【机器学习】Sklearn-cluster聚类方法_sklearn cluster-程序员宅基地
技术标签: 机器学习
Classes1
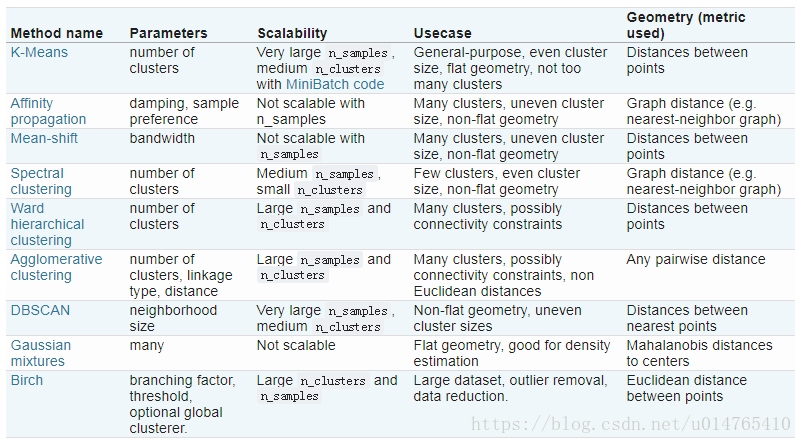
各种聚类方法特性汇总:
sklearn.cluster.KMeans
from sklearn.cluster import KMeans
KMeans(n_clusters=8,init='k-means++',n_init=10,max_iter=300,tol=0.0001,precompute_distances='auto',verbose=0,random_state=None,copy_x=True,n_jobs=1,algorithm='auto')
#n_clusters:class的个数;
#max_inter:每一个初始化值下,最大的iteration次数;
#n_init:尝试用n_init个初始化值进行拟合;
#tol:within-cluster sum of square to declare convergence;
#init=‘k-means++’:可使初始化的centroids相互远离;
算法要点:
1、将training data (X)分为k clusters;
2、object function:
3、缺陷:
1)KMeans假设clusters是convex or isotropics;他不能很好的拟合elongated clusters or manifolds with irregular shape;
2)欧几里得距离会随着特征数量的增加(dimension),而变得越来越膨胀;从而影响模型收敛。针对这一问题,一个好的解决方法是:可以利用PCA等降维工具先将data的特征数目降低在可接受的范围内,然后在计算其欧几里得距离;
3)initial centroids选择不慎,可能会使模型convergence to local minimum;利用KMeans的参数init=‘k-means++’,可以使initial centroids相互远离,从而使模型收敛到一个更好的结果。
sklearn.cluster.MiniBatchKMeans
from sklearn.cluster import MiniBatchKMeans(n_clusters=8,init='k-means++',max_iter=100,batch-size=100,verbose=0,compute_labels=True,random_state=None,tol=0.0,max_no_improvement=10,init_size=None,n_init=3,reassignment_ration=0.01)
#n_clusters: class数量;
#batch_size:用来拟合KMeans的subset size;
#compute_labels=True:将在batch_size上的拟合结果应用到整个data;
#tol:目标函数变化值<tol时,停止迭代;
#max_no_improvement:当max_no_improvement个batchset停止迭代时,给出最终的模型拟合结果;
算法要点:
相比标准的KMeans算法,MiniBatchKMeans是在subset进行模型拟合;其拟合效果比标准的KMeans算法略差(差别较小);但是MiniBatchKMeans的收敛速度要快于KMeans;
sklearn.cluster.AffinityPropagation
from sklearn.cluster import AffinityPropagation
AffinityPropagation(damping=0.5,max_iter=200,convergence_iter=15,copy=True,preference=None,affinity='euclidean',verbose=False)
#damping:减振因子,用来避免在iteration中r,a的来回震荡;
#preference???
#convergence_iter:在estimated cluster数量不变后,还要进行的iteration次数;
#affinity:用来估计样本之间亲密度的函数:{precomputed,euclidean},{事先定义,欧几里得}
算法要点:
1)工作原理:
AffinityPropagation不需要在运行算法前确定聚类的个数;AffinityPropagation的要旨是选择exampler(data中实际存在的点),用来代表data(exampler的初始化主要是通过preference设定的);
在算法中,exampler的选择主要是通过两个函数进行的:responsibility r(i,k):the responsiblity of sample k to be the exampler of sample i,availability a(i,k):the availability of sample k to be the exampler of sample i;
在算法开始时,将r(i,k)和a(i,k)均设为0,iteration,直到r,a都达到收敛;为了减小r,a在iteration中的震荡,可以引入减振因子(可用damping参数实现);
2)缺陷:算法时间复杂度和空间复杂度均很高;
3)相关公式:
4)参考博文
sklearn.cluster.MeanShift
from sklearn.cluster import MeanShift
MeanShift(bandwidth=None,seeds=None,bin_seeding=False,min_bin_freq=1,cluster_all=True,n_jobs=1)
算法要点:
1)缺陷:由于算法运行过程中需要多次计算最近邻points,因此,该算法的可扩展性不高;estimate_bandwidth function,相比MeanShift算法具有更低的可扩展性,因此,如果在MeanShift算法中引入estimate_bandwidth,将进一步限值MeanShift的使用;
2)参考博文:
MeanShift聚类算法
MeanShift算法介绍
sklearn.cluster.SpectralClustering
from sklearn.cluster import SpectralClustering(n_clusters=8,eigen_solver=None,random_state=None,n_init=10,gamma=1.0,affinity='rbf',n_neighbors=10,eigen_tol=0.0,assign_labels='kmeans',degree=3,coef0=1,kernel_params=None,n_jobs=1)
#n_clusters:聚类的个数;
#eigen_solver:使用的特征值分解策略;
#gamma:计算相似矩阵时,如果使用核函数,该核函数的系数;
#affinity:计算相似度时使用的距离公式;
#n_neighbors:利用k近邻方法构建邻接矩阵时,所使用的k近邻;
#eigen_tol:Stopping criterion for eigendecomposition of the Laplacian matrix when using arpack eigen_solver.
#assign_labels:通过求解“拉普拉斯矩阵特征值”,获得指示向量矩阵(类似于降维后的特征),在指示向量矩阵的基础上,对矩阵各行,运用assign_labels进行聚类;取值:{kmeans,discretize};
#degree:Degree of the polynomial kernel. Ignored by other kernels;
#coef0:Zero coefficient for polynomial and sigmoid kernels. Ignored by other kernels.
#kernel_params:Parameters (keyword arguments) and values for kernel passed as callable object. Ignored by other kernels.
#n_jobs:The number of parallel jobs to run. If -1, then the number of jobs is set to the number of CPU cores.算法要点:
1)优点:
谱聚类只需要数据之间的相似度矩阵,因此对于处理稀疏数据的聚类很有效。这点传统聚类算法比如K-Means很难做到;
由于使用了降维,因此在处理高维数据聚类时的复杂度比传统聚类算法好。
2)缺点:
如果最终聚类的维度非常高,则由于降维的幅度不够,谱聚类的运行速度和最后的聚类效果均不好。
聚类效果依赖于相似矩阵,不同的相似矩阵得到的最终聚类效果可能很不同。
3)参考博文:
谱聚类原理总结
谱聚类及其实现详解
sklearn.cluster.AgglomerativeClustering
from sklearn.cluster import AgglomerativeClustering
AgglomerativeClustering(n_clusters=2,affinity='euclidean',memory=None,connectivity=None,compute_full_tree='auto',linkage='ward',pooling_func=<function mean>)
#affinity:距离计算公式:{eucidean,l1,l2,cosine,manhattan,precomputed}
#memory:是否要缓冲;
#connectivity:是否设定connectivity matrix;
#compute_full_tree:是否要进行完全聚类;
#linkage:进行聚类的标准:{ward,complete,average}
算法要点:
1)将两个不同的类进行融合的标准有3:
ward:minimizes the sum of squared differences within all clusters;
complete:minimizes the maximum distance between observations of pairs of clusters;
average:minimizes the average of the distances between all observations of pairs of clusters.
note that:Agglomerative cluster 可能会导致各个cluster间大小的不均衡;complete 能够导致非常不均衡簇的产生,相比而言 ward 可以产生相对均衡的簇,但是,ward只能采用欧几里得距离公式,不能使用其他的距离公式,因此,如果要用其他的距离公式进行聚类,可使用 average 策略。
2)在算法中引入connectivity matrix 不仅可以将算法应用于更大的数据集,而且可以禁止聚类在特定的subset之间发生,如下图,可保证聚类不在各个folds间发生:
3)度量两点之间距离的公式:{l1,l2,manhattan,cosine,ecludiean}

l1 :比较实用于稀疏矩阵;
cosine :对于数据全局的缩放,可以保持距离不变;
sklearn.cluster.DBSCAN
from sklearn.cluster import DBSCAN
DBSCAN(eps=0.5,min_samples=5,metric='euclidean',mtric_params=None,algorithm='auto',leaf_size=30,p=None,n_jobs=1)
#eps:对象半径;
#min_samples:一个核心对象应该拥有的最少sample数;
#metric:计算样本之间距离的公式;{precomputed,callable}
#algorithm:用来找最近邻样本点算法{'auto','ball_tree','ke_tree'}
#leaf_size:kd_tree或ball_tree中的叶子节点数;决定了搜索快慢;
算法要点:
1)对于给定ordered data,其多次运用该算法的聚类结果相同,但是,对于不同order的同一data,可能会得到不同的结果;
2)如果一个data中重复value较多,可以做成稀疏矩阵,将各个数据根据其重复度设定一个weight,进而,在用DBSCAN拟合数据;
3)参考博文:DBSCAN简介
sklearn.cluster.Birch
from sklearn.cluster import Birch
Birch(threshold=0.5,branching_factor=50,n_clusters=3,compute_labels=True,copy=True)
#threshold:subcluster的半径,如果某一样本点的加入,使subcluster半径超过这个值,则该样本会被分到其它的subcluster;
#branching_factor:每个node拥有的CF个数,如果新加入的CF使node中的CF数超过设定值,则将该Node一分为二;
#n_clusters:想要得到的cluster数量;如果n_cluster=None,则输出叶子结点中所有CF;如果n_cluster= int,则将叶子节点中的CF再次进行聚类;如果n_cluster=instance of sklearn.cluster.model,则将叶子节点中的CF看作new data,利用该model进行聚类;
#copy=False:将overwritten data;
#compute_labels=True:计算所有data sample的label;
算法要点:
1)优点:
节约内存,所有的样本都在磁盘上,CF Tree仅仅存了CF节点和对应的指针。
聚类速度快,只需要一遍扫描训练集就可以建立CF Tree,CF Tree的增删改都很快。
可以识别噪音点,进行异常点检测,还可以对数据集进行初步分类的预处理,降低数据实例数量;
Birch和MiniBatch一样,都使用与数据量较大的情况,但是,MiniBatch适用于类别数较少或中等的情况,而Birch使用与类别数较大的情况;
2)缺点:
由于CF Tree对每个节点的CF个数有限制,导致聚类的结果可能和真实的类别分布不同.
对高维特征的数据聚类效果不好。当n_feature > 20时,此时可以选择Mini Batch K-Means。
如果数据集的分布簇不是类似于超球体,或者说不是凸的,则聚类效果不好。
3)参考博文:BIRCH聚类算法原理
clustering performance evaluation
from sklearn import metrics
metrics.adjusted_rand_score(labels_true,labels_pred)
metrics.adjuested_mutual_info_score(labels_true,labels_pred)
metrics.homogeneity_score(labels_true,labels_pred)
metrics.completeness_score(labels_true,labels_pred)
metrics.v_measure_score(labels_true,labels_pred)
metrics.homogeneity_completeness_v_measure(labels_true,labels_pred)
metrics.fowlkes_mallows_score(labels_true,labels_pred)
metrics.silhouette_score(X,labels,metric='euclidean')
metrics.calinski_harabaz_score(X,labels)
参考文献:Clustering
Class 2
sklearn.cluster.Biclustering
Biclustering 简介
Biclustering同时对rows和columns进行聚类,每一个cluster(rows,columns)被叫做一个bicluster,在聚类的过程中,会重新排列data matrix的rows和columns;比如,一个data matrix(10,10),通过Biclustering,可能会形成一个(3,2)的bicluster(submatrix);
sklearn.cluster.bicluster中有两种biclustering的function:
SpectralBiclustering
sklearn.cluster.bicluster.SpectralBiclustering(n_clusters=3,method='bistochastic',n_components=6,n_best=3,svd_method='randomized',n_svd_vecs=None,mini_batch=False,init='k-means++',n_init=10,n_jobs=1,random_state=None)
该algorithm形成的是一个hidden checkboard structure biclusters,每一个checkboard内各个点的值几乎相同,因此,该checkboard structure提供了一个对原data的近似;
checkboard structure如下图所示:
SpectralCoclustering
sklearn.cluster.bicluster.SpectralCoclustering(n_clusters=3,svd_method='randomized',n_svd_vecs=None,mini_batch=False,init='k-means++',n_init=10,n_jobs=1,random_state=None)
该algorithm形成的是一个diagonal structure,diagonal上的每一个bicluster代表了data matrix中的high values。此算法通过对data matrix gaph进行归一化,从而找到数据图中的heavy subgraph(The algorithm approximates the normalized cut of this graph to find heavy subgraphs.)其结构如下图所示:


---------------------
作者:Wbq_Zero
来源:CSDN
原文:https://blog.csdn.net/u014765410/article/details/82784885
版权声明:本文为博主原创文章,转载请附上博文链接!
智能推荐
怎么才能用SPSS按条件选择数据?_spss如何按条件分类-程序员宅基地
文章浏览阅读1.4w次,点赞4次,收藏41次。我们在进行数据分析的时候,并不是所有的数据都需要进行分析。这就要求我们要对数据进行按条件选择。本文我将用IBM SPSS Statistics演示如何进行按条件筛选数据。1、打开数据如图所示,是一个学生个人信息的数据集。我将在此基础上演示如何筛选出语文成绩大于78的学生。图1:数据展示2、菜单位置如图所示,第一步我们点击菜单栏中的“数据”按钮,第二步选择下级菜单中的“选择个案”。图2:菜单位置3、选择条件如图所示,我们先选中语文成绩,在点击“如果条件满足”.._spss如何按条件分类
离散数学程序实践——差集——c_用c++实现离散数学差运算-程序员宅基地
文章浏览阅读591次。//集合的差集程序实现#include<stdio.h>//降序排序数组void sort( int a[],int n ){ int i,j,k,temp; for( i=0;i<n-1;i++ ){ k=i; for( j=i+1;j<n;j++ ){ if( a[j]>a[k] ) k=j; } if( k!=i ){ temp=a[k]; a[k]=a[i]; a[i]=temp; } }}//计算差集._用c++实现离散数学差运算
python正则表达式-程序员宅基地
文章浏览阅读524次,点赞14次,收藏14次。ndex-editionrecommend 如果没有今天,明天会不会有昨天?[瑞士]伊夫·博萨尔特(YvesBossart) 2017-1。
CentOS操作系统防火墙添加例外端口_centos7域控服务器里防火墙需要例外那些端口-程序员宅基地
文章浏览阅读1w次。CentOS6与CentOS7添加防火墙例外端口的命令不同,需单独来说:(1)CentOS6下添加防火墙例外端口#vim/ets/sysconfig/iptables在 -A INPUT -m state--state NEW -m tcp -p tcp --dport 22 -j ACCEPT一行的后台添加类似的一行命令即可,如 # Firewall configura..._centos7域控服务器里防火墙需要例外那些端口
数据结构|数组为什么这么快?-程序员宅基地
文章浏览阅读2.9k次,点赞8次,收藏10次。我相信在很多地方,大家在进行数据结构的比较的时候,说到数组,第一反应就是—快,但是为什么快呢?数组到底快在哪里呢?不知道大家是否有思考过这个问题,这篇文章,我就讲讲我对数组的一些看法,抛砖引玉,希望大家多多交流!文章目录数组到底哪里快?查找快吗?为什么数组能支持随机访问呢?答案:举例分析:我们要分析的第一个问题是:数组到底哪里快?查找快吗?可能有的同学第一反应利用数组进行查找的话,时间...
基于Matlab图像融合总结_图像融合代码matlab-程序员宅基地
文章浏览阅读273次。图像融合是一种将多幅图像信息合并成一幅新图像的技术,可以获得比单独图像更多的信息。在Matlab中,有多种方法可以实现图像融合,包括像素级融合、变换域融合和深度学习融合等。本文将总结这些方法,并提供相应的源代码。在实际应用中,根据图像融合的具体需求,选择合适的方法进行处理。这些方法可以互相结合,实现更细致、更精确的图像融合效果。希望本文提供的源代码和示例能够对您在Matlab中进行图像融合的工作有所帮助。基于Matlab图像融合总结。_图像融合代码matlab
随便推点
bugfree安装时,提示MySQL未安装_bugfree 显示mysql未安装-程序员宅基地
文章浏览阅读371次。1.解决办法:安装低版本的XAMPP(<7.0版本)2.遇到的问题:安装bugfree,我先安装了XAMPP来搭建环境,但是XAMPP7.0+版本安装成功了,但是后面到了安装bugfree时,输入了http://localhost/bugfree/install,后出现了检测到未安装MySQL数据库,打了一个红色叉子。3.解决过程:我尝试了各种版本的XAMPP和bugfree版本,发现,只要是XAMPP的版本太高,比如是7.0+的,b..._bugfree 显示mysql未安装
Delphi调用Excel设置单元格的格式 _delphi excelapp.worksheets[j].columns[2].numberfor-程序员宅基地
文章浏览阅读1w次。在做设计过程中,需要把数据内容导入到Excel中,可是每次导入EXcel之后,总有一些数据不能正常显示,比如'123456789012'显示为科学技术形式'1.23457E+11’,还有以'0’开头的数据总会把0撇开再显示。在VB中好像这么更改Excel更改单元格式:Worksheets("Sheet1").Range("A17").NumberFormat = "General" //对A17 单元格格式进行设置Worksheets("S_delphi excelapp.worksheets[j].columns[2].numberformatlocal
php的错误和异常处理机制_php exception输出错误行-程序员宅基地
文章浏览阅读2.5k次。php的错误和异常处理机制。1、php错误分类;2、error_reporting、display_errors、log_errors、log_errors_max_len、error_log等配置;3、set_error_handler的使用;4、set_exception_handler 的使用;5、用trigger_error触发错误;6、捕获异常try/catch/finally的使用方式_php exception输出错误行
Java 中应用Dijkstra算法求解最短路径_路由最短路径代码java-程序员宅基地
文章浏览阅读476次。Dijkstra算法是一个经典的解决最短路径问题的算法,在路由算法、导航系统等领域都有广泛的应用。它通过逐步选择距离起始节点最近的节点,并更新其邻接节点的最短距离,最终得到起始节点到其他所有节点的最短路径。然后,在一个循环中,每次选择距离最小且未加入最短路径集合的节点,将其加入最短路径集合,并更新其邻接节点的最短路径长度。它遍历所有未加入最短路径集合(shortestPathTreeSet)的节点,查找距离最小且未加入最短路径集合的节点,并返回其索引。数组来追踪起始节点到其他节点的最短路径长度,_路由最短路径代码java
Mybatis-plus解决selectOne查询多个会报错的问题_mybatisplus selectone-程序员宅基地
文章浏览阅读2w次,点赞13次,收藏36次。123_mybatisplus selectone
【android】android12蓝牙框架_android 蓝牙框架-程序员宅基地
文章浏览阅读1.6k次,点赞15次,收藏22次。参考:hl=zh-cnhl=zh-cnhl=zh-cn。_android 蓝牙框架