MySQL查询基本概念_mysql 点查询 概念-程序员宅基地
技术标签: 数据库
MySQL查询
MySQL索引基础知识,MySQL索引的优化,MySQL排序
索引结构
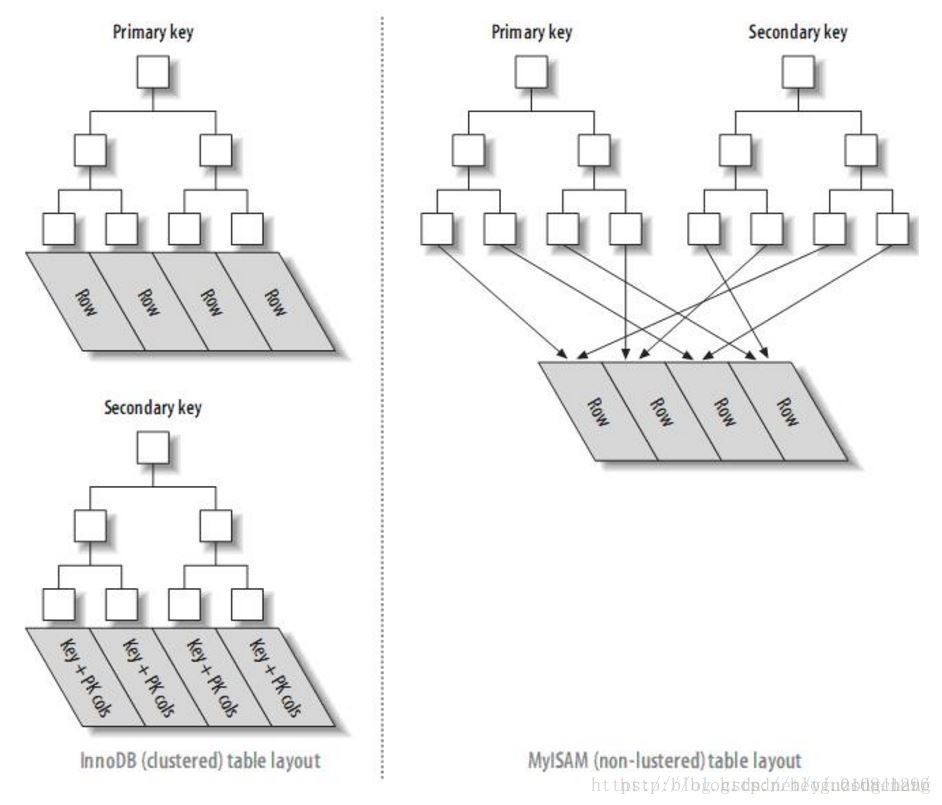
聚簇索引
聚簇索引:又称聚集索引,并不是一种单独的索引类型,而是一种数据存储方式。具体的细节依赖于其实现方式,但InnoDB的聚簇索引实际上在同一个结构中保存了B-Tree索引和数据行。
当表有聚簇索引时,它的数据行实际上存放在索引的叶子页(Leaf page)中,术语“聚簇”表示数据行和相邻的键值紧凑地存储在一起。因为无法同时把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引(不过,覆盖索引可以模拟多个聚簇索引的情况)。
InnoDB通过主键聚集数据,如果没有定义主键,InnoDB会选择一个唯一的非空索引代替。如果没有这样的索引,InnoDB会隐式定义一个主键来作为聚簇索引。InnoDB只聚集在同一页面中的记录。包含相邻键值的页面可能会相距甚远。
聚簇索引按照如下规则创建:
- 当定义了主键后,innodb会利用主键来生成其聚簇索引;
- 如果没有主键,innodb会选择一个非空的唯一索引来创建聚簇索引;
- 如果这也没有,Innodb会隐式的创建一个自增的列来作为聚簇索引。
Note: 对于选择唯一索引的顺序是按照定义唯一索引的顺序,而非表中列的顺序, 同时选中的唯一索引字段会充当为主键,或者Innodb隐式创建的自增列也可以看做主键。
聚簇索引整体是一个b+树,非叶子节点存放的是键值,叶子节点存放的是行数据,称之为数据页,这就决定了表中的数据也是聚簇索引中的一部分,数据页之间是通过一个双向链表来链接的,上文说到B+树是一棵平衡查找树,也就是聚簇索引的数据存储是有序的,但是这个是逻辑上的有序,但是在实际在数据的物理存储上是,因为数据页之间是通过双向链表来连接,假如物理存储是顺序的话,那维护聚簇索引的成本非常的高。
详细引用来源
二级索引
二级索引保存的式行的主键值
三星查询
- 一星,索引将相关的记录放到一起;
- 二星,索引中的数据顺序和查找中的排列顺序一致;
- 三星,索引中的列包含了查询中需要的全部列。
CREATE TABLE `t_wms_sku` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`sku_id` bigint(20) NOT NULL DEFAULT '0',
`sku_name` varchar(50) NOT NULL DEFAULT '',
`price` decimal(18,2) NOT NULL DEFAULT '0.00',
`class3_id` bigint(20) NOT NULL DEFAULT '0',
PRIMARY KEY (`id`),
UNIQUE KEY `udx_sku_id` (`sku_id`) USING BTREE,
KEY `idx_class3` (`class3_id`) USING BTREE
) ENGINE=InnoDB AUTO_INCREMENT=8195 DEFAULT CHARSET=utf8
type
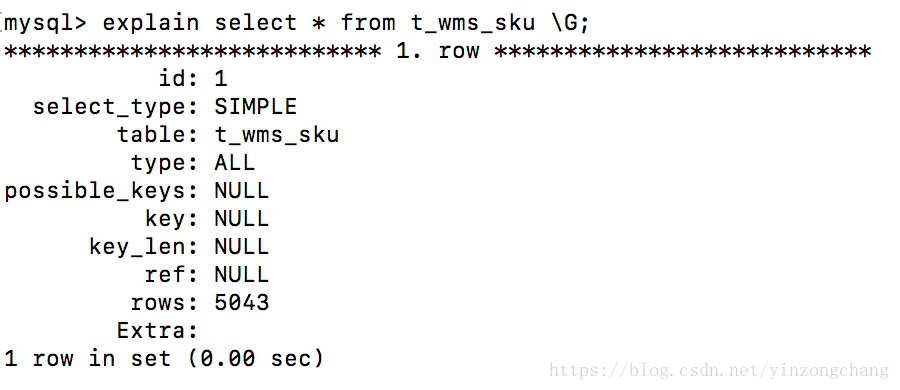
type意味着类型,这里的type官方全称是“join type”,意思是“连接类型”,这样很容易给人一种错觉觉得必须需要俩个表以上才有连接类型。事实上这里的连接类型并非字面那样的狭隘,它更确切的说是一种数据库引擎查找表的一种方式,在《高性能mysql》称呼它为访问类型更贴切一些。
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最差依次是:system>const>eq_ref>refindex>all
- all :Full Table Scan,将遍历全表以找到匹配的行。
这便是所谓的“全表扫描”,如果是展示一个数据表中的全部数据项,倒是觉得也没什么,如果是在一个查找数据项的sql中出现了all类型,那通常意味着你的sql语句处于一种最原生的状态,有很大的优化空间。
比如:explain select * from t_wms_sku where sku_name = '油菜(大棵/新鲜|斤)' ; - index:Full Index Scan,index与ALL区别为index类型只遍历索引树。这通常比ALL快,因为索引文件通常比数据文件小。(也就是说虽然all和index都是读全表,但index是从索引中读取的,而all是从磁盘中读取的)。
比如:explain select sku_id from t_wms_sku; - range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现了between、<、>、in等的查询,这种范围扫描索引扫描比全表扫描要好,因为它只需要开始于索引的某一点,而结束于另一点,不会扫描全部索引。
比如:explain select * from t_wms_sku where sku_id < 1249;
explain select * from t_wms_sku where id < 1249 - ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引还能访问,它返回所有匹配某个单独值的行,然而,他可能会找到多个符合条件的行,所以他应该属于查找和扫描的混合体。
通俗的解释:索引非唯一,条件用索引列=xxx
比如:explain select * from t_wms_sku where class3_id = 555; - eq_ref:唯一性索引扫描,对于每个索引键,表中都只有一条记录与之匹配。常见于主键或唯一索引扫描。
比如:
explain
select s.*, p.* from t_wms_sku s
inner join p_sku p on s.sku_id = p.id
- const:表示通过索引一次就找到了,const用于比较primary key或者unique索引。因此只匹配一行数据,所以很快,如将主键置于where列表中,mysql就能将该查询转换为一个常量。
比如:explain select * from t_wms_sku where sku_id = 1238; - system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现,这个也可以忽略不计。
ref
表示上述表的连接匹配条件,即哪些列或常量被用于查找索引列上的值。



出现上述情况,因为MySQL的join是通过嵌套循环实现的。
Extra
- Distinct:MySQL is looking for distinct values, so it stops searching for more rows for the current row combination after it has found the first matching row.(MySQL正在寻找不同的值,因此在找到第一个匹配行之后,它不再为当前行组合搜索更多行。)平时不太关注。
- Using filesort:MySQL must do an extra pass to find out how to retrieve the rows in sorted order. The sort is done by going through all rows according to the join type and storing the sort key and pointer to the row for all rows that match the WHERE clause. The keys then are sorted and the rows are retrieved in sorted order。(MySQL必须做一个额外的传递来查找如何按排序顺序检索行。排序是通过根据联接类型遍历所有行,并为匹配WHERE子句的所有行存储排序键和指向该行的指针来完成的。然后对键进行排序,并按排序顺序检索行。)
注:看到这个一般就需要优化了,总而言之,排序没有用到索引,需要文件排序,文件排序 - Using index
The column information is retrieved from the table using only information in the index tree without having to do an additional seek to read the actual row. This strategy can be used when the query uses only columns that are part of a single index.
For InnoDB tables that have a user-defined clustered index, that index can be used even when Using index is absent from the Extra column. This is the case if type is index and key is PRIMARY.
(综合一句话,索引覆盖查询,查询语句只查询了索引,没有真正扫描数据)
- Using where
A WHERE clause is used to restrict which rows to match against the next table or send to the client. Unless you specifically intend to fetch or examine all rows from the table, you may have something wrong in your query if the Extra value is not Using where and the table join type is ALL or index.
Using where has no direct counterpart in JSON-formatted output; the attached_condition property contains any WHERE condition used.
(表示优化器需要通过索引回表查询数据)
Using index condition:在5.6版本后加入的新特性(Index Condition Pushdown); Using index condition 会先条件过滤索引,过滤完索引后找到所有符合索引条件的数据行,随后用 WHERE 子句中的其他条件去过滤这些数据行。

智能推荐
获取大于等于一个整数的最小2次幂算法(HashMap#tableSizeFor)_整数 最小的2的几次方-程序员宅基地
文章浏览阅读2w次,点赞51次,收藏33次。一、需求给定一个整数,返回大于等于该整数的最小2次幂(2的乘方)。例: 输入 输出 -1 1 1 1 3 4 9 16 15 16二、分析当遇到这个需求的时候,我们可能会很容易想到一个"笨"办法:..._整数 最小的2的几次方
Linux 中 ss 命令的使用实例_ss@,,x,, 0-程序员宅基地
文章浏览阅读865次。选项,以防止命令将 IP 地址解析为主机名。如果只想在命令的输出中显示 unix套接字 连接,可以使用。不带任何选项,用来显示已建立连接的所有套接字的列表。如果只想在命令的输出中显示 tcp 连接,可以使用。如果只想在命令的输出中显示 udp 连接,可以使用。如果不想将ip地址解析为主机名称,可以使用。如果要取消命令输出中的标题行,可以使用。如果只想显示被侦听的套接字,可以使用。如果只想显示ipv4侦听的,可以使用。如果只想显示ipv6侦听的,可以使用。_ss@,,x,, 0
conda activate qiuqiu出现不存在activate_commandnotfounderror: 'activate-程序员宅基地
文章浏览阅读568次。CommandNotFoundError: 'activate'_commandnotfounderror: 'activate
Kafka 实战 - Windows10安装Kafka_win10安装部署kafka-程序员宅基地
文章浏览阅读426次,点赞10次,收藏19次。完成以上步骤后,您已在 Windows 10 上成功安装并验证了 Apache Kafka。在生产环境中,通常会将 Kafka 与外部 ZooKeeper 集群配合使用,并考虑配置安全、监控、持久化存储等高级特性。在生产者窗口中输入一些文本消息,然后按 Enter 发送。ZooKeeper 会在新窗口中运行。在另一个命令提示符窗口中,同样切换到 Kafka 的。Kafka 服务器将在新窗口中运行。在新的命令提示符窗口中,切换到 Kafka 的。,应显示已安装的 Java 版本信息。_win10安装部署kafka
【愚公系列】2023年12月 WEBGL专题-缓冲区对象_js 缓冲数据 new float32array-程序员宅基地
文章浏览阅读1.4w次。缓冲区对象(Buffer Object)是在OpenGL中用于存储和管理数据的一种机制。缓冲区对象可以存储各种类型的数据,例如顶点、纹理坐标、颜色等。在渲染过程中,缓冲区对象中存储的数据可以被复制到渲染管线的不同阶段中,例如顶点着色器、几何着色器和片段着色器等,以完成渲染操作。相比传统的CPU访问内存,缓冲区对象的数据存储和管理更加高效,能够提高OpenGL应用的性能表现。_js 缓冲数据 new float32array
四、数学建模之图与网络模型_图论与网络优化数学建模-程序员宅基地
文章浏览阅读912次。(1)图(Graph):图是数学和计算机科学中的一个抽象概念,它由一组节点(顶点)和连接这些节点的边组成。图可以是有向的(有方向的,边有箭头表示方向)或无向的(没有方向的,边没有箭头表示方向)。图用于表示各种关系,如社交网络、电路、地图、组织结构等。(2)网络(Network):网络是一个更广泛的概念,可以包括各种不同类型的连接元素,不仅仅是图中的节点和边。网络可以包括节点、边、连接线、路由器、服务器、通信协议等多种组成部分。网络的概念在各个领域都有应用,包括计算机网络、社交网络、电力网络、交通网络等。_图论与网络优化数学建模
随便推点
android 加载布局状态封装_adnroid加载数据转圈封装全屏转圈封装-程序员宅基地
文章浏览阅读1.5k次。我们经常会碰见 正在加载中,加载出错, “暂无商品”等一系列的相似的布局,因为我们有很多请求网络数据的页面,我们不可能每一个页面都写几个“正在加载中”等布局吧,这时候将这些状态的布局封装在一起就很有必要了。我们可以将这些封装为一个自定布局,然后每次操作该自定义类的方法就行了。 首先一般来说,从服务器拉去数据之前都是“正在加载”页面, 加载成功之后“正在加载”页面消失,展示数据;如果加载失败,就展示_adnroid加载数据转圈封装全屏转圈封装
阿里云服务器(Alibaba Cloud Linux 3)安装部署Mysql8-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏29次。PS: 如果执行sudo grep 'temporary password' /var/log/mysqld.log 后没有报错,也没有任何结果显示,说明默认密码为空,可以直接进行下一步(后面设置密码时直接填写新密码就行)。3.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件。下面示例中,将创建新的MySQL账号,用于远程访问MySQL。2.依次运行以下命令,创建远程登录MySQL的账号,并允许远程主机使用该账号访问MySQL。_alibaba cloud linux 3
excel离散度图表怎么算_excel离散数据表格-Excel 离散程度分析图表如何做-程序员宅基地
文章浏览阅读7.8k次。EXCEL中数据如何做离散性分析纠错。离散不是均值抄AVEDEV……=AVEDEV(A1:A100)算出来的是A1:A100的平均数。离散是指各项目间指标袭的离散均值(各数值的波动情况),数值较低表明项目间各指标波动幅百度小,数值高表明波动幅度较大。可以用excel中的离散公式为STDEV.P(即各指标平均离散)算出最终度离散度。excel表格函数求一组离散型数据,例如,几组C25的...用exc..._excel数据分析离散
学生时期学习资源同步-JavaSE理论知识-程序员宅基地
文章浏览阅读406次,点赞7次,收藏8次。i < 5){ //第3行。int count;System.out.println ("危险!System.out.println(”真”);System.out.println(”假”);System.out.print(“姓名:”);System.out.println("无匹配");System.out.println ("安全");
linux 性能测试磁盘状态监测:iostat监控学习,包含/proc/diskstats、/proc/stat简单了解-程序员宅基地
文章浏览阅读3.6k次。背景测试到性能、压力时,经常需要查看磁盘、网络、内存、cpu的性能值这里简单介绍下各个指标的含义一般磁盘比较关注的就是磁盘的iops,读写速度以及%util(看磁盘是否忙碌)CPU一般比较关注,idle 空闲,有时候也查看wait (如果wait特别大往往是io这边已经达到了瓶颈)iostatiostat uses the files below to create ..._/proc/diskstat
glReadPixels读取保存图片全黑_glreadpixels 全黑-程序员宅基地
文章浏览阅读2.4k次。问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError()没有抓到错误,但是获取到的数据有误,如果将获取到的数据保存成为图片,得到的图片为黑色。解决方法:glReadPixels实际上是从缓冲区中读取数据,如果使用了双缓冲区,则默认是从正在显示的缓冲(即前缓冲)中读取,而绘制工作是默认绘制到后缓..._glreadpixels 全黑