目标检测网络(RCNN系列,SSD,Yolo系列)_目标识别网络-程序员宅基地
技术标签: 计算机视觉
Table of Contents
SSD: Single Shot MultiBox Detector
深度学习相关的目标检测方法也可以大致分为两派
- 基于区域提名的,如R-CNN, SPP-net, Fast R-CNN, Faster R-CNN, R-FCN;
- 端到端(End-to-End)无需区域提名的,如YOLO, SSD。
发展历程
https://blog.csdn.net/yangshengjie_/article/details/81533580
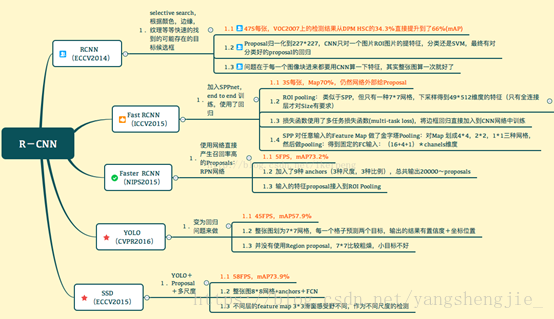

基于区域提名的R-CNN家族对比总括
R-CNN解决的是,“为什么不用CNN做classification呢?”
Fast R-CNN解决的是,“为什么不一起输出bounding box和label呢?”
Faster R-CNN解决的是,“为什么还要用selective search呢?”
RCNN
1. 在图像中确定约 1000-2000 个候选框 (使用选择性搜索)
2. 每个候选框内图像块缩放至相同大小,并输入到 CNN 内进行特征提取
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
Fast-RCNN
1. 在图像中确定约 1000-2000 个候选框 (使用选择性搜索)
2. 对整张图片输进 CNN,得到 feature map
3. 找到每个候选框在 feature map 上的映射 patch,将此 patch 作为每个候选框的卷积特征输入到 SPP layer 和之后的层
4. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
5. 对于属于某一特征的候选框,用回归器进一步调整其位置
Faster-RCNN
1. 对整张图片输进 CNN,得到 feature map
2. 卷积特征输入到 RPN,得到候选框的特征信息
3. 对候选框中提取出的特征,使用分类器判别是否属于一个特定类
4. 对于属于某一特征的候选框,用回归器进一步调整其位置
R-CNN(2014)
博客:https://blog.csdn.net/yangshengjie_/article/details/81533580
意义:
CNN除了在object classification领域的有一大的应用,证明了CNN的广泛应用性,导致深度学习在成为非常热门的一个研究方向。R-CNN主要是应用在object detection领域,传统的识别是一张图片中有一个物体,而R-CNN是用来识别一个图片中的若干张物体的方法。
算法结构如下:
创新点:
借助CNN良好的特征提取和分类性能,通过Region Proposal方法实现目标检测问题的转化。
实现过程:
目标检测系统由三个模块组成。
(1)第一个模块:区域提取和区域大小归一化
区域提取:通过Selective Search算法对每张图片提取了约2000个自底向上的候选区域。
区域大小归一化:将产生的所有的boxes resize成固定的size(原文采用227×227,作为CNN网络的输入,用来选取特征);
(2)第二个模块:特征提取
利用大型卷积神经网络,负责从每个区域提取固定长度的特征向量。
(3)第三个模块:分类与回归
利用SVM分类器判断whether this is an object, and if so what object,在boxes中找到object之后,通过对所有的region proposals run a simple linear regression to generate tighter bounding box coordinates.
存在的问题:
(1)训练需要多阶段: 先用ConvNet进行微调,再用SVM进行分类,最后通过regression对 bounding box进行微调。
(2)耗时长:每张图片需要运行2k次CNN去寻找特征,selective search (ss)提取候选框耗时较长。
(3)特征提取冗余:每一个候选框依次进入CNN网络,存在冗余提取特征的问题。
(4)时间空间耗费很大:区域提名、特征提取、分类、回归都是断开的训练的过程,中间数据还需要单独保存;卷积出来的特征需要先存在硬盘上,这些特征需要几百G的存储空间;另外,时间消耗很大,GPU上处理一张图片需要13秒,CPU上则需要53秒。
Selective search算法(以下简称ss算法):
首先通过简单的聚类生成区域集合;然后根据定义的相似度不断合并相邻区域构成新的候选框。本质上是一种基于在原始聚类后的区域集合上,依照邻域的相似度,从小到大的进行滑动窗口。具体算法实现如下:
算法实现步骤:
step1:计算区域集R里每个相邻区域的相似度S={s1,s2,…}
step2:找出相似度最高的两个区域,将其合并为新集,添加进R
step3:从S中移除所有与step2中有关的子集
step4:计算新集与所有子集的相似度
step5:跳至step2,直至S为空
- 相似度度量标准:
颜色相似度、纹理相似度、尺寸相似度以及交叠相似度。selective search具体计算方式参考:https://blog.csdn.net/guoyunfei20/article/details/78723646
SPP-Net
博客:https://blog.csdn.net/sum_nap/article/details/80388110
论文:https://arxiv.org/abs/1406.4729
创新点:
在R-CNN的基础上做出改进,将Region Proposal的位置信息放在卷积层之后,这样使得图像可以在一次计算的基础上整体提取特征,减少RCNN带来的最大问题——冗余计算和冗余存储。
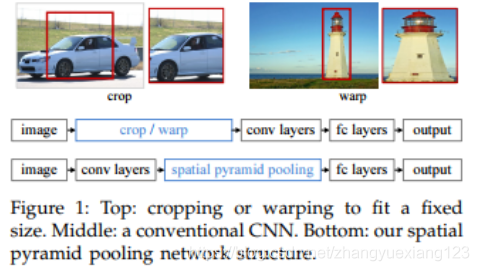
SPP允许输入图像大小任意,网络结构如下:

为了使输入图像任意大小,网络修改如下:

Fast R-CNN(2015)
论文:https://arxiv.org/abs/1504.08083
R-CNN按照上面的三个标准步骤依次进行,selective search for region proposals,cnn for features,svm for classification。
Fast-R-CNN将后两个步骤合并,cnn对region proposal生成feature map,接着通过ROI(region of interest)层将feature map转换成fc layer,然后对fc layer进行softmax classification以及bounding box regression的多任务训练。
创新点:
(1)提出ROI pooling池化层结构(ROI pooling解析见下面),解决了候选框子图必须将图像裁剪缩放到相同尺寸大小的问题。由于CNN网络的输入图像尺寸必须是固定的某一个大小(否则全连接时没法计算),故R-CNN中对大小形状不同的候选框,进行了裁剪和缩放,使得他们达到相同的尺寸。这个操作既浪费时间,又容易导致图像信息丢失和形变。fast R-CNN在全连接层之前插入了ROI pooling层,从而不需要对图像进行裁剪,很好的解决了这个问题。
如下图,剪切会导致信息丢失,缩放会导致图像形变。
ROI pooling的思路是,如果最终我们要生成MxN的图片,那么先将特征图水平和竖直分为M和N份,然后每一份取最大值,输出MxN的特征图。这样就实现了固定尺寸的图片输出了。即针对每个推荐区域,ROI池化层从每个特征映射中提取固定大小的特征向量。ROI pooling层位于卷积后,全连接前。
(2)提出多任务损失函数思想,将分类损失和边框定位回归损失结合在一起统一训练,最终输出对应分类和边框坐标。
Fast R-CNN的结构如如下:
存在问题:
提取候选框依然十分耗时,这个过程十分耗时,制约fast-RCNN的速度瓶颈。
ROI pooling具体操作:
博客:https://blog.csdn.net/auto1993/article/details/78514071
(1)根据输入image,将ROI映射到feature map对应位置;
(2)将映射后的区域划分为相同大小的sections(sections数量与输出的维度相同);
(3)对每个sections进行max pooling操作;
这样我们就可以从不同大小的方框得到固定大小的相应 的feature maps。值得一提的是,输出的feature maps的大小不取决于ROI和卷积feature maps大小。ROI pooling 最大的好处就在于极大地提高了处理速度。
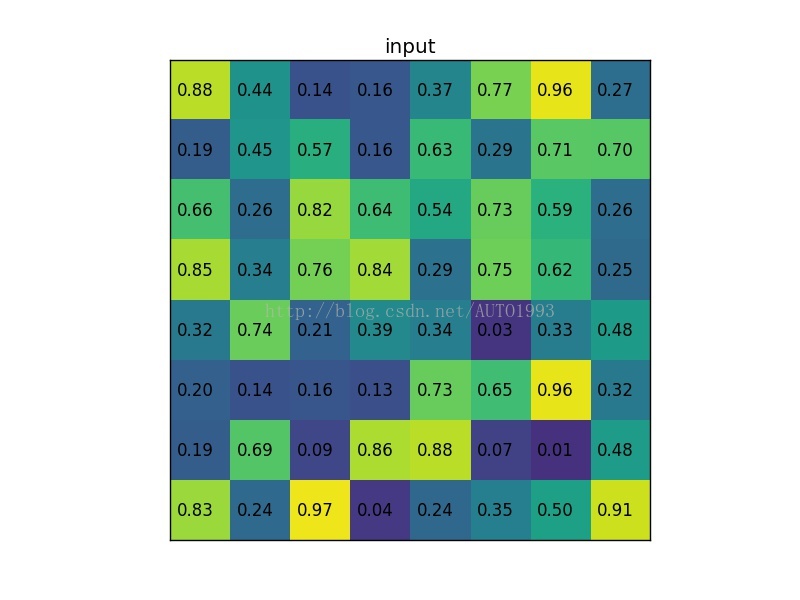
ROI pooling example
考虑一个8*8大小的feature map,一个ROI,以及输出大小为2*2.
(1)输入的固定大小的feature map
(2)region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)。
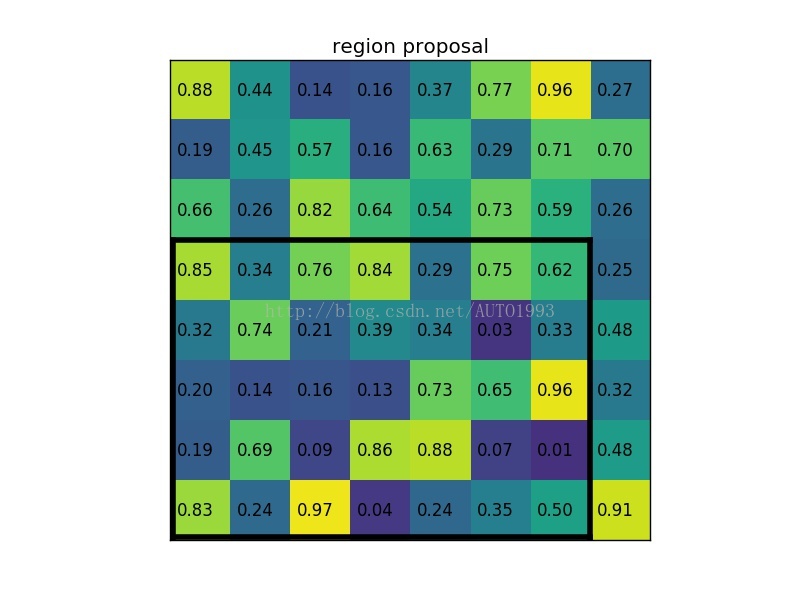
(3)将其划分为(2*2)个sections(因为输出大小为2*2),我们可以得到:
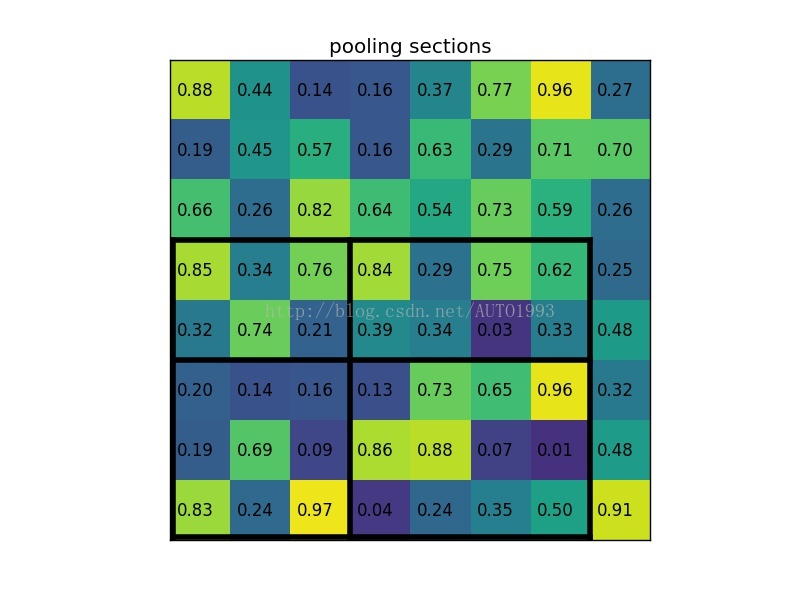
(4)对每个section做max pooling,可以得到:
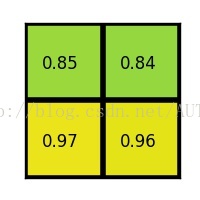
ROI pooling总结:
(1)用于目标检测任务;(2)允许我们对CNN中的feature map进行reuse;(3)可以显著加速training和testing速度;(4)允许end-to-end的形式训练目标检测系统。
Faster-RCNN
Faster-R-CNN将三个步骤合并,region proposal、classification、regression三者共享一个based cnn network。
R-CNN和fast R-CNN均存在一个问题,那就是由选择性搜索来生成候选框,这个算法很慢。faster R-CNN 针对这个问题,提出了RPN网络来进行候选框的获取,从而摆脱了选择性搜索算法,也只需要一次卷积层操作,从而大大提高了识别速度。
博客:https://blog.csdn.net/u013510838/article/details/79947553
创新点:
候选框提取不一定非要在原图上做,可以考虑在特征图上做。继而提出了RPN(RegionProposal Network),使得其可以抛弃传统的Region proposal的方法,大幅加快训练速度。
Faster R-CNN模型由两个模块组成:
(1)第一个模块:负责提出区域的深度卷积网络。
(2)第二个模块:使用上述提取区域的Fast R-CNN探测器。
候选区域网络(Region Proposal Network)以图像为输入,生成矩形目标候选的输出。每个矩形都有一个objectness score。
ROI分为四个步骤:
(1)卷积层。原始图片先经过conv-relu-pooling的多层卷积神经网络,提取出特征图。供后续的RPN网络和全连接层使用。faster R-CNN不像R-CNN需要对每个子图进行卷积层特征提取,它只需要对全图进行一次提取就可以了,从而大大减小了计算时间。
(2)RPN层,region proposal networks。RPN层用于生成候选框,并利用softmax判断候选框是前景还是背景,从中选取前景候选框(因为物体一般在前景中),并利用bounding box regression调整候选框的位置,从而得到特征子图,称为proposals。
(3)ROI层,fast R-CNN中已经讲过了ROI层了,它将大小尺寸不同的proposal池化成相同的大小,然后送入后续的全连接层进行物体分类和位置调整回归.
(4)分类层。利用ROI层输出的特征图proposal,判断proposal的类别,同时再次对bounding box进行regression从而得到精确的形状和位置。
使用VGG-16卷积模型的具体网络结构如下图:
4.1 卷积层
卷积层采用的VGG-16模型,先将PxQ的原始图片,缩放裁剪为MxN的图片,然后经过13个conv-relu层,其中会穿插4个max-pooling层。所有的卷积的kernel都是3x3的,padding为1,stride为1。pooling层kernel为2x2, padding为0,stride为2。
MxN的图片,经过卷积层后,变为了(M/16) x (N/16)的feature map了。
4.2 RPN层
faster R-CNN抛弃了R-CNN中的选择性搜索(selective search)方法,使用RPN层来生成候选框,能极大的提升候选框的生成速度。RPN层先经过3x3的卷积运算,然后分为两路。一路用来判断候选框是前景还是背景,它先reshape成一维向量,然后softmax来判断是前景还是背景,然后reshape恢复为二维feature map。另一路用来确定候选框的位置,通过bounding box regression实现,后面再详细讲。两路计算结束后,挑选出前景候选框(因为物体在前景中),并利用计算得到的候选框位置,得到我们感兴趣的特征子图proposal。
4.2.1 候选框的生成 anchors
卷积层提取原始图像信息,得到了256个feature map,经过RPN层的3x3卷积后,仍然为256个feature map。但是每个点融合了周围3x3的空间信息。对每个feature map上的一个点,生成k个anchor(k默认为9)。anchor分为前景和背景两类(我们先不去管它具体是飞机还是汽车,只用区分它是前景还是背景即可)。anchor有[x,y,w,h]四个坐标偏移量,x,y表示中心点坐标,w和h表示宽度和高度。这样,对于feature map上的每个点,就得到了k个大小形状各不相同的选区region。
4.2.2 softmax判断选区是前景还是背景
对于生成的anchors,我们首先要判断它是前景还是背景。由于感兴趣的物体位于前景中,故经过这一步之后,我们就可以舍弃背景anchors了。大部分的anchors都是属于背景,故这一步可以筛选掉很多无用的anchor,从而减少全连接层的计算量。
对于经过了3x3的卷积后得到的256个feature map,先经过1x1的卷积,变换为18个feature map。然后reshape为一维向量,经过softmax判断是前景还是背景。此处reshape的唯一作用就是让数据可以进行softmax计算。然后输出识别得到的前景anchors。
4.2.3 确定候选框位置
另一路用来确定候选框的位置,也就是anchors的[x,y,w,h]坐标值。如下图所示,红色代表我们当前的选区,绿色代表真实的选区。虽然我们当前的选取能够大概框选出飞机,但离绿色的真实位置和形状还是有很大差别,故需要对生成的anchors进行调整。这个过程我们称为bounding box regression。
假设红色框的坐标为[x,y,w,h], 绿色框即目标框的坐标为[Gx, Gy,Gw,Gh], 我们要建立一个变换,使得[x,y,w,h]能够变为[Gx, Gy,Gw,Gh]。最简单的思路是,先做平移,使得中心点接近,然后进行缩放,使得w和h接近。如下:
我们要学习的就是dx dy dw dh这四个变换。由于是线性变换,我们可以用线性回归来建模。设定loss和优化方法后,就可以利用深度学习进行训练,并得到模型了。对于空间位置loss,我们一般采用均方差算法,而不是交叉熵(交叉熵使用在分类预测中)。优化方法可以采用自适应梯度下降算法Adam。
4.2.4 输出特征子图proposal
得到了前景anchors,并确定了他们的位置和形状后,我们就可以输出前景的特征子图proposal了。步骤如下:
(1)得到前景anchors和他们的[x y w h]坐标。
(2)按照anchors为前景的不同概率,从大到小排序,选取前pre_nms_topN个anchors,比如前6000个。
(3)剔除非常小的anchors。
(4)通过NMS非极大值抑制,从anchors中找出置信度较高的。这个主要是为了解决选取交叠问题。首先计算每一个选区面积,然后根据他们在softmax中的score(也就是是否为前景的概率)进行排序,将score最大的选区放入队列中。接下来,计算其余选区与当前最大score选区的IOU(IOU为两box交集面积除以两box并集面积,它衡量了两个box之间重叠程度)。去除IOU大于设定阈值的选区。这样就解决了选区重叠问题。
(5)选取前post_nms_topN个结果作为最终选区proposal进行输出,比如300个。
经过这一步之后,物体定位应该就基本结束了,剩下的就是物体识别了
4.3 ROI Pooling层
和fast R-CNN中类似,这一层主要解决之前得到的proposal大小形状各不相同,导致没法做全连接。全连接计算只能对确定的shape进行运算,故必须使proposal大小形状变为相同。通过裁剪和缩放的手段,可以解决这个问题,但会带来信息丢失和图片形变问题。我们使用ROI pooling可以有效的解决这个问题。
ROI pooling中,如果目标输出为MxN,则在水平和竖直方向上,将输入proposal划分为MxN份,每一份取最大值,从而得到MxN的输出特征图。
4.4 分类层
ROI Pooling层后的特征图,通过全连接层与softmax,就可以计算属于哪个具体类别,比如人,狗,飞机,并可以得到cls_prob概率向量。同时再次利用bounding box regression精细调整proposal位置,得到bbox_pred,用于回归更加精确的目标检测框。
这样就完成了faster R-CNN的整个过程了。算法还是相当复杂的,对于每个细节需要反复理解。faster R-CNN使用resNet101模型作为卷积层,在voc2012数据集上可以达到83.8%的准确率,超过yolo ssd和yoloV2。其最大的问题是速度偏慢,每秒只能处理5帧,达不到实时性要求。
Yolo:you only look once
论文:https://arxiv.org/pdf/1506.02640.pdf
优点:
针对于two-stage目标检测算法普遍存在的运算速度慢的缺点,yolo创造性的提出了one-stage。也就是将物体分类和物体定位在一个步骤中完成。yolo直接在输出层回归bounding box的位置和bounding box所属类别,从而实现one-stage。通过这种方式,yolo可实现45帧每秒的运算速度,完全能满足实时性要求(达到24帧每秒,人眼就认为是连续的)。
缺点:
速度极大的得到提升,但是检测精度跟faster-RCNN相比,降低了不少。不再显式提取候选框。
步骤:
主要分为三个部分:卷积层,目标检测层,NMS筛选层。
5.1 卷积层
采用Google inceptionV1网络,对应到上图中的第一个阶段,共20层。这一层主要是进行特征提取,从而提高模型泛化能力。但作者对inceptionV1进行了改造,他没有使用inception module结构,而是用一个1x1的卷积,并联一个3x3的卷积来替代。(可以认为只使用了inception module中的一个分支,应该是为了简化网络结构)
5.2 目标检测层
先经过4个卷积层和2个全连接层,最后生成7x7x30的输出。先经过4个卷积层的目的是为了提高模型泛化能力。yolo将一副448x448的原图分割成了7x7个网格,每个网格要预测两个bounding box的坐标(x,y,w,h)和box内包含物体的置信度confidence,以及物体属于20类别中每一类的概率(yolo的训练数据为voc2012,它是一个20分类的数据集)。所以一个网格对应的参数为(4x2+2+20) = 30。如下图:
(1)bounding box坐标: 如上图,7x7网格内的每个grid(红色框),对应两个大小形状不同的bounding box(黄色框)。每个box的位置坐标为(x,y,w,h), x和y表示box中心点坐标,w和h表示box宽度和高度。通过与训练数据集上标定的物体真实坐标(Gx,Gy,Gw,Gh)进行对比训练,可以计算出初始bounding box平移和伸缩得到最终位置的模型。
(2)bounding box置信度confidence:这个置信度只是为了表达box内有无物体的概率,并不表达box内物体是什么。
confidence=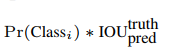
其中前一项表示有无人工标记的物体落入了网格内,如果有则为1,否则为0。第二项代表bounding box和真实标记的box之间的重合度。它等于两个box面积交集,除以面积并集。值越大则box越接近真实位置。
(3)分类信息:yolo的目标训练集为voc2012,它是一个20分类的目标检测数据集。常用目标检测数据集如下表
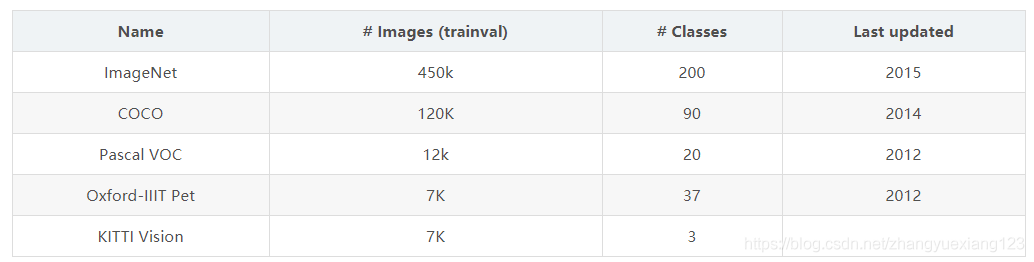
每个网格还需要预测它属于20分类中每一个类别的概率。分类信息是针对每个网格的,而不是bounding box。故只需要20个,而不是40个。而confidence则是针对bounding box的,它只表示box内是否有物体,而不需要预测物体是20分类中的哪一个,故只需要2个参数。虽然分类信息和confidence都是概率,但表达含义完全不同。
5.3 NMS筛选层
筛选层是为了在多个结果中(多个bounding box)筛选出最合适的几个,这个方法和faster R-CNN 中基本相同。都是先过滤掉score低于阈值的box,对剩下的box进行NMS非极大值抑制,去除掉重叠度比较高的box(NMS具体算法可以回顾上面faster R-CNN小节)。这样就得到了最终的最合适的几个box和他们的类别。
5.4 yolo损失函数
yolo的损失函数包含三部分,位置误差,confidence误差,分类误差。具体公式如下:
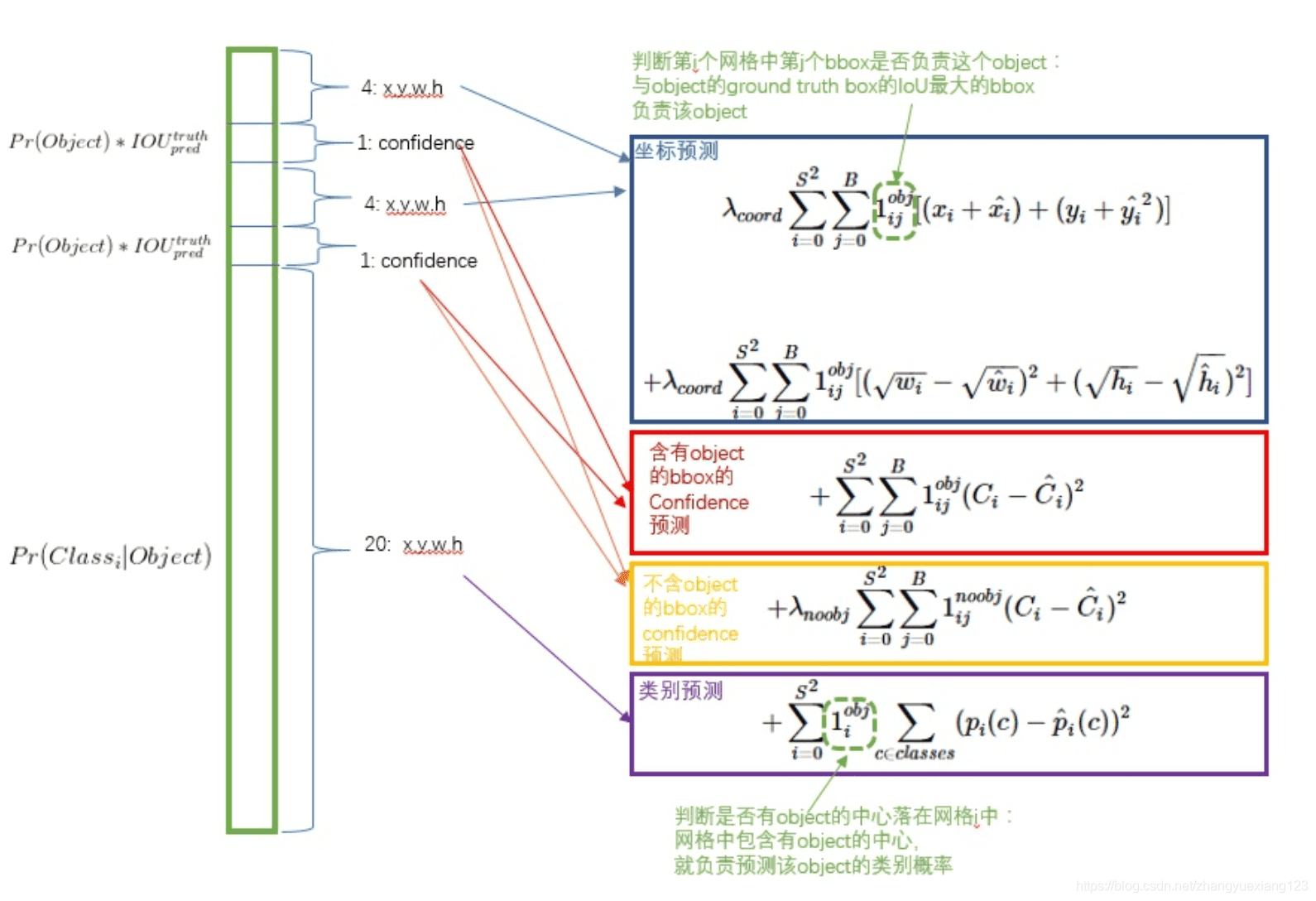
继续解释损失函数:

误差均采用了均方差算法,其实我认为,位置误差应该采用均方差算法,而分类误差应该采用交叉熵。由于物体位置只有4个参数,而类别有20个参数,他们的累加和不同。如果赋予相同的权重,显然不合理。故yolo中位置误差权重为5,类别误差权重为1。由于我们不是特别关心不包含物体的bounding box,故赋予不包含物体的box的置信度confidence误差的权重为0.5,包含物体的权重则为1。
yolo算法开创了one-stage检测的先河,它将物体分类和物体检测网络合二为一,都在全连接层完成。故它大大降低了目标检测的耗时,提高了实时性。
但它的缺点也十分明显:
(1)每个网格只对应两个bounding box,当物体的长宽比不常见(也就是训练数据集覆盖不到时),效果很差。
(2)原始图片只划分为7x7的网格,当两个物体靠的很近时,效果很差
(3)最终每个网格只对应一个类别,容易出现漏检(物体没有被识别到)。
(4)对于图片中比较小的物体,效果很差。这其实是所有目标检测算法的通病,SSD对它有些优化,我们后面再看。
SSD: Single Shot MultiBox Detector
论文链接:https://arxiv.org/abs/1512.02325
Faster R-CNN准确率mAP较高,漏检率recall较低,但速度较慢。而yolo则相反,速度快,但准确率和漏检率不尽人意。SSD综合了他们的优缺点,对输入300x300的图像,在voc2007数据集上test,能够达到58 帧每秒( Titan X 的 GPU ),72.1%的mAP。
SSD网络结构如下图:
步骤:
和yolo一样,也分为三部分:卷积层,目标检测层和NMS筛选层。
SSD网络结构从图中可以看出来分为两部分 基础网络 + 金字塔网络。基础网络是VGG-16的前4层网络。金字塔网络是特征图逐渐变小的简单卷积网络由5部分构成。
(1)多尺寸feature map上进行目标检测
就是特征金字塔检测方式。从不同尺度的特征图下面来预测目标分类与位置。
可以克服yolo对于宽高比不常见的物体,识别准确率较低的问题。
而yolo中,只在最后一个卷积层上做目标位置和类别的训练和预测。这是SSD相对于yolo能提高准确率的一个关键所在。
如上所示,在每个卷积层上都会进行目标检测和分类,最后由NMS进行筛选,输出最终的结果。多尺度feature map上做目标检测,就相当于多了很多宽高比例的bounding box,可以大大提高泛化能力。
(2)多个anchors,每个anchor对应4个位置参数和21个类别参数
和faster R-CNN相似,SSD也提出了anchor的概念。
卷积输出的feature map,每个点对应为原图的一个区域的中心点。以这个点为中心,构造出6个宽高比例不同,大小不同的anchor(SSD中称为default box)。每个anchor对应4个位置参数(x,y,w,h)和21个类别概率(voc训练集为20分类问题,在加上anchor是否为背景,共21分类)。如下图所示
(3)筛选层
和yolo的筛选层基本一致,同样先过滤掉类别概率低于阈值的default box,再采用NMS非极大值抑制,筛掉重叠度较高的。只不过SSD综合了各个不同feature map上的目标检测输出的default box。
SSD基本已经可以满足我们手机端上实时物体检测需求了,TensorFlow在Android上的目标检测官方模型ssd_mobilenet_v1_android_export.pb,就是通过SSD算法实现的。它的基础卷积网络采用的是mobileNet,适合在终端上部署和运行。
YoloV2, Yolo9000
两者联系:
yoloV2只能识别20类物体,为了优化这个问题,提出了yolo9000,可以识别9000类物体。它在yoloV2基础上,进行了imageNet和coco的联合训练。这种方式充分利用imageNet可以识别1000类物体和coco可以进行目标位置检测的优点。当使用imageNet训练时,只更新物体分类相关的参数。而使用coco时,则更新全部所有参数。
相对于Yolo V1改进:
博客:https://blog.csdn.net/sum_nap/article/details/80453396
(1)Batch Normalization:引入了BN(batch normalization)算法,加速训练,同时使MAP增加了2%。
- 关于BN的实现、作用及思想:参考链接:https://www.zhihu.com/question/38102762
- 关于BN算法,这个讲解的挺好:https://www.cnblogs.com/stingsl/p/6428694.html
- 额外链接:白化算法:https://blog.csdn.net/whiteinblue/article/details/36171233
(2)High resolution classifier:采用高分辨率的图片输入对分类网络进行fine-tune(即用448x448的输入分辨率在ImageNet上进行参数微调),从而适用于高分辨率的(fifilters)的输入;
(3)Convolution with anchor boxes:把全连接层取消,使用anchor boxes来预测目标方框。
yolo中以全连接层预测bounding box的坐标,因为是全连接层,所以能够直接预测坐标值(个人理解:全连接层保证每一个输出节点跟任何一个像素点都有关系,类似于感受野)。
faster-RCNN通过卷积核的方式预测相对偏移而不是直接坐标,作者通过发现,预测相对偏执相对于预测直接来说更加容易(make it easier for the network to learn.)。
yolo v2将yolo最后的全连接层去掉,换成类似于faster-RCNN的卷积层,并且使用anchor box的方式对boundin box的相对位置进行预测,作者去掉了网络中一个Pooling层,这让卷积层的输出能有更高的分辨率。收缩网络让其运行在416*416而不是448*448。由于图片中的物体都倾向于出现在图片的中心位置,特别是那种比较大的物体,所以有一个单独位于物体中心的位置用于预测这些物体。
(4)Dimension clusters:通过k-means聚类选择合适的anchor box,更加体现了(faster-RCNN中的)anchor box在选择时的经验性。通过聚类算法,找出最能代表物体shape的不同比例或尺度的anchor box。并且通过实验表明聚类算法是有效果的。
FPN
博客:https://blog.csdn.net/qq_29462849/article/details/80844845
论文概述
作者提出的多尺度的object detection算法:FPN(feature pyramid networks)。原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本文不一样的地方在于预测是在不同特征层独立进行的。
论文详解
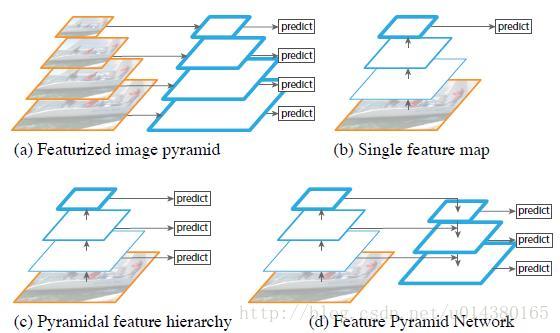
下图FIg1展示了4种利用特征的形式:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
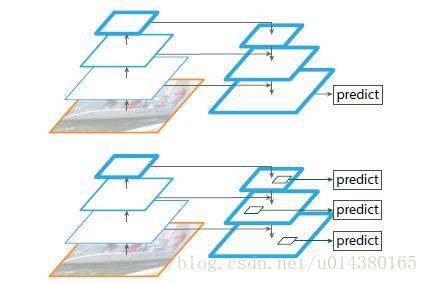
如下图Fig2。上面一个带有skip connection的网络结构在预测的时候是在finest level(自顶向下的最后一层)进行的,简单讲就是经过多次上采样并融合特征到最后一步,拿最后一步生成的特征做预测。而下面一个网络结构和上面的类似,区别在于预测是在每一层中独立进行的。后面有这两种结构的实验结果对比,非常有意思,因为之前只见过使用第一种特征融合的方式。
作者的主网络采用ResNet。
作者的算法大致结构如下Fig3:一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
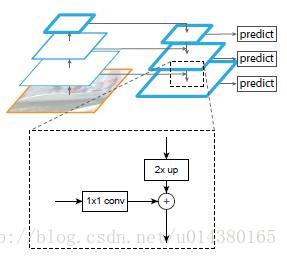
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
贴一个ResNet的结构图:这里作者采用Conv2,CONV3,CONV4和CONV5的输出。因此类似Conv2就可以看做一个stage。
作者一方面将FPN放在RPN网络中用于生成proposal,原来的RPN网络是以主网络的某个卷积层输出的feature map作为输入,简单讲就是只用这一个尺度的feature map。但是现在要将FPN嵌在RPN网络中,生成不同尺度特征并融合作为RPN网络的输入。在每一个scale层,都定义了不同大小的anchor,对于P2,P3,P4,P5,P6这些层,定义anchor的大小为32^2,64^2,128^2,256^2,512^2,另外每个scale层都有3个长宽对比度:1:2,1:1,2:1。所以整个特征金字塔有15种anchor。
正负样本的界定和Faster RCNN差不多:如果某个anchor和一个给定的ground truth有最高的IOU或者和任意一个Ground truth的IOU都大于0.7,则是正样本。如果一个anchor和任意一个ground truth的IOU都小于0.3,则为负样本。
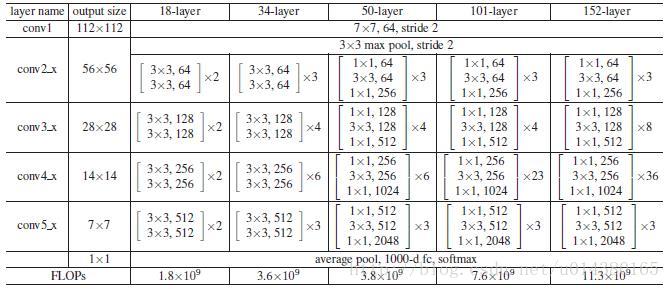
看看加入FPN的RPN网络的有效性,如下表Table1。网络这些结果都是基于ResNet-50。评价标准采用AR,AR表示Average Recall,AR右上角的100表示每张图像有100个anchor,AR的右下角s,m,l表示COCO数据集中object的大小分别是小,中,大。feature列的大括号{}表示每层独立预测。
从(a)(b)(c)的对比可以看出FRN的作用确实很明显。另外(a)和(b)的对比可以看出高层特征并非比低一层的特征有效。
(d)表示只有横向连接,而没有自顶向下的过程,也就是仅仅对自底向上(bottom-up)的每一层结果做一个1*1的横向连接和3*3的卷积得到最终的结果,有点像Fig1的(b)。从feature列可以看出预测还是分层独立的。作者推测(d)的结果并不好的原因在于在自底向上的不同层之间的semantic gaps比较大。
(e)表示有自顶向下的过程,但是没有横向连接,即向下过程没有融合原来的特征。这样效果也不好的原因在于目标的location特征在经过多次降采样和上采样过程后变得更加不准确。
(f)采用finest level层做预测(参考Fig2的上面那个结构),即经过多次特征上采样和融合到最后一步生成的特征用于预测,主要是证明金字塔分层独立预测的表达能力。显然finest level的效果不如FPN好,原因在于PRN网络是一个窗口大小固定的滑动窗口检测器,因此在金字塔的不同层滑动可以增加其对尺度变化的鲁棒性。另外(f)有更多的anchor,说明增加anchor的数量并不能有效提高准确率。
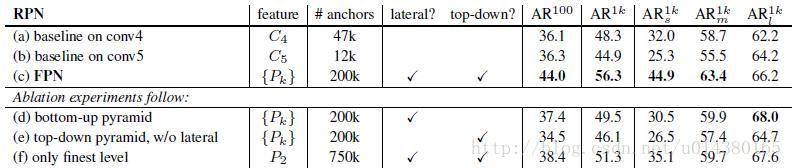
另一方面将FPN用于Fast R-CNN的检测部分。除了(a)以外,分类层和卷积层之前添加了2个1024维的全连接层。细节地方可以等代码出来后再研究。
实验结果如下表Table2,这里是测试Fast R-CNN的检测效果,所以proposal是固定的(采用Table1(c)的做法)。与Table1的比较类似,(a)(b)(c)的对比证明在基于区域的目标卷积问题中,特征金字塔比单尺度特征更有效。(c)(f)的差距很小,作者认为原因是ROI pooling对于region的尺度并不敏感。因此并不能一概认为(f)这种特征融合的方式不好,博主个人认为要针对具体问题来看待,像上面在RPN网络中,可能(f)这种方式不大好,但是在Fast RCNN中就没那么明显。
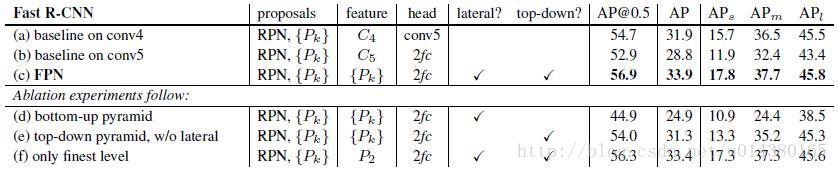
同理,将FPN用于Faster RCNN的实验结果如下表Table3。

下表Table4是和近几年在COCO比赛上排名靠前的算法的对比。注意到本文算法在小物体检测上的提升是比较明显的。
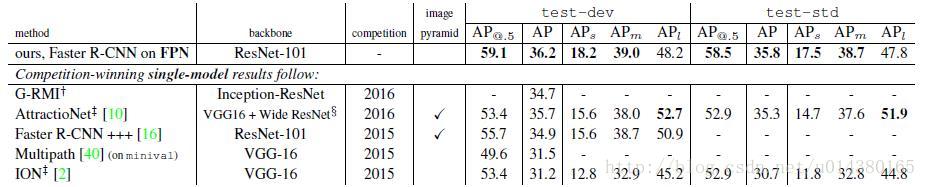
另外作者强调这些实验并没有采用其他的提升方法(比如增加数据集,迭代回归,hard negative mining),因此能达到这样的结果实属不易。
总结
作者提出的FPN(Feature Pyramid Network)算法同时利用低层特征高分辨率和高层特征的高语义信息,通过融合这些不同层的特征达到预测的效果。并且预测是在每个融合后的特征层上单独进行的,这和常规的特征融合方式不同。
Mask R-CNN
博客:https://blog.csdn.net/WZZ18191171661/article/details/79453780
Yolo V3
改进:
(1)bouning box prediction:
在训练的时候使用均方误差损失和(sum of squared error loss);
对于检测框是否有物体采用logistic regression预测一个(object score),即对先验与实际方框IOU大于0.5的作为正例,与SSD不同的是,若有多个先验满足目标,只取一个IOU最大的先验。
(2)class prediction:
作者在训练时对于不同的类别使用独立的logistc classifiers,而不再采用softmax的方式生成类别预测向量,原因系(We have found it is unnecessary for good performance)。
使用二元交叉熵作为分类损失。
另一方面是因为在当存在类别重叠的时候,softmax无法适用。
(3)prediction across scales:
利用多个scale进行预测,实际使用3个不同的scale。将前两层的feature-map进行上采样,与开始的feature-map进行concat起来,加一些卷积层,然后进行预测。
(4)feature extractor:
新的特征提取网络Darkent-53:(Darknet-53和Resnet-152正确率相同,但速度是2倍。)
总结
博客:https://blog.csdn.net/u013510838/article/details/79947553
目标检测领域主要的难点如下:
(1)检测速度:实时性要求高,故网络结构不能太复杂,参数不能太多,卷积层次也不能太多。
(2)位置准确率:(x y w h)参数必须准确,也就是检测框大小尺寸要匹配,且重合度IOU要高。SSD和faster RCNN通过多个bounding box来优化这个问题。
(3)漏检率:必须尽量检测出所有目标物体,特别是靠的近的物体和尺寸小的物体。SSD和faster RCNN通过多个bounding box来优化这个问题。
(4)物体宽高比例不常见:SSD通过不同尺寸feature map,yoloV2通过不同尺寸输入图片,来优化这个问题。
(5)靠的近的物体准确率低。
(6)小尺寸物体准确率低:SSD取消全连接层,yoloV2增加pass through layer,采用高分辨率输入图片,来优化这个问题。
SlimYOLO V3
剪枝过程
什么是深度模型的剪枝?就像论文名字中的更窄(Narrower),它是要减少模型通道数。
去除每个卷积层中不重要的特征通道。所以需要合理地评估特征通道的重要性。
下图可以较为明了地说明整个过程。
合理地评估特征通道的重要性方法
移除的组件可以是单独的神经连接或网络结构。为了定义每个组件的重要性,我们根据它们的贡献对网络的每个神经元进行排序。有多种方法可以做到:
– 我们可以采用L1 / L2正则化神经元权重的平均值
– 每个神经元的平均激活
– 神经元输出不为零的次数
智能推荐
Sandboxie v5.45.2正式版 系统安全工具_sandboxie系统安全工具-程序员宅基地
文章浏览阅读141次。简介:菜鸟高手裸奔工具沙盘Sandboxie是一款国外著名的系统安全工具,它可以让选定程序在安全的隔离环境下运行,只要在此环境中运行的软件,浏览器或注册表信息等都可以完整的进行清空,不留一点痕迹。同时可以防御些带有木马或者病毒的恶意网站,对于经常测试软件或者不放心的软件,可放心在沙盘里面运行!下载地址:http://www.bytepan.com/J7BwpqQdKzR..._sandboxie系统安全工具
Mac技巧|如何在 MacBook上设置一位数登录密码-程序员宅基地
文章浏览阅读230次,点赞4次,收藏5次。Mac老用户都知道之前的老版本系统是可以设置一位数登陆密码的,但是更新到10.14以后就不可以了,今天就教大家怎么在新版本下设置Mac一位数登陆密码。
chatgpt中的强化学习 PPO_chatgpt使用的强化学习-程序员宅基地
文章浏览阅读3.4k次。本该到此结束,但是上述实现的时候其实是把生成的每一步的奖励都使用统一的句子级reward,但该代码其实也额外按照每个token来计算奖励值的,为了获取每个token的奖励,我们在生成模型的隐层表示上,多加一个线性层,映射到一维,作为每个状态的预测奖励值。类似的,在文本生成中我们也可以用蒙特卡洛方法来估计一个模型的状态价值。假如我们只采样到了s1和s2,没有采样到s3,由于7和3都是正向奖励,s1和s2的训练后生成的概率都会变大,且s1的概率变的更大,这看似合理,但是s3是未参与训练的,它的概率反而减小了。_chatgpt使用的强化学习
获取不规则多边形中心点_truf计算重心-程序员宅基地
文章浏览阅读433次,点赞10次,收藏8次。尝试了3种方法,都失败了!_truf计算重心
HDU 1950最长上升子序列 学习nlogn_poj 1631 hdu 1950为啥是最长上升子序列-程序员宅基地
文章浏览阅读406次。学习LIS_poj 1631 hdu 1950为啥是最长上升子序列
kubernetes===》二进制安装_sed -ie 's#image.*#image: ${ epic_image_fullname }-程序员宅基地
文章浏览阅读550次。一、节点规划主机名称IP域名解析k8s-m-01192.168.12.51m1k8s-m-02192.168.12.52m2k8s-m-03192.168.12.53m3k8s-n-01192.168.12.54n1k8s-n-02192.168.12.55n2k8s-m-vip192.168.12.56vip二、插件规划#1.master节点规划kube-apiserverkube-controller-manage_sed -ie 's#image.*#image: ${ epic_image_fullname }#g
随便推点
UAC绕过提权_uac白名单 提权-程序员宅基地
文章浏览阅读106次。UAC绕过提权_uac白名单 提权
Linux一键部署OpenVPN脚本-程序员宅基地
文章浏览阅读664次,点赞7次,收藏12次。每次架设OpenVPN Server就很痛苦,步骤太多,会出错的地方也多,基本很少一次性成功的。
头文件的相互包含问题_多个头文件相互包含-程序员宅基地
文章浏览阅读397次。 今天看了继承以及派生类,并且运行了教程中的一个实例,但是仍然有好多坑。主要如下:建立了一个基类bClass以及由基类bClass派生的一个dClass,并且建立两个头文件.h分别申明这两个类,在cpp程序中进行运行来检验。具体程序如下:#ifndef ITEM_BASE//为避免类重复定义,需要在头文件的开头和结尾加上如这个所示 #define ITEM_BASEclass bClass..._多个头文件相互包含
python -- PyQt5(designer)安装详细教程-程序员宅基地
文章浏览阅读1.3w次,点赞19次,收藏88次。PyQt5安装详细教程,安装步骤很详细
微信小程序scroll-view去除滚动条-程序员宅基地
文章浏览阅读154次。官方文档:https://developers.weixin.qq.com/miniprogram/dev/component/scroll-view.html。_scroll-view去除滚动条
POJ-3233 Matrix Power Series 矩阵A^1+A^2+A^3...求和转化-程序员宅基地
文章浏览阅读146次。S(k)=A^1+A^2...+A^k.保利求解就超时了,我们考虑一下当k为偶数的情况,A^1+A^2+A^3+A^4...+A^k,取其中前一半A^1+A^2...A^k/2,后一半提取公共矩阵A^k/2后可以发现也是前一半A^1+A^2...A^k/2。因此我们可以考虑只算其中一半,然后A^k/2用矩阵快速幂处理。对于k为奇数,只要转化为k-1+A^k即可。n为矩阵数量,m为矩阵..._a^1 a^2 ... a^k