SPDK Thread 模型设计与实现_spdk c++-程序员宅基地
技术标签: spring SPDK c++无锁队列 C++后端开发 网络编程 C++Linux后端 Thread
Reactor – 单个CPU Core抽象,主要包含了:
- Lcore对应的CPU Core id
- Threads在该核心下的线程
- Events 这是一个spdk ring,用于事件传递接收
Thread – 线程,但它是spdk抽象出来的线程,主要包含了:
- io_channels资源的抽象,可以是bdev,也可以是具体的tgt
- tailq 线程队列,用于连接下一个线程
- name 线程的名称
- Stats 用于计时统计闲置和忙时时间的
- active_pollers 轮询使用的poller,非定时
- timer_pollers 定时的poller
- messages 这是一个spdk ring,用于消息传递接收
- msg_cache 事件的缓存
1.1 Reactor
对象g_reactor_state有五个状态对应了应用中reactors运行运行状态,
enum spdk_reactor_state {
SPDK_REACTOR_STATE_INVALID = 0,
SPDK_REACTOR_STATE_INITIALIZED = 1,
SPDK_REACTOR_STATE_RUNNING = 2,
SPDK_REACTOR_STATE_EXITING = 3,
SPDK_REACTOR_STATE_SHUTDOWN = 4,
};本文福利, 免费领取C++学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发,音视频开发,Qt开发)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
初始情况下是:
SPDK_REACTOR_STATE_INVALID状态,在spdk app(任意一个target,比如nvmf_tgt)启动时,即调用了spdk_app_start方法,会调用spdk_reactors_init,在这个方法中将会初始化所有需要被初始化的reactors(可以在配置文件中指定需要使用的Core,CPU Core 和reactor是一对一的)。并且会将g_reactor_state设置为SPDK_REACTOR_STATE_INITIALIZED。具体代码如下:
Int spdk_reactors_init(void)
{
// 初始化所有的event mempool
g_spdk_event_mempool = spdk_mempool_create(…);
// 为g_reactors分配内存,g_reactors是一个数组,管理了所有的reactors
posix_memalign((void **)&g_reactors, 64, (last_core + 1) * sizeof(struct spdk_reactor));
// 这里设置了reactor创建线程的方法,之后需要初始化线程的时候将会调用该方法
spdk_thread_lib_init(spdk_reactor_schedule_thread, sizeof(struct spdk_lw_thread));
// 对于每一个启动的reactor,将会初始化它们
// 初始化reactor过程,即为绑定lcore,初始化spdk ring、threads,对rusage无操作
SPDK_ENV_FOREACH_CORE(i) {
reactor = spdk_reactor_get(i);
spdk_reactor_construct(reactor, i);
}
// 设置好状态返回
g_reactor_state = SPDK_REACTOR_STATE_INITIALIZED;
return 0;
}在进入SPDK_REACTOR_STATE_INITIALIZED状态且spdk_app_start在创建了自己的线程并绑定到了reactors后,会调用spdk_reactors_start方法并将g_reactor_state设置为SPDK_REACTOR_STATE_RUNNING状态并会创建所有reactor的线程且轮询。
Void spdk_reactors_start(void) {
SPDK_ENV_FOREACH_CORE(i) {
if (i != current_core) { // 在非master reactor中
reactor = spdk_reactor_get(i); // 得到相应的reactor
// 设置好线程创建后的一个消息,该消息为轮询函数
rc = spdk_env_thread_launch_pinned(reactor->lcore, _spdk_reactor_run, reactor);
// reactor创建好线程并且会自动执行第一个消息
spdk_thread_create(thread_name, tmp_cpumask);
}
}
// 当前CPU core得到reactor,并且开始轮询
reactor = spdk_reactor_get(current_core);
_spdk_reactor_run(reactor);
}之前提到spdk_reactors_init方法中调用了spdk_thread_lib_init方法传入了创建thread的spdk_reactor_schedule_thread方法,在调用spdk_thread_create会回调该方法。这个方法它主要的功能就是告诉这个新创建的线程绑定创建该线程的reactor。
spdk_reactor_schedule_thread(struct spdk_thread *thread)
{
// 得到该线程设置的cpu mask
cpumask = spdk_thread_get_cpumask(thread);
for (i = 0; i < spdk_env_get_core_count(); i++) {
…. // 遍历cpu core
// 通过cpu mask找到对应的核心,并产生event
if (spdk_cpuset_get_cpu(cpumask, core)) {
evt = spdk_event_allocate(core, _schedule_thread, lw_thread, NULL);
break;
}
}
// 传递该event,即对应的reatcor会调用_schedule_thread方法,
spdk_event_call(evt);
}
_schedule_thread(void *arg1, void *arg2)
{
struct spdk_lw_thread *lw_thread = arg1;
struct spdk_reactor *reactor;
// 消息传递到对应的reactor后将该thread加入到reactor中
reactor = spdk_reactor_get(spdk_env_get_current_core());
TAILQ_INSERT_TAIL(&reactor->threads, lw_thread, link);
}
在SPDK_REACTOR_STATE_RUNNING后,此时所有reactor就进入了轮询状态。_spdk_reactor_run函数为线程提供了轮询方法:
static int _spdk_reactor_run(void *arg) {
while (1) {
// 处理reactor上的event消息,消息会在之后讲到
_spdk_event_queue_run_batch(reactor);
// 每一个reactor上注册的thread进行遍历并且处理poller事件
TAILQ_FOREACH_SAFE(lw_thread, &reactor->threads, link, tmp) {
rc = spdk_thread_poll(thread, 0, now);
}
// 检查reactor的状态
if (g_reactor_state != SPDK_REACTOR_STATE_RUNNING) {
break;
}
}
}而当spdk app被调用spdk_app_stop方法后将会相应的通知每一个reactor调用spdk_reactors_stop方法,将g_reactor_state赋值为SPDK_REACTOR_STATE_EXITING,即开始退出了。回到_spdk_reactor_run函数中,轮询将会被跳出,并且执行销毁线程的代码。
static int _spdk_reactor_run(void *arg) {
….. // 轮询
TAILQ_FOREACH_SAFE(lw_thread, &reactor->threads, link, tmp) {
thread = spdk_thread_get_from_ctx(lw_thread);
TAILQ_REMOVE(&reactor->threads, lw_thread, link);
spdk_set_thread(thread);
spdk_thread_exit(thread);
spdk_thread_destroy(thread);
}
}在这之后,主线程的_spdk_reactor_run会返回到spdk_reactors_start中,并将g_reactor_state赋值为SPDK_REACTOR_STATE_SHUTDOWN,返回到spdk_app_start中等待应用退出。
最后,总结一下reactors和CPU core以及spdk thread关系应该如图1所示
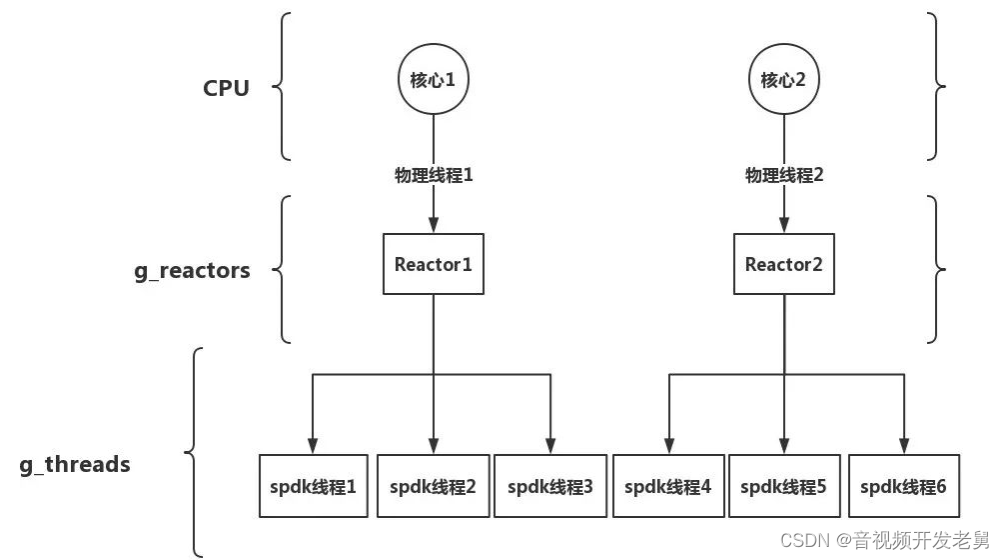
图1 CPU cores、reactors和thread关系图
Reactor生命周期流程图则如图2所示
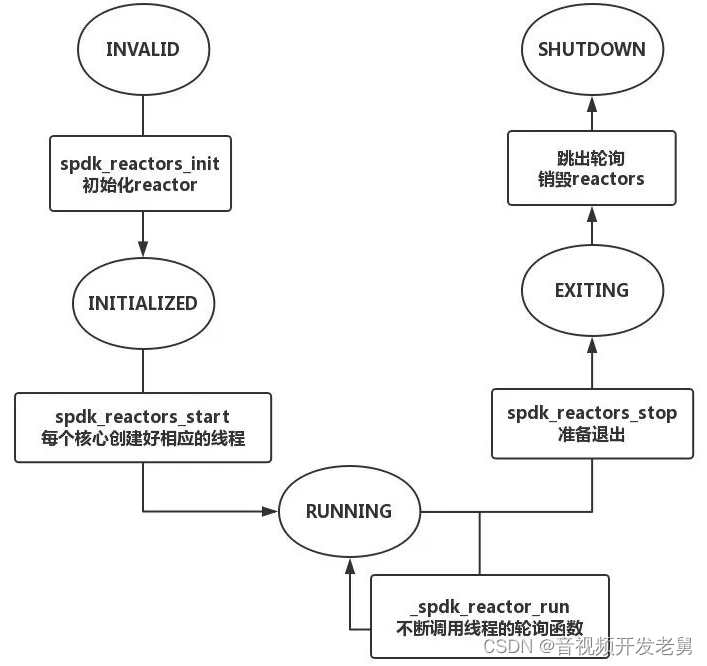
图2 reactor生命周期流程图
1.2 thread
当Reactors进行轮询时,除了处理自己的事件消息之外,还会调用注册在该reactor下面的每一个线程进行轮询。不过通常一个reactor只有一个thread,在spdk应用中,更多的是注册多个poller而不是注册多个thread。具体的轮询方法为:
Int spdk_thread_poll(struct spdk_thread *thread, uint32_t max_msgs, uint64_t now) {
// 首先先处理ring传递过来的消息
msg_count = _spdk_msg_queue_run_batch(thread, max_msgs);
// 调用非定时poller中的方法
TAILQ_FOREACH_REVERSE_SAFE(poller, &thread->active_pollers,
active_pollers_head, tailq, tmp) {
// 调用poller注册的方法之前,会对poller状态检测且转换
if (poller->state == SPDK_POLLER_STATE_UNREGISTERED) {
TAILQ_REMOVE(&thread->active_pollers, poller, tailq);
free(poller);
continue;
}
poller->state = SPDK_POLLER_STATE_RUNNING;
// 调用poller注册的方法
poller_rc = poller->fn(poller->arg);
// poller转换状态
poller->state = SPDK_POLLER_STATE_WAITING;
}
// 调用定时poller中的方法
TAILQ_FOREACH_SAFE(poller, &thread->timer_pollers, tailq, tmp) {
// 类似非定时poller过程,不过会检查是否到了预定的时间
if (now < poller->next_run_tick) break;
}
// 最后统计时间
}Io_device 和 io_channel在thread中也是非常重要的概念。它们的实现都在thread.c中,io_device是设备的抽象,io_channel是对该设备通道的抽象。一个线程可以创建多个io_channel . io_channel只能和一个io_device绑定,并且这个io_channel是别的线程使用不了的。
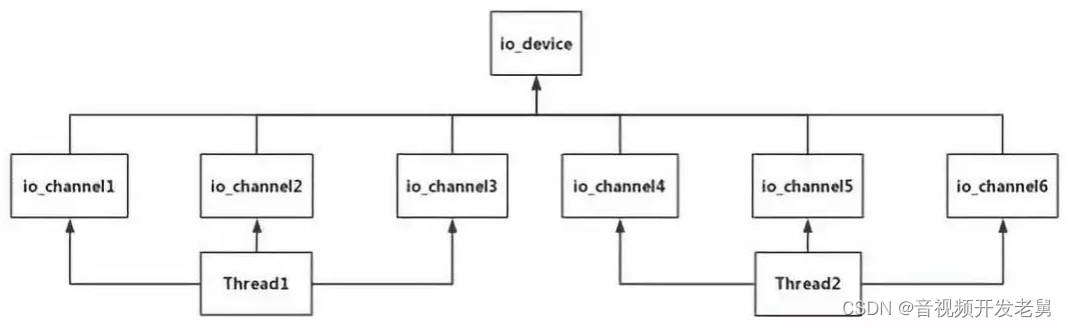
图 3 io_device、io_channel和线程关系图
Io_device结构
struct io_device {
void *io_device; // 抽象的device指针
char name[SPDK_MAX_DEVICE_NAME_LEN + 1]; // 名字
spdk_io_channel_create_cb create_cb; // io_channel创建的回调函数
spdk_io_channel_destroy_cb destroy_cb; // io_channel销毁的回调函数
spdk_io_device_unregister_cb unregister_cb; // io_device解绑的回调函数
struct spdk_thread *unregister_thread; // 不使用该device线程
uint32_t ctx_size; // ctx的大小,将会传给io_channel处理
uint32_t for_each_count; // io_channel的数量
TAILQ_ENTRY(io_device) tailq; // device队列头
uint32_t refcnt; // 计数器
bool unregistered; // 是否该device被注册
};可以看到,io_device实际上只提供了一些自身io_device的操作和io_channel相关的方法,具体的io_device实体其实是那个名字叫io_device的void指针。因为thread中的io_device只提供了thread这一层接口,具体的io操作每一个设备很难被抽象出来,所以这一层的接口只负责管理io_channel的创建、销毁和绑定等。
Io_channel的结构
struct spdk_io_channel {
struct spdk_thread *thread; // 绑定的线程
struct io_device *dev; // 绑定的io_device
uint32_t ref; // io_channel引用计数
uint32_t destroy_ref; // destroy前被引用的次数
TAILQ_ENTRY(spdk_io_channel) tailq; // io_channel 队列头
spdk_io_channel_destroy_cb destroy_cb; // io_channel销毁的回调函数
};虽然io_channel看起来是很简单的结构体,实际上在创建一个io_device的时候,会要求使用者传入一个io_channel_ctx的大小作为调用的参数,而在给io_channel分配内存的时候,除了分配本身io_channel结构体的大小外,还会额外分配一个io_channel_ctx的大小,这个context可以理解成一个void指针,当用户在使用io_channel的时候,实际上还是通过context的部分去访问io_device。
NVMe-oF实例
nvmf_tgt 是spdk中一个重要的模块,这里详细的写一下它作为一个target实例是如何使用thread、io_device以及io_channel的。
在spdk应用刚启动的时候,reactor模块就会自动加载起来,然后在加载nvmf subsystem的时候,会调用spdk_nvmf_subsystem_init(lib/event/subsystems/nvmf/nvmf_tgt.c)方法,nvmf_tgt其实也是有生命周期,并且有一个状态机去管理它的生命周期。
enum nvmf_tgt_state {
NVMF_TGT_INIT_NONE = 0, // 最初的状态
NVMF_TGT_INIT_PARSE_CONFIG, // 解析配置文件
NVMF_TGT_INIT_CREATE_POLL_GROUPS, // 创建poll groups
NVMF_TGT_INIT_START_SUBSYSTEMS, // 启动subsystem
NVMF_TGT_INIT_START_ACCEPTOR, // 开始接收
NVMF_TGT_RUNNING, // running
NVMF_TGT_FINI_STOP_SUBSYSTEMS,
NVMF_TGT_FINI_DESTROY_POLL_GROUPS,
NVMF_TGT_FINI_STOP_ACCEPTOR,
NVMF_TGT_FINI_FREE_RESOURCES,
NVMF_TGT_STOPPED,
NVMF_TGT_ERROR,
};首先在NVMF_TGT_INIT_PARSE_CONFIG状态中,nvmf_tgt会去解析启动时传入的配置文件,当解析了[nvmf]这个label后,会调用spdk_nvmf_tgt_create这个方法,这个方法将初始化了全局的g_nvmf_tgt变量,同时也将tgt注册成了一个io_device。
1 spdk_io_device_register(tgt,
2 spdk_nvmf_tgt_create_poll_group,
3 spdk_nvmf_tgt_destroy_poll_group,
4 sizeof(struct spdk_nvmf_poll_group),
5 "nvmf_tgt");spdk_nvmf_tgt_create_poll_group和spdk_nvmf_tgt_destroy_poll_group是io_channel创建和销毁的回调方法(在spdk_get_io_channel时调用 create_cb)。第三个参数是io_channel_ctx的size,既然这里传入了spdk_nvmf_poll_group的大小,那么很明显说明在nvmf中io_channel_ctx对象就是spdk_nvmf_poll_group。
当config文件解析完了之后,nvmf_tgt状态到了NVMF_TGT_INIT_CREATE_POLL_GROUPS,这个状态下会为每一个线程都创建相应的poll group。
spdk_for_each_thread(nvmf_tgt_create_poll_group,
NULL,
nvmf_tgt_create_poll_group_done);
static void nvmf_tgt_create_poll_group(void *ctx)
{
struct nvmf_tgt_poll_group *pg;
….
pg->thread = spdk_get_thread();
pg->group = spdk_nvmf_poll_group_create(g_spdk_nvmf_tgt);
….
}再看spdk_nvmf_poll_group_create中,
struct spdk_nvmf_poll_group * spdk_nvmf_poll_group_create(struct spdk_nvmf_tgt *tgt)
{
struct spdk_io_channel *ch;
ch = spdk_get_io_channel(tgt);
….
return spdk_io_channel_get_ctx(ch);
}在spdk_get_io_channel中,会先去检查传入的io_device是不是已经注册好了的,如果已经注册了,将会创建一个新的io_channel返回,创建的过程会回调在注册io_device时注册的io_channel创建方法(即方法spdk_nvmf_tgt_create_poll_group)。
static int spdk_nvmf_tgt_create_poll_group(void *io_device, void *ctx_buf)
{
….. // 初始化transport 、nvmf subsystem等
// 注册一个poller
group->poller = spdk_poller_register(spdk_nvmf_poll_group_poll, group, 0);
group->thread = spdk_get_thread();
return 0;
}在spdk_nvmf_poll_group_poll中,因为spdk_nvmf_poll_group对象中有transport的poll group,所以它会调用对应的transport的poll_group_poll方法,比如rdma的poll_group_poll就会轮询rdma注册的poller处理每个在相应的qpair来的请求,进入rdma的状态机将请求处理好。
然后这个状态就结束了,之后再初始化好了nvmf subsystem相关的东西之后,到了状态NVMF_TGT_INIT_START_ACCEPTOR。在这个状态中,只注册了一个poller。
1 g_acceptor_poller = spdk_poller_register(acceptor_poll, g_spdk_nvmf_tgt,
2 g_spdk_nvmf_tgt_conf->acceptor_poll_rate);这个poller调用的transport的方法,不断的监听是不是有新的fd连接进来,如果有就调用new_qpair的回调。
总结
spdk thread 模型是spdk无锁化的基础,在一个线程中,当分配一个任务后,一直会运行到任务结束为止,这确保了不需要进行线程之间的切换而带来额外的损耗。同时,高效的spdk ring提供了不同线程之间的消息传递,这就使得任务结束的结果可以高效的传递给别的处理线程。而io_device和io_channel的设计保证了资源的抽象访问以及独立的路径不去争抢资源池,并且块设备由于是对块进行操作的所以也十分适合抽象成io_device。正是因为以上几点才让spdk线程模型能够达到无锁化且为多个target提供了基础线程框架的支持。
本文福利, 免费领取C++学习资料包、技术视频/代码,1000道大厂面试题,内容包括(C++基础,网络编程,数据库,中间件,后端开发,音视频开发,Qt开发)↓↓↓↓↓↓见下面↓↓文章底部点击免费领取↓↓
智能推荐
关于idea将模块修改为Resources报错:Two modules in a project cannot share the same content root.-程序员宅基地
文章浏览阅读1.8k次。点击: file-->Project Structure-->选择:Models----> 右击文件点击Delete最后修改即可_two modules in a project cannot share the same content root
异步FIFO设计-程序员宅基地
文章浏览阅读590次,点赞26次,收藏26次。同步后的写指针与读指针进行比较,如果它们相等或满足其他预定的条件,就表明FIFO为空,从而产生空逻辑信号。产生空状态信号时,实际FIFO中有数据,相当于提前判断了空状态信号,此时不再进行读FIFO数据操作也是安全的。此时经常使用多余的1bit分别当做读写地址的拓展位,来区分读写地址相同的时候,FIFO的状态是空还是满状态。(格雷码是一种二进制编码方式,其相邻的两个数值只有一个位的差异,这种特性使得格雷码在变化时只涉及到一个位的翻转,从而减少了由于多位同时变化可能带来的不稳定性和错误。
Cannot load configuration class_cannot load configuration class: com.jsh.erp.erpap-程序员宅基地
文章浏览阅读3.0k次。将SDK从16设置为1.8,如下图_cannot load configuration class: com.jsh.erp.erpapplication
java csv 复杂表头_POIUtil(动态复杂表头、动态数据、多线程、合并数据列的POI导出成Excel工具附带生成csv文件)...-程序员宅基地
文章浏览阅读426次。package com.sckj.base.util;import java.io.IOException;import java.lang.reflect.Constructor;import java.util.ArrayList;import java.util.HashMap;import java.util.List;import java.util.Map;import java.ut..._csv能复杂表头吗
【Python】Python中input的使用_python中input的用法-程序员宅基地
文章浏览阅读1.8w次。input有类似c中的scanf函数。Python2中input使用如下:>>>x = input("x: ")x: 3>>>y = input("y" )y: 4>>> print x*y12但是Python3中input使用会有如下的提示:>>> x=input("x:")x:3>>> y=input("y:")y:5>>> print (x*y)Traceback (mos_python中input的用法
sql server异地备份_sql2008r2 异地备份-程序员宅基地
文章浏览阅读562次。服务器名为:jiliangserver 备份的数据库为:JLSDB declare @strsql varchar(1000) declare @strdirname varchar(50) declare @strcmd varchar(50) dec_sql2008r2 异地备份
随便推点
MediaServerStudioEssentials2017R2版本安装_media server studio community 2017-程序员宅基地
文章浏览阅读1.1k次。安装依赖sudo apt-get install -y preload libpciaccess-dev libpthread-stubs0-devsudo apt-get install -y compizconfig-settings-managersudo apt-get install -y subversion git git-svn gcc g++ make cmake nasms_media server studio community 2017
第9讲:使用ajax技术实现增删改查及分页显示功能(jQuery)_ajax实现修改功能-程序员宅基地
文章浏览阅读1.2k次。本讲内容首先讲解jQuery对ajax的支持,分别讲解$.post,$.get,$.ajax等方法,这些方法的参数,使用方法及区别。最后对ajax的综合应用举例:在同一个页面实现新增,修改,删除学校资料,分页列表等功能,前端使用html静态页面,使用MySQL数据库,后台使用servlet技术实现。_ajax实现修改功能
找回word文件的两种密码_word文档保护默认密码是多少-程序员宅基地
文章浏览阅读773次。Word文档的密码也有两种:一种是打开密码,一种是编辑限制两种密码加密后的效果也是不一样的:设置了打开密码的Word文档,是在打开文件的时候需要输入密码,保护文件内容不被其他人看到。当我们输入了正确的word密码,进入到文件之后,就一些都正常了,可以正常阅读、正常编辑word文件。设置了编辑限制的Word文档,打开文件的时候不需要输入密码,打开之后能够查看Word文档内容,但是想要编辑WORD文件的时候,保护文件内容不被修改,需要输入正确的Word密码,将限制编辑取消才能够正常编辑Word文档。两种密码如果_word文档保护默认密码是多少
Cocos2d场景编辑器CocosBuilder使用教程-程序员宅基地
文章浏览阅读162次。在使用Cocos2d-iPhone框架开发iOS游戏的时候,对于每一个场景(CCScene)的编辑是比较麻烦的,好在有外国的牛人提供了非常棒的场景编辑器----CocosBuilder。下面我将详细介绍CocosBuilder结合Cocos2d-iPhone框架的使用。 框架:Cocos2d-iPhone v2.0-rc2 工具:CocosBuilde..._coco2d场景编辑
el-input输入保留两位小数_el-input保留两位小数-程序员宅基地
文章浏览阅读1k次。el-input输入保留两位小数_el-input保留两位小数
MyBatis多条件查询_mybatis if test 多条件-程序员宅基地
文章浏览阅读1.8k次。在MyBatis中进行多条件查询可以使用动态SQL来构建查询语句。_mybatis if test 多条件