dubbo熔断限流_dubbo 限流 熔断-程序员宅基地
技术标签: 流量控制、熔断降级
限流
- 根据排队理论,具有延迟的服务随着请求量的不断提升,其平均响应时间也会迅速提升,为了保证服务的SLA(Service-Level Agreement 服务等级协议),有必要控制单位时间的请求量。这就是限流为什么愈发重要的原因。
分类
-
qps限流
限制每秒处理请求数不超过阈值
-
并发限流
限制同时处理的请求数目。Java 中的 Semaphore(信号量) 是做并发限制的好工具,特别适用于资源有效的场景。
-
单机限流
Guava 中的 RateLimiter(内部采用令牌捅算法实现)。
-
集群限流
redis限流,计时器和计数器处理、key加秒为key
nginx(+lua)前端限流,按照一定的规则如帐号、IP、系统调用逻辑等在Nginx层面做限流
算法
常见的限流算法有:令牌桶、漏桶。计数器也可以进行粗暴限流实现。
-
漏桶算法
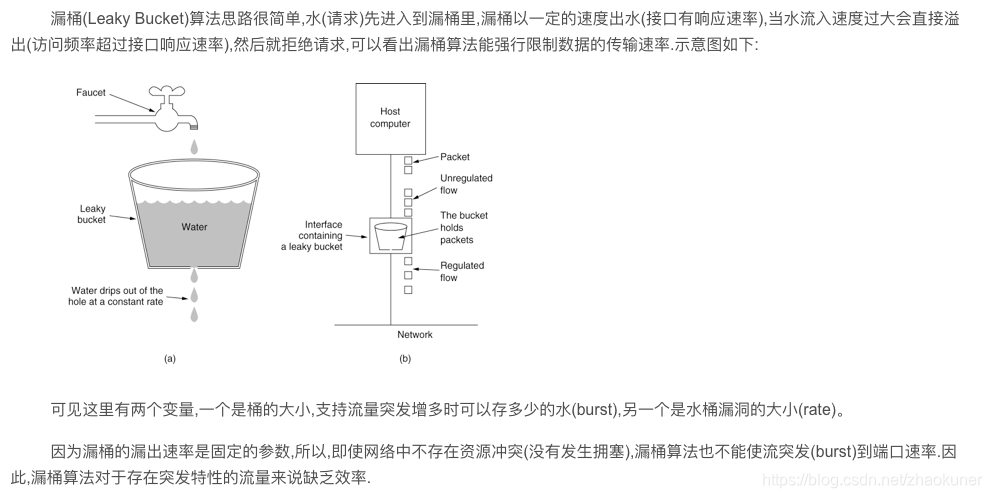
-
令牌桶算法
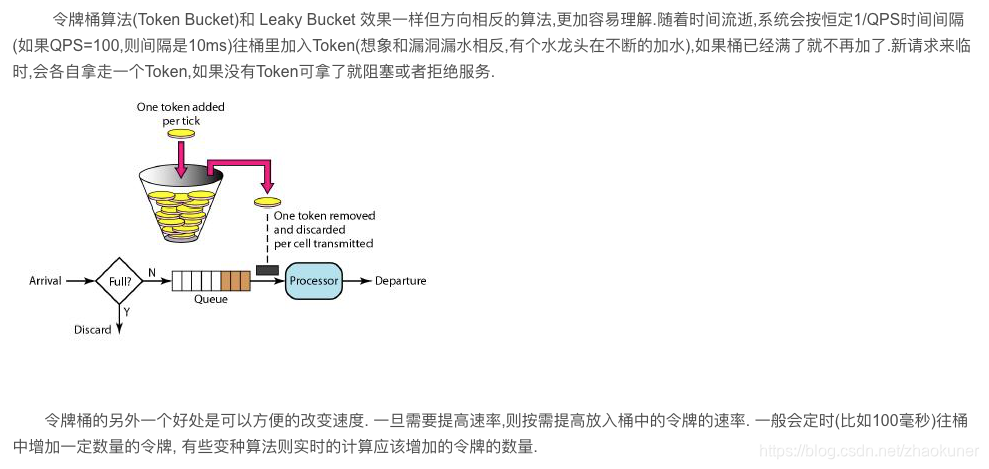
实施方案
RPC限流(dubbo)
dubbo调用模型
连接调用图
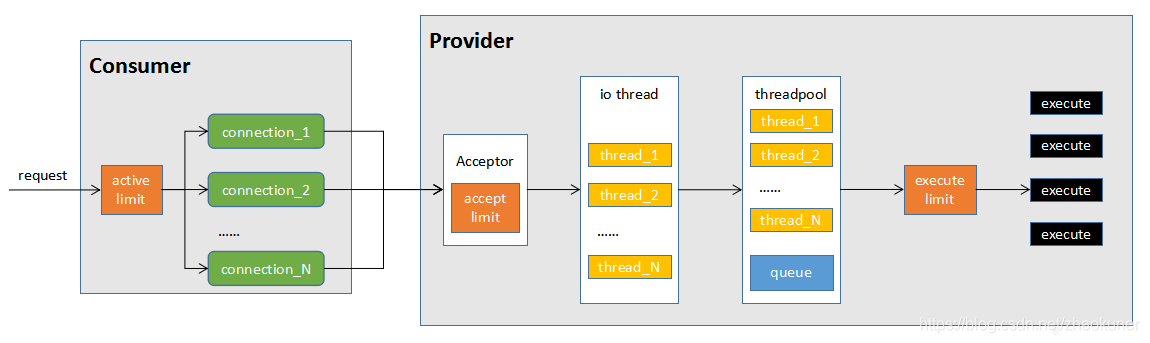
调用时关键参数影响
| 参数名 | 作用范围 | 默认值 | 说明 | 备注 |
|---|---|---|---|---|
| actives | consumer | 0 | 每服务消费者每服务每方法最大并发调用数 | 0表示不限制 |
| connections | consumer | 对每个提供者的最大连接数,rmi、http、hessian等短连接协议表示限制连接数,dubbo等长连接协表示建立的长连接个数 | dubbo时为1,即复用单链接 | |
| accepts | provider | 0 | 服务提供方最大可接受连接数 | 0表示不限制 |
| iothreads | provider | cpu个数+1 | io线程池大小(固定大小) | |
| threads | provider | 200 | 业务线程池大小(固定大小) | |
| executes | provider | 0 | 服务提供者每服务每方法最大可并行执行请求数 | 0表示不限制 |
| tps | provider | 指定时间内(默认60s)最大的可执行次数,注意与executes的区别 | 默认不开启 | |
| queues | provider | 0 | 线程池队列大小,当线程池满时,排队等待执行的队列大小,建议不要设置,当线程程池时应立即失败,重试其它服务提供机器,而不是排队,除非有特殊需求。 |
分析
-
当consumer发起一个请求时,首先经过active limit(参数actives)进行方法级别的限制,其实现方式为CHM中存放计数器(AtomicInteger),请求时加1,请求完成(包括常)减1,如果超过actives则等待有其他请求完成后重试或者超时后失败;
-
从多个连接(connections)中选择一个连接发送数据,对于默认的netty实现来说,由于可以复用连接,默认一个连接就可以。不过如果你在压测,且只有一个consumer,一个provider,此时适当的加大connections确实能够增强网络传输能力。但线上业务由于有多个consumer多个provider,因此不建议增加connections参数;
-
连接到达provider时(如dubbo的初次连接),首先会判断总连接数是否超限(acceps),超过限制连接将被拒绝;
-
连接成功后,具体的请求交给io thread处理。io threads虽然是处理数据的读写,但io部分为异步,更多的消耗的是cpu,因此iothreads默认cpu个数+1是比较合理的设置,不建议调整此参数;
-
数据读取并反序列化以后,交给业务线程池处理,默认情况下线程池为fixed,且排队队列为0(queues),这种情况下,最大并发等于业务线程池大小(threads),如果希望有请求的堆积能力,可以调整queues参数。如果希望快速失败由其他节点处理(官方推荐方式),则不修改queues,只调整threads;
-
execute limit(参数executes)是方法级别的并发限制,原理与actives类似,只是少了等待的过程,即受限后立即失败;
-
tps,控制指定时间内(默认60s)的请求数。注意目前dubbo默认没有支持该参数
从上面的分析,可以看出如果 (consumer数 * actives > provider数 * threads) 且 (queues=0),则会存在部分请求无法申请到资源,重试也有很大几率失败。
当需要对一个接口的不同方法进行不同的并发控制时使用executes,否则调整threads就可以。
内容引用自 dubbo参数调优说明
dubbo filter
dubbo提供了多个和请求相关的filter 我们可以看到:ActiveLimitFilter ExecuteLimitFilter TPSLimiterFilter
-
ActiveLimitFilter
@Activate(group = Constants.CONSUMER, value = Constants.ACTIVES_KEY)
作用于客户端,控制客户端同样的方法可同时运行的次数【即该方法的并发度】
```
dubbo:reference
配置类:org.apache.dubbo.config.ReferenceConfig
actives:(int default 0) 每服务消费者每服务每方法最大并发调用数 2.0.5以上版本
```
```
dubbo:consumer
配置类: org.apache.dubbo.config.ConsumerConfig
同时为 dubbo:reference 缺省值设置
default.actives:(int default 0) 每服务消费者每服务每方法最大并发调用数 2.0.5以上版本
```
```
dubbo:provider
配置类: org.apache.dubbo.config.ProviderConfig
同时为 dubbo:service 和 dubbo:protocol 缺省值设置
default.actives:(int default 0) 每服务消费者每服务每方法最大并发调用数 2.0.5以上版本
```
actives:消费者端的最大并发调用限制,即当 Consumer 对一个服务的并发调用到上限后,新调用会阻塞直到超时,在方法上配置 dubbo:method 则针对该方法进行并发限制,在接口上配置 dubbo:service,则针对该服务进行并发限制
建议在 Provider 端配置的 Consumer 端属性
当超过了指定的active值之后该请求将等待前面的请求完成
何时结束呢?依赖于该方法的timeout 如果没有设置timeout的话 可能就是多个请求一直被阻塞然后等待随机唤醒吧
搭配timeout一起使用
-
ExecuteLimitFilter
@Activate(group = Constants.PROVIDER, value = Constants.EXECUTES_KEY)
服务端限制
```
dubbo:service
配置类:org.apache.dubbo.config.ServiceConfig
executes:(int default 0) 服务提供者每服务每方法最大可并行执行请求数 2.0.5以上版
```
```
dubbo:provider
配置类: org.apache.dubbo.config.ProviderConfig
同时为 dubbo:service 和 dubbo:protocol 缺省值设置
default.actives:(int default 0) 服务提供者每服务每方法最大可并行执行请求数 2.0.5以上版
```
一旦超出指定的数目直接报错 其实是指在服务端的并行度【需要注意这些都是指的是在单台服务上而不是整个服务集群】
-
TpsLimitFilter
@Activate(group = Constants.PROVIDER, value = Constants.TPS_LIMIT_RATE_KEY)
同样作用在服务端 目的在于控制一段时间类中的请求数。dubbo没有默认支持。
```
使用TpsLimitFilter
Dubbo框架并没有默认通过配置文件启动这个Filter,
所以我们需要在classpath的META-INF/dubbo/目录下增加com.alibaba.dubbo.rpc.Filter文件
tps=com.alibaba.dubbo.rpc.filter.TpsLimitFilter
就算加上了这个配置,其实也还是生效不了,我们的provider url需要有tps=xxx参数
相关操作比较繁琐,dubbo没有提供默认实现自有其不推荐使用的理由
```
dubbo Sentinel
Sentinel 限流、熔断、降级
Sentinel 开源地址:https://github.com/alibaba/Sentinel
Sentinel以流量为切入点,从流量控制、熔断降级、系统负载保护等多个维度保护服务的稳定性
Spring Cloud Alibaba
Sentinel 为 Dubbo 服务保驾护航
Sentinel
dubbo Hystrix
Hystrix 主要用于熔断降级
讨论
- dubbo 全局限流实现方案及是否有必要?
API限流(http)
Nginx
对于Nginx接入层限流可以使用Nginx自带了两个模块:
连接数限流模块ngx_http_limit_conn_module和漏桶算法实现的请求限流模块ngx_http_limit_req_module。
-
ngx_http_limit_conn_module
我们经常会遇到这种情况,服务器流量异常,负载过大等等。对于大流量恶意的攻击访问,会带来带宽的浪费,服务器压力,影响业务,往往考虑对同一个ip的连接数,并发数进行限制。ngx_http_limit_conn_module 模块来实现该需求。该模块可以根据定义的键来限制每个键值的连接数,如同一个IP来源的连接数。并不是所有的连接都会被该模块计数,只有那些正在被处理的请求(这些请求的头信息已被完全读入)所在的连接才会被计数。
我们可以在nginx_conf的http{}中加上如下配置实现限制:#限制每个用户的并发连接数,取名one limit_conn_zone $binary_remote_addr zone=one:10m; 配置记录被限流后的日志级别,默认error级别 limit_conn_log_level error; #配置被限流后返回的状态码,默认返回503 limit_conn_status 503;然后在server{}里加上如下代码:
#限制用户并发连接数为1 limit_conn one 1;然后我们是使用ab测试来模拟并发请求:
ab -n 5 -c 5 http://10.23.22.239/index.html
得到下面的结果,很明显并发被限制住了,超过阈值的都显示503另外刚才是配置针对单个IP的并发限制,还是可以针对域名进行并发限制,配置和客户端IP类似。
#http{}段配置 limit_conn_zone $ server_name zone=perserver:10m; #server{}段配置 limit_conn perserver 1; -
ngx_http_limit_req_module
上面我们使用到了ngx_http_limit_conn_module 模块,来限制连接数。那么请求数的限制该怎么做呢?这就需要通过ngx_http_limit_req_module 模块来实现,该模块可以通过定义的键值来限制请求处理的频率。特别的,可以限制来自单个IP地址的请求处理频率。 限制的方法是使用了漏斗算法,每秒固定处理请求数,推迟过多请求。如果请求的频率超过了限制域配置的值,请求处理会被延迟或被丢弃,所以所有的请求都是以定义的频率被处理的。
在http{}中配置#区域名称为one,大小为10m,平均处理的请求频率不能超过每秒一次。 limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;在server{}中配置
#设置每个IP桶的数量为5 limit_req zone=one burst=5;上面设置定义了每个IP的请求处理只能限制在每秒1个。并且服务端可以为每个IP缓存5个请求,如果操作了5个请求,请求就会被丢弃。
使用ab测试模拟客户端连续访问10次:ab -n 10 -c 10 http://10.23.22.239/index.html
设置了桶的个数为5个。一共10个请求,第一个请求马上被处理。第2-6个被存放在桶中。由于桶满了,没有设置nodelay因此,余下的4个请求被丢弃。 -
openresty(nginx+lua)
OpenResty实现限流的几种方式
spring cloud的zuul
Spring Cloud:服务网关 Zuul
- Zuul 是开源的微服务网关,可与 Eureka、Ribbon、Hystrix 等组件配合使用,Zuul 它的核心是一系列过滤器,这些过滤器可完成下面功能:
- 身份认证与安全:识别每个资源的验证要求,并拒绝那些要求不符合的请求
- 审核与监控:在边缘位置追踪有意义的数据和统计结果,从而带来精确的生产视图
- 动态路由:动态的将请求路由到不同的后端集群
- 压力测试:逐渐增加指向集群的流量,以了解性能
- 负载分配:为每一种负载类型分配对应容量,并弃用超出限定值的请求
- 静态响应处理:在边缘位置直接建立部分响应,从而避免转发到内部集群
- 多区域弹性:跨越 AWS Region 进行请求路由,实现 ELB 使用多样化,让系统边缘更贴近使用者
- Spring Cloud 对 Zuul 进行了整合和增强,Zuul 默认使用的 HTTP 客户端是 Apache Http Client,也可使用 RestClient 或 okHttpClient
spring cloud Hystrix
Hystrix 主要用于熔断降级
- Hystrix的设计原则
- 防止单个服务的故障耗尽整个服务的Servlet容器(如Tomcat)的线程池资源。
- 快速失败机制,如果某个服务出现了故障,则调用该服务的请求快速失败,而不是线程等待。
- 提供回退方案,在请求发生故障时,提供设定好的回退方案。
- 使用熔断器机制,防止故障扩散到其他的服务。
- 提供熔断器的监控组件Hystrix Dashboard,可以实时监控熔断器的状态。
- Hystrix的工作机制
- 当服务的某个API接口的失败次数在一定时间内小于设定的阈值时,熔断器处于关闭状态,该API接口正常提供服务。
- 当该API接口处理请求的失败次数大于设定的阈值时,Hystrix判定该API接口出现了故障,打开熔断器,这时该API接口会执行快速失败的逻辑,不执行业务逻辑,请求的线程不会处于阻塞状态。
- 处于打开状态的熔断器在一定时间后会处于半打开状态,并将一定数量的请求执行正常逻辑,剩余的请求会执行快速失败。
- 若执行正常逻辑的请求失败了,则熔断器继续打开,若成功了,则熔断器关闭。这样熔断器就具有了自我修复的功能。
内容引用 熔断器Hystrix
智能推荐
oracle 12c 集群安装后的检查_12c查看crs状态-程序员宅基地
文章浏览阅读1.6k次。安装配置gi、安装数据库软件、dbca建库见下:http://blog.csdn.net/kadwf123/article/details/784299611、检查集群节点及状态:[root@rac2 ~]# olsnodes -srac1 Activerac2 Activerac3 Activerac4 Active[root@rac2 ~]_12c查看crs状态
解决jupyter notebook无法找到虚拟环境的问题_jupyter没有pytorch环境-程序员宅基地
文章浏览阅读1.3w次,点赞45次,收藏99次。我个人用的是anaconda3的一个python集成环境,自带jupyter notebook,但在我打开jupyter notebook界面后,却找不到对应的虚拟环境,原来是jupyter notebook只是通用于下载anaconda时自带的环境,其他环境要想使用必须手动下载一些库:1.首先进入到自己创建的虚拟环境(pytorch是虚拟环境的名字)activate pytorch2.在该环境下下载这个库conda install ipykernelconda install nb__jupyter没有pytorch环境
国内安装scoop的保姆教程_scoop-cn-程序员宅基地
文章浏览阅读5.2k次,点赞19次,收藏28次。选择scoop纯属意外,也是无奈,因为电脑用户被锁了管理员权限,所有exe安装程序都无法安装,只可以用绿色软件,最后被我发现scoop,省去了到处下载XXX绿色版的烦恼,当然scoop里需要管理员权限的软件也跟我无缘了(譬如everything)。推荐添加dorado这个bucket镜像,里面很多中文软件,但是部分国外的软件下载地址在github,可能无法下载。以上两个是官方bucket的国内镜像,所有软件建议优先从这里下载。上面可以看到很多bucket以及软件数。如果官网登陆不了可以试一下以下方式。_scoop-cn
Element ui colorpicker在Vue中的使用_vue el-color-picker-程序员宅基地
文章浏览阅读4.5k次,点赞2次,收藏3次。首先要有一个color-picker组件 <el-color-picker v-model="headcolor"></el-color-picker>在data里面data() { return {headcolor: ’ #278add ’ //这里可以选择一个默认的颜色} }然后在你想要改变颜色的地方用v-bind绑定就好了,例如:这里的:sty..._vue el-color-picker
迅为iTOP-4412精英版之烧写内核移植后的镜像_exynos 4412 刷机-程序员宅基地
文章浏览阅读640次。基于芯片日益增长的问题,所以内核开发者们引入了新的方法,就是在内核中只保留函数,而数据则不包含,由用户(应用程序员)自己把数据按照规定的格式编写,并放在约定的地方,为了不占用过多的内存,还要求数据以根精简的方式编写。boot启动时,传参给内核,告诉内核设备树文件和kernel的位置,内核启动时根据地址去找到设备树文件,再利用专用的编译器去反编译dtb文件,将dtb还原成数据结构,以供驱动的函数去调用。firmware是三星的一个固件的设备信息,因为找不到固件,所以内核启动不成功。_exynos 4412 刷机
Linux系统配置jdk_linux配置jdk-程序员宅基地
文章浏览阅读2w次,点赞24次,收藏42次。Linux系统配置jdkLinux学习教程,Linux入门教程(超详细)_linux配置jdk
随便推点
matlab(4):特殊符号的输入_matlab微米怎么输入-程序员宅基地
文章浏览阅读3.3k次,点赞5次,收藏19次。xlabel('\delta');ylabel('AUC');具体符号的对照表参照下图:_matlab微米怎么输入
C语言程序设计-文件(打开与关闭、顺序、二进制读写)-程序员宅基地
文章浏览阅读119次。顺序读写指的是按照文件中数据的顺序进行读取或写入。对于文本文件,可以使用fgets、fputs、fscanf、fprintf等函数进行顺序读写。在C语言中,对文件的操作通常涉及文件的打开、读写以及关闭。文件的打开使用fopen函数,而关闭则使用fclose函数。在C语言中,可以使用fread和fwrite函数进行二进制读写。 Biaoge 于2024-03-09 23:51发布 阅读量:7 ️文章类型:【 C语言程序设计 】在C语言中,用于打开文件的函数是____,用于关闭文件的函数是____。
Touchdesigner自学笔记之三_touchdesigner怎么让一个模型跟着鼠标移动-程序员宅基地
文章浏览阅读3.4k次,点赞2次,收藏13次。跟随鼠标移动的粒子以grid(SOP)为partical(SOP)的资源模板,调整后连接【Geo组合+point spirit(MAT)】,在连接【feedback组合】适当调整。影响粒子动态的节点【metaball(SOP)+force(SOP)】添加mouse in(CHOP)鼠标位置到metaball的坐标,实现鼠标影响。..._touchdesigner怎么让一个模型跟着鼠标移动
【附源码】基于java的校园停车场管理系统的设计与实现61m0e9计算机毕设SSM_基于java技术的停车场管理系统实现与设计-程序员宅基地
文章浏览阅读178次。项目运行环境配置:Jdk1.8 + Tomcat7.0 + Mysql + HBuilderX(Webstorm也行)+ Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:Springboot + mybatis + Maven +mysql5.7或8.0+html+css+js等等组成,B/S模式 + Maven管理等等。环境需要1.运行环境:最好是java jdk 1.8,我们在这个平台上运行的。其他版本理论上也可以。_基于java技术的停车场管理系统实现与设计
Android系统播放器MediaPlayer源码分析_android多媒体播放源码分析 时序图-程序员宅基地
文章浏览阅读3.5k次。前言对于MediaPlayer播放器的源码分析内容相对来说比较多,会从Java-&amp;gt;Jni-&amp;gt;C/C++慢慢分析,后面会慢慢更新。另外,博客只作为自己学习记录的一种方式,对于其他的不过多的评论。MediaPlayerDemopublic class MainActivity extends AppCompatActivity implements SurfaceHolder.Cal..._android多媒体播放源码分析 时序图
java 数据结构与算法 ——快速排序法-程序员宅基地
文章浏览阅读2.4k次,点赞41次,收藏13次。java 数据结构与算法 ——快速排序法_快速排序法