Elasticsearch介绍及如何使用_elasticsearch match_phrase_prefix-程序员宅基地
技术标签: elasticsearch
是什么
Elasticsearch 是一个分布式可扩展的实时搜索和分析引擎,一个建立在全文搜索引擎 Apache Lucene 基础上的搜索引擎.当然 Elasticsearch 并不仅仅是 Lucene 那么简单,它不仅包括了全文搜索功能,还可以进行以下工作:
- 分布式实时文件存储,并将每一个字段都编入索引,使其可以被搜索。
- 实时分析的分布式搜索引擎。
- 可以扩展到上百台服务器,处理PB级别的结构化或非结构化数据。
基本概念:
- 节点(Node):
一个节点是一个单一的服务器,是你的集群的一部分,存储数据,并且参与集群的索引和搜索功能。
一个节点可以通过配置特定的集群名称来加入特定的集群。默认情况下,每个节点被设定加入一个名称为 “elasticsearch” 的集群,这意味着如果你在你的网络中启动了一些节点,并且假设它们能相互发现,它们将会自动组织并加入一个名称是 “elasticsearch” 的集群。 - 索引(Index):
可以近似的理解SQL中的数据库,虽然官方文档上说这是不好的。可以包涵表和数据。 - 类型(Type):(警告!Type在6.0.0版本中已经不赞成使用):
可以近似的理解成是SQL中的表,里面会包涵许多数据 - 文档(Document):
可以近似的理解是SQL中的表里的每一条数据。
去哪下:
官网下载传送
官网下载window版(我的是6.6.1版本)。
双击运行bin目录下的 elasticsearch.bat
怎么玩:
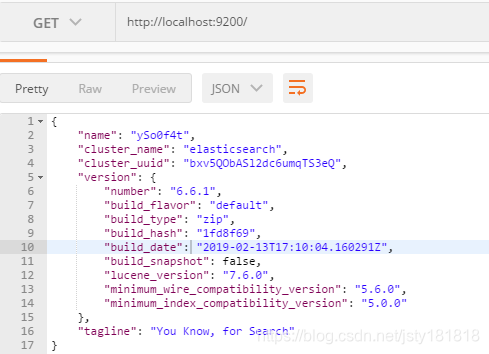
看到这个结果,说明安装,启动成功。
- 列出所有的索引:(GET)
http://localhost:9200/_cat/indices?v
- 创建一个索引:(PUT)
http://localhost:9200/customer
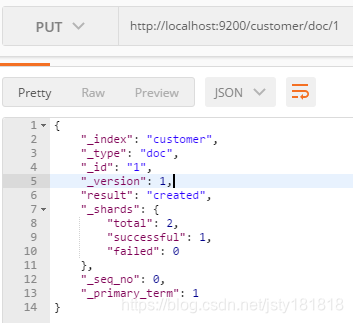
- 向索引中添加文档(PUT)
http://localhost:9200/customer/doc/1
//其中doc是类型。
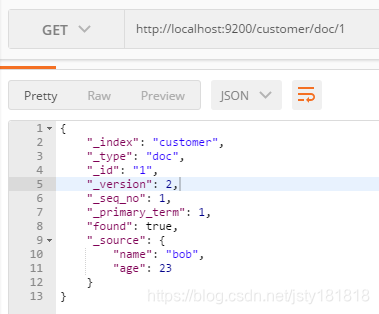
- 获取刚刚加入索引的文档:(GET)
http://localhost:9200/customer/doc/1
- 删除一个索引:(DELETE)
http://localhost:9200/customer
- 更新文档(POST)
除了能够新增和替换文档,我们也可以更新文档。注意虽然 Elasticsearch 在底层并没有真正更新文档,而是当我们更新文档时,Elasticsearch 首先去删除旧的文档,然后加入新的文档。
http://localhost:9200/customer/doc/1/_update?pretty
{
"doc": { "name": "Jane Doe" }
}
更新操作也可以使用简单的脚本来执行。如下的示例使用一个脚本将age增加了5:
http://localhost:9200/customer/doc/1/_update?pretty
{
"script" : "ctx._source.age += 5"
}
- 删除文档(DELETE):
http://localhost:9200/customer/doc/2?pretty
推荐使用Kibana进行数据查询
搜索:
- _mget(批量获取文档)
类似sql中的 id in(1,2,3)这样。
GET _mget
{
"docs":[
{
"_index": "bank",
"_type": "account",
"_id": "1",
"_source": ["balance", "city"]
},
{
"_index": "bank",
"_type": "account",
"_id": "5",
"_source": "firstname"
}
]
}
也可以简写:
GET /bank/account/_mget
{
"ids": ["1", "2", "4"]
}
-
_bulk(批量操作)
1.格式:
{action:{metadata}}
{requestbody}
其中action(行为)可以取值:
1.create:文档不存在时创建
2.update:更新文档
3.index:创建新文档或覆盖已有文档
4.delete:删除一个文档
create和index的区别:如果数据存在,使用create操作失败,会提示文档以存在,使用index可以成功执行。
如果使用create创建多个,其中有存在的,那么存在的返回失败,不存在的添加成功
其中metadata可以取值:
_index,_type,_id示例:
1.create:POST /bank/account/_bulk { "create":{ "_id":"999"}} { "account_number":999, "balance": 999} { "create":{ "_id":"1000"}} { "account_number":1000, "balance": 1000} { "create":{ "_id":"1001"}} { "account_number":1001, "balance": 1001}2.delete:
POST bank/account/_bulk { "delete":{ "_index":"bank", "_type":"account", "_id":"1000"}}3.update:
POST /bank/account/_bulk { "update":{ "_id":"1001"}} { "doc":{ "balance":"0"}} -
term:
用于查询指定字段包含某个词项的文档。这个查询不知道分词器的存在,所以搜索的值不会进行分词。只会拿搜索的值去倒排索引中找。
GET /bank/account/_search
{
"query":{
"term":{
"address":{
"value":"heath"
}
}
}
}
- match:
知道分词器的存在,所以搜索的值会被分词在去查询。
GET /bank/account/_search
{
"query":{
"match":{
"address":"511 Heath Place"
}
}
}
- multi_match:
可以指定多个字段,意思是:查找fields字段值的字段中包含query字段中对应的值
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
}
}
- match_phrase:
短语搜索,就是搜索含有指定的短语的数据。意思是搜索的值经过分词之后和es中分词保存的一致,顺序也一致,两头的可以少,中间的不可以少
GET /bank/account/_search
{
"query":{
"match_phrase":{
"address":"511 Heath Place"
}
}
}
- _source:
用来指定返回的字段:
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": ["firstname", "age"]
}
_可以写个数组来指定,也可以在 "source" 字段中加"includes"和"excludes"
GET /bank/account/_search
{
"query":{
"multi_match":{
"query":"Worcester",
"fields":["city", "address"]
}
},
"_source": {
"includes": ["age", "balance", "gen*"],
"excludes": ["gender"]
}
}
- sort:
用来排序,和关系型数据库的排序类似
GET /bank/account/_search
{
"query":{
"match_all":{
}
},
"sort":[
{
"balance":{
"order":"desc"
}
},
{
"age":{
"order":"asc"
}
}
]
}
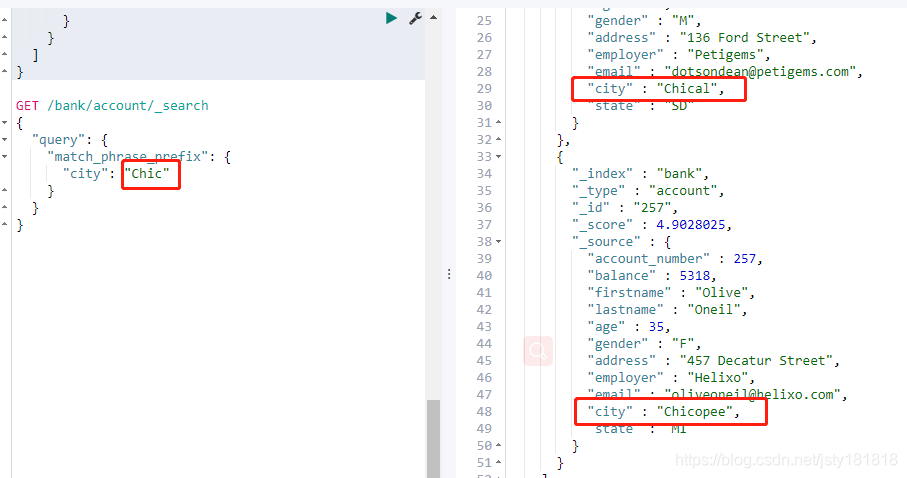
- match_phrase_prefix:
前缀匹配(查询的值不会分词,但是忽略大小写)
- range:
范围查询:
GET /bank/account/_search
{
"query":{
"range":{
"age":{
"gte": 20,
"lt": 30
}
}
}
}
- wildcard:
通配符匹配:
通配符:
* 代表任意多字符
? 代表一个字符
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
}
}
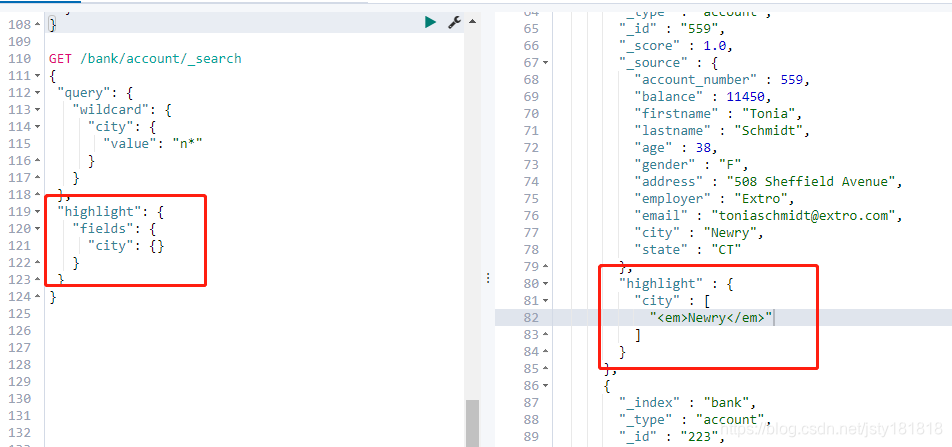
- highlight:
高亮显示:
GET /bank/account/_search
{
"query":{
"wildcard":{
"city":{
"value": "nicho*n"
}
}
},
"highlight":{
"fields":{
"city":{
}
}
}
}
- fuzzy:
模糊匹配,这个可不是mysql中的like,是可以错误的输入一些字 来进行匹配
GET /bank/account/_search
{
"query":{
"fuzzy":{
"city": "Nicho1so"
}
}
}
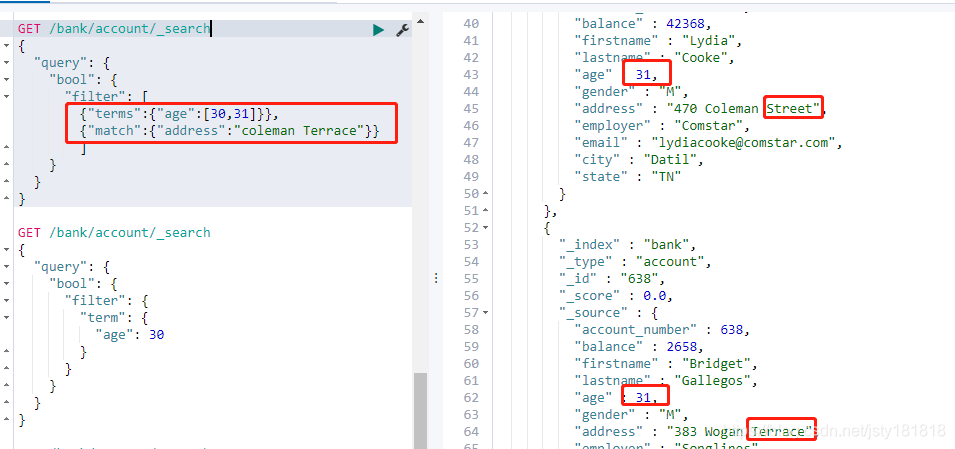
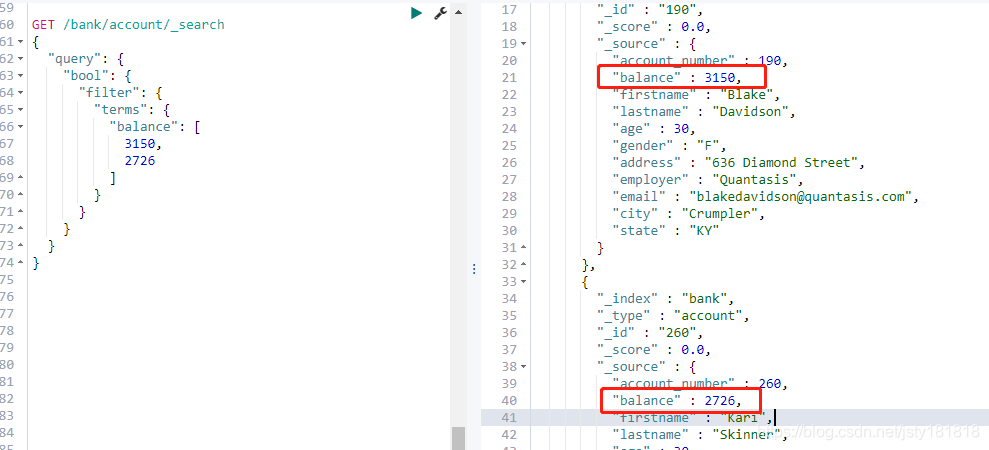
- filter查询:
过滤查询:
- must,should,must_not:
GET /bank/account/_search
{
"query":{
"bool":{
"must": [
{
"term":{
"age":{
"value" :20
}
}
}
]
}
}
}
- exists:
查询某个字段不为空
GET /bank/account/_search
{
"query":{
"bool":{
"filter": {
"exists":{
"field": "age"
}
}
}
}
}
- 聚合查询:
1.sum

智能推荐
【玩转华为云】手把手教你利用ModelArts实现垃圾自动分类_华为云人工智能 垃圾分类-程序员宅基地
文章浏览阅读1.4k次。本篇推文共计2000个字,阅读时间约3分钟。华为云—华为公司倾力打造的云战略品牌,2011年成立,致力于为全球客户提供领先的公有云服务,包含弹性云服务器、云数据库、云安全等云计算服务,软件开发服务,面向企业的大数据和人工智能服务,以及场景化的解决方案。华为云用在线的方式将华为30多年在ICT基础设施领域的技术积累和产品解决方案开放给客户,致力于提供稳定可靠、安全可信、可持续创新的云服务,做智能世界的“黑土地”,推进实现“用得起、用得好、用得放心”的普惠AI。华为云作为底座,为华为全栈全场景A.._华为云人工智能 垃圾分类
Python 开发桌面应用居然如此简单_python制作桌面端-程序员宅基地
文章浏览阅读6.4k次,点赞4次,收藏86次。我们都知道 Python 可以用来开发桌面应用,一旦功能开发完成,最后打包的可执行文件体积大,并且使用 Python 开发桌面应用周期相对较长假如想快速开发一款 PC 端的桌面应用,推荐使用 Aardio + Python 搭配的方式进行开发1. Aardio介绍Aardio 是一款专注于 Windows 桌面端的软件开发,适用于快速开发一些自用的 PC端桌面工具,并且它支持与Python、JS、Golang 等主流语言进行混合编程它是一款免费的开发工具,简单易学,支持多线程,具有轻巧..._python制作桌面端
IDEA中Spring配置错误:class path resource [.xml] cannot be opened because it does not exist_class path resource [feign/requestinterceptor.clas-程序员宅基地
文章浏览阅读10w+次,点赞71次,收藏72次。如果在运行 Spring 项目时出现了类似于:class path resource [applicationContext.xml] cannot be opened because it does not exist这样的异常 意思就是没有找到你的 .xml 配置文件原因我可以肯定你一定用的是 ApplicationContext ctx = new ClassPathXmlApplicati_class path resource [feign/requestinterceptor.class] cannot be opened becaus
Activiti工作流引擎-程序员宅基地
文章浏览阅读1w次,点赞8次,收藏50次。Activiti是一个工作流引擎, activiti可以将业务系统中复杂的业务流程抽取出来,使用专门的建模语言BPMN2.0进行定义,业务流程按照预先定义的流程进行执行,实现了系统的流程由activiti进行管理,减少业务系统由于流程变更进行系统升级改造的工作量,从而提高系统的健壮性,同时也减少了系统开发维护成本。........._activiti工作流引擎
【BZOJ】【3053】The Closest M Points-程序员宅基地
文章浏览阅读76次。KD-Tree 题目大意:K维空间内,与给定点欧几里得距离最近的 m 个点。 KD树啊……还能怎样啊……然而扩展到k维其实并没多么复杂?除了我已经脑补不出建树过程……不过代码好像变化不大>_> 然而我WA了。。。为什么呢。。。我也不知道…… 一开始我的Push_up是这么写的:inline void Push_up(int o){ rep(..._euclidean distance between w and the closest point to w in s v
testng生成报告ReportNG美化测试报告-程序员宅基地
文章浏览阅读184次。testng生成报告ReportNG美化测试报告testng生成报告ReportNG美化测试报告ReportNG 是一个配合TestNG运行case后自动帮你在test-output文件内生成一个相对较为美观的测试报告!ReportNG 里面Log 是不支持中文的,我改过ReportNG.jar源码,具体方法看最下面,也可以找我直接要jar!话不多说直接上环境准备:1,你需要这些架包 ..._testng reportng美化报告
随便推点
C++实现线性表的顺序存储结构_c++使用顺序存储表示方法创建线性表-程序员宅基地
文章浏览阅读2.5k次,点赞6次,收藏48次。C++线性表的顺序存储结构 线性表是最基本、最简单、也是最常用的一种数据结构。线性表(linear list)是数据结构的一种,一个线性表是n个具有相同特性的数据元素的有限序列。线性表的特点除第一个元素外,其他每一个元素有且仅有一个直接前驱。除最后一个元素外,其他每一个元素有且仅有一个直接后继。直接前驱和直接后继描..._c++使用顺序存储表示方法创建线性表
重装protobuf报错undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev-程序员宅基地
文章浏览阅读1.4w次,点赞2次,收藏7次。服务器将protobuf版本从2.6.1降级到2.5.0后,重新装回2.6.1,出现报错:protoc: symbol lookup error: /usr/lib/x86_64-linux-gnu/libprotoc.so.9: undefined symbol: _ZNK6google8protobuf7Message11GetTypeNameB5cxx11Ev搜索网上解决办法,发现并...__znk6google8protobuf7message11gettypenameb5cxx11ev
【校招VIP】java语言考点之synchronized和volatile-程序员宅基地
文章浏览阅读356次。synchronized和volatile两个关键字也是校招常考点之一。volatile可以禁止进行指令重排。synchronized可作用于一段代码或方法,既可以保证可见性,又能够保证原子性。_synchronized和volatile
互联网平台经济模式逐渐形成,许多新的创新型企业涌现出来,将会影响到社会的治理结构以及公共政策走向-程序员宅基地
文章浏览阅读461次。作者:禅与计算机程序设计艺术 1.简介在新冠病毒疫情期间,由于经济全面恢复、国内外大量人员返乡、工作日程调整等因素的影响,使得整个社会成为新冠病毒大流行的重灾区。为了减轻生产企业和消费者的不满情绪,提高社会福利水平,防止再次发生类似事件,各地都制定了诸多限制、规范、政策等方面的法律法规,但这些法律法规
ethereum/EIPs-161 State trie clearing-程序员宅基地
文章浏览阅读152次。EIP 161: State trie clearing- makes it possible to remove a large number of empty accounts that were put in the state at very low cost as a result of earlier DoS attacks. With this EIP, 'empty' accou..._eip161
2003与2007导出_导出2003-程序员宅基地
文章浏览阅读120次。using System;using System.Data;using System.Configuration;using System.Collections;using System.Data.OleDb;using System.IO;using System.Web;using System.Web.Security;using System.Web.U..._导出2003