Linux内存管理:什么是CMA(contiguous memory allocation)连续内存分配器?可与DMA结合使用_swiotlb-程序员宅基地
技术标签: 【Linux内核】
目录
cma,全称(contiguous memory allocation),在内存初始化时预留一块连续内存,可以在内存碎片化严重时通过调用dma_alloc_contiguous接口并且gfp指定为__GFP_DIRECT_RECLAIM从预留的那块连续内存中分配大块连续内存。
1. 概述
Contiguous Memory Allocator, CMA,连续内存分配器,用于分配连续的大块内存。
连续内存分配器(CMA)是一个框架,它允许为物理连续内存管理设置特定于计算机的配置。然后根据该配置分配设备的内存。该框架的主要作用不是分配内存,而是解析和管理内存配置,并充当设备驱动程序和可插拔分配器之间的中介。因此,它不依赖于任何内存分配方法或策略。
嵌入式系统上的各种设备不支持散点图和/或IO映射,因此需要连续的内存块才能运行。它们包括相机,硬件视频解码器和编码器等设备。此类设备通常需要大的内存缓冲区(例如,全高清帧的大小大于2兆像素,即,内存大小超过6 MB),这使得kmalloc()之类的机制无效。一些嵌入式设备对缓冲区提出了额外的要求,例如,它们只能在分配给特定位置/内存库(如果系统具有多个内存库)的缓冲区或与特定内存边界对齐的缓冲区上运行。嵌入式设备的开发最近出现了很大的增长(尤其是在V4L领域),许多这样的驱动程序都包含了自己的内存分配代码。他们中的大多数使用基于bootmem的方法。
CMA分配器,会Reserve一片物理内存区域:
- 设备驱动不用时,内存管理系统将该区域用于分配和管理可移动类型页面;
- 设备驱动使用时,用于连续内存分配,此时已经分配的页面需要进行迁移;
此外,CMA分配器还可以与DMA子系统集成在一起,使用DMA的设备驱动程序无需使用单独的CMA API。

《搞懂Linux零拷贝,DMA》https://rtoax.blog.csdn.net/article/details/108825666
《ARM SMMU原理与IOMMU技术(“VT-d” DMA、I/O虚拟化、内存虚拟化)》
1.1.为什么在默认版本中使用它
大多数i.MX SoC都没有针对特定IP的IOMMU,后者需要较大的连续内存来进行操作,例如VPU / GPU / ISI / CSI。或者他们有IOMMU,但是性能却不怎么样。在默认的i.MX BSP中,我们仍然为那些IP驱动程序分配物理连续内存,以进行DMA传输。
在arm64内核中,DMA分配API将以各种方式分配内存,具体取决于设备配置(在dts或gfp标志中)。下表显示了DMA分配API(不带IOMMU的设备)如何工作以找到正确的页面方式(按顺序,连贯池-> CMA->好友-> SWIOTLB):
| Allocator (by order) | Configurations (w/o IOMMU) | Comments | Mapping |
|---|---|---|---|
| Coherent Pool |
|
By __alloc_from_pool() | Already mapped on boot when coherent pool init in VMALLOC |
| CMA |
|
By cma_alloc() | map_vm_area, mapped in VMALLOC |
| Buddy |
|
By __get_free_pages(), which can only allocate from the DMA/normal zone (lowmem), 32bits address spaces | Already mapped in the lowmem area by kernel on boot |
| SWIOTLB |
|
By map_single() | Already mapped on boot when SWIOTLB init |
翻译一下:
| 分配者(按订单) | 配置(不带IOMMU) | 注释评论 | 映射 |
|---|---|---|---|
| 相干池Coherent Pool |
|
通过__alloc_from_pool() | 在VMALLOC中进行相关池初始化时已在启动时映射 |
| CMA |
|
通过cma_alloc() | map_vm_area,在VMALLOC中映射 |
| 伙伴Buddy |
|
通过只能从DMA /正常区域(lowmem)分配的__get_free_pages(),可以使用32位地址空间 | 引导时已经由内核映射到lowmem区域 |
| SWIOTLB |
|
由map_single() | SWIOTLB初始化时已在启动时映射 |
还显示了它的工作原理(DMA分配路径):

默认情况下,在大多数情况下,内核使用CMA作为DMA缓冲区分配的后端。这就是为什么i.MX BSP在默认版本中将CMA用于GPU / VPU / CSI / ISI或其他用于DMA传输的缓冲区的原因。
https://rtoax.blog.csdn.net/article/details/109558498

2. 数据结构
内核定义了struct cma结构,用于管理一个CMA区域,此外还定义了全局的cma数组,如下:
struct cma {
unsigned long base_pfn;
unsigned long count;
unsigned long *bitmap;
unsigned int order_per_bit; /* Order of pages represented by one bit */
struct mutex lock;
#ifdef CONFIG_CMA_DEBUGFS
struct hlist_head mem_head;
spinlock_t mem_head_lock;
#endif
const char *name;
};
extern struct cma cma_areas[MAX_CMA_AREAS];
extern unsigned cma_area_count;base_pfn:CMA区域物理地址的起始页帧号;count:CMA区域总体的页数;*bitmap:位图,用于描述页的分配情况;order_per_bit:位图中每个bit描述的物理页面的order值,其中页面数为2^order值;
来一张图就会清晰明了:


3. 流程分析
3.1 CMA区域创建
3.1.1 方式一 根据dts来配置
之前的文章也都分析过,物理内存的描述放置在dts中,最终会在系统启动过程中,对dtb文件进行解析,从而完成内存信息注册。
CMA的内存在dts中的描述示例如下图:
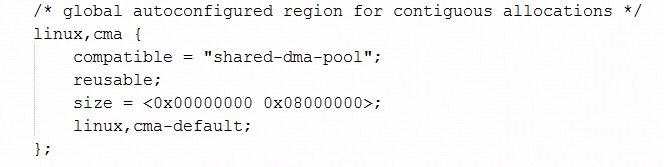
在dtb解析过程中,会调用到rmem_cma_setup函数:
RESERVEDMEM_OF_DECLARE(cma, "shared-dma-pool", rmem_cma_setup);
3.1.2 方式二 根据参数或宏配置
可以通过内核参数或配置宏,来进行CMA区域的创建,最终会调用到cma_declare_contiguous函数,如下图:

3.2 CMA添加到Buddy System
在创建完CMA区域后,该内存区域成了保留区域,如果单纯给驱动使用,显然会造成内存的浪费,因此内存管理模块会将CMA区域添加到Buddy System中,用于可移动页面的分配和管理。CMA区域是通过cma_init_reserved_areas接口来添加到Buddy System中的。
core_initcall(cma_init_reserved_areas);
core_initcall宏将cma_init_reserved_areas函数放置到特定的段中,在系统启动的时候会调用到该函数。

3.3 CMA分配/释放
CMA分配,入口函数为cma_alloc:

CMA释放,入口函数为cma_release:函数比较简单,直接贴上代码
/**
* cma_release() - release allocated pages
* @cma: Contiguous memory region for which the allocation is performed.
* @pages: Allocated pages.
* @count: Number of allocated pages.
*
* This function releases memory allocated by alloc_cma().
* It returns false when provided pages do not belong to contiguous area and
* true otherwise.
*/
bool cma_release(struct cma *cma, const struct page *pages, unsigned int count)
{
unsigned long pfn;
if (!cma || !pages)
return false;
pr_debug("%s(page %p)\n", __func__, (void *)pages);
pfn = page_to_pfn(pages);
if (pfn < cma->base_pfn || pfn >= cma->base_pfn + cma->count)
return false;
VM_BUG_ON(pfn + count > cma->base_pfn + cma->count);
free_contig_range(pfn, count);
cma_clear_bitmap(cma, pfn, count);
trace_cma_release(pfn, pages, count);
return true;
}3.4 DMA使用
代码参考driver/base/dma-contiguous.c,主要包括的接口有:
/**
* dma_alloc_from_contiguous() - allocate pages from contiguous area
* @dev: Pointer to device for which the allocation is performed.
* @count: Requested number of pages.
* @align: Requested alignment of pages (in PAGE_SIZE order).
* @gfp_mask: GFP flags to use for this allocation.
*
* This function allocates memory buffer for specified device. It uses
* device specific contiguous memory area if available or the default
* global one. Requires architecture specific dev_get_cma_area() helper
* function.
*/
struct page *dma_alloc_from_contiguous(struct device *dev, size_t count,
unsigned int align, gfp_t gfp_mask);
/**
* dma_release_from_contiguous() - release allocated pages
* @dev: Pointer to device for which the pages were allocated.
* @pages: Allocated pages.
* @count: Number of allocated pages.
*
* This function releases memory allocated by dma_alloc_from_contiguous().
* It returns false when provided pages do not belong to contiguous area and
* true otherwise.
*/
bool dma_release_from_contiguous(struct device *dev, struct page *pages,
int count);在上述的接口中,实际调用的就是cma_alloc/cma_release接口来实现的。
整体来看,CMA分配器还是比较简单易懂,也不再深入分析。
4.CMA利弊
4.1.优点
- 精心设计,即使在内存碎片情况下也可用于大型连续内存分配。
- CMA中的页面可以由伙伴系统共享,而不是保留池共享
- 可以是特定于设备的CMA区域,仅由该设备使用并与系统共享
- 无需重新编译内核即可轻松配置它的启动地址和大小
4.2.缺点
- 需要迁移页面时分配过程变慢
- 容易被系统内存分配破坏。当系统内存不足时,客户可能会遇到cma_alloc故障,这会在前台应用程序需要图形缓冲区进行渲染而RVC希望缓冲区用于CAR反向时导致不良的用户体验。
- 当cma_alloc()需要迁移某些页面时仍可能出现死锁,而这些页面仍在刷新到存储中(当FUSE文件系统在回写路径中有一页时,某些客户已经遇到了死锁,而cma_alloc希望迁移它)。这是编写此文档的最初动机。
5.为什么要摆脱CMA
上面的RED Cons声明。关键是为关键的分配路径(例如GPU图形缓冲区和摄像机/ VPU预览/记录缓冲区)保留内存,以防止分配失败而导致良好的用户体验,分配失败会导致黑屏,预览卡死等。 CMA和FUSE一起工作。
5.1.如何摆脱CMA
要摆脱CMA,基本思想是在DMA分配中切断CMA方式,转向相干池(原子池)。请注意,连贯池只能由DMA分配API使用,它不会与系统伙伴共享。
5.1.1.启用连贯池
在命令行中添加“ coherent_pool = <size>”,Coherent池实际上是从系统默认CMA分配的,因此CMA size> coherent_pool。
此大小没有参考,因为从系统到系统以及用例到用例各有不同:
- DMA的最大消耗者是GPU,其使用情况可以通过gmem_info工具进行监控。在典型的用例下监视gmem_info,并确定GPU所需的内存。
- 检查DMA的第二个使用者:ISI /相机,取决于V4l2 reqbuf的大小和数量
- 检查VPU,取决于多媒体框架
- 加上alsa snd,USB,fec使用
必须通过测试验证大小,以确保系统稳定。
5.1.2. DMA分配技巧
修改至arch / arm64 / mm / dma-mapping.c,在__dma_alloc()函数中删除gfpflags_allow_blocking检查:
diff --git a/arch/arm64/mm/dma-mapping.c b/arch/arm64/mm/dma-mapping.c
index 7015d3e..ef30b46 100644
--- a/arch/arm64/mm/dma-mapping.c
+++ b/arch/arm64/mm/dma-mapping.c
@@ -147,7 +147,7 @@ static void *__dma_alloc(struct device *dev, size_t size,
size = PAGE_ALIGN(size);
- if (!coherent && !gfpflags_allow_blocking(flags)) {
+ if (!coherent) { // && !gfpflags_allow_blocking(flags)) {
struct page *page = NULL;
void *addr = __alloc_from_pool(size, &page, flags);
5.1.3.离子分配器
在Android和Yocto版本中,ION分配器(Android临时驱动程序)都用于VPU缓冲区。它默认进入ION CMA堆。这意味着ION对连续内存的请求直接发送给CMA。为了避免CMA,我们可以在ION中使用分割堆栈而不是CMA堆栈:
5.1.3.1安卓
启用CARVEOUT堆,禁用CMA堆:
CONFIG_ION = y
CONFIG_ION_SYSTEM_HEAP = y
-CONFIG_ION_CMA_HEAP = y
+ CONFIG_ION_CARVEOUT_HEAP = y
+ CONFIG_ION_CMA_HEAP = n在dts中调整分割保留的堆基地址和大小:
/ {
reserved-memory {
#address-cells = <2>;
#size-cells = <2>;
ranges;
carveout_region: imx_ion@0 {
compatible = "imx-ion-pool";
reg = <0x0 0xf8000000 0 0x8000000>;
};
};
};5.1.3.2 Linux
- 内核-请参阅i.MX8QM的随附补丁。与Linux几乎相同,但需要对ION分离堆驱动程序进行修补。
- Gstreamer-应用以下补丁从分配中分配:
yocto / build-8qm / tmp / work / aarch64-mx8-poky-linux / gstreamer1.0-plugins-base / 1.14.4.imx-r0 / git:
diff --git a/gst-libs/gst/allocators/gstionmemory.c b/gst-libs/gst/allocators/gstionmemory.c
index 1218c4a..12e403d 100644
--- a/gst-libs/gst/allocators/gstionmemory.c
+++ b/gst-libs/gst/allocators/gstionmemory.c
@@ -227,7 +227,8 @@ gst_ion_alloc_alloc (GstAllocator * allocator, gsize size,
}
for (gint i=0; i<heapCnt; i++) {
- if (ihd[i].type == ION_HEAP_TYPE_DMA) {
+ if (ihd[i].type == ION_HEAP_TYPE_DMA ||
+ ihd[i].type == ION_HEAP_TYPE_CARVEOUT) {
heap_mask |= 1 << ihd[i].heap_id;
}
}
6.CMA documentation file
https://lwn.net/Articles/396707/
* Contiguous Memory Allocator
The Contiguous Memory Allocator (CMA) is a framework, which allows
setting up a machine-specific configuration for physically-contiguous
memory management. Memory for devices is then allocated according
to that configuration.
The main role of the framework is not to allocate memory, but to
parse and manage memory configurations, as well as to act as an
in-between between device drivers and pluggable allocators. It is
thus not tied to any memory allocation method or strategy.
** Why is it needed?
Various devices on embedded systems have no scatter-getter and/or
IO map support and as such require contiguous blocks of memory to
operate. They include devices such as cameras, hardware video
decoders and encoders, etc.
Such devices often require big memory buffers (a full HD frame is,
for instance, more then 2 mega pixels large, i.e. more than 6 MB
of memory), which makes mechanisms such as kmalloc() ineffective.
Some embedded devices impose additional requirements on the
buffers, e.g. they can operate only on buffers allocated in
particular location/memory bank (if system has more than one
memory bank) or buffers aligned to a particular memory boundary.
Development of embedded devices have seen a big rise recently
(especially in the V4L area) and many such drivers include their
own memory allocation code. Most of them use bootmem-based methods.
CMA framework is an attempt to unify contiguous memory allocation
mechanisms and provide a simple API for device drivers, while
staying as customisable and modular as possible.
** Design
The main design goal for the CMA was to provide a customisable and
modular framework, which could be configured to suit the needs of
individual systems. Configuration specifies a list of memory
regions, which then are assigned to devices. Memory regions can
be shared among many device drivers or assigned exclusively to
one. This has been achieved in the following ways:
1. The core of the CMA does not handle allocation of memory and
management of free space. Dedicated allocators are used for
that purpose.
This way, if the provided solution does not match demands
imposed on a given system, one can develop a new algorithm and
easily plug it into the CMA framework.
The presented solution includes an implementation of a best-fit
algorithm.
2. CMA allows a run-time configuration of the memory regions it
will use to allocate chunks of memory from. The set of memory
regions is given on command line so it can be easily changed
without the need for recompiling the kernel.
Each region has it's own size, alignment demand, a start
address (physical address where it should be placed) and an
allocator algorithm assigned to the region.
This means that there can be different algorithms running at
the same time, if different devices on the platform have
distinct memory usage characteristics and different algorithm
match those the best way.
3. When requesting memory, devices have to introduce themselves.
This way CMA knows who the memory is allocated for. This
allows for the system architect to specify which memory regions
each device should use.
3a. Devices can also specify a "kind" of memory they want.
This makes it possible to configure the system in such
a way, that a single device may get memory from different
memory regions, depending on the "kind" of memory it
requested. For example, a video codec driver might want to
allocate some shared buffers from the first memory bank and
the other from the second to get the highest possible
memory throughput.
** Use cases
Lets analyse some imaginary system that uses the CMA to see how
the framework can be used and configured.
We have a platform with a hardware video decoder and a camera each
needing 20 MiB of memory in worst case. Our system is written in
such a way though that the two devices are never used at the same
time and memory for them may be shared. In such a system the
following two command line arguments would be used:
cma=r=20M cma_map=video,camera=r
The first instructs CMA to allocate a region of 20 MiB and use the
first available memory allocator on it. The second, that drivers
named "video" and "camera" are to be granted memory from the
previously defined region.
We can see, that because the devices share the same region of
memory, we save 20 MiB of memory, compared to the situation when
each of the devices would reserve 20 MiB of memory for itself.
However, after some development of the system, it can now run
video decoder and camera at the same time. The 20 MiB region is
no longer enough for the two to share. A quick fix can be made to
grant each of those devices separate regions:
cma=v=20M,c=20M cma_map=video=v;camera=c
This solution also shows how with CMA you can assign private pools
of memory to each device if that is required.
Allocation mechanisms can be replaced dynamically in a similar
manner as well. Let's say that during testing, it has been
discovered that, for a given shared region of 40 MiB,
fragmentation has become a problem. It has been observed that,
after some time, it becomes impossible to allocate buffers of the
required sizes. So to satisfy our requirements, we would have to
reserve a larger shared region beforehand.
But fortunately, you have also managed to develop a new allocation
algorithm -- Neat Allocation Algorithm or "na" for short -- which
satisfies the needs for both devices even on a 30 MiB region. The
configuration can be then quickly changed to:
cma=r=30M:na cma_map=video,camera=r
This shows how you can develop your own allocation algorithms if
the ones provided with CMA do not suit your needs and easily
replace them, without the need to modify CMA core or even
recompiling the kernel.
** Technical Details
*** The command line parameters
As shown above, CMA is configured from command line via two
arguments: "cma" and "cma_map". The first one specifies regions
that are to be reserved for CMA. The second one specifies what
regions each device is assigned to.
The format of the "cma" parameter is as follows:
cma ::= "cma=" regions [ ';' ]
regions ::= region [ ';' regions ]
region ::= reg-name
'=' size
[ '@' start ]
[ '/' alignment ]
[ ':' [ alloc-name ] [ '(' alloc-params ')' ] ]
reg-name ::= a sequence of letters and digits
// name of the region
size ::= memsize // size of the region
start ::= memsize // desired start address of
// the region
alignment ::= memsize // alignment of the start
// address of the region
alloc-name ::= a non-empty sequence of letters and digits
// name of an allocator that will be used
// with the region
alloc-params ::= a sequence of chars other then ')' and ';'
// optional parameters for the allocator
memsize ::= whatever memparse() accepts
The format of the "cma_map" parameter is as follows:
cma-map ::= "cma_map=" rules [ ';' ]
rules ::= rule [ ';' rules ]
rule ::= patterns '=' regions
patterns ::= pattern [ ',' patterns ]
regions ::= reg-name [ ',' regions ]
// list of regions to try to allocate memory
// from for devices that match pattern
pattern ::= dev-pattern [ '/' kind-pattern ]
| '/' kind-pattern
// pattern request must match for this rule to
// apply to it; the first rule that matches is
// applied; if dev-pattern part is omitted
// value identical to the one used in previous
// pattern is assumed
dev-pattern ::= pattern-str
// pattern that device name must match for the
// rule to apply.
kind-pattern ::= pattern-str
// pattern that "kind" of memory (provided by
// device) must match for the rule to apply.
pattern-str ::= a non-empty sequence of characters with '?'
meaning any character and possible '*' at
the end meaning to match the rest of the
string
Some examples (whitespace added for better readability):
cma = r1 = 64M // 64M region
@512M // starting at address 512M
// (or at least as near as possible)
/1M // make sure it's aligned to 1M
:foo(bar); // uses allocator "foo" with "bar"
// as parameters for it
r2 = 64M // 64M region
/1M; // make sure it's aligned to 1M
// uses the first available allocator
r3 = 64M // 64M region
@512M // starting at address 512M
:foo; // uses allocator "foo" with no parameters
cma_map = foo = r1;
// device foo with kind==NULL uses region r1
foo/quaz = r2; // OR:
/quaz = r2;
// device foo with kind == "quaz" uses region r2
foo/* = r3; // OR:
/* = r3;
// device foo with any other kind uses region r3
bar/* = r1,r2;
// device bar with any kind uses region r1 or r2
baz?/a* , baz?/b* = r3;
// devices named baz? where ? is any character
// with kind being a string starting with "a" or
// "b" use r3
*** The device and kind of memory
The name of the device is taken form the device structure. It is
not possible to use CMA if driver does not register a device
(actually this can be overcome if a fake device structure is
provided with at least the name set).
The kind of memory is an optional argument provided by the device
whenever it requests memory chunk. In many cases this can be
ignored but sometimes it may be required for some devices.
For instance, let say that there are two memory banks and for
performance reasons a device uses buffers in both of them. In
such case, the device driver would define two kinds and use it for
different buffers. Command line arguments could look as follows:
cma=a=32M@0,b=32M@512M cma_map=foo/a=a;foo/b=b
And whenever the driver allocated the memory it would specify the
kind of memory:
buffer1 = cma_alloc(dev, 1 << 20, 0, "a");
buffer2 = cma_alloc(dev, 1 << 20, 0, "b");
If it was needed to try to allocate from the other bank as well if
the dedicated one is full command line arguments could be changed
to:
cma=a=32M@0,b=32M@512M cma_map=foo/a=a,b;foo/b=b,a
On the other hand, if the same driver was used on a system with
only one bank, the command line could be changed to:
cma=r=64M cma_map=foo/*=r
without the need to change the driver at all.
*** API
There are four calls provided by the CMA framework to devices. To
allocate a chunk of memory cma_alloc() function needs to be used:
unsigned long cma_alloc(const struct device *dev,
const char *kind,
unsigned long size,
unsigned long alignment);
If required, device may specify alignment that the chunk need to
satisfy. It have to be a power of two or zero. The chunks are
always aligned at least to a page.
The kind specifies the kind of memory as described to in the
previous subsection. If device driver does not use notion of
memory kinds it's safe to pass NULL as the kind.
The basic usage of the function is just a:
addr = cma_alloc(dev, NULL, size, 0);
The function returns physical address of allocated chunk or
a value that evaluated true if checked with IS_ERR_VALUE(), so the
correct way for checking for errors is:
unsigned long addr = cma_alloc(dev, size);
if (IS_ERR_VALUE(addr))
return (int)addr;
/* Allocated */
(Make sure to include <linux/err.h> which contains the definition
of the IS_ERR_VALUE() macro.)
Allocated chunk is freed via a cma_put() function:
int cma_put(unsigned long addr);
It takes physical address of the chunk as an argument and
decreases it's reference counter. If the counter reaches zero the
chunk is freed. Most of the time users do not need to think about
reference counter and simply use the cma_put() as a free call.
If one, however, were to share a chunk with others built in
reference counter may turn out to be handy. To increment it, one
needs to use cma_get() function:
int cma_put(unsigned long addr);
The last function is the cma_info() which returns information
about regions assigned to given (dev, kind) pair. Its syntax is:
int cma_info(struct cma_info *info,
const struct device *dev,
const char *kind);
On successful exit it fills the info structure with lower and
upper bound of regions, total size and number of regions assigned
to given (dev, kind) pair.
*** Allocator operations
Creating an allocator for CMA needs four functions to be
implemented.
The first two are used to initialise an allocator far given driver
and clean up afterwards:
int cma_foo_init(struct cma_region *reg);
void cma_foo_done(struct cma_region *reg);
The first is called during platform initialisation. The
cma_region structure has saved starting address of the region as
well as its size. It has also alloc_params field with optional
parameters passed via command line (allocator is free to interpret
those in any way it pleases). Any data that allocate associated
with the region can be saved in private_data field.
The second call cleans up and frees all resources the allocator
has allocated for the region. The function can assume that all
chunks allocated form this region have been freed thus the whole
region is free.
The two other calls are used for allocating and freeing chunks.
They are:
struct cma_chunk *cma_foo_alloc(struct cma_region *reg,
unsigned long size,
unsigned long alignment);
void cma_foo_free(struct cma_chunk *chunk);
As names imply the first allocates a chunk and the other frees
a chunk of memory. It also manages a cma_chunk object
representing the chunk in physical memory.
Either of those function can assume that they are the only thread
accessing the region. Therefore, allocator does not need to worry
about concurrency.
When allocator is ready, all that is left is register it by adding
a line to "mm/cma-allocators.h" file:
CMA_ALLOCATOR("foo", foo)
The first "foo" is a named that will be available to use with
command line argument. The second is the part used in function
names.
*** Integration with platform
There is one function that needs to be called form platform
initialisation code. That is the cma_regions_allocate() function:
void cma_regions_allocate(int (*alloc)(struct cma_region *reg));
It traverses list of all of the regions given on command line and
reserves memory for them. The only argument is a callback
function used to reserve the region. Passing NULL as the argument
makes the function use cma_region_alloc() function which uses
bootmem for allocating.
Alternatively, platform code could traverse the cma_regions array
by itself but this should not be necessary.
The If cma_region_alloc() allocator is used, the
cma_regions_allocate() function needs to be allocated when bootmem
is active.
Platform has also a way of providing default cma and cma_map
parameters. cma_defaults() function is used for that purpose:
int cma_defaults(const char *cma, const char *cma_map)
It needs to be called after early params have been parsed but
prior to allocating regions. Arguments of this function are used
only if they are not-NULL and respective command line argument was
not provided.
** Future work
In the future, implementation of mechanisms that would allow the
free space inside the regions to be used as page cache, filesystem
buffers or swap devices is planned. With such mechanisms, the
memory would not be wasted when not used.
Because all allocations and freeing of chunks pass the CMA
framework it can follow what parts of the reserved memory are
freed and what parts are allocated. Tracking the unused memory
would let CMA use it for other purposes such as page cache, I/O
buffers, swap, etc.
7.后记
内存管理的分析先告一段落,后续可能还会针对某些模块进一步的研究与完善。
内存管理子系统,极其复杂,盘根错节,很容易就懵圈了,尽管费了不少心力,也只能说略知皮毛。
学习就像是爬山,面对一座高山,可能会有心理障碍,但是当你跨越之后,再看到同样高的山,心理上你将不再畏惧。
接下来将研究进程管理子系统,将任督二脉打通。
未来会持续分析内核中的各类框架,并发机制等,敬请关注,一起探讨。
https://www.cnblogs.com/LoyenWang/p/12182594.html
8.推荐阅读
《搞懂Linux零拷贝,DMA》https://rtoax.blog.csdn.net/article/details/108825666
《ARM SMMU原理与IOMMU技术(“VT-d” DMA、I/O虚拟化、内存虚拟化)》
《直接内存访问 (Direct Memory Access, DMA)》
《[Linux Device Drivers, 2nd Edition] mmap和DMA》
《arm64/hugetlb: Reserve CMA areas for gigantic pages on 16K and 64K configs》
《“ CMA文档”》
《如何摆脱CMA》
智能推荐
hive使用适用场景_大数据入门:Hive应用场景-程序员宅基地
文章浏览阅读5.8k次。在大数据的发展当中,大数据技术生态的组件,也在不断地拓展开来,而其中的Hive组件,作为Hadoop的数据仓库工具,可以实现对Hadoop集群当中的大规模数据进行相应的数据处理。今天我们的大数据入门分享,就主要来讲讲,Hive应用场景。关于Hive,首先需要明确的一点就是,Hive并非数据库,Hive所提供的数据存储、查询和分析功能,本质上来说,并非传统数据库所提供的存储、查询、分析功能。Hive..._hive应用场景
zblog采集-织梦全自动采集插件-织梦免费采集插件_zblog 网页采集插件-程序员宅基地
文章浏览阅读496次。Zblog是由Zblog开发团队开发的一款小巧而强大的基于Asp和PHP平台的开源程序,但是插件市场上的Zblog采集插件,没有一款能打的,要么就是没有SEO文章内容处理,要么就是功能单一。很少有适合SEO站长的Zblog采集。人们都知道Zblog采集接口都是对Zblog采集不熟悉的人做的,很多人采取模拟登陆的方法进行发布文章,也有很多人直接操作数据库发布文章,然而这些都或多或少的产生各种问题,发布速度慢、文章内容未经严格过滤,导致安全性问题、不能发Tag、不能自动创建分类等。但是使用Zblog采._zblog 网页采集插件
Flink学习四:提交Flink运行job_flink定时运行job-程序员宅基地
文章浏览阅读2.4k次,点赞2次,收藏2次。restUI页面提交1.1 添加上传jar包1.2 提交任务job1.3 查看提交的任务2. 命令行提交./flink-1.9.3/bin/flink run -c com.qu.wc.StreamWordCount -p 2 FlinkTutorial-1.0-SNAPSHOT.jar3. 命令行查看正在运行的job./flink-1.9.3/bin/flink list4. 命令行查看所有job./flink-1.9.3/bin/flink list --all._flink定时运行job
STM32-LED闪烁项目总结_嵌入式stm32闪烁led实验总结-程序员宅基地
文章浏览阅读1k次,点赞2次,收藏6次。这个项目是基于STM32的LED闪烁项目,主要目的是让学习者熟悉STM32的基本操作和编程方法。在这个项目中,我们将使用STM32作为控制器,通过对GPIO口的控制实现LED灯的闪烁。这个STM32 LED闪烁的项目是一个非常简单的入门项目,但它可以帮助学习者熟悉STM32的编程方法和GPIO口的使用。在这个项目中,我们通过对GPIO口的控制实现了LED灯的闪烁。LED闪烁是STM32入门课程的基础操作之一,它旨在教学生如何使用STM32开发板控制LED灯的闪烁。_嵌入式stm32闪烁led实验总结
Debezium安装部署和将服务托管到systemctl-程序员宅基地
文章浏览阅读63次。本文介绍了安装和部署Debezium的详细步骤,并演示了如何将Debezium服务托管到systemctl以进行方便的管理。本文将详细介绍如何安装和部署Debezium,并将其服务托管到systemctl。解压缩后,将得到一个名为"debezium"的目录,其中包含Debezium的二进制文件和其他必要的资源。注意替换"ExecStart"中的"/path/to/debezium"为实际的Debezium目录路径。接下来,需要下载Debezium的压缩包,并将其解压到所需的目录。
Android 控制屏幕唤醒常亮或熄灭_android实现拿起手机亮屏-程序员宅基地
文章浏览阅读4.4k次。需求:在诗词曲文项目中,诗词整篇朗读的时候,文章没有读完会因为屏幕熄灭停止朗读。要求:在文章没有朗读完毕之前屏幕常亮,读完以后屏幕常亮关闭;1.权限配置:设置电源管理的权限。
随便推点
目标检测简介-程序员宅基地
文章浏览阅读2.3k次。目标检测简介、评估标准、经典算法_目标检测
记SQL server安装后无法连接127.0.0.1解决方法_sqlserver 127 0 01 无法连接-程序员宅基地
文章浏览阅读6.3k次,点赞4次,收藏9次。实训时需要安装SQL server2008 R所以我上网上找了一个.exe 的安装包链接:https://pan.baidu.com/s/1_FkhB8XJy3Js_rFADhdtmA提取码:ztki注:解压后1.04G安装时Microsoft需下载.NET,更新安装后会自动安装如下:点击第一个傻瓜式安装,唯一注意的是在修改路径的时候如下不可修改:到安装实例的时候就可以修改啦数据..._sqlserver 127 0 01 无法连接
js 获取对象的所有key值,用来遍历_js 遍历对象的key-程序员宅基地
文章浏览阅读7.4k次。1. Object.keys(item); 获取到了key之后就可以遍历的时候直接使用这个进行遍历所有的key跟valuevar infoItem={ name:'xiaowu', age:'18',}//的出来的keys就是[name,age]var keys=Object.keys(infoItem);2. 通常用于以下实力中 <div *ngFor="let item of keys"> <div>{{item}}.._js 遍历对象的key
粒子群算法(PSO)求解路径规划_粒子群算法路径规划-程序员宅基地
文章浏览阅读2.2w次,点赞51次,收藏310次。粒子群算法求解路径规划路径规划问题描述 给定环境信息,如果该环境内有障碍物,寻求起始点到目标点的最短路径, 并且路径不能与障碍物相交,如图 1.1.1 所示。1.2 粒子群算法求解1.2.1 求解思路 粒子群优化算法(PSO),粒子群中的每一个粒子都代表一个问题的可能解, 通过粒子个体的简单行为,群体内的信息交互实现问题求解的智能性。 在路径规划中,我们将每一条路径规划为一个粒子,每个粒子群群有 n 个粒 子,即有 n 条路径,同时,每个粒子又有 m 个染色体,即中间过渡点的_粒子群算法路径规划
量化评价:稳健的业绩评价指标_rar 海龟-程序员宅基地
文章浏览阅读353次。所谓稳健的评估指标,是指在评估的过程中数据的轻微变化并不会显著的影响一个统计指标。而不稳健的评估指标则相反,在对交易系统进行回测时,参数值的轻微变化会带来不稳健指标的大幅变化。对于不稳健的评估指标,任何对数据有影响的因素都会对测试结果产生过大的影响,这很容易导致数据过拟合。_rar 海龟
IAP在ARM Cortex-M3微控制器实现原理_value line devices connectivity line devices-程序员宅基地
文章浏览阅读607次,点赞2次,收藏7次。–基于STM32F103ZET6的UART通讯实现一、什么是IAP,为什么要IAPIAP即为In Application Programming(在应用中编程),一般情况下,以STM32F10x系列芯片为主控制器的设备在出厂时就已经使用J-Link仿真器将应用代码烧录了,如果在设备使用过程中需要进行应用代码的更换、升级等操作的话,则可能需要将设备返回原厂并拆解出来再使用J-Link重新烧录代码,这就增加了很多不必要的麻烦。站在用户的角度来说,就是能让用户自己来更换设备里边的代码程序而厂家这边只需要提供给_value line devices connectivity line devices