NNLM神经网络语言模型简单实现词语预测(含python代码详解)_神经网络语言模型代码-程序员宅基地
文章目录
一、NNLM简单介绍
NNLM:Neural Network Language Model,神经网络语言模型。源自Bengio等人于2001年发表在NIPS上的《A Neural Probabilistic Language Model一文。
利用神经网络计算词向量的方法,根据(w{t-n+1}...w{t-1})来预测(w{t})是什么单词,即用前(n-1)个单词来预测第(n)个单词。
二、NNLM词语预测代码
1. 导入包
torch库——又称PyTorach,是一个以Python优先的深度学习框架,一个开源的Python机器学习库,用于自然语言处理等应用程序。
torch.nn包——nn全称为neural network,意思是神经网络,是torch中构建神经网络的模块。
torch.optim包——这个包里面有很多的优化算法,比如我们常用的随机梯度下降算法,添加动量的随机梯度下降算法。
import torch
import torch.nn as nn
import torch.optim as optim2. 文本数据处理
输入三句短文本,"i like dog", "i love coffee", "i hate milk",作为模型预测的资料。
dtype = torch.FloatTensor
sentences = ["i like dog", "i love coffee", "i hate milk"]
word_list = " ".join(sentences).split() # 提取句子中所有词语
#print(word_list)
word_list = list(set(word_list)) # 去除重复元素,得到词汇表
#print("去重后的word_list:", word_list)
word_dict = {w: i for i, w in enumerate(word_list)} # 按照词汇表生成相应的词典 {‘word’:0,...}
number_dict = {i: w for i, w in enumerate(word_list)} # 将每个索引对应于相应的单词{0:'word',...}
n_class = len(word_dict) # 单词的总数,也是分类数torch.FloatTensor——FloatTensor用于生成浮点类型的张量。 torch.FloatTensor()默认生成32位浮点数,dtype 为 torch.float32 或 torch.float。
enumerate() 函数用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
3. 自定义mini-batch迭代器
自定义函数:def make_batch(sentences),make_batch(sentences)函数是一个mini-batch迭代器,实现数据的输入输出,函数以sentences列表作为输入, 最终函数将输入数据集input_batch和输出数据集target_batch返回为结果。详见代码注释。
def make_batch(sentences):
input_batch = []
target_batch = []
for sen in sentences:
#通过for循环遍历sentences中的每个句子
word = sen.split()
input = [word_dict[n] for n in word[:-1]]
#设定输入为列表word中每个词汇对应的数字所组成的序列,一句话中最后一个词是要用来预测的, 不作为输入。最后的:-1就表示取每个句子在最后一个单词之前的单词作为输入,通过word_dict取出这些单词的下标,作为整个网络的输入。
target = word_dict[word[-1]]
#将每句话的最后一个词作为目标值(target),以本次实验为例就是cat,coffee和milk,word_dict取出单词的下标,作为输出。
input_batch.append(input)
#input_batch是空列表,将每句话的输入放入列表中,形成输入数据集
target_batch.append(target)
#target_batch是空列表,将每句话的输出放入列表中,形成输出数据集
return input_batch, target_batch接下来调用make_batch函数进行数据输入和转化:
将sentences输入make_batch函数,使用make_batch从训练集中获得输入和对应的标记,将输入数据集用input_batch存储,将输出数据集target_batch用存储。
input_batch, target_batch = make_batch(sentences) 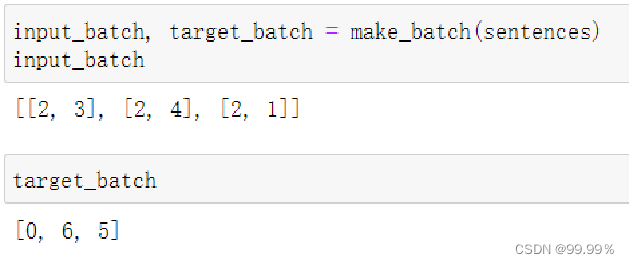
4. 定义NNLM模型
1. 定义模型结构
# 定义模型
class NNLM(nn.Module):
def __init__(self):
super(NNLM, self).__init__() #定义网络结构,继承nn.Module
self.C = nn.Embedding(n_class, m)
self.H = nn.Parameter(torch.randn(n_step * m, n_hidden).type(dtype))
self.W = nn.Parameter(torch.randn(n_step * m, n_class).type(dtype))
self.d = nn.Parameter(torch.randn(n_hidden).type(dtype))
self.U = nn.Parameter(torch.randn(n_hidden, n_class).type(dtype))
self.b = nn.Parameter(torch.randn(n_class).type(dtype))
#C: 词向量,计算词向量表,大小是len(word_dict) * m 词向量随机赋值,先使用one-hot,然后使用matrix C映射到词向量。
#H: 隐藏层的权重; W: 输入层到输出层的权重;
#d: 隐藏层的bias; U: 输出层的weight; b: 输出层的bias;
#n_step为文中用n_step个词预测下一个词,在本程序中其值为2
#n_hidden为隐藏层的神经元的数量
#m为词向量的维度
def forward(self, X):
X = self.C(X) # [batch_size, n_step] => [batch_size, n_step, m]
#输入层的输入转换:x=x’* C==[C(wi−(n−1)), …,C(wi−1)];
根据词向量表,将输入数据X转换成三维数据,将每个单词替换成相应的词向量。X原本形式为[batch_size, n_step],转换后为[batch_size, n_step, m]
X = X.view(-1, n_step * m) # [batch_size, n_step * m]
#将替换后的词向量表的相同行进行拼接,view函数的第一个参数为-1表示自动判断需要合并成几行。
hidden_out = torch.tanh(self.d + torch.mm(X, self.H)) # [batch_size, n_hidden]
#隐藏层的计算,主要计算h=tanh(d+Hx)。其中,H表示输入层
到隐藏层的权重矩阵,其维度为|V| * |h|。|V|表示词表的大小,d表示偏置,torch.mm表示矩阵的相乘。输出为[batch_size, n_hidden]
output = self.b + torch.mm(X, self.W) + torch.mm(hidden_out, self.U) # [batch_size, n_class]
#输出层的计算:主要计算y=b+Uh。其中,U表示隐藏层到输出层的权重矩阵,b表示偏置,y表示输出的一个|V|的向量,向量中内容是下一个词wi是词表中每一个词的可能性。输出为[batch_size, n_class],最终return返回output。
return output代码中的:
torch.nn.Embedding()函数是指torch.nn包下的Embedding,作为训练的一层,随模型训练得到适合的词向量。
torch.nn.Parameter()函数含义是将一个固定不可训练的tensor转换成可以训练的类型parameter,并将这个parameter绑定到这个module里面,所以经过类型转换这个self.H变成了模型的一部分,成为了模型中根据训练可以改动的参数了。使用这个函数的目的也是想让某些变量在学习的过程中不断的修改其值以达到最优化。
torch.randn()函数用来生成随机数字的tensor,这些随机数字满足标准正态分布(0~1)。例如torch.randn(size),size可以是一个整数,也可以是一个元组。
输入层的输入:将词序列wi−(n-1)…wi−1中的n-1个词,每一个词 进行one-hot编码,得到向量1*V;词向量按照顺序进行拼接, 获的输入向量x’=[V(wi−(n−1)), …,V(wi−1)];
总之就是将将输入的 n-1 个单词索引转为词向量,然后将这 n-1 个词向量进行 concat,形成一个 (n-1)*w 的输入向量。接下来将向量作为X送入隐藏层进行计算,hidden = tanh(d + X * H) 这就涉及到了自定义函数forward,使NNLM模型可以训练并完成向量的迭代更新,forword函数的代码解释详见代码注释。
2. NNLM参数设置
# NNLM参数设置
n_step = 2 # 设定n_gram为2,即根据当前词的前两个词语预测当前单词
n_hidden = 2 # 设定隐藏层神经元的个数为2
m = 2 # 设定词向量的维度为2
model = NNLM() #将之前建立的NNLM模型实例化为model
criterion = nn.CrossEntropyLoss() #使用交叉熵损失
optimizer = optim.Adam(model.parameters(), lr=0.001) #优化器 选择Adam其中分类问题用交叉熵作为损失函数; nn.CrossEntropyLoss()为交叉熵损失函数,用于解决多分类问题,也可用于解决二分类问题。在使用nn.CrossEntropyLoss()其内部会自动加上Sofrmax层。
优化器使用Adam。所谓的优化器,实际上就是你用什么方法去更新网路中的参数。 torch.optim是一个实现了多种优化算法的包,大多数通用的方法都已支持,提供了丰富的接口调用。 Adam算法本质上是带有动量项的RMSprop,它利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。
5. 输入数据并完成训练
输入数据:
# 数据输入
input_batch, target_batch = make_batch(sentences)
input_batch = torch.LongTensor(input_batch)
target_batch = torch.LongTensor(target_batch)其中使用make_batch从训练集中获得输入和对应的标记;
input_batch:一组batch中前n_steps个单词的索引;
target_batch:一组batch中每句话待预测单词的索引 torch.FloatTensor是32位浮点类型数据,而torch.LongTensor是64位整型;
开始训练:
# 开始训练
for epoch in range(5000): #设定训练5000轮
optimizer.zero_grad() #梯度清零,也就是把loss关于weight的导数变成0
output = model(input_batch) #模型训练 tensor(3,7)
# output : [batch_size, n_class], target_batch : [batch_size] (LongTensor, not one-hot)
loss = criterion(output, target_batch)
#计算损失,criterion()为损失函数,用来计算出loss
if (epoch + 1) % 1000 == 0:
print("Epoch:{}".format(epoch + 1), "Loss:{:.3f}".format(loss))
#每到1000输出一次损失值
loss.backward() #反向传播
optimizer.step() #更新参数,optimizer实现了step()方法,这个方法会更新对应的参数。只有用了optimizer.step(),模型才会更新。其中重点解释output = model(input_batch):
计算预测值,对之前建立的NNLM模型集进行训练,形式为tensor(3,7)。 一行代表一个输入对应的七个输出,这七个值对应着7类,也就是词典个数,对应最大值的位置序号就是最终预测值。

6. 预测
# 预测
predict = model(input_batch).data.max(1, keepdim=True)[1] #tensor (3,1)获取最大值对应的(序号)单词,也就是预测值 [batch_size, n_class]
# print("predict: \n", predict)
# 测试
print([sentence.split()[:2] for sentence in sentences], "---->",
[number_dict[n.item()] for n in predict.squeeze()]) #predict.squeeze 的 tensor(3)
先获取预测值最大者对应的(序号)单词,也就是预测值 [batch_size, n_class] max()取的是最内层维度中最大的那个数的值和索引,[1]表示取索引。
squeeze()表示将数组中维度为1的维度去掉,squeeze():对张量的维度进行减少的操作,假设原来:tensor([[0],[6],[5]]),squeeze()操作后变成tensor([0, 6, 5])。
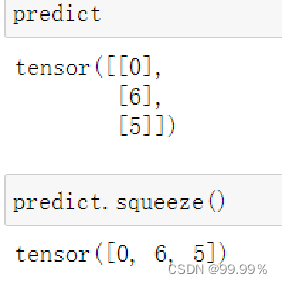
最终通过for循环将每个句子的前两个词组成元素放在列表中,再通过for循环将预测出来的序号对应词汇放入列表中,中间用"---->"连接。
验证一下,发现tensor([0, 6, 5])正是对应number_dict中的dog, coffee, milk:


智能推荐
python编码问题之encode、decode、codecs模块_python中encode在什么模块-程序员宅基地
文章浏览阅读2.1k次。原文链接先说说编解码问题编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 Eg:str1.decode('gb2312') #将gb2312编码的字符串转换成unicode编码str2.encode('gb2312') #将unicode编码..._python中encode在什么模块
Java数据流-程序员宅基地
文章浏览阅读949次,点赞21次,收藏15次。本文介绍了Java中的数据输入流(DataInputStream)和数据输出流(DataOutputStream)的使用方法。
ie浏览器无法兼容的问题汇总_ie 浏览器 newdate-程序员宅基地
文章浏览阅读111次。ie无法兼容_ie 浏览器 newdate
想用K8s,还得先会Docker吗?其实完全没必要-程序员宅基地
文章浏览阅读239次。这篇文章把 Docker 和 K8s 的关系给大家做了一个解答,希望还在迟疑自己现有的知识储备能不能直接学 K8s 的,赶紧行动起来,K8s 是典型的入门有点难,后面越用越香。
ADI中文手册获取方法_adi 如何查看数据手册-程序员宅基地
文章浏览阅读561次。ADI中文手册获取方法_adi 如何查看数据手册
React 分页-程序员宅基地
文章浏览阅读1k次,点赞4次,收藏3次。React 获取接口数据实现分页效果以拼多多接口为例实现思路加载前 加载动画加载后 判断有内容的时候 无内容的时候用到的知识点1、动画效果(用在加载前,加载之后就隐藏或关闭,用开关效果即可)2、axios请求3、map渲染页面4、分页插件(antd)代码实现import React, { Component } from 'react';//引入axiosimport axios from 'axios';//引入antd插件import { Pagination }_react 分页
随便推点
关于使用CryPtopp库进行RSA签名与验签的一些说明_cryptopp 签名-程序员宅基地
文章浏览阅读449次,点赞9次,收藏7次。这个变量与验签过程中的SignatureVerificationFilter::PUT_MESSAGE这个宏是对应的,SignatureVerificationFilter::PUT_MESSAGE,如果在签名过程中putMessage设置为true,则在验签过程中需要添加SignatureVerificationFilter::PUT_MESSAGE。项目中使用到了CryPtopp库进行RSA签名与验签,但是在使用过程中反复提示无效的数字签名。否则就会出现文章开头出现的数字签名无效。_cryptopp 签名
新闻稿的写作格式_新闻稿时间应该放在什么位置-程序员宅基地
文章浏览阅读848次。新闻稿是新闻从业者经常使用的一种文体,它的格式与内容都有着一定的规范。本文将从新闻稿的格式和范文两个方面进行介绍,以帮助读者更好地了解新闻稿的写作_新闻稿时间应该放在什么位置
Java中的转换器设计模式_java转换器模式-程序员宅基地
文章浏览阅读1.7k次。Java中的转换器设计模式 在这篇文章中,我们将讨论 Java / J2EE项目中最常用的 Converter Design Pattern。由于Java8 功能不仅提供了相应类型之间的通用双向转换方式,而且还提供了转换相同类型对象集合的常用方法,从而将样板代码减少到绝对最小值。我们使用Java8 功能编写了..._java转换器模式
应用k8s入门-程序员宅基地
文章浏览阅读150次。1,kubectl run创建pods[root@master ~]# kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=1[root@master ~]# kubectl get podsNAME READY STATUS REST...
PAT菜鸡进化史_乙级_1003_1003 pat乙级 最优-程序员宅基地
文章浏览阅读128次。PAT菜鸡进化史_乙级_1003“答案正确”是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的“答案正确”大派送 —— 只要读入的字符串满足下列条件,系统就输出“答案正确”,否则输出“答案错误”。得到“答案正确”的条件是: 1. 字符串中必须仅有 P、 A、 T这三种字符,不可以包含其它字符; 2. 任意形如 xPATx 的字符串都可以获得“答案正确”,其中 x 或者是空字符串,或..._1003 pat乙级 最优
CH340与Android串口通信_340串口小板 安卓给安卓发指令-程序员宅基地
文章浏览阅读5.6k次。CH340与Android串口通信为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio移植的具体步骤CH340串口通信驱动函数通信过程中重难点还存在的问题为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio为了在这个工程基础上进行改动,验证串口的数据和配置串口的参数,我首先在Eclipse上配置了安卓开发环境,注意在配置环境是..._340串口小板 安卓给安卓发指令