计算机组成原理-程序员宅基地
技术标签: c++
第一章 计算机系统概论
1.1 计算机的分类
计算机从总体上来说分为两大类:
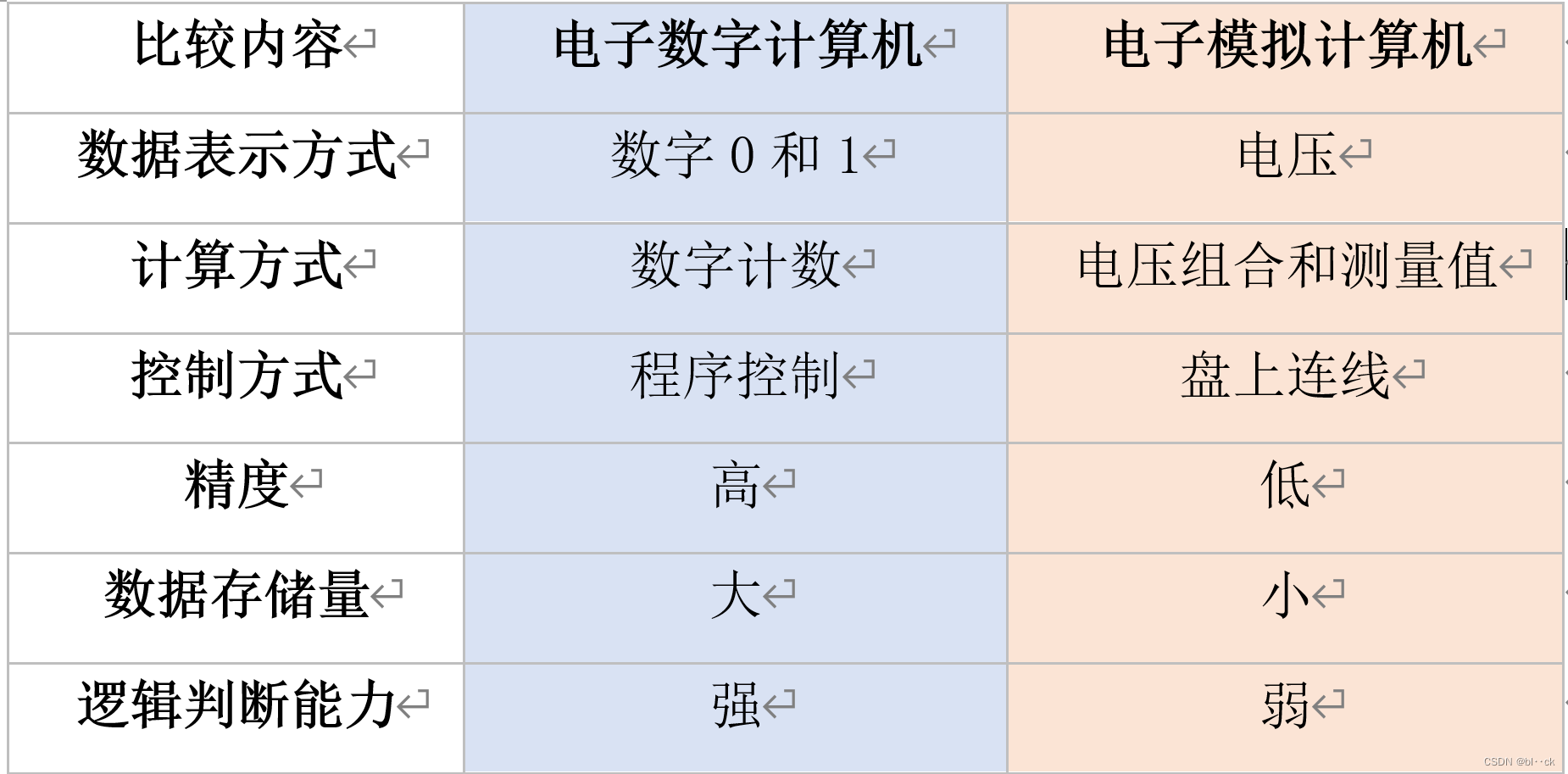
①电子模拟计算机
电子模拟计算机由于精度和解题能力都有限,所以应用范围较小。
②电子数字计算机
电子数字计算进一步可分为两种:
专用计算机
专用和通用是根据计算机的效率、价格、速度、运行的经济型性和适应性来划分的。
专用计算机是最有效、最经济和最快速的计算机,但是它的适应性很差。
通用计算机
通用计算机适应性很强,但是牺牲了效率、速度和经济性。
通用计算机可分为超级计算机、大型机、服务器、PC机、单片机和多核机六大类。
它们区别在于体积、简易性、功率损耗、性能指标、数据存储容量、指令系统规模和机器价格。
一般来说超级计算机主要用来科学计算,数据存储容量很大、结构复杂、价格昂贵。
单片机是只用一片集成电路做成的计算机,体积小、结构简单、性能指标较低、价格便宜。
1.2 计算机的发展简史
1.21计算机的五代变化:
第一代:1946~1957 ,电子管计算机
体积大,成本高,可靠性较低,在此期间,形成了计算机的基本体系,确定了程序设计的基本方法,数据处理机开始得到应用。
第二代:1958~1964 ,晶体管计算机
可靠性提高,体积缩小,成本降低,在此期间,工业控制机开始得到应用。
第三代:1965~1971 ,中小规模集成电路计算机
可靠性进一步提高,体积进一步缩小,成本进一步下降,在此期间形成机种多样化,成产系列化,使用系统化,小型计算机开始出现。
第四代:1972~1990 ,大规模和超大规模集成电路计算机
可靠性更进一步提高,提及更进一步缩小,成本更进一步降低,由几片大规模集成电路组成的微型计算机开始出现。
第五代:1991~xxxx ,巨大规模集成电路计算机
由一片巨大规模集成电路实现的单片计算机开始出现。
1.22 半导体存储器的发展
1.23 微处理器的发展
1.24 计算机的性能指标
吞吐量:表征一台计算机在某一时间间隔内能够处理的信息量。
响应时间:表征从输入有效到系统产生响应之间的时间度量,用时间单位来度量。
利用率:在给定的时间间隔内系统被实际使用的时间所占的比率,用百分比表示。
处理机字长:指处理机运算器中一次能够完成二进制数运算的位数,如32位、64位。
总线宽度:一般指CPU中运算器与存储器之间进行互连的内部总线二进制位数。
存储器容量:存储器中所有存储单元的总数目,通常用KB、MB、GB、TB来表示。
存储器带宽:单位时间内从存储器读出的二进制数信息量,一般用 字节数/秒 表示。
主频/时钟周期 :CPU的工作节拍受主时钟控制,主时钟不断产生固定频率的时钟,主时钟的频率(f)叫CPU的主频,度量单位是MHz(兆赫兹),GHz(吉赫兹)
主频的倒数称为CPU时钟周期(T),T=1/f,
CPU执行时间 :表示CPU执行一般程序所占用的CPU时间,可用下式计算:
CPU执行时间 = CPU 时钟周期数 × CPU时钟周期
CPI :表示每条指令周期数,即执行一条指令所需要的平均时钟周期数,可用下式计算:
CPI =执行某段程序所需要的CPU时钟周期数 ÷ 程序包含的指令条数
MISP :表示平均每秒执行多少百万条定点指令数,用下式计算:
MISP = 指令数 ÷(程序执行时间×10的6次方)
FLOPS :表示每秒执行浮点操作的次数,用来衡量机器浮点操作的性能,用下式计算:
FLOPS = 程序中的浮点操作次数 ÷ 程序执行时间(s)
1.3 计算机的硬件
1.31 硬件组成要素
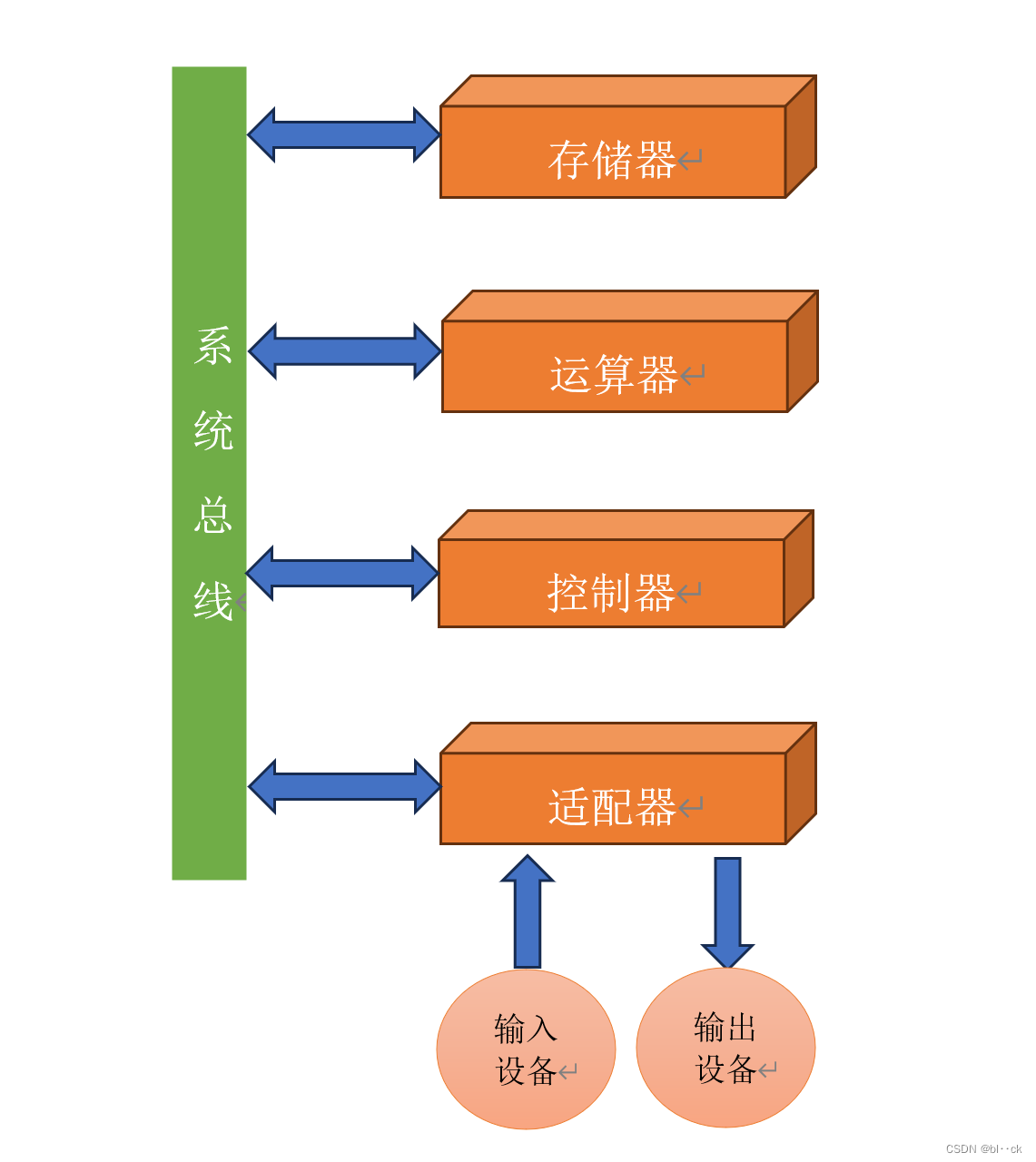
在电子计算机里,相当于算盘功能的部件,我们称之为运算器;
相当于纸那样具有 “记忆” 功能的部件,我们称之为存储器;
相当于笔那样把原始解题信息送到计算机或把运算结果显示出来的设备,我们称之为输入设备或输出设备;
而相当于人的大脑,能够自动控制整个计算过程的,称之为控制器。
1.32 运算器
运算器就好像是一个由电子线路构成的算盘,它的主要功能是进行加减乘除等算术运算。除此之外,还可以进行逻辑运算,因此通常称为ALU (算术逻辑运算部件)。
1.33 存储器
存储器的功能是保存或 “记忆” 解题的原始数据和解题步骤。为此,在运算前需要把参加运算的数据和解题步骤通过输入设备送到存储器中保存起来。
通常,在存储器中把保存一个数的16个触发器称为一个存储单元,存储器是由许多存储单元组成的。每个存储单元都有编号,称为地址。向存储器中存数或者从存储器中取数,都要按给定的地址来寻找所选的存储单元,相当于横格纸每一行存放一个数一样。
存储器所有存储单元的总数称为存储器的存储容量,存储容量越大,表示计算机记忆存储的信息越多。
半导体存储器的存储容量有限,计算机中可配备存储容量更大的磁盘存储器和光盘存储器,称为外存储器,相对而言,半导体存储器称为内存储器,简称内存。
1.34 控制器
控制器是计算机发号施令的部件,它控制计算机的各部分有条不紊的进行工作,更具体的讲,控制器的任务是从内存中取出解题步骤加以分析,然后执行某种操作。
1.计算程序
运算器只能完成加减乘除四则运算以及其他一些辅助操作。对于比较复杂的计算题目,计算机在运算前面必须完成一步一步简单的加减乘除等基本操作来做。每一个基本操作就叫做一条指令,而解算某一问题的一串指令序列,叫做该问题的计算程序,简称为程序。
2.指令的形式
每条指令应当明确告诉控制器,从存储器的哪个单元取数,并进行何种操作。这样可知指令的内容由两部分组成,即操作的性质和操作数的地址。前者称为操作码,后者称为地址码。形式如下:
| 操作码 | 地址码 |
其中操作码应指出指令所进行的操作,如加、减、乘、除、取数、存数等;而地址码表示参加运算的数据应从存储器的哪个单元中取来,或运算的结果应该存到哪个单元去。
指令数码化以后,就可以和数据一样放入存储器。存储器的任何位置既可以存放数据也可以存放指令,不过一般是分开存放。
将解题的程序(指令序列)存放到存储器中称为存储程序,而控制器依据存储的程序来控制全机协调地完成计算机的任务叫程序控制。
存储程序按照地址顺序执行,这就是冯·诺依曼型计算机的设计思想,也是机器自动化工作的关键。由于指令和数据放在同一个存储器,称为冯·诺依曼结构;如果指令和数据分别放在两个存储器,称为哈佛结构,显然哈佛结构的计算机速度更快。
一台计算机通常有十几种基本指令,从而构成了该计算机的指令系统。指令系统不仅是硬件设计的依据,而且是软件设计的基础。因此,指令系统是衡量计算机性能的一个重要标志。
3.控制器的基本任务
计算机进行计算时,指令必须是按一定的顺序一条接一条的进行,控制器的基本任务,就是按照计算机程序所排的指令序列,先从存储器取出一条指令放在控制器中,对该指令的操作码由译码器进行分析判别,然后根据指令性质,执行这条指令,进行相应的操作。
以此类推。通常把取指令的一段时间叫做取指周期,而把执行指令的一段时间叫做执行周期,因此,控制器反复交替地处在取指周期与执行周期中。
每取出一条指令,控制器中的指令计数器就加一,从而为取下一条指令做好准备,这也就是指令在存储器中顺序存放的原因。
在计算机系统中,运算器和控制器通常被组合在一个集成电路芯片中,合成为中央处理器,简称处理器(CPU)。
4.指令流和数据流
由于计算机仅使用 0 和 1 两个二进制数字,所有用 “ 位 ” (bit) 作为数字计算机的最小信息单位。当CPU想存储器送入或从存储器取出信息时,不能存在单个的 “ 位 ” ,而用B(字节)和 W(字)等较大的信息单位来工作。
一个 “字节” 由8位二进制信息组成,而一个 “字” 则至少由一个以上的字节组成。通常把组成一个字的二进制位数叫字长。
由于计算机使用的信息既有指令又有数据,所以计算机字既可以代表指令,也可以代表数据。
如果某字代表要处理的数据,则称为数据字;如果某字为一条指令,则称指令字。
指令和数据统统放在内存中,从形式上看,都是二进制数码,然而控制器可以区分。
一般来讲,取指周期中从内存读出的信息流是指令流,它流向控制器;而在执行周期中从内存读出的信息流是数据流,它由内存流向运算器。
1.35 适配器与输入/输出设备
键盘,鼠标等设备,作用是将人们所熟悉的某种信息形式变为机器内部所能接受和识别的二进制信息形式。
计算机的输入/输出设备通常称为外围设备。这些外围设备不是直接与高速工作的主机相连,而是通过适配器部件与主机相连,适配器的作用相当于一个转换器,它可以保证外围设备用计算机系统特性所要求的形式发送或接收信息。
计算机系统还必须有总线,系统总线是构成计算机系统的骨架,是多个系统部件之间进行数据传送的公共通路。借助系统总线,计算机在各系统部件之间实现传送地址、数据和控制信息的操作。
1.4 计算机的软件
1.41 软件的组成与分类
上面说过,,现代电子计算机是由运算器、存储器、控制器、适配器、总线和输入/输出设备组成的。这些部件或设备都是由元器件构成的有形物体,因而称为硬件或硬件设备。
事实上,利用电子计算机进行计算、控制或做其他工作时,需要有各种用途的程序。因此,凡是用于一台计算机的各种程序,统称为这台计算机的程序或软件系统。
计算机软件一般分为两大类:一类叫系统程序,一类叫应用程序。
系统程序
系统程序是用来简化程序设计,简化使用方法,提高计算机的使用效率,发挥和扩大计算机的功能及用途。包括以下四类:①各种服务性程序 ②语言程序 ③操作系统 ④数据库管理系统。
应用程序
应用程序是用户利用计算机来解决某些问题而编制的程序,如工程设计程序、数据处理程序、自动控制程序、企业管理程序、情报检索程序、科学计算程序等。随着计算机的广泛应用,这类程序的种类越来越多。
1.42 软件的发展演变
如同硬件一样,计算机软件也是在不断发展的。
在早期的计算机中,人们是直接用机器语言(即机器指令代码)来编写程序的,称为手编程序。
这种用机器语言书写的程序,计算机完全可以 “ 识别 ” 并能执行,所以又叫目的程序。
为了编写程序方便和提高机器的使用效率,人们用一些约定的文字、符号和数字按规定的格式来表示各种不同的指令,然后再用这些特殊符号表示的指令来编写程序。这就是所谓的汇编语言,它是一种能被转化为二进制文件的符号语言。
对人类来讲,符号语言简单直观、便于记忆,比二进制数表示的机器语言方便了很多,但是计算机只 “ 认识 ” 机器语言而不认识这些文字、数字、符号,为此创造了一种程序,叫汇编器。汇编器的作用相当于一个翻译员,借助于汇编器,计算机本身可以自动的把符号语言表示的程序(称为汇编语言程序)翻译成用机器语言表示的目的程序,从而实现了程序设计工作的部分自动化。
为了进一步实现程序自动化和便于程序交流,使不熟悉具体计算机的人也能很方便的使用计算机,又创造了各种接近于数学语言的算法语言。
所谓算法语言,是指按实际需要规定好的一套基本符号及由这套基本符号构成程序的规则。算法语言比较接近数学语言,直观通用,与具体机器无关。
用算法语言编写的程序称为源程序,但是这种源程序和汇编语言程序一样,是不能由机器直接识别和执行的,也必须给计算机配备一个即懂算法又懂机器语言的翻译。
通常采用的方法是给计算机配置一套用机器语言写的编译程序,它把源程序翻译成目的程序,然后机器执行目的程序,得出计算结果。由于目的程序一般不能独立运行,还需要一种叫做运行系统的辅助程序来帮助。通常,把编译程序和运行系统合称为编译器。
C语言程序转换为计算机上可运行的机器语言程序有四个步骤:C语言程序通过编译器首先被编译为汇编语言程序,然后通过汇编器汇编为机器语言的目标模块。链接器将多个模块与库程序组合在一起以解析所有的应用。加载器将机器代码放入合适的内存位置以便处理器执行。
显然人类的思维跟不上计算机的计算速度,要摆脱这种情况还需要依靠计算机来管理自己和管理用户,于是人们创造出一类程序,叫做操作系统。
操作系统是随着硬件和软件的不断发展而逐渐形成的一套软件系统,用来管理计算机资源(如处理器,内存,外部设备和各种编译、应用程序)和自动调度用户的作业程序,而使多个用户能有效地共用一套计算机系统。
操作系统的出现,使计算机的使用效率成倍地提高,并且为用户提供了方便的的使用手段和令人满意的服务质量。
根据不同的使用环境要求,操作系统目前大致分为批处理操作系统、分时操作系统、网络操作系统、实时操作系统等。个人计算机中广泛使用微软公司的 “ 视窗 ” 操作系统。
随着计算机在信息处理、情报检索及各种管理系统中的应用发展,要求大量处理某些数据,建立和检索大量的表格。这些数据和表格按照一定的规律组织起来,使得处理更加方便,检索更加迅速,用户使用更方便,于是出现了数据库。所谓数据库,就是实现有组织地,动态地存储大量相关数据,方便多用户访问的计算机软件、硬件资源组成的系统。数据库和数据库管理软件一起,组成了数据库管理系统。
计算机语言发展的方向是标准化、积木化、产品化,最终是向自然语言发展,它们能够自动生成程序。
1.5 计算机系统的层次结构
1.51 多级组成的计算机系统
计算机不能简单地认为是一种电子设备,而是一个十分复杂的硬、软件结合而成的整体。它通常由五个以上不同的级组成,每一级都能进行程序设计。
第一级:微程序设计级或逻辑电路级。这是一个实在的硬件级,由硬件直接执行。
第二级:一般机器级,也称机器语言级,它由微程序解释机器指令系统,这一级也叫硬件级。
第三级:操作系统级,由操作系统程序实现。这些操作系统由机器指令和广义指令组成,广义指令是操作系统定义和解释的软件指令,所以这一级也称混合级。
第四级:汇编语言级,它给程序人员提供一种符号形式语言,以减少程序编写的复杂性。如果应用程序采用汇编语言编写,则机器必须要有这一级的功能。
第五级:高级语言级,面向用户,为方便用户编写应用程序而设置的。这一级由各种高级语言编译程序支持和执行。
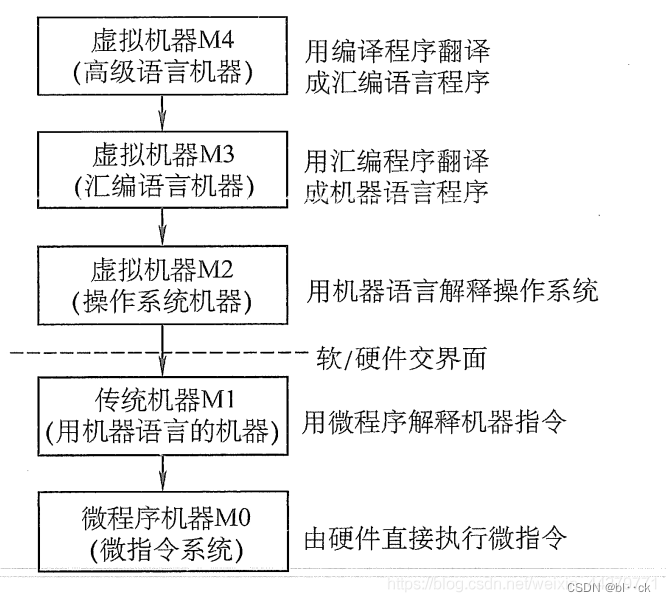
通常把没有配备软件的纯硬件系统称为“裸机”。第3层~第5层称为虚拟机,简单来说就是软件实现的机器。虚拟机只对该层的观察者存在,这里的分层和计算机网络的分层类似,对于某层的观察者来说,只能通过该层次的语言来了解和使用计算机,而不必关心下层是如何工作的。.层次之间的关系紧密,下层是上层的基础,上层是 下层的扩展。随着超大规模集成电路技术的不断发展,部分软件功能将由硬件来实现,因而软/硬件交界面的划分也不是绝对的。
1.52 软件与硬件的逻辑等价性
第二章 运算方法和运算器
2.1 数据与文字的表示方法
2.11 数据格式
2.12 数的机器码表示
2.13 字符与字符串的表示方法
2.14 汉字的表示方法
2.15 效验码
2.2 定点加法、减法运算
2.21 补码加法
2.22 补码减法
2.23 溢出概念与检测方法
2.24 基本的二进制加法/减法器
2.3 定点乘法运算
2.4 定点除法运算
2.41 原码除法算法原理
2.42 并行除法器
2.5 定点运算器的组成
2.51 逻辑运算
2.52 多功能算术/逻辑运算单元
2.53 内部总线
2.54 定点运算器的基本结构
2.6 浮点运算方法和浮点运算器
2.61 浮点加法、减法运算
2.62 浮点乘法、除法运算
2.63 浮点运算流水线
第三章 存储系统
3.1 存储器概述
3.1.1存储器的分类
1.按在计算机中的作用(层次)分类
1)主存储器:
简称主存,又称内存储器,用来存放计算机运行期间所需的程序和数据,CPU可以直接随机的对其访问,也可以和高速缓冲器(Cache)及辅助存储器交换数据。其特点是容量较小,存取速度较快,每位的价格较高。
2)辅助存储器
简称辅存,又称外存储器(外存),用来存放当前暂时不用的程序和数据,以及一些需要永久性保存的信息。辅存的内容需要调入主存后才能被CPU访问。其特点是容量大、存取速度较慢、单位成本低。
3)高速缓冲存储器
简称Cache,位于主存和CPU之间,用来存放当前CPU经常使用的指令和数据,以便CPU能高速的访问它们。Cache的存取速度可与CPU的速度相匹配,但是存储容量小、价格高。现代计算机通常将它们制作在CPU中。
2.按存储介质分类
按存储介质,存储器可分为磁表面存储器(磁盘、磁带)、磁芯存储器、半导体存储器(MOS型存储器、双极型存储器)和光存储器(光盘)。
3.按存取方式分类
1)随机存储器(RAM)
存储器的任何一个存储单元都可以随机存取,而且存取时间与存储单元的物理位置无关。其优点是读写方便、使用灵活,主要用作主存或高速缓冲存储器。RAM又分为静态RAM和动态RAM。
2)只读存储器(ROM)
存储器的内容只能随机读出而不能写入。信息一旦写入存储器就固定不变,即使断电,内容也不会丢失。因此,通常用它存放固定不变的程序、常数和汉字字库等。它与随机存储器可共同作为主存的一部分,统一构成主存的地址域。
由ROM派生出的存储器也包括可反复重写的类型,ROM和RAM的存取方式均为随机存取。广义上的只读存储器已电擦除等方式进行写入,其“只读”的概念没有保留,但仍保留了断电内容保留、随机读取特性,但其写入速度比读取速度慢的多。
3)串行访问存储器
对存储单元进行读写操作时,需按其物理位置的先后顺序寻址,包括顺序存取存储器(如磁带)与直接存取存储器(如磁盘、光盘)。
顺序存取存储器的内容只能按某种顺序存取,存取时间的长短与信息在存储体上的物理位置有关,其特点是存取速度慢。
直接存取存储器既不像RAM那样随机地访问任何一个存取单元,又不像顺序存取存储器那样完全按顺序存取,而是介于两者之间。存取信息时通常先寻找整个存储器中的某个小区域(如磁盘上的磁道),再在小区域顺序查找。
4.按信息的可保存性分类
断电后,存储信息即消失的存储器,称为易失性存储器,如RAM。断电后信息仍然保持的存储器,称为非易失性存储器,如ROM、磁表面存储器和光存储器。
若某个存储单元所存储的信息被读出时,原存储信息被破坏,称为破坏性读出;若读出时,被读单元存储信息不被破坏,则称为非破坏性读出。
具有破坏性读出的存储器,每次读出操作后,必须紧接一个再生的操作以便恢复被破坏的信息。
3.1.2存储器的性能指标
存储器有三个主要性能指标,即存储容量、单位成本和存储速度。这三个指标相互制约,设计存储器系统所追求的目标就是大容量、低成本和高速度。
1)存储容量 = 存储字数×字长。单位换算:1B(Byte,字节)= 8b(bit、位)。
存储字数表示存储器的地址空间大小,字长表示一次存取操作的数据量。
2)单位成本:每位价格 =总成本/总容量
3)存储速度:数据传输率 = 数据的宽度/存取周期(或称存储周期)。
①存取时间(Ta):存取时间是指从启动一次存储器操作到完成该操作所经历的时间,分为读出时间和写入时间。
②存取周期(Tm):存取周期又称读写周期或访问周期。它是指存储器进行一次完整的读写操作所需要的全部时间,即连续两次独立访问存储器操作(读或写操作)之间所需要的最小时间间隔。
③主存带宽(Bm):主存带宽又称数据传输率,表示每秒从主存进出信息的最大数量,单位位字/秒、字节/秒或位/秒。
存取时间不等于存取周期,通常存取周期大于存取时间。这是因为对任何一种存储器,在读写操作之后,总要有一段恢复内部状态的复原时间。对于破坏性读出的存储器,存取周期往往比存取时间大得多,甚至可以达到Tm = 2Ta,因为存储器中的信息读出后需要马上再生。
3.1.3多层级的存储系统
为了解决存储系统大容量、高速度和低成本三个相互制约的矛盾,在计算机系统中,通常采用多级存储器结构,在图中由上至下,价格越来越低、速度越来越慢、容量越来越大,CPU访问的频度也越来越低。
实际上,存储系统层次结构主要体现在Cache-主存层和主存-辅存层。前者主要解决CPU和主存速度不匹配的问题,后者主要解决存储系统的容量问题。在存储体系中,Cache、主存能与CPU直接交换信息,辅存则需要通过主存与CPU交换信息;主存与CPU、Cache、辅存都能交换信息。
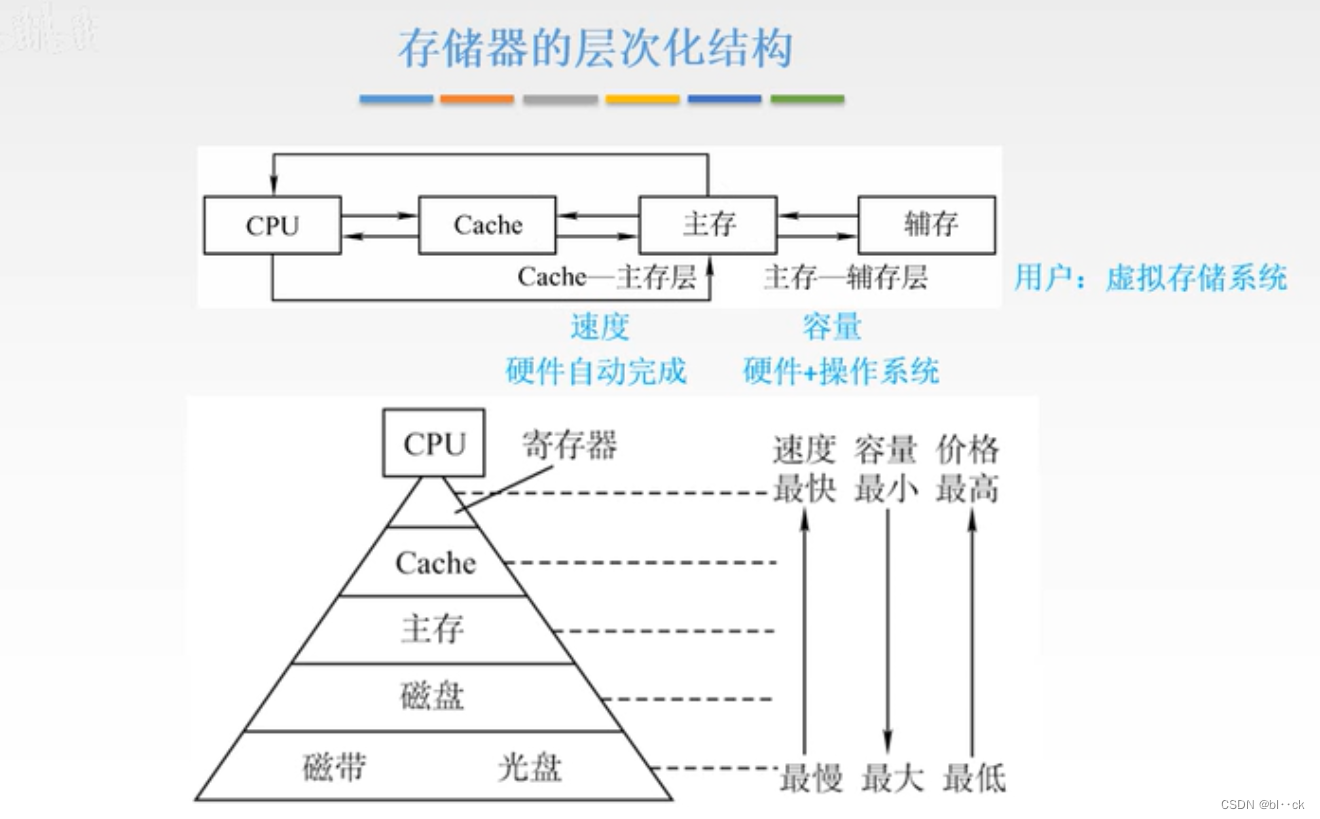
存储器层次结构的主要思想是上一层的存储器作为低一层存储器的高速缓存,从CPU的角度看,Cache-主存层速度接近于Cache,容量和价位却接近于主存。从主存-辅存层分析,其速度接近于主存,容量和价位却接近于辅存。这就解决了速度、容量、成本这三者之间的矛盾,现代计算机几乎都采用这种三级存储系统。
主存和Cache之间的数据调动是由硬件自动完成的,对所有程序员均是透明的;而主存和辅存之间的数据调动则是由硬件和操作系统共同完成,对应用程序员是透明的。
在主存-辅存层的不断发展中,逐渐形成了虚拟存储系统,在这个系统中程序员编程的地址范围与虚拟存储器的地址空间相对应,对具有虚拟存储器的计算机系统而言,编程时可用的地址空间远大于主存空间。
注意:在Cache-主存层和主存-辅存层中,上一层的内容都只是下一层中内容的副本,也即Cache(或主存)中的内容只是主存(或辅存)中内容的一部分。
3.2主存储器
主存储器由DRAM实现,靠处理器的那一层(Cache)则由SRAM实现,它们都属于易失性存储器,只要电源被切断,原来保存的信息便会丢失。
DRAM的每位价格低于SRAM,速度也慢于SRAM,价格差异主要是因为制造SRAM需要更多的硅。
ROM属于非易失性存储器。
3.2.1SRAM芯片和DRAM芯片
1.SRAM的工作原理
通常把存放一个二进制位的物理器件称为存储元,它是存储器的最基本的构件。地址码相同的多个存储元构成一个存储单元。若干存储单元的集合构成存储体。
静态随机存储器(SRAM)的存储元是用双稳态触发器(六晶体管MOS)来记忆信息的,因此即时信息被读出后,它仍然保持其原装不需要再生(非破坏性读出)。
SRAM的存取速度快,但集成度低,功耗较大,价格昂贵,一般用于高速缓冲存储器。
2.DRAM的工作原理
与SRAM的存储原理不同,动态随机存储器(DRAM)是利用存储元电路中栅极电容上的电荷来存储信息的,DRAM的基本存储元通常只使用一个晶体管,所以它比SRAM的密度要高很多。
相对于SRAM来说,DRAM具有容易集成、价位低、容量大、功耗低等优点,但DRAM的存取速度比SRAM的慢,一般用于大容量的主存系统。
DRAM电容上的电荷一般只能维持1~2ms,因此即使电源不断电,信息也会自动消失,为此,必须每隔一定时间必须刷新,通常取2ms,称为刷新周期,常用的刷新方式有三种:
1)集中刷新:指在一个刷新周期内,利用一段固定时间,依次对存储器的所有行进行逐一再生,在此期间停止对存储器的读写操作,称为“死时间”,又称访存“死区”。优点是读写操作时不受刷新工作的影响;缺点是在集中刷新期间(死区)不能访问存储器。
2)分散刷新:把对每行的刷新分散到各个工作周期中。这样,一个存储器的系统工作周期分为两部分:前半部分用于正常读、写或保持;后半部分用于刷新。这种刷新方式增加了系统的存取周期,如存储芯片的存取周期为0.5μs,则系统的存取周期1μs,优点是没有死区,缺点是加长了系统的存取周期,降低了整机速度。
3)异步刷新:异步刷新是前两种方法的结合,它既可以缩短“死时间”,又能充分利用最大刷新间隔2ms的特点,具体做法是将刷新周期除以行数,得到两次刷新操作之间的时间间隔t,利用逻辑电路每隔时间t产生一次刷新请求。这样可以避免使CPU连续等待过长的时间,而且减少了刷新次数,从根本上提高了整机的工作效率。
DRAM的刷新需要注意以下问题:
①刷新对CPU是透明的,即刷新不依赖于外部的访问;
②动态RAM的刷新单位是行,由芯片内部自行生成地址;
③刷新类似于读操作,但又有所不同,另外,刷新时不需要选片,即整个存储器中的所有芯片同时被刷新。
3.DRAM芯片的读写周期
4.SRAM和DRAM的比较
| 特点\类型 | SRAM | DRAM |
| 存储信息 | 触发器 | 电容 |
| 破坏性读出 | 否 | 是 |
| 需要刷新 | 不需要 | 需要 |
| 送行列地址 | 同时送 | 分两次送 |
| 运行速度 | 快 | 慢 |
| 集成度 | 低 | 高 |
| 存储成本 | 高 | 低 |
| 主要用途 | 高速缓存 | 主机内存 |
5.存储芯片的内部结构
3.2.2只读存储器
3.2.3主存储器的基本组成
3.2.多模块存储器
3.3主存储器与CPU的连接
3.4外部存储器
3.5高速缓冲存储器
第四章 指令系统
第五章 中央处理器
第六章 总线系统
第七章 外围设备
第八章 输入/输出系统
第九章 并行组织与结构
第十章 课程教学实验设计
第十一章 课程综合设计
智能推荐
while循环&CPU占用率高问题深入分析与解决方案_main函数使用while(1)循环cpu占用99-程序员宅基地
文章浏览阅读3.8k次,点赞9次,收藏28次。直接上一个工作中碰到的问题,另外一个系统开启多线程调用我这边的接口,然后我这边会开启多线程批量查询第三方接口并且返回给调用方。使用的是两三年前别人遗留下来的方法,放到线上后发现确实是可以正常取到结果,但是一旦调用,CPU占用就直接100%(部署环境是win server服务器)。因此查看了下相关的老代码并使用JProfiler查看发现是在某个while循环的时候有问题。具体项目代码就不贴了,类似于下面这段代码。while(flag) {//your code;}这里的flag._main函数使用while(1)循环cpu占用99
【无标题】jetbrains idea shift f6不生效_idea shift +f6快捷键不生效-程序员宅基地
文章浏览阅读347次。idea shift f6 快捷键无效_idea shift +f6快捷键不生效
node.js学习笔记之Node中的核心模块_node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是-程序员宅基地
文章浏览阅读135次。Ecmacript 中没有DOM 和 BOM核心模块Node为JavaScript提供了很多服务器级别,这些API绝大多数都被包装到了一个具名和核心模块中了,例如文件操作的 fs 核心模块 ,http服务构建的http 模块 path 路径操作模块 os 操作系统信息模块// 用来获取机器信息的var os = require('os')// 用来操作路径的var path = require('path')// 获取当前机器的 CPU 信息console.log(os.cpus._node模块中有很多核心模块,以下不属于核心模块,使用时需下载的是
数学建模【SPSS 下载-安装、方差分析与回归分析的SPSS实现(软件概述、方差分析、回归分析)】_化工数学模型数据回归软件-程序员宅基地
文章浏览阅读10w+次,点赞435次,收藏3.4k次。SPSS 22 下载安装过程7.6 方差分析与回归分析的SPSS实现7.6.1 SPSS软件概述1 SPSS版本与安装2 SPSS界面3 SPSS特点4 SPSS数据7.6.2 SPSS与方差分析1 单因素方差分析2 双因素方差分析7.6.3 SPSS与回归分析SPSS回归分析过程牙膏价格问题的回归分析_化工数学模型数据回归软件
利用hutool实现邮件发送功能_hutool发送邮件-程序员宅基地
文章浏览阅读7.5k次。如何利用hutool工具包实现邮件发送功能呢?1、首先引入hutool依赖<dependency> <groupId>cn.hutool</groupId> <artifactId>hutool-all</artifactId> <version>5.7.19</version></dependency>2、编写邮件发送工具类package com.pc.c..._hutool发送邮件
docker安装elasticsearch,elasticsearch-head,kibana,ik分词器_docker安装kibana连接elasticsearch并且elasticsearch有密码-程序员宅基地
文章浏览阅读867次,点赞2次,收藏2次。docker安装elasticsearch,elasticsearch-head,kibana,ik分词器安装方式基本有两种,一种是pull的方式,一种是Dockerfile的方式,由于pull的方式pull下来后还需配置许多东西且不便于复用,个人比较喜欢使用Dockerfile的方式所有docker支持的镜像基本都在https://hub.docker.com/docker的官网上能找到合..._docker安装kibana连接elasticsearch并且elasticsearch有密码
随便推点
Python 攻克移动开发失败!_beeware-程序员宅基地
文章浏览阅读1.3w次,点赞57次,收藏92次。整理 | 郑丽媛出品 | CSDN(ID:CSDNnews)近年来,随着机器学习的兴起,有一门编程语言逐渐变得火热——Python。得益于其针对机器学习提供了大量开源框架和第三方模块,内置..._beeware
Swift4.0_Timer 的基本使用_swift timer 暂停-程序员宅基地
文章浏览阅读7.9k次。//// ViewController.swift// Day_10_Timer//// Created by dongqiangfei on 2018/10/15.// Copyright 2018年 飞飞. All rights reserved.//import UIKitclass ViewController: UIViewController { ..._swift timer 暂停
元素三大等待-程序员宅基地
文章浏览阅读986次,点赞2次,收藏2次。1.硬性等待让当前线程暂停执行,应用场景:代码执行速度太快了,但是UI元素没有立马加载出来,造成两者不同步,这时候就可以让代码等待一下,再去执行找元素的动作线程休眠,强制等待 Thread.sleep(long mills)package com.example.demo;import org.junit.jupiter.api.Test;import org.openqa.selenium.By;import org.openqa.selenium.firefox.Firefox.._元素三大等待
Java软件工程师职位分析_java岗位分析-程序员宅基地
文章浏览阅读3k次,点赞4次,收藏14次。Java软件工程师职位分析_java岗位分析
Java:Unreachable code的解决方法_java unreachable code-程序员宅基地
文章浏览阅读2k次。Java:Unreachable code的解决方法_java unreachable code
标签data-*自定义属性值和根据data属性值查找对应标签_如何根据data-*属性获取对应的标签对象-程序员宅基地
文章浏览阅读1w次。1、html中设置标签data-*的值 标题 11111 222222、点击获取当前标签的data-url的值$('dd').on('click', function() { var urlVal = $(this).data('ur_如何根据data-*属性获取对应的标签对象