大数据毕业设计Hadoop+Spark+Hive景区游客满意度预测与优化 旅游推荐系统 Apriori算法 景区客流量预测 旅游大数据 旅游景点推荐 景点规划 计算机毕业设计 机器学习 深度学习-程序员宅基地
技术标签: hive 机器学习 spark 人工智能 hadoop 大数据 课程设计 大数据毕业设计
核心算法代码分享如下:
#使用PySpark完成部分机票指标分析
from pyspark.sql.types import StringType, StructField, IntegerType, DoubleType, StructType
from pyspark.sql.functions import col
from pyspark.sql import SparkSession
csv_format = 'com.databricks.spark.csv'
mysql_url = "jdbc:mysql://bigdata:3306/tour"
prop = {'user': 'root', 'password': '123456', 'driver': "com.mysql.jdbc.Driver"}
# 1.创建SparkSession
spark = SparkSession.builder.appName("table01_task").getOrCreate()
fields = [
StructField("name", StringType(), True),
StructField("username", StringType(), True),
StructField("content", StringType(), True),
StructField("ctime", StringType(), True),
StructField("sentiments", DoubleType(), True),
StructField("star", IntegerType(), True),
StructField("star_desc", StringType(), True),
StructField("province", StringType(), True),
StructField("supports", IntegerType(), True)
]
schema= StructType(fields)
# 2.读取本地文件路径
# flights_data = spark.read.format(csv_format).options( ending='utf-8').load(
# "hdfs://bigdata:9000/flink_fliggy_flight/flight/hdfs_flights.csv")
flights_data=spark.read.option("header", "false").schema(schema).csv("hdfs://bigdata:9000/ctrip/comments/comments.csv")
# 3.创建临时表
flights_data.createOrReplaceTempView("ods_comments")
# 4.分析sql
tables01_sql='''
select province,count(1) num
from ods_comments
group by province
order by num desc
'''
spark.sql(tables01_sql).write.jdbc(mysql_url, 'table01', 'overwrite', prop)


| 拟选题目 |
基于hadoop+spark的旅游数据分析与推荐系统的设计与实现 |
| 选题依据和研究意义 我国旅游景区众多,五千年的历史文明及广袤无垠的疆土为旅游产业提供了有力的客观支持,但是不同的用户对景区地理位置、景观特点、人文历史、出行方式选择等旅游服务需求不尽相同。用户在庞大的旅游资源信息中查询契合需求的出行路线,往往既花费时间又消耗精力,使用传统的旅游搜索方式对于旅游资源信息进行查询使用户感到极大困难[3]。而运用大数据技术对符合相似需求类型的旅游信息进行整理计算和归纳,能够为个体需求提供更加契合的精准服务和更加合理的旅行体验。使用基于Hadoop的MapReduce计算处理框架[2],对旅游景点评价数据进行归纳推理能够为用户提供更加精准舒适的旅行服务。 为了更好的满足人们的旅游需求,摒弃传统出行的各局限性跟上信息时代的高速发展,通过汇编语言开发出能够在线智能搜索的旅游网站,并且能够高效的对其管理的系统成为目前的发展趋势[3]。目前,旅游网站越来越多,其中绝大多是由旅游爱好者和文化部门所创建,百度搜索旅游网站就会看到各种不同的旅游网站,排名前几的有:携程,去哪儿,飞猪,同程,马蜂窝等热门旅游网站[2]。这类网站一般都是独立公司开发出来的产品,网站规模大,旅游信息也比较全面,客户访问人次多,打开他们的首页会发现除了内容布局有所出入,其推荐结果,热门景点,排行榜都是一样的必不可少。除了上述大型的旅游网站,还有一些小型旅游网站,这类小型旅游网站往往规模小,关于旅游信息的内容上也有所侧重,大多为驴友个人所创。 旅游网站给用户和管理员都带来了很大方便,一般旅游网站都是通过数据库管理、软件协作来实现用户与管理员之间的友好操作,由此设计而成[2]。计算机快捷高效的协助管理员解决管理工作可以实现对旅游数据管理自动化的巨大优势,因此计算机成为现代管理应用主要工具也是必然趋势。 |
|
| 文献综述(对已有相关代表性研究成果的综合介绍与评价) 国内研究现状: 近年来,随着中国旅游业的迅速发展,旅游数据呈现出爆炸性增长。国内对于基于大数据的旅游分析和推荐系统的研究逐渐增多。其中,一些研究集中于利用Hadoop和Spark这类大数据处理框架对旅游数据进行处理和分析。例如,去哪儿网的研究团队针对旅游评论数据,利用Spark进行情感分析,从而为旅游景区提供有益的建议。另外,还有一些研究结合了深度学习算法,如腾讯云团队开发的基于深度学习的旅游景点推荐系统,该系统能够根据用户的喜好和历史行为为其推荐合适的旅游目的地。 国外研究现状: 在国外,对于基于Hadoop+Spark的旅游数据分析与推荐系统的研究也相当活跃。例如,斯坦福大学的一个研究团队利用Spark对全球范围内的旅游数据进行处理和分析,旨在预测旅游趋势和热门目的地。他们的工作不仅对旅游业有重要影响,还对城市规划和政策制定具有指导意义。此外,谷歌也推出了自己的旅游推荐系统,该系统基于用户的历史搜索数据和点击行为,利用机器学习算法为用户推荐相关的旅游产品和服务。 发展趋势: 随着技术的不断进步,未来的旅游数据分析与推荐系统将更加智能化和个性化。基于大数据和机器学习的推荐系统将能够更好地理解用户的喜好和需求,从而为其提供更加精准的推荐。同时,随着物联网和传感器技术的发展,旅游数据来源将更加丰富,这为更深入的数据分析和预测提供了可能。 总的来说,基于Hadoop+Spark的旅游数据分析与推荐系统是一个充满挑战和机遇的研究领域。国内外的研究者们正努力探索如何更好地利用大数据技术为旅游业提供有价值的信息和服务,这将为推动旅游业的发展和提升用户体验起到重要作用。 |
|
| 研究内容(包括基本思路、框架、主要研究方式、方法等)
二、 系统框架
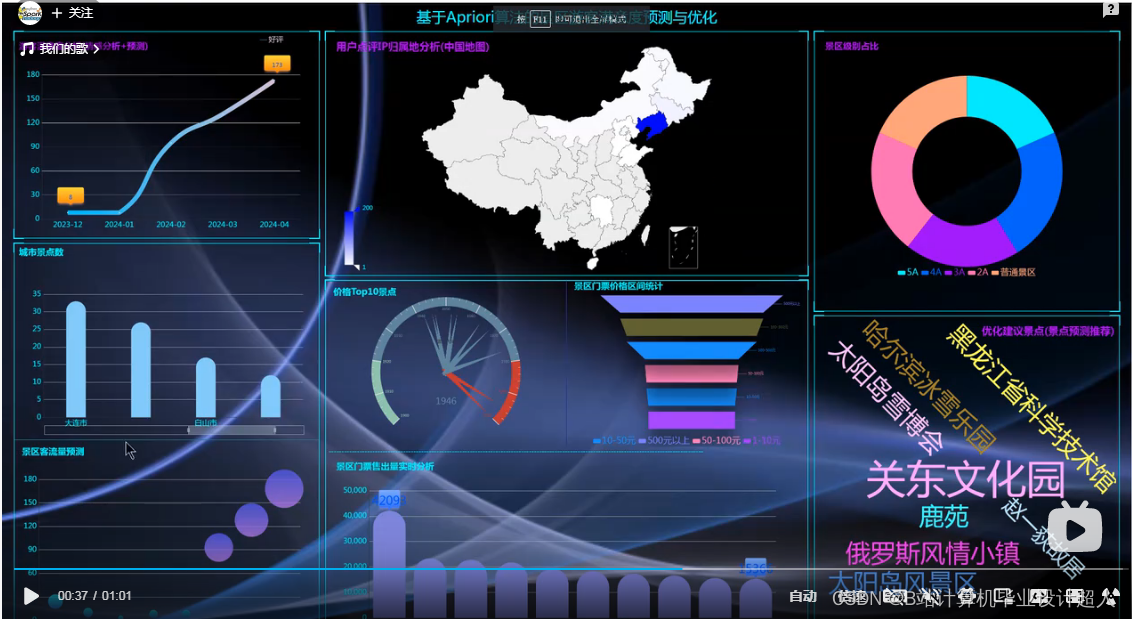
三、 研究方式和方法 (一)使用vmvare导入centos7镜像搭建Linux开发环境; (二)在虚拟机中安装并配置jdk1.8、hadoop、azkaban、hive、mysql等大数据生态圈组件; (三)使用Python的DrissionPage自动化工具框架爬取驴妈妈旅游网站本地景点数据,爬取完成以后存入.csv文件中; (四)编写shell脚本对虚拟机中的.csv原始数据进行数据清洗:去除重复数据、错误数据、补齐缺失字段、数据校校验等,最终的.csv旅游数据文件文件上传至hdfs文件服务器; (五)通过hive工具将hdfs中海量旅游数据.csv文件导入数据仓库; (六)编写hive脚本对数据仓库分DWA、DWB、DWT三层数仓架构; (七)离线指标编写shell脚本调用hive_sql语句对DWA层的数据进行多种维度计算,经过DWB、DWT层形成最终统计数据;实时指标编写Spark之Scala脚本对hdfs中的.csv文件进行分析; (八)编写shell脚本调用sqoop框架把DWT层的数据传输到mysql中方便制作BI报表; (九)封装以上全部shell脚本,使用azkaban调度工具进行一键调用; (十)使用Flask+echarts搭建可视化web环境。使用柱状图、饼状图、折线图、中国地图等直观展示可视化统计结果,指标有:各省星级景点数量、各等级景区收入占比、各省景点销售额、全国热门景点Top、各省景点平均票价、各省景点销售额占比、全国景点信息滚动动态图(景点名称、地区、等级、评分、评论数); (十一)启动Flask,完成可视化统计图web端展示; (十二)使用sprringboot+vue.js搭建推荐系统,进行个性化旅游景点推荐、购票等业务功能实现; |
|
| 研究进程安排 1、1月10日-2月26日:阅读文献,课题准备/熟悉开发环境 2、2月27日-3月19日:毕业实习,撰写实习报告 3、3月20日-3月30日:完成开题报告和文献翻译,熟练掌握开发环境和编程语言 4、4月1日-4月7日:系统需求分析和系统概要设计 5、4月8日-4月30日:系统详细分析与设计,代码编写 6、5月1日-5月7日:系统测试,资料整理 7、5月8日-5月15日:完成论文初稿撰写 8、5月16日-6月10日:论文修改及定稿,准备答辩 |
|
| 主要参阅文献 [1]范路桥,高洁,段班祥,等基于Python+ECharts的旅游销售数据可视化系统[J]电脑编程技巧与维护,2022(6):78-81. [2]常亮,曹玉婷,孙文平,等旅游推荐系统研究综述J计算机科学,2021.44(10):1-6. [5]孙文杰,张素莉,许骏,等,长白山旅游数据爬取及可视化分析[].吉林大学学报(信息科学版),2021.39(4):416-420. [4]南淑萍,王莉丽,王秀友Python Web开发案例教程:慕课版:使用Flask、Tornado、Django[M].北京:人民邮电出版社,2020. [5]黄源,蒋文豪,徐受蓉大数据分析:Python爬虫、数据清洗和数据可视化[M]北京:清华大学出版社,2020. [6]吕太之,颜悦,刘子为,等基于Flas和ECharts的科研数据可视化系统[].电脑与电信,2020(11):16-19. [7]张艺豪,盛丹红,翟丹丹基于Flask和ECharts的光缆数据管理平台[J].电脑编程技巧与维护,2021(6):94-95. [8]LIDMEI H,SHEN Y,et alECharts:a declarative framework for rapid construction of web-based visualization[J].Visual informatics,2023,2(2):136-146. [9]HUANG ML.HUANG TH,ZHANG XY.A noveI vMrtual node approach for interactive visual analytics of big datasets in parallel coordinatesJ].Future generation computer systems,2022,55.510-523. [10]蒙芳,霍建丽学习行为大数据可视化的网络数据库学习仿真(J],计算机仿真,2021,38(9):216-220. [11]SAKET B,KM H,BROWN E T,et al.Visualization by demonstration:an interaction paradigm for visual data explorationJ].IEEE transactions on visualization&computer graphics,2022,23(1):331-340. [12]陈东辉,高峰,刘娜,等气象台站历史沿革信息检索可视化系统设计与实现(J].计算机应用,2021,41(Z1):119-124. [13]范路桥,张良均,郑述招,等Web数据可视化(ECharts版)[M]北京:人民邮电出版社,2021. |
|
| 其它说明 |
|
| 指导教师是否同意开题 签名: 年 月 日 |
|
| 教研室教学负责人签署 签名: 年 月 日 |
|
| 说明: 1、开题报告工作从第七学期学生确定毕业设计(论文)题目后开始,在教师指导下,学生通过调研、收资后,于第八学期第四周前完成。 2、纸张填写不够可另加附页。 |
|
智能推荐
什么是内部类?成员内部类、静态内部类、局部内部类和匿名内部类的区别及作用?_成员内部类和局部内部类的区别-程序员宅基地
文章浏览阅读3.4k次,点赞8次,收藏42次。一、什么是内部类?or 内部类的概念内部类是定义在另一个类中的类;下面类TestB是类TestA的内部类。即内部类对象引用了实例化该内部对象的外围类对象。public class TestA{ class TestB {}}二、 为什么需要内部类?or 内部类有什么作用?1、 内部类方法可以访问该类定义所在的作用域中的数据,包括私有数据。2、内部类可以对同一个包中的其他类隐藏起来。3、 当想要定义一个回调函数且不想编写大量代码时,使用匿名内部类比较便捷。三、 内部类的分类成员内部_成员内部类和局部内部类的区别
分布式系统_分布式系统运维工具-程序员宅基地
文章浏览阅读118次。分布式系统要求拆分分布式思想的实质搭配要求分布式系统要求按照某些特定的规则将项目进行拆分。如果将一个项目的所有模板功能都写到一起,当某个模块出现问题时将直接导致整个服务器出现问题。拆分按照业务拆分为不同的服务器,有效的降低系统架构的耦合性在业务拆分的基础上可按照代码层级进行拆分(view、controller、service、pojo)分布式思想的实质分布式思想的实质是为了系统的..._分布式系统运维工具
用Exce分析l数据极简入门_exce l趋势分析数据量-程序员宅基地
文章浏览阅读174次。1.数据源准备2.数据处理step1:数据表处理应用函数:①VLOOKUP函数; ② CONCATENATE函数终表:step2:数据透视表统计分析(1) 透视表汇总不同渠道用户数, 金额(2)透视表汇总不同日期购买用户数,金额(3)透视表汇总不同用户购买订单数,金额step3:讲第二步结果可视化, 比如, 柱形图(1)不同渠道用户数, 金额(2)不同日期..._exce l趋势分析数据量
宁盾堡垒机双因素认证方案_horizon宁盾双因素配置-程序员宅基地
文章浏览阅读3.3k次。堡垒机可以为企业实现服务器、网络设备、数据库、安全设备等的集中管控和安全可靠运行,帮助IT运维人员提高工作效率。通俗来说,就是用来控制哪些人可以登录哪些资产(事先防范和事中控制),以及录像记录登录资产后做了什么事情(事后溯源)。由于堡垒机内部保存着企业所有的设备资产和权限关系,是企业内部信息安全的重要一环。但目前出现的以下问题产生了很大安全隐患:密码设置过于简单,容易被暴力破解;为方便记忆,设置统一的密码,一旦单点被破,极易引发全面危机。在单一的静态密码验证机制下,登录密码是堡垒机安全的唯一_horizon宁盾双因素配置
谷歌浏览器安装(Win、Linux、离线安装)_chrome linux debian离线安装依赖-程序员宅基地
文章浏览阅读7.7k次,点赞4次,收藏16次。Chrome作为一款挺不错的浏览器,其有着诸多的优良特性,并且支持跨平台。其支持(Windows、Linux、Mac OS X、BSD、Android),在绝大多数情况下,其的安装都很简单,但有时会由于网络原因,无法安装,所以在这里总结下Chrome的安装。Windows下的安装:在线安装:离线安装:Linux下的安装:在线安装:离线安装:..._chrome linux debian离线安装依赖
烤仔TVの尚书房 | 逃离北上广?不如押宝越南“北上广”-程序员宅基地
文章浏览阅读153次。中国发达城市榜单每天都在刷新,但无非是北上广轮流坐庄。北京拥有最顶尖的文化资源,上海是“摩登”的国际化大都市,广州是活力四射的千年商都。GDP和发展潜力是衡量城市的数字指...
随便推点
java spark的使用和配置_使用java调用spark注册进去的程序-程序员宅基地
文章浏览阅读3.3k次。前言spark在java使用比较少,多是scala的用法,我这里介绍一下我在项目中使用的代码配置详细算法的使用请点击我主页列表查看版本jar版本说明spark3.0.1scala2.12这个版本注意和spark版本对应,只是为了引jar包springboot版本2.3.2.RELEASEmaven<!-- spark --> <dependency> <gro_使用java调用spark注册进去的程序
汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用_uds协议栈 源代码-程序员宅基地
文章浏览阅读4.8k次。汽车零部件开发工具巨头V公司全套bootloader中UDS协议栈源代码,自己完成底层外设驱动开发后,集成即可使用,代码精简高效,大厂出品有量产保证。:139800617636213023darcy169_uds协议栈 源代码
AUTOSAR基础篇之OS(下)_autosar 定义了 5 种多核支持类型-程序员宅基地
文章浏览阅读4.6k次,点赞20次,收藏148次。AUTOSAR基础篇之OS(下)前言首先,请问大家几个小小的问题,你清楚:你知道多核OS在什么场景下使用吗?多核系统OS又是如何协同启动或者关闭的呢?AUTOSAR OS存在哪些功能安全等方面的要求呢?多核OS之间的启动关闭与单核相比又存在哪些异同呢?。。。。。。今天,我们来一起探索并回答这些问题。为了便于大家理解,以下是本文的主题大纲:[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JCXrdI0k-1636287756923)(https://gite_autosar 定义了 5 种多核支持类型
VS报错无法打开自己写的头文件_vs2013打不开自己定义的头文件-程序员宅基地
文章浏览阅读2.2k次,点赞6次,收藏14次。原因:自己写的头文件没有被加入到方案的包含目录中去,无法被检索到,也就无法打开。将自己写的头文件都放入header files。然后在VS界面上,右键方案名,点击属性。将自己头文件夹的目录添加进去。_vs2013打不开自己定义的头文件
【Redis】Redis基础命令集详解_redis命令-程序员宅基地
文章浏览阅读3.3w次,点赞80次,收藏342次。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。此时,可以将系统中所有用户的 Session 数据全部保存到 Redis 中,用户在提交新的请求后,系统先从Redis 中查找相应的Session 数据,如果存在,则再进行相关操作,否则跳转到登录页面。当数据量很大时,count 的数量的指定可能会不起作用,Redis 会自动调整每次的遍历数目。_redis命令
URP渲染管线简介-程序员宅基地
文章浏览阅读449次,点赞3次,收藏3次。URP的设计目标是在保持高性能的同时,提供更多的渲染功能和自定义选项。与普通项目相比,会多出Presets文件夹,里面包含着一些设置,包括本色,声音,法线,贴图等设置。全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,主光源和附加光源在一次Pass中可以一起着色。URP:全局只有主光源和附加光源,主光源只支持平行光,附加光源数量有限制,一次Pass可以计算多个光源。可编程渲染管线:渲染策略是可以供程序员定制的,可以定制的有:光照计算和光源,深度测试,摄像机光照烘焙,后期处理策略等等。_urp渲染管线