python 论坛自动发帖功能_python discuz发帖-程序员宅基地
技术标签: python网络爬虫
# -*- coding: utf-8 -*- """ @author: amtsing """ ''' Google翻译 ''' import execjs class Py4Js(): def __init__(self): self.ctx = execjs.compile(""" function TL(a) { var k = ""; var b = 406644; var b1 = 3293161072; var jd = "."; var $b = "+-a^+6"; var Zb = "+-3^+b+-f"; for (var e = [], f = 0, g = 0; g < a.length; g++) { var m = a.charCodeAt(g); 128 > m ? e[f++] = m : (2048 > m ? e[f++] = m >> 6 | 192 : (55296 == (m & 64512)
&& g + 1 < a.length && 56320 == (a.charCodeAt(g + 1) & 64512) ? (m = 65536 +
((m & 1023) << 10) + (a.charCodeAt(++g) & 1023), e[f++] = m >> 18 | 240, e[f++] = m >> 12 & 63 | 128) : e[f++] = m >> 12 | 224, e[f++] = m >> 6 & 63 | 128), e[f++] = m & 63 | 128) } a = b; for (f = 0; f < e.length; f++) a += e[f], a = RL(a, $b); a = RL(a, Zb); a ^= b1 || 0; 0 > a && (a = (a & 2147483647) + 2147483648); a %= 1E6; return a.toString() + jd + (a ^ b) }; function RL(a, b) { var t = "a"; var Yb = "+"; for (var c = 0; c < b.length - 2; c += 3) { var d = b.charAt(c + 2), d = d >= t ? d.charCodeAt(0) - 87 : Number(d), d = b.charAt(c + 1) == Yb ? a >>> d: a << d; a = b.charAt(c) == Yb ? a + d & 4294967295 : a ^ d } return a } """) def getTk(self, text): return self.ctx.call("TL", text) import urllib.request, urllib.parse def open_url(url): '''打开网页链接''' headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64;rv:23.0)Gecko/20100101
Firefox/23.0'} req = urllib.request.Request(url=url, headers=headers) response = urllib.request.urlopen(req) data = response.read().decode('utf-8') return data def translate(content): '''定义翻译函数''' if len(content) > 4891: print("翻译的长度超过限制!!!") return # 获取tk值 if len(content) > 4891: print("翻译的长度超过限制!!!") return js = Py4Js() tk = js.getTk(content) # 对输入内容编码 content = urllib.parse.quote(content) url = "http://translate.google.cn/translate_a/single?client=t&sl=en&tl=zh-CN&hl=zh-CN&dt
=at&dt=bd&dt=ex&dt=ld&dt=md&dt=qca&dt=rw&dt=rm&dt=ss&dt=t&ie=UTF-8&oe=UTF-8&
source=bh&otf=1&ssel=0&tsel=0&kc=1&tk=%s&q=%s" % (tk, content)
# 返回值是一个多层嵌套列表的字符串形式,解析起来还相当费劲,写了几个正则,发现也很不理想, # 后来感觉,使用正则简直就是把简单的事情复杂化,这里直接切片就Ok了 result = open_url(url) end = result.find("\",") if end > 4: print(' '+ result[4:end]) output = (' '+ result[4:end]) return str(output) ''' 识别验证码 ''' import os import requests from PIL import Image,ImageGrab import pytesseract from collections import Counter,OrderedDict # def downimg(url): # '''下载图片''' # with open ('verifycodepage.jpg','wb') as f: # s = requests.Session() # response = s.get(url) # f.write(response.content) def acumulate_colors(image): '''对色彩像素进行统计''' img = Image.open(image) pixdata = img.load() # c = Counter() # print(pixdata) colors = {} for y in range(img.size[1]): for x in range(img.size[0]): #print(pixdata[x, y]) # c.update(pixdata[x, y]) if pixdata[x, y] in colors: colors[pixdata[x, y]] += 1 else: colors[pixdata[x, y]] = 1 colors = sorted(colors.items(),key=lambda d:d[1],reverse=True) # c = OrderedDict(c) # print (c.values()) print(colors[2][0]) return colors # def gray(): # '''灰度化''' # img = Image.open('verifycodepage.jpg') # img.convert('L').save('灰色图.jpg') ''' convert() 是图像实例对象的一个方法,接受一个 mode 参数,用以指定一种色彩模式,mode 的取值可以是如下几种: · 1 (1-bit pixels, black and white, stored with one pixel per byte) · L (8-bit pixels, black and white) · P (8-bit pixels, mapped to any other mode using a colour palette) · RGB (3x8-bit pixels, true colour) · RGBA (4x8-bit pixels, true colour with transparency mask) · CMYK (4x8-bit pixels, colour separation) · YCbCr (3x8-bit pixels, colour video format) · I (32-bit signed integer pixels) · F (32-bit floating point pixels) 怎么样,够丰富吧?其实如此之处,PIL 还有限制地支持以下几种比较少见的色彩模式: LA (L with alpha), RGBX (true colour with padding) and RGBa。 ''' def binary(image): '''二值化''' img = Image.open(image) pixdata = img.load() for y in range(img.size[1]): for x in range(img.size[0]): # if pixdata[x, y] != colors[0][0]: # pixdata[x, y] = (255,255,255) # else: # pixdata[x, y] = (0,0,0) if pixdata[x, y][0] < 115: pixdata[x, y] = (0, 0, 0)# 黑色 for y in range(img.size[1]): for x in range(img.size[0]): if pixdata[x, y][1] < 90: pixdata[x, y] = (0, 0, 0) for y in range(img.size[1]): for x in range(img.size[0]): if pixdata[x, y][2] > 120: pixdata[x, y] = (255, 255, 255)# 白色 img.save('2值.jpg') ''' red 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的红色成份。 green 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的绿色成份。 blue 必要参数;Integer类型。数值范围从 0 到 255,表示颜色的蓝色成份。 ''' def denoisepoint(n,opt_point=0): '''去噪点''' direction = [ [1, 1], [1, 0], [1, -1], [0, -1], [-1, -1], [-1, 0], [-1, 1], [0, 1] ] num = 0 # 操作数量 point = 0 # 噪点数 img = Image.open('2值.jpg') pix = img.load() # 像素值 size = img.size #图片大小 # print(size) for y in range(size[1]): for x in range(size[0]): num += 1 if pix[x, y][0] < n: nearpoint = 0 for (a, b) in direction: if (x+a>= 0 and x+a <= size[0]-1) and (y+b>= 0 and y+b <= size[1]-1): # 如果遇到边界外的点不处理 if pix[x + a, y + b][0] < n: nearpoint += 1 if nearpoint <= opt_point: pix[x, y] = (255, 255, 255, 255) point += 1 # 噪点数 img.save('无噪点.jpg') return (num, point) def img2string(): '''图像转验证码''' img = Image.open('无噪点.jpg') pytesseract.pytesseract.tesseract_cmd= 'C:\\Program Files(x86)\\Tesseract-OCR\\tesseract' captcha = pytesseract.image_to_string(img,lang='eng') print(captcha) return captcha ''' 自动发帖 ''' import requests import re from lxml import etree from selenium import webdriver from selenium.webdriver.common.keys import Keys from selenium.webdriver.common.action_chains import ActionChains from selenium.common.exceptions import NoSuchElementException import random import time import newspaper from PIL import Image def get_content(url,language): '''获取正文''' content = newspaper.Article(url, language) content.download() content.parse() return content login_url = "http://www.****.so/member.php?mod=logging&action=login" def login(login_url): '''模拟登陆''' headers = { "User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML,
like Gecko) Chrome/58.0.3026.3 Safari/537.36" } for key,value in headers.items(): webdriver.DesiredCapabilities.PHANTOMJS['phantomjs.page.customHeaders{}'.format
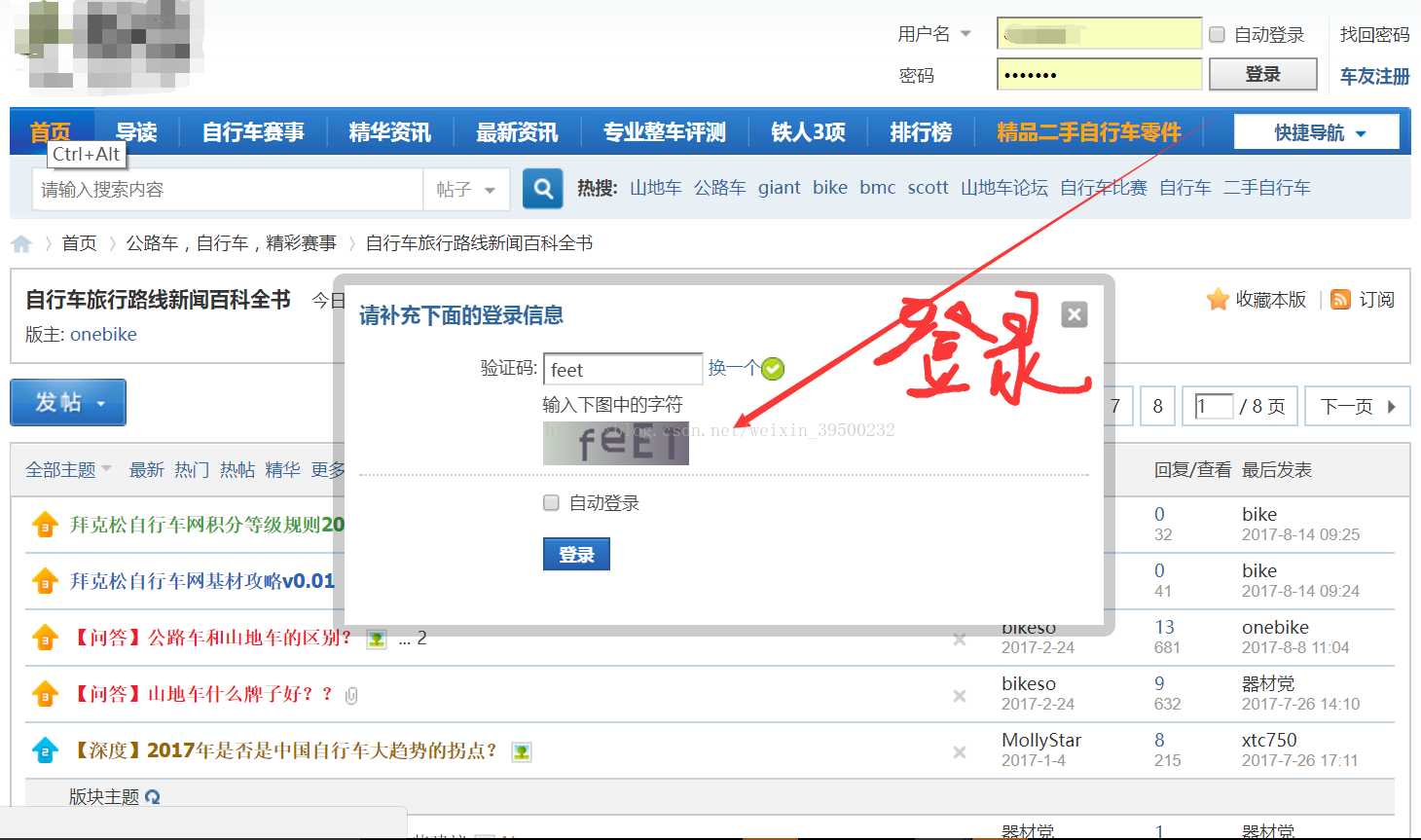
(key)] = value acountdictionary = { '*****':'*****', '******':'*****', '*******':'*****', } acount = random.choice(list(acountdictionary.items())) name = acount[0] password = acount[1] print(name,password) browser.get(login_url) time.sleep(3) browser.find_element_by_xpath('//input[@name="username"]').send_keys(name) browser.find_element_by_xpath('//input[@name="password"]').send_keys(password) # browser.get_screenshot_as_file('bks.png') # 截取当前网页,该网页有我们需要的验证码 # imgelement = browser.find_element_by_xpath('//*[@id="vseccode_cS"]/img') # 定位验证码 # location = imgelement.location # 获取验证码x,y轴坐标 # size = imgelement.size # 获取验证码的长宽 # rangle = (location['x']+ size['width'], # location['y']+ ize['height'], # location['x'] + size['width'], # location['y'] + size['height']) # 写成我们需要截取的位置坐标 # img = Image.open("bks.png") # 打开截图 # frame = img.crop(rangle) # 使用Image的crop函数,从截图中再次截取我们需要的区域 # frame.save('验证码.png') # img = Image.open('验证码.png') # img.show() # colors = acumulate_colors('验证码.png') # denoisepoint(10) # binary('验证码.png') # denoisepoint(100) # # devide(4) # captcha = img2string() browser.find_element_by_xpath('//input[@name="seccodeverify"]').send_keys(captcha) browser.find_element_by_xpath('//button[@name="loginsubmit"]').click() for i in range(1,20): try: # browser.execute_script('window.scrollTo(0, 5)') time.sleep(1) a = browser.find_element_by_xpath('//*[@id="ntcwin"]/table/tbody/tr/td[2]/div/i') a = a.text while a == '抱歉,验证码填写错误': time.sleep(4) if browser.current_url == 'http://www.bike.so/': # print(browser.current_url) # print('验证码正确!!') break else: print('你还有{0}尝试机会'.format(20 - i)) i += 1 if 20-i == 0: print('对不起验证码错误次数过多!!!') time.sleep(4) browser.close() break else: print('验证码错误!!!!请重新输入……') browser.find_element_by_xpath('// *[ @ id = "seccode_cS"] / div
/ table / tbody / tr / td / a').click() # browser.get_screenshot_as_file('bks.png') # 截取当前网页,该网页有我们
# 需要的验证码 # imgelement = browser.find_element_by_xpath('//*[@id="vseccode_cS"]
/img') # 定位验证码 # location = imgelement.location # 获取验证码x,y轴坐标 # size = imgelement.size # 获取验证码的长宽 # rangle = (location['x'] + size['width'], # location['y'] + size['height'], # location['x'] + size['width'], # location['y'] + size['height']) # 写成我们需要截取的位置坐标 # img = Image.open("bks.png") # 打开截图 # frame = img.crop(rangle) # 使用Image的crop函数,从截图中再次截取
# 我们需要的区域 # frame.save('验证码.png') # img = Image.open('验证码.png') # img.show() # colors = acumulate_colors('验证码.png') # denoisepoint(10) # binary('验证码.png') # denoisepoint(100) # # devide(4) # captcha = img2string() browser.find_element_by_xpath('//input[@name="seccodeverify"]').clear() browser.find_element_by_xpath('//input[@name="seccodeverify"]')
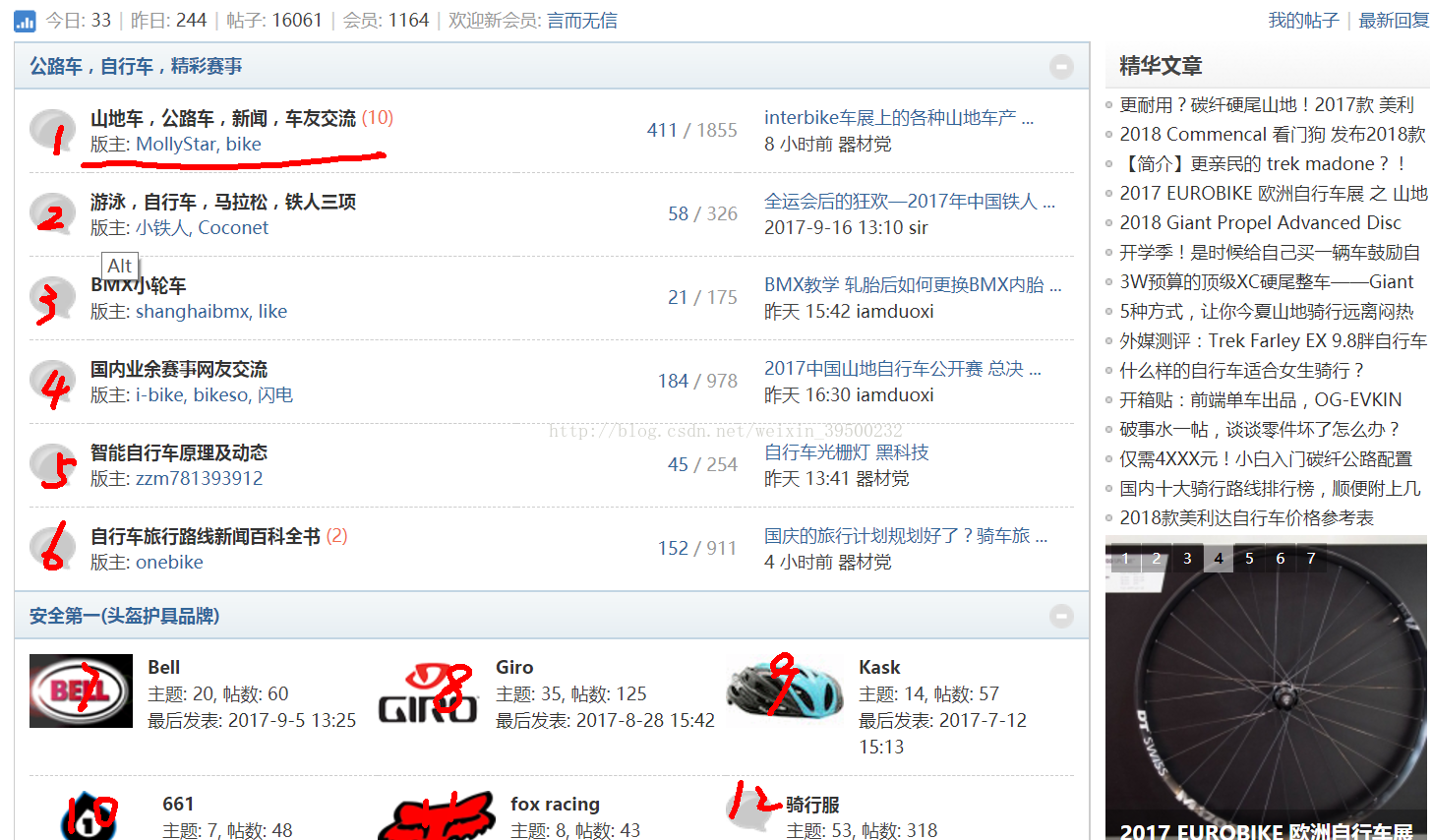
.send_keys(captcha) browser.find_element_by_xpath('//button[@name="loginsubmit"]').click() except NoSuchElementException: print("验证码正确!!") break def locat_plate(): '''定位发帖板块''' browser.execute_script('window.scrollTo(0, 100)') time.sleep(2) # 所有版块 plates = { 'plate1':"山地车,公路车,新闻,车友交流", 'plate2':"游泳,自行车,马拉松,铁人三项", 'plate3': "BMX小轮车", 'plate4': "国内业余赛事网友交流", 'plate5': "智能自行车原理及动态", 'plate6': "自行车旅行路线新闻百科全书", 'plate7': "骑行眼镜", 'plate8': "骑行书籍", 'plate9': "骑行饮料", 'plate10': "国产著名品牌/native", 'plate11': "Giant/捷安特", 'plate12': "Merida/美利达", 'plate13': "Lapierre/法国拉皮尔", 'plate14': "Trek/崔克", 'plate15': "Shimano/禧玛诺" } print(""" "请选择你要发表的版块:", 'plate1':"山地车,公路车,新闻,车友交流", 'plate2':"游泳,自行车,马拉松,铁人三项", 'plate3': "BMX小轮车", 'plate4': "国内业余赛事网友交流", 'plate5': "智能自行车原理及动态", 'plate6': "自行车旅行路线新闻百科全书", 'plate7': "骑行眼镜", 'plate8': "骑行书籍", 'plate9': "骑行饮料", 'plate10': "国产著名品牌/native", 'plate11': "Giant/捷安特", 'plate12': "Merida/美利达", 'plate13': "Lapierre/法国拉皮尔", 'plate14': "Trek/崔克", 'plate15': "Shimano/禧玛诺" """ ) browser.execute_script('window.scrollTo(100, 0.5*document.body.scrollHeight)') time.sleep(1) ratio = input('要重新定位到哪里?范围是0~0.5:') browser.execute_script('window.scrollTo(0.5*document.body.scrollHeight, {}*document.body.
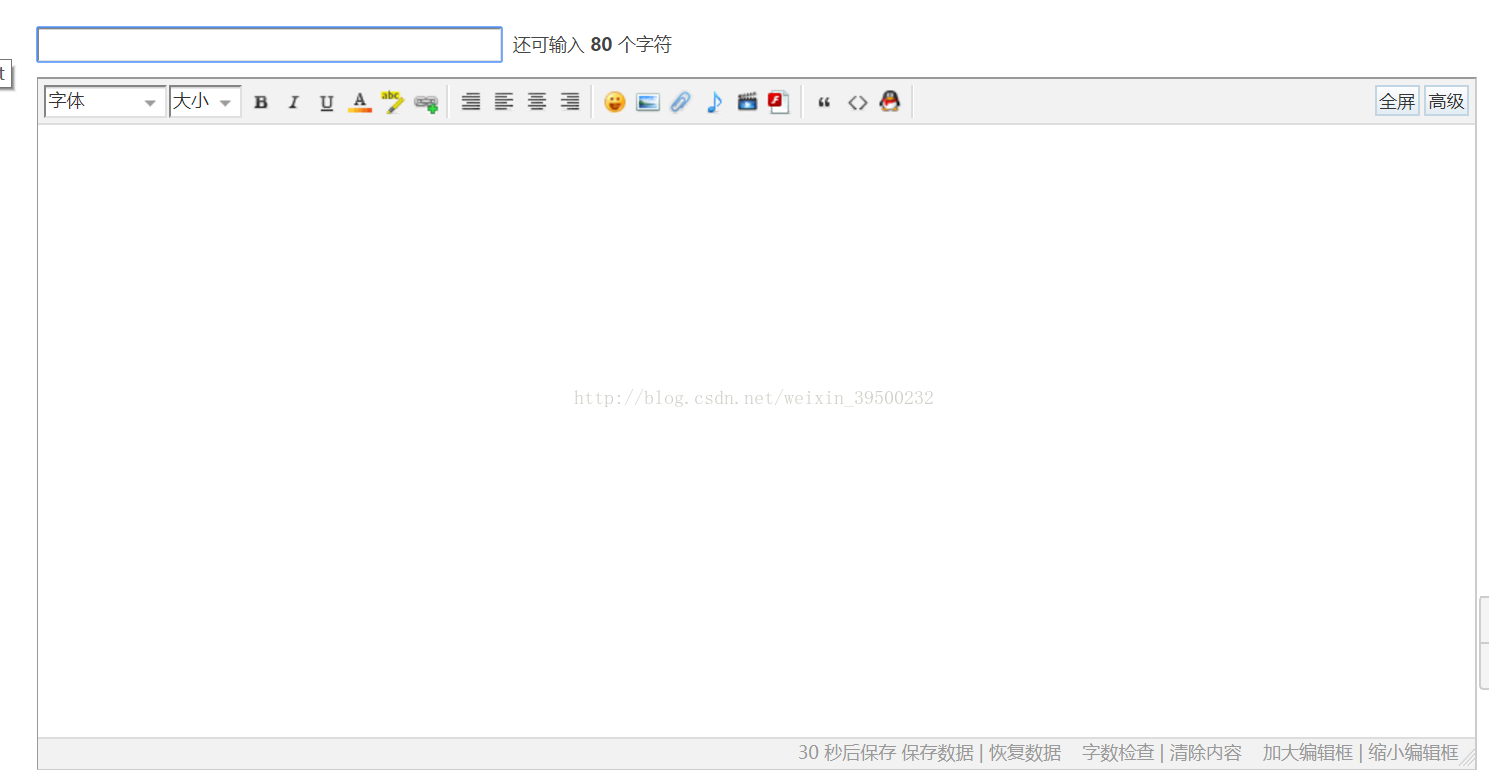
scrollHeight)'.format(ratio)) plate = input('请输入你要发帖的版块:') browser.find_element_by_link_text(plates[plate]).click() time.sleep(2) def random_pick(some_list, probabilities): '''定义不等概率抽样''' x = random.uniform(0, 1) cumulative_probability = 0.0 for item, item_probability in zip(some_list, probabilities): cumulative_probability += item_probability if x < cumulative_probability: break return item def post_content(content): '''自动发帖''' browser.find_element_by_id('newspecial').click() browser.switch_to.frame("e_iframe") browser.find_element_by_xpath('/html/body').send_keys(Keys.TAB) a = content.text.split('\n') postcontent = [] for i in a: if i != '': output = translate(i) + '\n' postcontent.append(output) else: beautystyle = [i, '……………………………………………………………………………………………………………………………………………', '=====================================================', '-----------------------------------------------------', '—————————————————————————————————————————————————————' ] probabilities = [0.8, 0.05, 0.05, 0.05, 0.05] line = random_pick(beautystyle, probabilities) postcontent.append(line + '\n') browser.find_element_by_xpath('/html/body').send_keys(postcontent) time.sleep(4) browser.switch_to.default_content() # 或者driver.switch_to.parent_frame() if content.title != '': # if flag == 0: title = translate(content.title) browser.find_element_by_xpath('//*[@id="subject"]').send_keys(title) else: browser.find_element_by_xpath('//*[@id="subject"]').send_keys(input('请输入标题:')) browser.execute_script('window.scrollTo(0, 300)') time.sleep(2) # browser.find_element_by_xpath('//button[@id="为了不给网站带来麻烦,
请大家不要使用此命令"]').click() # 编辑帖子 # browser.find_element_by_link_text('编辑').click() # browser.page_source if __name__ == '__main__': # 获取正文并翻译 urls = [ 'http://www.360doc.com/content/11/1021/10/7796166_157906146.shtml', ] for url in urls: # 登录论坛 browser = webdriver.Chrome() browser.maximize_window() login(login_url) content = get_content(url,'en') # 定位发帖版块 locat_plate() # 发帖 post_content(content) # browser.close()
智能推荐
GNU ARM Toolchain 初学者入门指南-程序员宅基地
文章浏览阅读6.2k次,点赞19次,收藏62次。什么是交叉编译?交叉编译过程!如何理解代码编译过程!arm-none-eabi-gccarm-none-eabi-asarm-none-eabi-ldarm-none-eabi-objcopy_arm toolchain
html页面上有一个id值为s1的,达内java第3次周考题黄色背景为正确答案.doc-程序员宅基地
文章浏览阅读2.5k次。达内java第3次周考题黄色背景为正确答案.doc1 选择题40 题,每题 2 分 1、 在 CSS 中,关于 BOX 的 margin 属性的叙述正确的是( )单选 A、 边距 margin 只能取一个值 B、 margin 属性的参数有 margin-left、margin-right、margin-top、 margin-bottom C、 margin 属性的值不可为 auto D、 ma..._html 页面上有一个 id 值为 s1 的 元素,现需要使用 javascript 代码
linux嵌入式串口与zigbee,zigbee的串口与STM32通信-程序员宅基地
文章浏览阅读1.2k次。在TI 的CC2530中,使用的是协议栈Z-Stack2007,现在想通过串口与STM32通信,当STM32给zigbee发送数据时,zigbee接收,只是接收的这部分代码TI给封装起来了,只知道在配置里头是这样的:/* @ZL 串口初始化 */halUARTCfg_t uartConfig;/* UART Configuration */uartConfig.configured ..._linux zigbee stack
jieba 计算2个句子的文本相似度(Python实现)_jieba判断语义重复-程序员宅基地
文章浏览阅读6.1k次,点赞7次,收藏33次。余弦相似度,又称为余弦相似性,是通过计算两个向量的夹角余弦值来评估他们的相似度。余弦相似度将向量根据坐标值,绘制到向量空间中,如最常见的二维空间。github 参考链接:https://github.com/ZhanPwBibiBibi/CHlikelihood# -*- coding: utf-8 -*-import jiebaimport numpy as npimport redef get_word_vector(s1,s2): """ :pa.._jieba判断语义重复
Openmesh函数库设计及与CGAL的对比_openmesh和cgal-程序员宅基地
文章浏览阅读4.7k次。Openmesh函数库设计及与CGAL的对比在前面写了CGAL模板类设计的一些思路,这里尝试写一点openmesh库的设计思路以及和CGAL的对比.虽然OPENMESH代码量小,不过还是只看懂皮毛,很大部分算是翻译帮助文档吧,主要用作笔记,方便以后继续分析。相对CGAL的功能强大和庞大(包含大量计算几何算法的实现),Openmesh显得更加小巧轻量化,它更专_openmesh和cgal
常用验证函数-程序员宅基地
文章浏览阅读1.1k次。//函数名:chksafe//功能介绍:检查是否含有"",//,"/"//参数说明:要检查的字符串//返回值:0:是 1:不是function chksafe(a){ return 1;/* fibdn = new Array ("" ,"//", "、", ",", ";", "/"); i=fibdn.length; j=a.length; for (ii=0;ii { for (
随便推点
a*算法流程图_关于流程图,你想知道的都在这里-程序员宅基地
文章浏览阅读9.5k次,点赞3次,收藏7次。为大家精选了10片优秀的流程图文章~画了多年的流程图,你真的画规范了吗?如何画逻辑流程图,这个技能你Get了没?流程图那么多,你数得过来吗?产品的三种流程图,你都知道吗?三种常见「产品流程图」是如何思考与绘制出来的?PM小技巧——流程图&产品原型关于流程图元素定义、结构分类;以及,我有一些技巧告诉你线框流程图:一款用于工作流程或APP的UX交付一次流程图设计的思考案例分析:绘制流程图需要注..._a* algorithm flowchart
计算机usb接口禁用,台式机usb接口禁用了怎么办-程序员宅基地
文章浏览阅读7.2k次。我们的台式机接口有时候用不了,可能是被禁用了,那要怎么样解决呢?下面由学习啦小编给你做出详细的台式机usb接口禁用了解决方法介绍!希望对你有帮助!台式机usb接口禁用了解决方法一:一、检查是否禁用主板usb设备。进入bios屏蔽掉usb,进入bios选择 Devices - USB Setup- Front USB Ports- 将该项改为 Enable; 按F10保存并退出。二、在控制面板里检查..._主机的usb接口封了怎么用
IDEA连接Mysql失败:下载驱动失败,Failed todownload Cannot download Read timed out_idea com.mysql:mysql-connector下载卡住-程序员宅基地
文章浏览阅读482次,点赞7次,收藏8次。解决:1. 手动加入jar包2.选择自己maven仓库中存在mysql-connector3. 选择完毕后,确定使用:4. 进行测试连接_idea com.mysql:mysql-connector下载卡住
Java连接Redis存取数据(详细)_redis导入导出数据java-程序员宅基地
文章浏览阅读6.5k次,点赞4次,收藏30次。Java连接Redis存取数据一.相关工具二.准备工作1.启动redis2.外部连接测试3.新建连接。4.连接成功三.新建jedis项目1.新建项目2.命名项目3.引入相关jar包4.引入 junit5.新建包com.redis.test四.编写代码1.redis.properties : redis连接配置文件2.RedisPoolUtil : 连接池配置工具3.SerializeUtil : ..._redis导入导出数据java
android dialog自定义布局 圆角背景 点击空白处不关闭 设置dialog大小-程序员宅基地
文章浏览阅读748次。1.首先上布局文件<?xml version="1.0" encoding="utf-8"?><LinearLayout ="http://schemas.android.com/apk/res/android" android:orientation="vertical" android:layout_width="300d
【算法】从记忆化搜索到递推——动态规划入门_记忆化搜索和递推-程序员宅基地
文章浏览阅读311次。本文的题目其实都比较简单,但是为了学习记忆化搜索,还是要用记忆化搜索再做一遍,不要眼高手低。由于 dp 数组的无后效性,因此还可以将 dp 数组优化成两个变量。将大问题分解成子问题,即 dfs (i) 可以分解成 dfs (i - 1)对于简单的 dp 题,直接写 dp 还更简单一些,硬写记忆化搜索还有点难。因为——有些动态规划直接去想递推公式太难了,所以可以先写成记忆化搜索。由于记忆化搜索是从将大问题分解成子问题的角度去考虑的,所以会简单一些。如果读者觉得本文的题目太简单了,可以去尝试一下。_记忆化搜索和递推