python爬虫知识:正则表达式_爬虫正则表达式实验原理-程序员宅基地
技术标签: 爬虫 python search match 正则表达式 findall
概念
正则表达式,又称规则表达式,通常被用来检索、替换那些符合某个模式(规则)的文本。
正则表达式是对字符串操作的一种逻辑公式,就是用事先定义好的一些特定字符、及这些特定字符的组合,组成一个“规则字符串”,这个“规则字符串”用来表达对字符串的一种过滤逻辑。
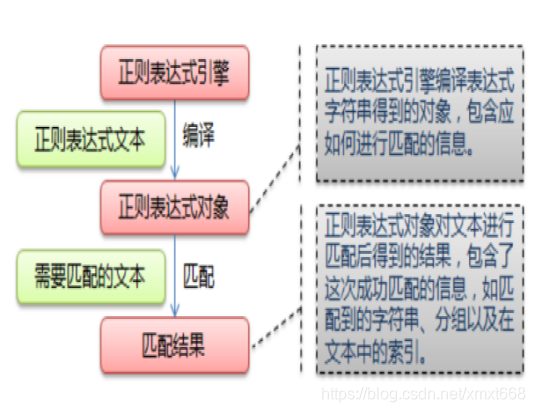
正则表达式的原理:
给定一个正则表达式和另一个字符串,我们可以达到如下的目的:
- 给定的字符串是否符合正则表达式的过滤逻辑(“匹配”);
- 通过正则表达式,从文本字符串中获取我们想要的特定部分(“过滤”)。
正则表达式是由普通字符和特殊字符(元字符)组成的文字模式
在 Python 中,我们可以使用内置的 re 模块来使用正则表达式。
有一点需要特别注意的是,正则表达式使用 对特殊字符进行转义,所以如果我们要使用原始字符串,只需加一个 r 前缀,示例:
import re
#因为\a\b是元字符,所以没有打印出来
print("\a\b\c")#\c
#如果我们想打印出原始字符串,则需要在前面加r,防止转义
print(r"\a\b\c")
#对\进行转义,打印出\本身
print("\\")
#这样也可以将原始字符字符串答应出来
print("\\a\\b\c")
re 模块的一般使用步骤如下:
- 使用 compile() 函数将正则表达式的字符串形式编译为一个 Pattern 对象;
- 通过 Pattern 对象提供的一系列方法对文本进行匹配查找,获得匹配结果,一个 Match 对象;
- 最后使用 Match 对象提供的属性和方法获得信息,根据需要进行其他的操作。
compile 函数
compile 函数用于编译正则表达式,生成一个 Pattern 对象,它的一般使用形式如下:
在上面,我们已将一个正则表达式编译成 Pattern 对象,接下来,我们就可以利用 pattern 的一系列方法对文本进行匹配查找了。
Pattern 对象的一些常用方法主要有:
match方法:从起始位置开始查找,一次匹配search方法:从任何位置开始查找,一次匹配findall方法:全部匹配,返回列表finditer方法:全部匹配,返回迭代器split方法:分割字符串,返回列表sub方法:替换
下面对这几种发方法进行介绍:
- findall方法
我们需要搜索整个字符串,获得所有匹配的结果,使用的是findall()方法
findall 方法的使用形式如下:
findall(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
findall 以列表形式返回全部能匹配的子串,如果没有匹配,则返回一个空列表。
import re
#1.创建pattern对象,编译正则表达式
pattern=re.compile("we")
#2.使用findall匹配信息,匹配到所有的we,返回一个列表
result=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result)
#1.创建pattern对象,编译正则表达式
#\b是元字符,是匹配单词开始和结束
pattern=re.compile(r"\bwe\b")
#2.使用findall匹配信息,匹配到所有的we单词,返回一个列表
result1=pattern.findall("we are working how are you i am well thinks and you Welcome")
print(result1)
常见元字符:
前面提到的元字符\b表示匹配单词的开始和结束。引出其他元字符
| 元字符 | 含义 |
|---|---|
| . | 匹配除换行符以外的任意一个字符 |
| ^ | 匹配行首 |
| $ | 匹配行尾 |
| ? | 重复匹配0次或1次 |
| * | 重复匹配0次或更多次 |
| + | 重复匹配1次或更多次 |
| {n,} | 重复n次或更多次 |
| {n,m} | 重复n~m次 |
| [a-z] | 匹配[a-z]任意字符 |
| [abc] | a/b/c中的任意一个字符 |
| {n} | 重复n次 |
| \b | 匹配单词的开始和结束 |
| \d | 匹配数字 |
| \w | 匹配字母,数字,下划线 |
| \s | 匹配任意空白,包括空格,制表符(Tab),换行符 |
| \W | 匹配任意不是字母,数字,下划线的字符 |
| \S | 匹配任意不是空白符的字符 |
| \D | 匹配任意非数字的字符 |
| \B | 匹配不是单词开始和结束的位置 |
| [^a] | 匹配除了a以外的任意字符 |
| [^(123|abc)] | 匹配除了123或者abc这几个字符以外的任意字符 |
import re
#\d匹配数字一个数字
pattern1=re.compile("\d")
result1=pattern1.findall("hello 123 567")
print(result1)
#\d+匹配一个或者多个数字 如果是多个数字,则必须连续
pattern2=re.compile("\d+")
result2=pattern1.findall("hello 123 567 wor65k6")
print(result2)
#\d{3,}匹配3次或者多次,必须连续
pattern3=re.compile("\d{3,}")
result3=pattern1.findall("hello 123 567 wor65k6")
print(result3)
#\d{3}连续匹配三次
pattern4=re.compile("\d{3}")
result4=pattern1.findall("hello 123 567 wor65453k6434")
print(result4)
#\d{1,2} 可以匹配一次,也可以匹配两次,已更多的优先
pattern5=re.compile("\d{1,2}")
result5=pattern1.findall("hello 123 567 wor65453k6434")
print(result5)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern6=re.compile("[a-z]{5}",re.I)
result6=pattern1.findall("hello 123 567 wor65453k6434")
print(result6)
#\w+匹配数字,字母, 下滑线 一次或者多次
pattern7=re.compile("\w+")
result7=pattern7.findall("hello 123 567 wor65_453k6434")
print(result7)
#\s+匹配空白字符一次或者多次
pattern8=re.compile("\s+")
result8=pattern8.findall("hello 123 567 wor65_453k6434")
print(result8)
# \W+ 匹配不是下滑线 字母 数字
pattern9=re.compile("\W+")
result9=pattern9.findall("hello 123 567 wor65_453k6434")
print(result9)
# [\w\W]+ 匹配所有字符, 一次或多次
pattern10=re.compile("[\w\W]+")
result10=pattern10.findall("hello 123 567 w¥or65_453k6434")
print(result10)
#[abc]+匹配a 或者b或c一次或多次
pattern10=re.compile("[abc]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# [^abc|123]+ 获取不是abc或者123的字符
pattern10=re.compile("[^abc|123]+")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
# .* 匹配任意字符,除了换行符
pattern10=re.compile(".*")
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434")
print(result10)
#re.I表示忽略大小写,"[a-z]{5}匹配a-z的字母五次
pattern10=re.compile("[a-z]{5}",re.I)
#只查找字符串在0-8之间范围的字符 ,要前不要后(左闭右开)-->只查找0,1,2,3,4,5,6,7
result10=pattern10.findall("hello b123 c567 w¥ora65_453ka6434",0,8)
print(result10)
- match 方法
match 方法用于查找字符串的头部(也可以指定起始位置),它是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果。它的一般使用形式如下:
match(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。因此,当你不指定 pos 和 endpos 时,match 方法默认匹配字符串的头部。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
import re
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配, 匹配不到返回none
result1=pattern1.match("gjkdsla3232342kjldf4332opopo")
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo")
print( type(result1))#span=(0, 4), match='5458' span是查找的范围,要前不要后
print(result1)
#提取匹配数据,后面的哦和没有0 效果是一样的
print(result1.group())
print(result1.group(0))
print(result1.start())#获取在字符串开始的位置
print(result1.end())#结束的位置
print(result1.span())#开始和结束的位置 是一个元组
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
#匹配不到 因为位置为6的是字符 不是数字
result1=pattern1.match("5458gjkdsla3232342kjldf4332opopo",6,10)
print(result1)
pattern1=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
pattern2=re.compile("\d+")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("5458gjkdsla3232342kjldf4332opopo",1,10)
print(result2)
pattern2=re.compile("([a-z])+ ([a-z]+)")
#match 匹配 匹配一次返回 从头开始匹配,返回的是match类型的数据
result2=pattern2.match("gjkdsla kjld opopo")
print(result2)
print(result2.group())
print(result2.group(0))#获取所有匹配的内容
print(result2.group(1))#获取第一个()中的内容
print(result2.group(2))#获取第2个()中的内容
print(result2.groups())#获取全部返回一个元组
在上面,当匹配成功时返回一个 Match 对象,其中:
- group([group1, …]) 方法用于获得一个或多个分组匹配的字符串,当要获得整个匹配的子串时,可直接使用 group() 或 group(0);
- start([group]) 方法用于获取分组匹配的子串在整个字符串中的起始位置(子串第一个字符的索引),参数默认值为 0;
- end([group]) 方法用于获取分组匹配的子串在整个字符串中的结束位置(子串最后一个字符的索引+1),参数默认值为 0;
- span([group]) 方法返回 (start(group), end(group))。
- search 方法
search 方法用于查找字符串的任何位置,它也是一次匹配,只要找到了一个匹配的结果就返回,而不是查找所有匹配的结果,它的一般使用形式如下:
search(string[, pos[, endpos]])
其中,string 是待匹配的字符串,pos 和 endpos 是可选参数,指定字符串的起始和终点位置,默认值分别是 0 和 len (字符串长度)。
当匹配成功时,返回一个 Match 对象,如果没有匹配上,则返回 None。
让我们看看例子:
import re
pattern=re.compile("\d+")
#search 是一次匹配 从任意位置开始,返回的是match对象,
#和match最大的不同,就是开始的位置不一样 ,没有查找到 返回none
result=pattern.search("nnd123tyy4566tre189")
#match类型,后面的操作和match方法是一样的
print(result)
print(type(result))
print(result.group())
- finditer 方法
finditer 方法的行为跟 findall 的行为类似,也是搜索整个字符串,获得所有匹配的结果。但它返回一个顺序访问每一个匹配结果(Match 对象)的迭代器。
看看例子:
import re
pattern=re.compile("\d+")
#finditer 是全局查找,返回一个迭代器
result=pattern.finditer("nnd123tyy4566tre189")
print(result)
#遍历迭代器,一个个拿出我们想要的数据
for i in result:
#返回到是match对象
print(i)
#获取match对象中的内容
print(i.group())
列表和迭代器的区别
- 迭代器不占用内存,等你想要的时候,遍历获取出来即可
- 列表是占用大量内存,不使用也占用内存
- split 方法
split 方法按照能够匹配的子串将字符串分割后返回列表,它的使用形式如下:
split(string[, maxsplit])
其中,maxsplit 用于指定最大分割次数,不指定将全部分割。
看看例子:
import re
#把所有的字母分开
pattern=re.compile("[\s;\,\:]+")
#split 是分隔符[\s;\,\:]+
result=pattern.split("i; want: eat;;; dinner, do, you,; want it yes")
print(result)
- sub 方法
sub 方法用于替换。它的使用形式如下:
sub(repl, string[, count])
其中,repl 可以是字符串也可以是一个函数:
- 如果 repl 是字符串,则会使用 repl 去替换字符串每一个匹配的子串,并返回替换后的字符串,另外,repl 还可以使用 id 的形式来引用分组,但不能使用编号 0;
- 如果 repl 是函数,这个方法应当只接受一个参数(Match 对象),并返回一个字符串用于替换(返回的字符串中不能再引用分组)。
- count 用于指定最多替换次数,不指定时全部替换。
import re
#\w 匹配数字 字母 下划线
pattern=re.compile("(\w+)(\w+)")
str1="hello 123 hello 456"
#相当于把str1中被paterna ((\w+)(\w+)) 匹配到的内容 使用wew替换
result=pattern.sub("wew,tr",str1)
print(result)
在某些情况下,我们想匹配文本中的汉字,有一点需要注意的是,中文的 unicode 编码范围 主要在[u4e00-u9fa5]+,这里说主要是因为这个范围并不完整,比如没有包括全角(中文)标点,不过,在大部分情况下,应该是够用的。
假设现在想把字符串 title = ‘你好,hello,世界’ 中的中文提取出来,可以这么做:
import re
#声明要匹配的内容
str="这世界真美好 fdjska dfa"
# [u4e00-u9fa5]这个范围可以匹配绝大多数汉字
# \u是匹配中文
pattern=re.compile("[\u4e00-\u9fa5]+")
result=pattern.findall(str)
print(result)
智能推荐
攻防世界_难度8_happy_puzzle_攻防世界困难模式攻略图文-程序员宅基地
文章浏览阅读645次。这个肯定是末尾的IDAT了,因为IDAT必须要满了才会开始一下个IDAT,这个明显就是末尾的IDAT了。,对应下面的create_head()代码。,对应下面的create_tail()代码。不要考虑爆破,我已经试了一下,太多情况了。题目来源:UNCTF。_攻防世界困难模式攻略图文
达梦数据库的导出(备份)、导入_达梦数据库导入导出-程序员宅基地
文章浏览阅读2.9k次,点赞3次,收藏10次。偶尔会用到,记录、分享。1. 数据库导出1.1 切换到dmdba用户su - dmdba1.2 进入达梦数据库安装路径的bin目录,执行导库操作 导出语句:./dexp cwy_init/[email protected]:5236 file=cwy_init.dmp log=cwy_init_exp.log 注释: cwy_init/init_123..._达梦数据库导入导出
js引入kindeditor富文本编辑器的使用_kindeditor.js-程序员宅基地
文章浏览阅读1.9k次。1. 在官网上下载KindEditor文件,可以删掉不需要要到的jsp,asp,asp.net和php文件夹。接着把文件夹放到项目文件目录下。2. 修改html文件,在页面引入js文件:<script type="text/javascript" src="./kindeditor/kindeditor-all.js"></script><script type="text/javascript" src="./kindeditor/lang/zh-CN.js"_kindeditor.js
STM32学习过程记录11——基于STM32G431CBU6硬件SPI+DMA的高效WS2812B控制方法-程序员宅基地
文章浏览阅读2.3k次,点赞6次,收藏14次。SPI的详情简介不必赘述。假设我们通过SPI发送0xAA,我们的数据线就会变为10101010,通过修改不同的内容,即可修改SPI中0和1的持续时间。比如0xF0即为前半周期为高电平,后半周期为低电平的状态。在SPI的通信模式中,CPHA配置会影响该实验,下图展示了不同采样位置的SPI时序图[1]。CPOL = 0,CPHA = 1:CLK空闲状态 = 低电平,数据在下降沿采样,并在上升沿移出CPOL = 0,CPHA = 0:CLK空闲状态 = 低电平,数据在上升沿采样,并在下降沿移出。_stm32g431cbu6
计算机网络-数据链路层_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输-程序员宅基地
文章浏览阅读1.2k次,点赞2次,收藏8次。数据链路层习题自测问题1.数据链路(即逻辑链路)与链路(即物理链路)有何区别?“电路接通了”与”数据链路接通了”的区别何在?2.数据链路层中的链路控制包括哪些功能?试讨论数据链路层做成可靠的链路层有哪些优点和缺点。3.网络适配器的作用是什么?网络适配器工作在哪一层?4.数据链路层的三个基本问题(帧定界、透明传输和差错检测)为什么都必须加以解决?5.如果在数据链路层不进行帧定界,会发生什么问题?6.PPP协议的主要特点是什么?为什么PPP不使用帧的编号?PPP适用于什么情况?为什么PPP协议不_接收方收到链路层数据后,使用crc检验后,余数为0,说明链路层的传输时可靠传输
软件测试工程师移民加拿大_无证移民,未受过软件工程师的教育(第1部分)-程序员宅基地
文章浏览阅读587次。软件测试工程师移民加拿大 无证移民,未受过软件工程师的教育(第1部分) (Undocumented Immigrant With No Education to Software Engineer(Part 1))Before I start, I want you to please bear with me on the way I write, I have very little gen...
随便推点
Thinkpad X250 secure boot failed 启动失败问题解决_安装完系统提示secureboot failure-程序员宅基地
文章浏览阅读304次。Thinkpad X250笔记本电脑,装的是FreeBSD,进入BIOS修改虚拟化配置(其后可能是误设置了安全开机),保存退出后系统无法启动,显示:secure boot failed ,把自己惊出一身冷汗,因为这台笔记本刚好还没开始做备份.....根据错误提示,到bios里面去找相关配置,在Security里面找到了Secure Boot选项,发现果然被设置为Enabled,将其修改为Disabled ,再开机,终于正常启动了。_安装完系统提示secureboot failure
C++如何做字符串分割(5种方法)_c++ 字符串分割-程序员宅基地
文章浏览阅读10w+次,点赞93次,收藏352次。1、用strtok函数进行字符串分割原型: char *strtok(char *str, const char *delim);功能:分解字符串为一组字符串。参数说明:str为要分解的字符串,delim为分隔符字符串。返回值:从str开头开始的一个个被分割的串。当没有被分割的串时则返回NULL。其它:strtok函数线程不安全,可以使用strtok_r替代。示例://借助strtok实现split#include <string.h>#include <stdio.h&_c++ 字符串分割
2013第四届蓝桥杯 C/C++本科A组 真题答案解析_2013年第四届c a组蓝桥杯省赛真题解答-程序员宅基地
文章浏览阅读2.3k次。1 .高斯日记 大数学家高斯有个好习惯:无论如何都要记日记。他的日记有个与众不同的地方,他从不注明年月日,而是用一个整数代替,比如:4210后来人们知道,那个整数就是日期,它表示那一天是高斯出生后的第几天。这或许也是个好习惯,它时时刻刻提醒着主人:日子又过去一天,还有多少时光可以用于浪费呢?高斯出生于:1777年4月30日。在高斯发现的一个重要定理的日记_2013年第四届c a组蓝桥杯省赛真题解答
基于供需算法优化的核极限学习机(KELM)分类算法-程序员宅基地
文章浏览阅读851次,点赞17次,收藏22次。摘要:本文利用供需算法对核极限学习机(KELM)进行优化,并用于分类。
metasploitable2渗透测试_metasploitable2怎么进入-程序员宅基地
文章浏览阅读1.1k次。一、系统弱密码登录1、在kali上执行命令行telnet 192.168.26.1292、Login和password都输入msfadmin3、登录成功,进入系统4、测试如下:二、MySQL弱密码登录:1、在kali上执行mysql –h 192.168.26.129 –u root2、登录成功,进入MySQL系统3、测试效果:三、PostgreSQL弱密码登录1、在Kali上执行psql -h 192.168.26.129 –U post..._metasploitable2怎么进入
Python学习之路:从入门到精通的指南_python人工智能开发从入门到精通pdf-程序员宅基地
文章浏览阅读257次。本文将为初学者提供Python学习的详细指南,从Python的历史、基础语法和数据类型到面向对象编程、模块和库的使用。通过本文,您将能够掌握Python编程的核心概念,为今后的编程学习和实践打下坚实基础。_python人工智能开发从入门到精通pdf