Hadoop 自定义序列化编程_1.package tem_com; 2.import java.io.ioexception; 3-程序员宅基地
package com.cakin.hadoop.mr;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.WritableComparable;
public class UserWritable implements WritableComparable<UserWritable> {
private Integer id;
private Integer income;
private Integer expenses;
private Integer sum;
public void write(DataOutput out) throws IOException {
// TODO Auto-generated method stub
out.writeInt(id);
out.writeInt(income);
out.writeInt(expenses);
out.writeInt(sum);
}
public void readFields(DataInput in) throws IOException {
// TODO Auto-generated method stub
this.id=in.readInt();
this.income=in.readInt();
this.expenses=in.readInt();
this.sum=in.readInt();
}
public Integer getId() {
return id;
}
public UserWritable setId(Integer id) {
this.id = id;
return this;
}
public Integer getIncome() {
return income;
}
public UserWritable setIncome(Integer income) {
this.income = income;
return this;
}
public Integer getExpenses() {
return expenses;
}
public UserWritable setExpenses(Integer expenses) {
this.expenses = expenses;
return this;
}
public Integer getSum() {
return sum;
}
public UserWritable setSum(Integer sum) {
this.sum = sum;
return this;
}
public int compareTo(UserWritable o) {
// TODO Auto-generated method stub
return this.id>o.getId()?1:-1;
}
@Override
public String toString() {
return id + "\t"+income+"\t"+expenses+"\t"+sum;
}
}package com.cakin.hadoop.mr;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.Reducer;
/*
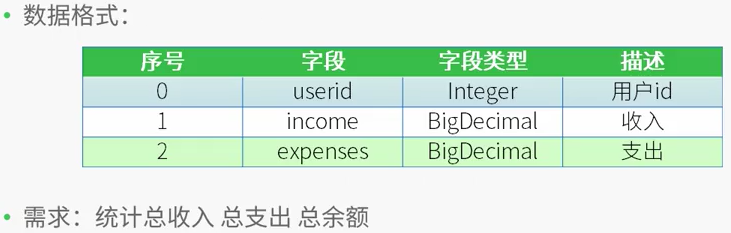
* 测试数据
* 用户id 收入 支出
* 1 1000 0
* 2 500 300
* 1 2000 1000
* 2 500 200
*
* 需求:
* 用户id 总收入 总支出 总的余额
* 1 3000 1000 2000
* 2 1000 500 500
* */
public class CountMapReduce {
public static class CountMapper extends Mapper<LongWritable,Text,IntWritable,UserWritable>
{
private UserWritable userWritable =new UserWritable();
private IntWritable id =new IntWritable();
@Override
protected void map(LongWritable key,Text value,
Mapper<LongWritable,Text,IntWritable,UserWritable>.Context context) throws IOException, InterruptedException{
String line = value.toString();
String[] words = line.split("\t");
if(words.length ==3)
{
userWritable.setId(Integer.parseInt(words[0]))
.setIncome(Integer.parseInt(words[1]))
.setExpenses(Integer.parseInt(words[2]))
.setSum(Integer.parseInt(words[1])-Integer.parseInt(words[2]));
id.set(Integer.parseInt(words[0]));
}
context.write(id, userWritable);
}
}
public static class CountReducer extends Reducer<IntWritable,UserWritable,UserWritable,NullWritable>
{
/*
* 输入数据
* <1,{[1,1000,0,1000],[1,2000,1000,1000]}>
* <2,[2,500,300,200],[2,500,200,300]>
*
* */
private UserWritable userWritable = new UserWritable();
private NullWritable n = NullWritable.get();
protected void reduce(IntWritable key,Iterable<UserWritable> values,
Reducer<IntWritable,UserWritable,UserWritable,NullWritable>.Context context) throws IOException, InterruptedException{
Integer income=0;
Integer expenses = 0;
Integer sum =0;
for(UserWritable u:values)
{
income += u.getIncome();
expenses+=u.getExpenses();
}
sum = income - expenses;
userWritable.setId(key.get())
.setIncome(income)
.setExpenses(expenses)
.setSum(sum);
context.write(userWritable, n);
}
}
public static void main(String[] args) throws IllegalArgumentException, IOException, ClassNotFoundException, InterruptedException {
Configuration conf=new Configuration();
/*
* 集群中节点都有配置文件
conf.set("mapreduce.framework.name.", "yarn");
conf.set("yarn.resourcemanager.hostname", "mini1");
*/
Job job=Job.getInstance(conf,"countMR");
//jar包在哪里,现在在客户端,传递参数
//任意运行,类加载器知道这个类的路径,就可以知道jar包所在的本地路径
job.setJarByClass(CountMapReduce.class);
//指定本业务job要使用的mapper/Reducer业务类
job.setMapperClass(CountMapper.class);
job.setReducerClass(CountReducer.class);
//指定mapper输出数据的kv类型
job.setMapOutputKeyClass(IntWritable.class);
job.setMapOutputValueClass(UserWritable.class);
//指定最终输出的数据kv类型
job.setOutputKeyClass(UserWritable.class);
job.setOutputKeyClass(NullWritable.class);
//指定job的输入原始文件所在目录
FileInputFormat.setInputPaths(job, new Path(args[0]));
//指定job的输出结果所在目录
FileOutputFormat.setOutputPath(job, new Path(args[1]));
//将job中配置的相关参数及job所用的java类在的jar包,提交给yarn去运行
//提交之后,此时客户端代码就执行完毕,退出
//job.submit();
//等集群返回结果在退出
boolean res=job.waitForCompletion(true);
System.exit(res?0:1);
//类似于shell中的$?
}
}[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /input/data
1 1000 0
2 500 300
1 2000 1000
2 500 200[root@centos hadoop-2.7.4]# bin/yarn jar /root/jar/mapreduce.jar /input/data /output3
17/12/20 21:24:45 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
17/12/20 21:24:46 WARN mapreduce.JobResourceUploader: Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
17/12/20 21:24:47 INFO input.FileInputFormat: Total input paths to process : 1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: number of splits:1
17/12/20 21:24:47 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1513775596077_0001
17/12/20 21:24:49 INFO impl.YarnClientImpl: Submitted application application_1513775596077_0001
17/12/20 21:24:49 INFO mapreduce.Job: The url to track the job: http://centos:8088/proxy/application_1513775596077_0001/
17/12/20 21:24:49 INFO mapreduce.Job: Running job: job_1513775596077_0001
17/12/20 21:25:13 INFO mapreduce.Job: Job job_1513775596077_0001 running in uber mode : false
17/12/20 21:25:13 INFO mapreduce.Job: map 0% reduce 0%
17/12/20 21:25:38 INFO mapreduce.Job: map 100% reduce 0%
17/12/20 21:25:54 INFO mapreduce.Job: map 100% reduce 100%
17/12/20 21:25:56 INFO mapreduce.Job: Job job_1513775596077_0001 completed successfully
17/12/20 21:25:57 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=94
FILE: Number of bytes written=241391
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=135
HDFS: Number of bytes written=32
HDFS: Number of read operations=6
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=23672
Total time spent by all reduces in occupied slots (ms)=11815
Total time spent by all map tasks (ms)=23672
Total time spent by all reduce tasks (ms)=11815
Total vcore-milliseconds taken by all map tasks=23672
Total vcore-milliseconds taken by all reduce tasks=11815
Total megabyte-milliseconds taken by all map tasks=24240128
Total megabyte-milliseconds taken by all reduce tasks=12098560
Map-Reduce Framework
Map input records=4
Map output records=4
Map output bytes=80
Map output materialized bytes=94
Input split bytes=94
Combine input records=0
Combine output records=0
Reduce input groups=2
Reduce shuffle bytes=94
Reduce input records=4
Reduce output records=2
Spilled Records=8
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=157
CPU time spent (ms)=1090
Physical memory (bytes) snapshot=275660800
Virtual memory (bytes) snapshot=4160692224
Total committed heap usage (bytes)=139264000
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=41
File Output Format Counters
Bytes Written=32[root@centos hadoop-2.7.4]# bin/hdfs dfs -cat /output3/part-r-00000
1 3000 1000 2000
2 1000 500 500智能推荐
计算机丢失concrt140,小编教你解决concrt140 dll 【解决教程】 的技巧_-程序员宅基地
文章浏览阅读4.5w次。近日有小伙伴发现电脑出现问题了,在突然遇到concrt140 dll时不知所措了,对于concrt140 dll带来的问题,其实很好解决concrt140 dll带来的问题,下面小编跟大家介绍concrt140 dll解决方法:丢失CONCRT140.dll,怎么办?答:分析及解决:网上下载这个DLL文件,将其放置到system32目录下面。 重启系统,或者在CMD下面运行regsvr32*.dl..._concrt140.dll下载教程
微信小程序源码案例大全_微信小程序switch页面demo-程序员宅基地
文章浏览阅读4.3k次,点赞4次,收藏62次。微信小程序demo:足球,赛事分析 小程序简易导航 小程序demo:办公审批 小程序Demo:电魔方 小程序demo:借阅伴侣 微信小程序demo:投票 微信小程序demo:健康生活 小程序demo:文章列表demo 微商城(含微信小程序)完整源码+配置指南 微信小程序Demo:一个简单的工作系统 微信小程序Demo:用于聚会的小程序 微信小程序Demo:Growth 是一款..._微信小程序switch页面demo
SLAM学习笔记(Code2)----刚体运动、Eigen库_eigen.determinant-程序员宅基地
文章浏览阅读2.2k次。2.1除了#include<iostream>之外的头文件#include <Eigen/Core>//Core:核心#include <Eigen/Dense>//求矩阵的逆、特征值、行列式等#include <Eigen/Geometry>//Eigen的几何模块,可以利用矩阵完成如旋转、平移/***其他***/#include <ctime>//可用于计时,比较哪个程序更快#include <cmath>//包含a_eigen.determinant
图像梯度-sobel算子-程序员宅基地
文章浏览阅读1w次,点赞12次,收藏61次。(1)理论部分x 水平方向的梯度, 其实也就是右边 - 左边,有的权重为1,有的为2 。若是计算出来的值很大 说明是一个边界 。y 竖直方向的梯度,其实也就是下面减上面,权重1,或2 。若是计算出来的值很大 说明是一个边界 。图像的梯度为:有时简化为:即:(2)程序部分函数:Sobelddepth 通常取 -1,但是会导致结果溢出,检测不出边缘,故使..._sobel算子
cuda10.1和cudnn7.6.5百度网盘下载链接(Linux版)_cudnn7.6网盘下载-程序员宅基地
文章浏览阅读3.6k次,点赞17次,收藏8次。cuda10.1和cudnn7.6.5百度网盘下载链接(Linux版)在官网下载不仅慢,,,主要是还总失败。。终于下载成功了,这里给出百度网盘下载链接,希望可以帮到别人百度网盘下载链接提取码: vyg5_cudnn7.6网盘下载
Python正则表达式大全-程序员宅基地
文章浏览阅读9.3w次,点赞69次,收藏427次。定义:正则表达式是对字符串(包括普通字符(例如,a 到 z 之间的字母)和特殊字符(称为“元字符”))操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。正则表达式是一种文本模式,该模式描述在搜索文本时要匹配的一个或多个字符串。上面都是官方的说明,我自己的理解是(仅供参考):通过事先规定好一些特殊字符的匹配规则,然后利用这些字符进行组合来匹配各种复杂的字符串场景。比如现在的爬虫和数据分析,字符串校验等等都需要用_python正则表达式
随便推点
NILM(非侵入式电力负荷监测)学习笔记 —— 准备工作(一)配置环境NILMTK Toolkit_nilmtk学习-程序员宅基地
文章浏览阅读1.9w次,点赞27次,收藏122次。安装Anaconda,Python,pycharm我另一篇文章里面有介绍https://blog.csdn.net/wwb1990/article/details/103883775安装NILMTK有了上面的环境,接下来进入正题。NILMTK官网:http://nilmtk.github.io/因为官方安装流程是基于linux的(官方安装流程),我这里提供windows..._nilmtk学习
k8s-pod 控制器-程序员宅基地
文章浏览阅读826次,点赞20次,收藏28次。如果实际 Pod 数量比指定的多那就结束掉多余的,如果实际数量比指定的少就新启动一些Pod,当 Pod 失败、被删除或者挂掉后,RC 都会去自动创建新的 Pod 来保证副本数量,所以即使只有一个 Pod,我们也应该使用 RC 来管理我们的 Pod。label 与 selector 配合,可以实现对象的“关联”,“Pod 控制器” 与 Pod 是相关联的 —— “Pod 控制器”依赖于 Pod,可以给 Pod 设置 label,然后给“控制器”设置对应的 selector,这就实现了对象的关联。
相关工具设置-程序员宅基地
文章浏览阅读57次。1. ultraEdit设置禁止自动更新: 菜单栏:高级->配置->应用程序布局->其他 取消勾选“自动检查更新”2.xshell 传输文件中设置编码,防止乱码: 文件 -- 属性 -- 选项 -- 连接 -- 使用UTF-8编码3.乱码修改:修改tomcat下配置中,修改: <Connector connectionTimeou..._高级-配置-应用程序布局
ico引入方法_arco的ico怎么导入-程序员宅基地
文章浏览阅读1.2k次。打开下面的网站后,挑选要使用的,https://icomoon.io/app/#/select/image下载后 解压 ,先把fonts里面的文件复制到项目fonts文件夹中去,然后打开其中的style.css文件找到类似下面的代码@font-face {font-family: ‘icomoon’;src: url(’…/fonts/icomoon.eot?r069d6’);s..._arco的ico怎么导入
Microsoft Visual Studio 2010(VS2010)正式版 CDKEY_visual_studio_2010_professional key-程序员宅基地
文章浏览阅读1.9k次。Microsoft Visual Studio 2010(VS2010)正式版 CDKEY / SN:YCFHQ-9DWCY-DKV88-T2TMH-G7BHP企业版、旗舰版都适用推荐直接下载电驴资源的vs旗舰版然后安装,好用方便且省时!) MSDN VS2010 Ultimate 简体中文正式旗舰版破解版下载(附序列号) visual studio 2010正_visual_studio_2010_professional key
互联网医疗的定义及架构-程序员宅基地
文章浏览阅读3.2k次,点赞2次,收藏17次。导读:互联网医疗是指综合利用大数据、云计算等信息技术使得传统医疗产业与互联网、物联网、人工智能等技术应用紧密集合,形成诊前咨询、诊中诊疗、诊后康复保健、慢性病管理、健康预防等大健康生态深度..._线上医疗的定义