Database_partition all share nothing-程序员宅基地
技术标签: DataBase
发展前沿 · NewSQL数据库概述
传统的关系型数据库有着悠久的历史,从上世纪60年代开始就已经在航空领域发挥作用。因为其严谨的强一致保证以及通用的关系型数据模型接口,获得了越来越多的应用,大有一统天下的气势。这期间,涌现出了一批佼佼者,其中有优秀的商业化数据库如Oracle,DB2,SQL Server等,也有我们耳熟能详的开源数据库MySQL及PostgreSQL。这里不严谨的将这类传统数据库统称为SQL数据库。
SQL to NoSQL
2000年以后,随着互联网应用的出现,很多场景下,并不需要传统关系型数据库提供的强一致性以及关系型数据模型。相反,由于快速膨胀和变化的业务场景,对可扩展性(Scalability)以及可靠性(Reliable)更加需要,而这个又正是传统关系型数据库的弱点。自然地,新的适合这种业务特点的数据库NoSQL开始出现,其中最句代表性的是Amazon的Dynamo以及Google的BigTable,以及他们对应的开源版本像Cassandra以及HBase。由于业务模型的千变万化,以及抛弃了强一致和关系型,大大降低了技术难度,各种NoSQL版本像雨后春笋一样涌现,基本成规模的互联网公司都会有自己的NoSQL实现。主要可以从两个维度来对各种NoSQL做区分:
- 按元信息管理方式划分:以Dynamo[1]为代表的对等节点的策略,由于没有中心节点的束缚有更高的可用性。而采用有中心节点的策略的,以BigTable[2]为代表的的数据库,则由于减少全网的信息交互而获得更好的可扩展性。
- 按数据模型划分:针对不同业务模型出现的不同数据模型的数据库,比较知名的有文档型数据库MongoDB,KV数据库Redis、Pika,列数据库Cassandra、HBase,图数据库Neo4J。
NoSQL to New SQL
NoSQL也有很明显的问题,由于缺乏强一致性及事务支持,很多业务场景被NoSQL拒之门外。同时,缺乏统一的高级数据模型、访问接口,又让业务代码承担了很多的负担。图灵奖得主Michael Stonebraker甚至专门发文声讨,”Why Enterprises Are Uninterested in NoSQL” [3] 一文中,列出了NoSQL的三大罪状:No ACID Equals No Interest, A Low-Level Query Language is Death,NoSQL Means No Standards。数据库的历史就这样经历了否定之否定,又螺旋上升的过程。而这一次,鱼和熊掌我们都要。
核心问题:分片(PARTITION)
如何能在获得SQL的强一致性、事务支持的同时,获得NoSQL的可扩展性及可靠性。答案显而易见,就是要在SQL的基础上像NoSQL一样做分片。通过分片将数据或计算打散到不同的节点,来摆脱单机硬件对容量和计算能力的限制,从而获得更高的可用性、性能以及弹性:
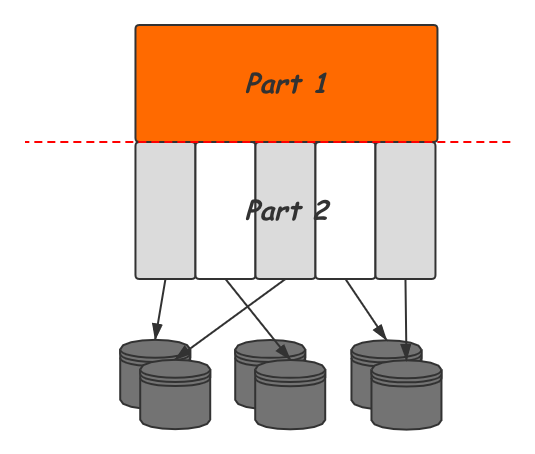
那么如何做分片呢,上图是一个高度抽象的数据库分片示意图,我们将数据库系统划分为上下两个部分,Part 1保持不动,将Part 2进行分片打散,由不同的节点负责,并在分片间通过副本方式保证高可用。同时,Part 2部分的功能由于被多个节点分担,也可以获得并行执行带来的性能提升。
所以现在实现NewSQL的核心问题变成了:确定一条分割线将数据库系统划分为上下两个部分,对Part 2做分片打散。而这条分割线的确定就成了主流NewSQL数据库的不同方向,不同的选择带来的不同的ACID实现方式,以及遇到的问题也大不相同。下图展示了更详细的数据库系统内部结构,以及主流的分界线选择及工业实现代表:
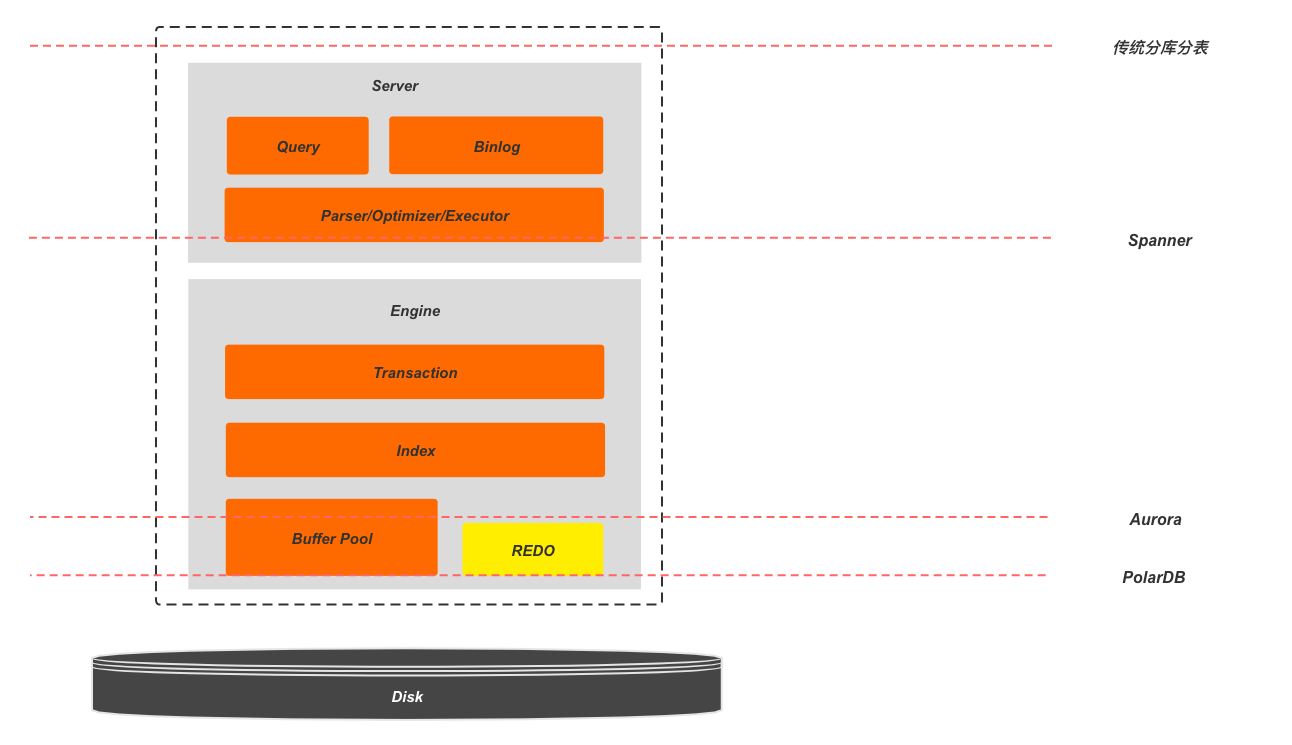
为了方便说明,本文中根据这个分片分割线的位置,将不同的方案命名为:Partition All、Partition Engine、Partiton Storage 以及 Partition Disk。这里先说结论:随着分片层次的下降,可扩展性会降低,但易用性和生态兼容性会增大。下面就分别介绍每种选择中需要解决的问题,优缺点,使用场景以及代表性工业实现的实现方式。
PARTITION ALL:分库分表
最直观的想法,就是直接用多个DB实例共同服务,从而缓解单机数据库的限制,这也是很多大公司内部在业务扩张期的第一选择。这种方式相当于是在数据库系统的最顶层就做了Partition,理想情况下,整个数据库的各个模块可以全部并发执行起来。

采用分库分表的首要问题就是如何对数据进行分片,常见的就是在表或者库的维度水平或垂直的进行分片。这里分片的选择是非常关键的,良好的,适应业务模式的分片可以让多DB实例尽量的并发起来获得最好的扩展性能。而不合适的分片则可能导致大量的跨节点访问,导致负载不均衡,或引入访问瓶颈。除分片策略之外,由于跨节点的访问需要,会有一些通用的问题需要解决,比如如何在分片之间支持分布式事务,处理分布式Query拆分和结果合并,以及全局自增ID的生成等。而且,最重要的,所有这些新增的负担全部要业务层来承担,极大的增加了业务的成本。
因此,分库分表的模式,在良好的业务侧设计下可以获得极佳的扩展性,取得高性能、大容量的数据库服务。但业务耦合大,通用性差,需要用户自己处理分片策略、分布式事务、分布式Query。这也是为什么在各大公司内部都有成熟稳定的分库分表的数据库实现的情况下,这些实现却很难对外通用的输出。
PARTITION ENGINE: SPANNER
我们将Part 1和Part2的分界线下移,到Server层之下,也就是只在引擎层做Partition。这种模式由于节点间相对独立,也被称作Share Nothing架构。相对于传统分库分表,Partition Engine的方式将之前复杂的分布式事务,分布式Query等处理放到了数据库内部来处理。
本文就以分布式事务为例,来尝试解释这种分片层次所面对的问题和解决思路。要支持事务就需要解决事务的ACID问题。而ACID的问题在分布式的环境下又变得复杂很多:

A(Atomicity),在传统数据库系统中,通过REDO加UNDO的方式容易解决这个问题[4],但当有多个不同的节点参与到同一个事务中的时候问题变的复杂起来,如何能把保证不同节点上的修改同时成功或同时回滚呢,这个问题有成熟的解决方案,就是2PC(Two-Phase Commit Protocol),引入Coordinator角色和prepare阶段来在节点间协商。
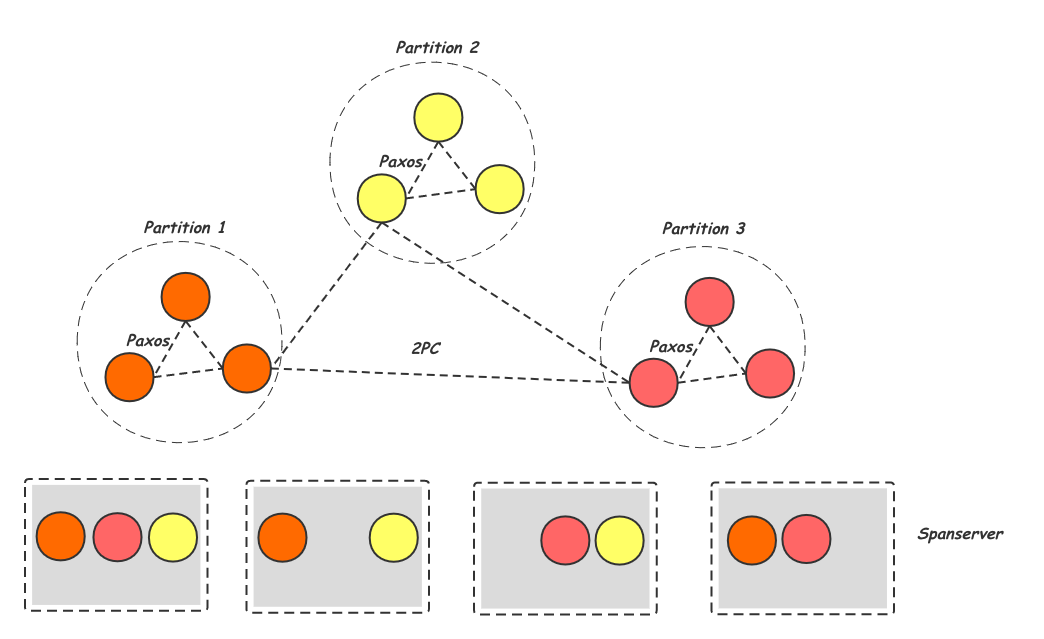
D (Durability),单机数据库中,我们通过REDO配合Buffer Pool的刷脏策略可以保证节点重启后可以看到已经提交的事务[4]。而在分布式环境中通常会需要更高的可用性,节点宕机后马上需要有新的节点顶上。这里的解决方案也比较成熟,就是给分片提供多个副本(通常是3个),每个副本由不同的节点负责,并且采用一致性算法Multi-Paxos[6]或其变种来保证副本间的一致性。下图是Spanner的实现方式,每个spanserver节点负责不同partition的多个分片,每个partition的副本之间用Paxos来保证其一致性,而跨Partition的事务则用2PC来保证原子。
I(Isolation),“数据库并发控控制”[5]一文中介绍过,是实现并发控制最直观的做法是2PL(两阶段锁),之后为了减少读写之间的加锁冲突,大多数数据库都采取了2PL + MVCC的实现方式,即通过维护多版本信息来让写请求和读请求可以并发执行。而MVCC的实现中有十分依赖一个全局递增的事务执行序列,用来判断事务开始的先后,从而寻找正确的可读历史版本。而这个全局递增的序列在分布式的数据库中变的十分复杂,原因是机器间的时钟存在误差,并且这种误差的范围不确定。常见的做法是通过节点间的信息交互来确定跨节点的时间先后,如Lamport时钟[7]。但更多的信息交互带来了瓶颈,从而限制了集群的扩展规模以及跨地域的复制。Spanner[8]提出了一种新的思路,通过引入GPS和原子钟的校准,在全球范围内,将不同节点的时钟误差限制到一个确定的范围内。这个确定的误差范围非常重要,因为他支持了一种可能:通过适度的等待保证事务的正确性。
具体的说,这里Spanner需要保证External Consistency,即如果事务T2开始在T1 commit之后, 那么T2拿到的Commit Timestamp一定要大于T1的Timestamp。Spanner实现这个保证的做法,是让事务等待其拿到的Commit Timestamp真正过去后才真正提交(Commit Wait):

如上图[9]所示,事务Commit时,首先通过TrueTime API获取一个当前时间now,这个时间是一个范围now = [t - ε, t + ε],那么这个t - ε就是作为这个事务的Commit Timestamp,之后要一直等待到TrueTime API返回的当前时间now.earliest > s时,才可以安全的开始做真正的comimt,这也就保证,这个事务commit以后,其他事务再也不会拿到更小的Timestamp。
总结下, 采用Partition Engine策略的NewSQL,向用户屏蔽了分布式事务等细节,提供统一的数据库服务,简化了用户使用。Spanner,CockroachDB,Oceanbase,TIDB都属于这种类型。这里有个值得探讨的问题:由于大多数分库分表的实现也会通过中间件的引入来屏蔽分布式事务等实现细节,同样采用类Multi Paxos这样的一致性协议来保证副本一致,同样对用户提供统一的数据库访问,那么相较而言,Partition Engine的策略优势又有多大呢?在大企业,银行等场景下, 这两种方案或许正在正面竞争,我们拭目以待[11]。
PARTITION STORAGE: AURORA、POLARDB
继续将分片的分界线下移,到事务及索引系统的下层。这个时候由于Part 1部分保留了完整的事务系统,已经不是无状态的,通常会保留单独的节点来处理服务。这样Part 1主要保留了计算相关逻辑,而Part 2负责了存储相关的像REDO,刷脏以及故障恢复。因此这种结构也就是我们常说的计算存储分离架构,也被称为Share Storage架构。
这种策略由于关键的事务系统并没有做分片处理,也避免了分布式事务的需要。而更多的精力放在了存储层的数据交互及高效的实现。这个方向最早的工业实现是Amazon的Aurora[12]。Aurora的计算节点层保留了锁,事务管理,死锁检测等影响请求能否执行成功的模块,对存储节点来说只需要执行持久化操作而不需要Vote。另外,计算节点还维护了全局递增的日志序列号LSN,通过跟存储节点的交互可以知道当前日志在所有分片上完成持久化的LSN位置,来进行实物提交或缓存淘汰的决策。因此,Aurora可以避免Partition Engine架构中面临的分布式事务的问题[18]。
Auraro认为计算节点与存储节点之间,存储节点的分片副本之间的网络交互会成为整个系统的瓶颈。而这些数据交互中的大量Page信息本身是可以通过REDO信息构建的,也就是说有大量的网络交互是冗余的,因此Aurora提出了“Log is Database”,也就是所有的节点间网络交互全部只传输REDO,每个节点本地自己在通过REDO的重放来构建需要的Page信息。
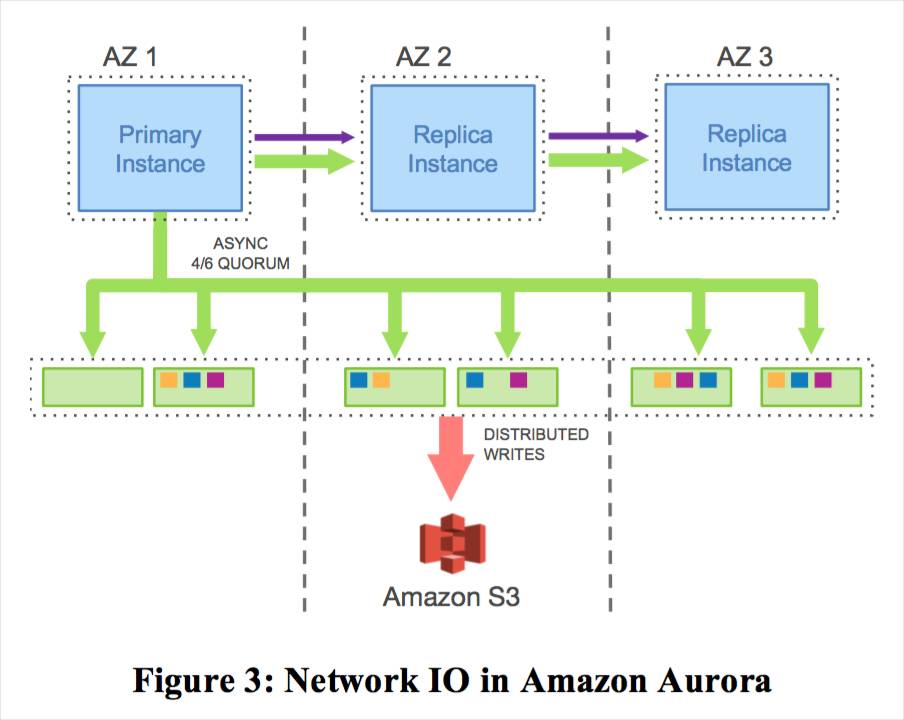
从上图可以看出,计算节点和存储节点之间传输的只有REDO,也就是是说,传统数据库中存储相关的部分从计算节点移到了存储节点中,这些功能包括:
- REDO日志的持久化
- 脏页的生成与持久化
- Recovery过程的REDO重放
- 快照及备份
这些功能对数据库整体的性能有非常大的影响:首先,根据ARIES[17]安全性要求,只有当REDO落盘后事务才能提交,这使得REDO的写速度很容易成为性能瓶颈;其次,当Buffer Pool接近满时,如果不能及时对Page做刷脏,后续的请求就会由于获取不到内存而变慢;最后,节点发生故障重启时,在完成REDO重放之前是无法对外提供服务的,因此这个时间会直接影响数据库的可用性。而在Aurora中,由于存储节点中对数据页做了分片打散,这些功能可以由不同的节点负责,得以并发执行,充分利用多节点的资源获得更大的容量,更好的性能。
PolarDB
2017年,由于RDMA的出现及普及,大大加快了网络间的网络传输速率,PolarDB[15]认为未来网络的速度会接近总线速度,也就是瓶颈不再是网络,而是软件栈。因此PolarDB采用新硬件结合Bypass Kernel的方式来实现高效的共享盘实现,进而支撑高效的数据库服务。由于PolarDB的分片层次更低,也就能做到更好的生态兼容,也就是为什么PolarDB能够很快的做到社区版本的全覆盖。副本间PoalrDB采用了ParalleRaft来允许一定范围内的乱序确认,乱序Commit以及乱序Apply。
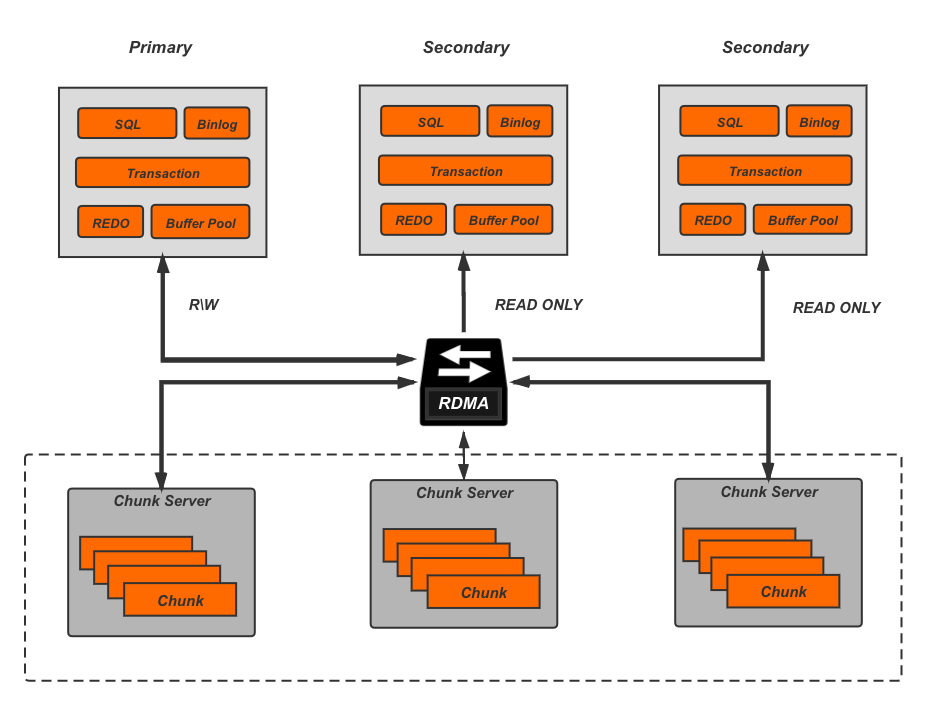
采用Partition Storage的策略的NewSQL,由于保持了完整的计算层,所以相对于传统数据库需要用户感知的变化非常少,能过做到更大程度的生态兼容。同时也因为只有存储层做了分片和打散,可扩展性不如上面提到的两种方案。在计算存储分离的基础上,Microsoft的Socrates[13]提出了进一步将Log模块拆分,实现Durability和Available的分离;Oracal的Cache Fusion[14]通过增加计算节点间共享的Memory来获得多点写及快速Recovery,总体来讲他们都属于Partition Storage这个范畴。
对比
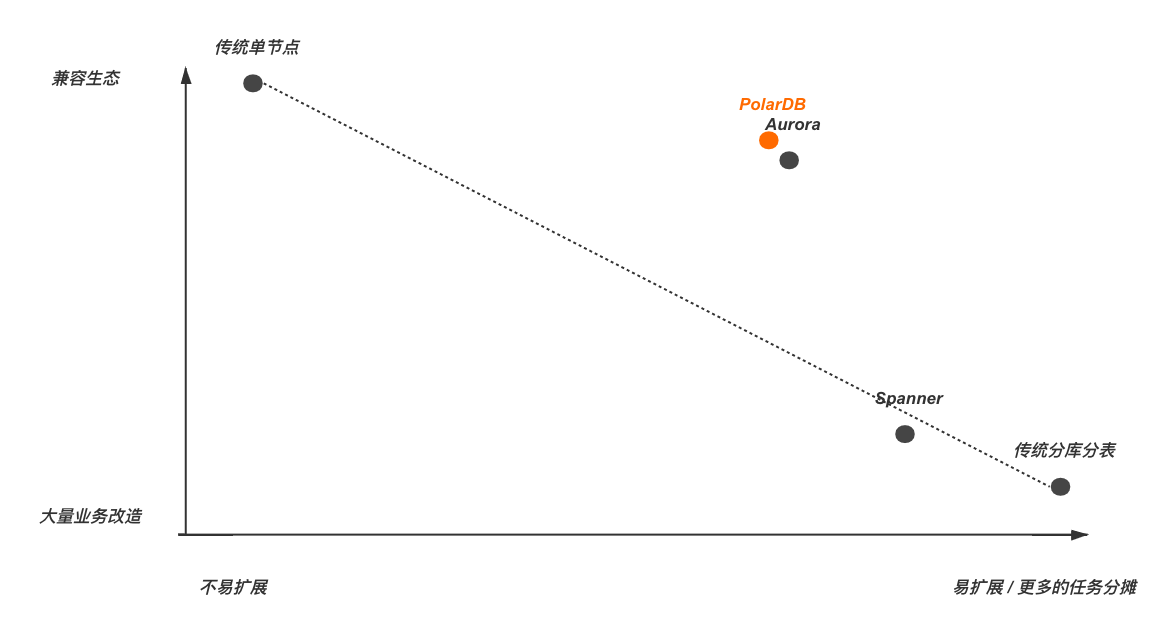
可以看出,如果我们以可扩展性为横坐标,易用及兼容生态作为纵坐标,可以得到如上图所示的坐标轴,越往右上角当然约理想,但现实是二者很难兼得,需要作出一定的取舍。首先来看传统的单节数据库其实就是不易扩展的极端,同时由于他自己就是生态所以兼容生态方面满分。另一个极端就是传统的分库分表实现,良好的分片设计下这种策略能一定程度下获得接近线性的扩展性。但需要做业务改造,并且需要外部处理分布式事务,分布式Query这种棘手的问题。之后以Spanner为代表的的Partition Engine类型的NewSQL由于较高的分片层次,可以获得接近传统分库分表的扩展性,因此容易在TPCC这样的场景下取得好成绩,但其需要做业务改造也是一个大的限制。以Aurora及PolarDB为代表的的Partition Storage的NewSQL则更倾向于良好的生态兼容,几乎为零的业务改造,来交换了一定程度的可扩展性。
使用场景上来看,大企业,银行等对用户对扩展性要求较高,可以接受业务改造的情况下,类Spanner的NewSQL及传统分库分表的实现正在正面竞争。而Aurora和PolarDB则在云数据库的场景下一统江湖。
参考
[3] Why Enterprises Are Uninterested in NoSQL
[18] Amazon Aurora: On Avoiding Distributed Consensus for I/Os, Commits, and Membership Changes
智能推荐
EasyDarwin开源流媒体云平台之EasyRMS录播服务器功能设计_开源录播系统-程序员宅基地
文章浏览阅读3.6k次。需求背景EasyDarwin开发团队维护EasyDarwin开源流媒体服务器也已经很多年了,之前也陆陆续续尝试过很多种服务端录像的方案,有:在EasyDarwin中直接解析收到的RTP包,重新组包录像;也有:在EasyDarwin中新增一个RecordModule,再以RTSPClient的方式请求127.0.0.1自己的直播流录像,但这些始终都没有成气候;我们的想法是能够让整套EasyDarwin_开源录播系统
oracle Plsql 执行update或者delete时卡死问题解决办法_oracle delete update 锁表问题-程序员宅基地
文章浏览阅读1.1w次。今天碰到一个执行语句等了半天没有执行:delete table XXX where ......,但是在select 的时候没问题。后来发现是在执行select * from XXX for update 的时候没有commit,oracle将该记录锁住了。可以通过以下办法解决: 先查询锁定记录 Sql代码 SELECT s.sid, s.seri_oracle delete update 锁表问题
Xcode Undefined symbols 错误_xcode undefined symbols:-程序员宅基地
文章浏览阅读3.4k次。报错信息error:Undefined symbol: typeinfo for sdk::IConfigUndefined symbol: vtable for sdk::IConfig具体信息:Undefined symbols for architecture x86_64: "typeinfo for sdk::IConfig", referenced from: typeinfo for sdk::ConfigImpl in sdk.a(config_impl.o) _xcode undefined symbols:
项目05(Mysql升级07Mysql5.7.32升级到Mysql8.0.22)_mysql8.0.26 升级32-程序员宅基地
文章浏览阅读249次。背景《承接上文,项目05(Mysql升级06Mysql5.6.51升级到Mysql5.7.32)》,写在前面需要(考虑)检查和测试的层面很多,不限于以下内容。参考文档https://dev.mysql.com/doc/refman/8.0/en/upgrade-prerequisites.htmllink推荐阅读以上链接,因为对应以下问题,有详细的建议。官方文档:不得存在以下问题:0.不得有使用过时数据类型或功能的表。不支持就地升级到MySQL 8.0,如果表包含在预5.6.4格_mysql8.0.26 升级32
高通编译8155源码环境搭建_高通8155 qnx 源码-程序员宅基地
文章浏览阅读3.7k次。一.安装基本环境工具:1.安装git工具sudo apt install wget g++ git2.检查并安装java等环境工具2.1、执行下面安装命令#!/bin/bashsudoapt-get-yinstall--upgraderarunrarsudoapt-get-yinstall--upgradepython-pippython3-pip#aliyunsudoapt-get-yinstall--upgradeopenjdk..._高通8155 qnx 源码
firebase 与谷歌_Firebase的好与不好-程序员宅基地
文章浏览阅读461次。firebase 与谷歌 大多数开发人员都听说过Google的Firebase产品。 这就是Google所说的“ 移动平台,可帮助您快速开发高质量的应用程序并发展业务。 ”。 它基本上是大多数开发人员在构建应用程序时所需的一组工具。 在本文中,我将介绍这些工具,并指出您选择使用Firebase时需要了解的所有内容。 在开始之前,我需要说的是,我不会详细介绍Firebase提供的所有工具。 我..._firsebase 与 google
随便推点
k8s挂载目录_kubernetes(k8s)的pod使用统一的配置文件configmap挂载-程序员宅基地
文章浏览阅读1.2k次。在容器化应用中,每个环境都要独立的打一个镜像再给镜像一个特有的tag,这很麻烦,这就要用到k8s原生的配置中心configMap就是用解决这个问题的。使用configMap部署应用。这里使用nginx来做示例,简单粗暴。直接用vim常见nginx的配置文件,用命令导入进去kubectl create cm nginx.conf --from-file=/home/nginx.conf然后查看kub..._pod mount目录会自动创建吗
java计算机毕业设计springcloud+vue基于微服务的分布式新生报到系统_关于spring cloud的参考文献有啥-程序员宅基地
文章浏览阅读169次。随着互联网技术的发发展,计算机技术广泛应用在人们的生活中,逐渐成为日常工作、生活不可或缺的工具,高校各种管理系统层出不穷。高校作为学习知识和技术的高等学府,信息技术更加的成熟,为新生报到管理开发必要的系统,能够有效的提升管理效率。一直以来,新生报到一直没有进行系统化的管理,学生无法准确查询学院信息,高校也无法记录新生报名情况,由此提出开发基于微服务的分布式新生报到系统,管理报名信息,学生可以在线查询报名状态,节省时间,提高效率。_关于spring cloud的参考文献有啥
VB.net学习笔记(十五)继承与多接口练习_vb.net 继承多个接口-程序员宅基地
文章浏览阅读3.2k次。Public MustInherit Class Contact '只能作基类且不能实例化 Private mID As Guid = Guid.NewGuid Private mName As String Public Property ID() As Guid Get Return mID End Get_vb.net 继承多个接口
【Nexus3】使用-Nexus3批量上传jar包 artifact upload_nexus3 批量上传jar包 java代码-程序员宅基地
文章浏览阅读1.7k次。1.美图# 2.概述因为要上传我的所有仓库的包,希望nexus中已有的包,我不覆盖,没有的添加。所以想批量上传jar。3.方案1-脚本批量上传PS:nexus3.x版本只能通过脚本上传3.1 批量放入jar在mac目录下,新建一个文件夹repo,批量放入我们需要的本地库文件夹,并对文件夹授权(base) lcc@lcc nexus-3.22.0-02$ mkdir repo2..._nexus3 批量上传jar包 java代码
关于去隔行的一些概念_mipi去隔行-程序员宅基地
文章浏览阅读6.6k次,点赞6次,收藏30次。本文转自http://blog.csdn.net/charleslei/article/details/486519531、什么是场在介绍Deinterlacer去隔行处理的方法之前,我们有必要提一下关于交错场和去隔行处理的基本知识。那么什么是场呢,场存在于隔行扫描记录的视频中,隔行扫描视频的每帧画面均包含两个场,每一个场又分别含有该帧画面的奇数行扫描线或偶数行扫描线信息,_mipi去隔行
ABAP自定义Search help_abap 自定义 search help-程序员宅基地
文章浏览阅读1.7k次。DATA L_ENDDA TYPE SY-DATUM. IF P_DATE IS INITIAL. CONCATENATE SY-DATUM(4) '1231' INTO L_ENDDA. ELSE. CONCATENATE P_DATE(4) '1231' INTO L_ENDDA. ENDIF. DATA: LV_RESET(1) TY_abap 自定义 search help