naive_bayes_with_diff_distribution(model, model_names[i], X_train, y_train, X_test, y_test)
print('模型测试结束!')
朴素贝叶斯——简单分词算法TF-IDF(扩展)
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
(1)TF是词频,表示关键字在文本中出现的频率
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。
公式:
(2)IDF是逆向文件频率
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
公式:
(3)TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
公式: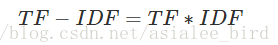
注: TF-IDF算法非常容易理解,并且很容易实现,但是其简单结构并没有考虑词语的语义信息,无法处理一词多义与一义多词的情况。
TF-IDF应用
(1)搜索引擎;(2)关键词提取;(3)文本相似性;(4)文本摘要
Sklearn实现TF-IDF算法
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.feature_extraction.text import TfidfTransformer
x_train = ['TF-IDF 主要 思想 是','算法 一个 重要 特点 可以 脱离 语料库 背景',
'如果 一个 网页 被 很多 其他 网页 链接 说明 网页 重要']
x_test=['原始 文本 进行 标记','主要 思想']
#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
vectorizer = CountVectorizer(max_features=10)
#该类会统计每个词语的tf-idf权值
tf_idf_transformer = TfidfTransformer()
#将文本转为词频矩阵并计算tf-idf
tf_idf = tf_idf_transformer.fit_transform(vectorizer.fit_transform(x_train))
#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
x_train_weight = tf_idf.toarray()
#对测试集进行tf-idf权重计算
tf_idf = tf_idf_transformer.transform(vectorizer.transform(x_test))
x_test_weight = tf_idf.toarray() # 测试集TF-IDF权重矩阵
print('输出x_train文本向量:')
print(x_train_weight)
print('输出x_test文本向量:')
print(x_test_weight)
智能推荐
python编码问题之encode、decode、codecs模块_python中encode在什么模块-程序员宅基地
文章浏览阅读2.1k次。原文链接先说说编解码问题编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 Eg:str1.decode('gb2312') #将gb2312编码的字符串转换成unicode编码str2.encode('gb2312') #将unicode编码..._python中encode在什么模块
Java数据流-程序员宅基地
文章浏览阅读949次,点赞21次,收藏15次。本文介绍了Java中的数据输入流(DataInputStream)和数据输出流(DataOutputStream)的使用方法。
ie浏览器无法兼容的问题汇总_ie 浏览器 newdate-程序员宅基地
文章浏览阅读111次。ie无法兼容_ie 浏览器 newdate
想用K8s,还得先会Docker吗?其实完全没必要-程序员宅基地
文章浏览阅读239次。这篇文章把 Docker 和 K8s 的关系给大家做了一个解答,希望还在迟疑自己现有的知识储备能不能直接学 K8s 的,赶紧行动起来,K8s 是典型的入门有点难,后面越用越香。
ADI中文手册获取方法_adi 如何查看数据手册-程序员宅基地
文章浏览阅读561次。ADI中文手册获取方法_adi 如何查看数据手册
React 分页-程序员宅基地
文章浏览阅读1k次,点赞4次,收藏3次。React 获取接口数据实现分页效果以拼多多接口为例实现思路加载前 加载动画加载后 判断有内容的时候 无内容的时候用到的知识点1、动画效果(用在加载前,加载之后就隐藏或关闭,用开关效果即可)2、axios请求3、map渲染页面4、分页插件(antd)代码实现import React, { Component } from 'react';//引入axiosimport axios from 'axios';//引入antd插件import { Pagination }_react 分页
随便推点
关于使用CryPtopp库进行RSA签名与验签的一些说明_cryptopp 签名-程序员宅基地
文章浏览阅读449次,点赞9次,收藏7次。这个变量与验签过程中的SignatureVerificationFilter::PUT_MESSAGE这个宏是对应的,SignatureVerificationFilter::PUT_MESSAGE,如果在签名过程中putMessage设置为true,则在验签过程中需要添加SignatureVerificationFilter::PUT_MESSAGE。项目中使用到了CryPtopp库进行RSA签名与验签,但是在使用过程中反复提示无效的数字签名。否则就会出现文章开头出现的数字签名无效。_cryptopp 签名
新闻稿的写作格式_新闻稿时间应该放在什么位置-程序员宅基地
文章浏览阅读848次。新闻稿是新闻从业者经常使用的一种文体,它的格式与内容都有着一定的规范。本文将从新闻稿的格式和范文两个方面进行介绍,以帮助读者更好地了解新闻稿的写作_新闻稿时间应该放在什么位置
Java中的转换器设计模式_java转换器模式-程序员宅基地
文章浏览阅读1.7k次。Java中的转换器设计模式 在这篇文章中,我们将讨论 Java / J2EE项目中最常用的 Converter Design Pattern。由于Java8 功能不仅提供了相应类型之间的通用双向转换方式,而且还提供了转换相同类型对象集合的常用方法,从而将样板代码减少到绝对最小值。我们使用Java8 功能编写了..._java转换器模式
应用k8s入门-程序员宅基地
文章浏览阅读150次。1,kubectl run创建pods[root@master ~]# kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=1[root@master ~]# kubectl get podsNAME READY STATUS REST...
PAT菜鸡进化史_乙级_1003_1003 pat乙级 最优-程序员宅基地
文章浏览阅读128次。PAT菜鸡进化史_乙级_1003“答案正确”是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的“答案正确”大派送 —— 只要读入的字符串满足下列条件,系统就输出“答案正确”,否则输出“答案错误”。得到“答案正确”的条件是: 1. 字符串中必须仅有 P、 A、 T这三种字符,不可以包含其它字符; 2. 任意形如 xPATx 的字符串都可以获得“答案正确”,其中 x 或者是空字符串,或..._1003 pat乙级 最优
CH340与Android串口通信_340串口小板 安卓给安卓发指令-程序员宅基地
文章浏览阅读5.6k次。CH340与Android串口通信为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio移植的具体步骤CH340串口通信驱动函数通信过程中重难点还存在的问题为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio为了在这个工程基础上进行改动,验证串口的数据和配置串口的参数,我首先在Eclipse上配置了安卓开发环境,注意在配置环境是..._340串口小板 安卓给安卓发指令