深度学习方法(十七):word2vec算法原理(1):跳字模型(skip-gram) 和连续词袋模型(CBOW)_word2vec模型-程序员宅基地
技术标签: 深度学习 Deep Learning 机器学习 机器学习 Machine Learning word2vec
word embedding算法中最为经典的算法就是今天要介绍word2vec,最早来源于Google的Mikolov的:
1、Distributed Representations of Sentences and Documents
2、Efficient estimation of word representations in vector space
也是开创了无监督词嵌入的新局面,让大量之后的NLP工作基于word2vec(或类似的改进工作)的词嵌入再做其他任务。推荐看[1]的论文,相对比较容易看懂。也推荐看下[4],是本文中的公式和基本原理讲解来源,因为我只是用于笔记,不作为商用,所以很多话如果我觉得可以理解的话我就不改了,但是中间会穿插一些自己的理解。希望通过本篇可以把word2vec再巩固一遍。
词向量表示
先讲一讲one-hot词向量和distributed representation分布式词向量
-
one hot的表示形式:word vector = [0,1,0,…,0],其中向量维数为词典的个数|V|,当前词对应的位置为1,其他位置为0。
-
distributed的表示形式:word vector = [0.171,-0.589,-0.346,…,0.863],其中向量维数需要自己指定(比如设定256维等),每个维度的数值需要通过训练学习获得。
虽然one-hot词向量构造起来很容易,但通常并不是一个好选择。一个主要的原因是,one-hot词向量无法准确表达不同词之间的相似度,如我们常常使用的余弦相似度。对于向量 x , y ∈ R d x,y \in R^d x,y∈Rd ,它们的余弦相似度是它们之间夹角的余弦值
x ⊤ y ∥ x ∥ ∥ y ∥ ∈ [ − 1 , 1 ] . \frac{\boldsymbol{x}^\top \boldsymbol{y}}{\|\boldsymbol{x}\| \|\boldsymbol{y}\|} \in [-1, 1]. ∥x∥∥y∥x⊤y∈[−1,1].
word2vec工具的提出正是为了解决上面这个问题 。它将每个词表示成一个定长的向量,并使得这些向量能较好地表达不同词之间的相似和类比关系。word2vec工具包含了两个模型,即跳字模型(skip-gram) 和连续词袋模型(continuous bag of words,CBOW)。接下来让我们分别介绍这两个模型以及它们的训练方法。
跳字模型(skip-gram)
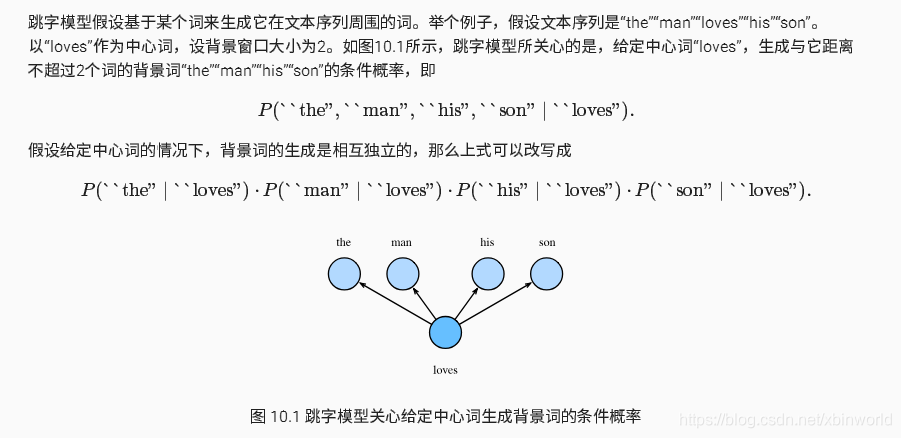

注解:看到这里,就引出了word2vec的核心方法,其实就是认为每个词相互独立,用连乘来估计最大似然函数,求解目标函数就是最大化似然函数。上面公式涉及到一个中心词向量v,以及北京词向量u,因此呢很有趣的是,可以用一个input-hidden-output的三层神经网络来建模上面的skip-model。
Skip-gram可以表示为由输入层(Input)、映射层(Projection)和输出层(Output)组成的神经网络(示意图如下,来自[2]):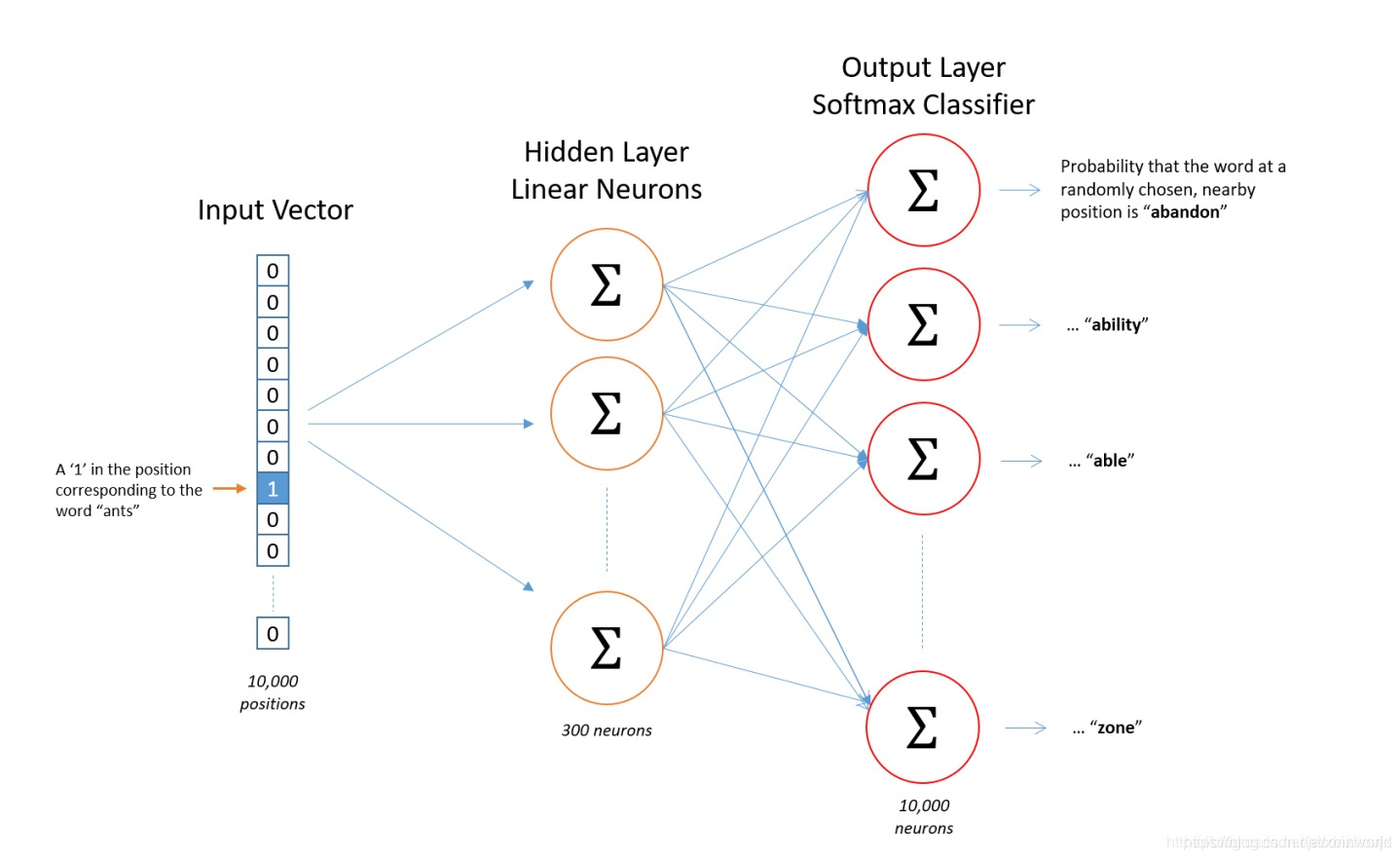
图1
- 输入的表示:输入层中每个词由独热编码方式表示,即所有词均表示成一个N维向量,其中N为词汇表中单词的总数。在向量中,每个词都将与之对应的维度置为1,其余维度的值均为0。
- 网络中传播的前向过程:输出层向量的值可以通过隐含层向量(K维),以及连接隐藏层和输出层之间的KxN维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的一个单词相对应。最后对输出层向量应用Softmax激活函数,可以计算每一个单词的生成概率。
训练跳字模型

注解:上面的公式每一步都推荐推到一下,都很基础。上面只求了对中心词向量v的梯度,同理对背景词向量的梯度,也很容易计算出来。然后就采用传统的梯度下降(一般采用sgd)来训练词向量(其实我们最后关心的是中心词向量来作为词的表征。)
这里有一个key point说下,也许大家也想到了:词向量到底在哪里呢?回看下前面图1,有两层神经网络,第一层是input层到hidden层,这个中间的weight矩阵就是词向量!!!
假设input的词汇表N长度是10000,hidden层的长度K=300,左乘以一个10000长度one-hot编码,实际上就是在做一个查表!因此,这个weight矩阵的行就是10000个词的词向量。很有创意是不是?再来看神经网络的第二层,hidden到out层,中间hidden层有没有激活函数呢?从前面建模看到,u和v是直接相乘的,没有激活层,所以hidden是一个线性层。out层就是建模了v和u相乘,结果过一个softmax,那么loss函数是最大似然怎么办呢?其实就是接多个只有一个true label(背景词)的cross entropy loss,把这些loss求和。因为交叉熵就是最大似然估计,如果这点不清楚的可以去网上搜一下,很容易知道。
所以呢,我们即可用前面常规的最大似然建模来理解如何对u和v的进行优化求解;也完全可以把skip-model套到上面图1这样的一个简单神经网络中,然后就让工具自己来完成weight的训练,就得到了我们想要的中心词向量。
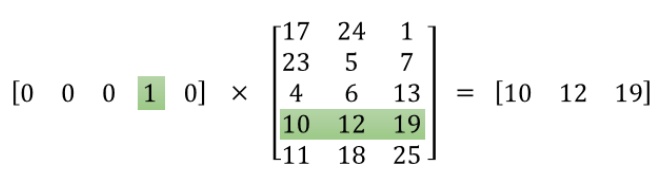
下图是对这个过程的简单可视化过程示意图。左边矩阵为词汇表中第四个单词的one-hot表示,右边矩阵表示包含3个神经元的隐藏层的权重矩阵,做矩阵乘法的结果就是从权重矩阵中选取了第四行的权重。因此,这个隐藏层的权重矩阵就是我们最终想要获得的词向量字典[2]
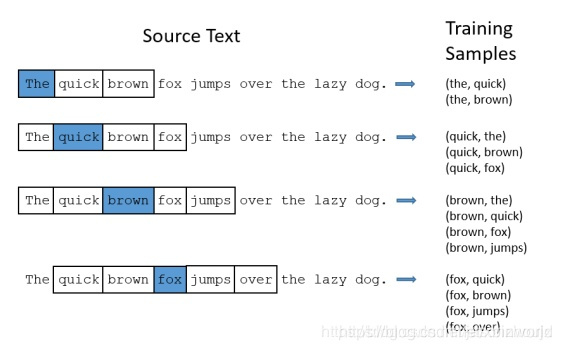
获取训练样本:按照上下文窗口的大小从训练文本中提取出词汇对,下面以句子The quick brown fox jumps over the lazy dog为例提取用于训练的词汇对,然后将词汇对的两个单词使用one-hot编码就得到了训练用的train_data和target_data。 下面的图中给出了一些我们的训练样本的例子。我们选定句子“The quick brown fox jumps over lazy dog”,设定我们的窗口大小为2(window_size=2),也就是说我们仅选输入词前后各两个词和输入词进行组合。下图中,蓝色代表input word,方框内代表位于窗口内的单词。Training Samples(输入, 输出)示意图如下:
如果使用随机梯度下降,那么在每一次迭代里我们随机采样一个较短的子序列来计算有关该子序列的损失,然后计算梯度来更新模型参数。
连续词袋模型(CBOW)
CBOW就倒过来,用多个背景词来预测一个中心词,CBOW对小型数据库比较合适,而Skip-Gram在大型语料中表现更好[2]。但是方法和上面是很像的,因此这里我就放下图。推导的方法是一样的。
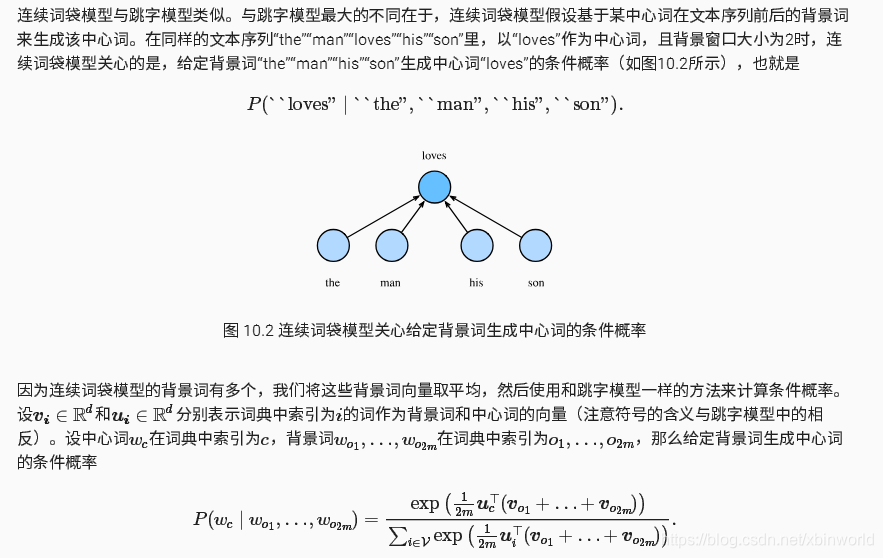
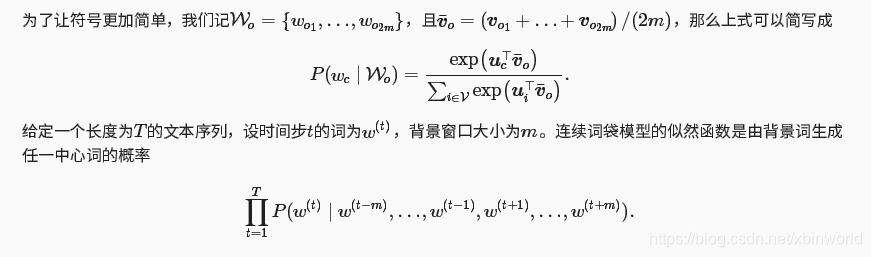
训练连续词袋模型

我们发现,不论是跳字模型(skip-gram) 还是连续词袋模型(CBOW),我们实际上都是取得input-hidden这个词向量(weight矩阵),而不是后面带着loss那一部分,这样我们也很容易可以对loss(训练方法)进行修改,这个也是下一篇要说的内容:
问:每次梯度的计算复杂度是多少?当词典很大时,会有什么问题?
word2vec作者很创造性地提出了2种近似训练方法(分层softmax(hierarchical softmax)和负采样(negative sampling)),得益于此,可以训练大规模语料库。
参考资料:
[1] word2vec Parameter Learning Explained,《word2vec Parameter Learning Explained》论文学习笔记
[2] Word2Vector之详解Skip-gram(1toN)
[3] 探索:word2vec
[4] http://zh.gluon.ai/chapter_natural-language-processing/word2vec.html
智能推荐
hadoop在eclipse上运行实例_hadoop eclipse run as-程序员宅基地
文章浏览阅读2.8k次,点赞2次,收藏18次。上一篇博客阐述了怎么创建hadoop与eclipse的连接(因为是在GUI版上装的linux版eclipse),所以这一篇不仅介绍怎么做,而且还讲解怎么创建windows上eclipse与linux上的hadoop的连接。(11条消息) Centos7(GUI)下的hadoop与eclipse的连接并运行wordcount实例_qq_45672631的博客-程序员宅基地这里,在hadoop已经成功的前提下,我们在官网下载eclipse (这里用的是2021-06版的)java-jdk(这里用的11._hadoop eclipse run as
PHP使用gearman扩展完成异步任务总结_php5 gearman-程序员宅基地
文章浏览阅读2.2k次。PHP的gearman扩展,可以在Linux服务器上,实现PHP脚本的异步任务,甚至是分布式异步任务。在项目中一些响应慢,或者是占用时间的PHP脚本,可以用异步任务去完成,用户访问时不用等待漫长的队列任务,因为在服务器上有专门跑这些异步任务的脚本。1、安装能执行任务的job(用于执行“work”)#wget http://launchpad.net/gearmand/tru_php5 gearman
【无标题】针对MNIST数据集,构造卷积神经网络实现手写数字识别。_从网上下载或自己编程实现一个卷积神经网络并在手写字符识别数据 mnist上进行实验-程序员宅基地
文章浏览阅读1.9k次,点赞2次,收藏31次。以pytorch构建的两层卷积核,一层池化层,两层全连接层的神经网络,在Mninst数据 集上训练,准确率达到98%,而且在增加旋转的Mninst数据集上达到97%的准确率。_从网上下载或自己编程实现一个卷积神经网络并在手写字符识别数据 mnist上进行实验
IDEA专栏—IDEA导入maven工程发现Java文件颜色不对_maven颜色-程序员宅基地
文章浏览阅读1.2k次。如下图设置,File Setting中:或者在我们导入项目时,idea右下角界面会弹出提示框,询问我们是否要自动导入,选择Enable Auto-imort即可,如下图。但是这里选择仅仅是针对当前项目自动导入,所以还是乖乖在file setting中设置自动导入最为保险。_maven颜色
详解@JsonProperty、@JsonFormat 和 @DateTimeFormat 注解用法-程序员宅基地
文章浏览阅读1.4w次,点赞6次,收藏37次。详细解释 @JsonProperty、@JsonFormat 和 @DateTimeFormat 注解的用法_@jsonproperty
Linux使用docker搭建Mysql主从复制_linux 实现docker的mysql主从复制-程序员宅基地
文章浏览阅读326次。Linux使用docker搭建Mysql主从复制_linux 实现docker的mysql主从复制
随便推点
三个整数的排序_将输入的三个数放到数组中并排序-程序员宅基地
文章浏览阅读4.1k次。1. 问题描述:问题描述 输入三个数,比较其大小,并从大到小输出输入格式 一行三个整数输出格式 一行三个整数,从大到小排序样例输入33 88 77样例输出88 77 332. 方法一:可以使用Java的三目运算符进行判断得到最大值然后判断剩下来的元素的大小关系,方法二新建一个整型数组把元素存进去然后对数组进行排序然后再逆序输出即可..._将输入的三个数放到数组中并排序
剑指 Offer 14- I. 剪绳子(C++暴力+动态规划、贪心解)_c++剪绳子动态规划法-程序员宅基地
文章浏览阅读627次。一、题目剑指 Offer 14- I. 剪绳子题目描述给你一根长度为 n 的绳子,请把绳子剪成整数长度的 m 段(m、n都是整数,n>1并且m>1),每段绳子的长度记为 k[0],k[1]…k[m-1] 。请问 k[0]k[1]…*k[m-1] 可能的最大乘积是多少?例如,当绳子的长度是8时,我们把它剪成长度分别为2、3、3的三段,此时得到的最大乘积是18。示例1:输入: 2输出: 1解释: 2 = 1 + 1, 1 × 1 = 1示例2:输入: 10输出: 36解释: _c++剪绳子动态规划法
关于Ionic cordova 的一些基本问题_关于cordova:ionic-(仅适用于ios)仍在应用程序第一个可见模板的背景中显示闪屏中-程序员宅基地
文章浏览阅读252次。新建项目 -vx 表示指定第x个ionic版本ionic start myAwesomeApp --vx(不指定会提示使用哪个版本)ionic创建项目报错Error: read ECONNRESET at _errnoException (util.js:992:11) at TLSWrap.onread (net.js:618:25)–> 版本4.1.1 降级为3.9.1 !!!..._关于cordova:ionic-(仅适用于ios)仍在应用程序第一个可见模板的背景中显示闪屏中
光线追踪渲染实战(五):低差异序列与重要性采样,加速收敛!_软光追,bvh可视化,gpu实现,brdf,重要性采样以及差异序列-程序员宅基地
文章浏览阅读5.2k次,点赞25次,收藏26次。1. 低差异序列具有很好的空间填充性质,使用 sobol sequence 作为生成半球采样样本的随机数 2. 使用重要性采样策略对 Disney BRDF 进行采样,大大加速收敛的过程 3. 预计算 hdr 贴图的重要性采样样本,直接采样光源,对 hdr 贴图高亮处分配更多的光线 4. 使用多重重要性采样策略混合 brdf 采样和 hdr 采样,适应粗糙度和不同大小的光源,加速光线追踪的收敛_软光追,bvh可视化,gpu实现,brdf,重要性采样以及差异序列
My97DatePicker日期控件使用方法_my97datepicker设置选择今天以后-程序员宅基地
文章浏览阅读660次。-------------------------------引入JS------------------------ ------------------使用控件------------------------------- class="Wdate" size="10" readonly="readonly" style="height:15px;wi_my97datepicker设置选择今天以后
医学图像分割模型:U-Net详解及实战-程序员宅基地
文章浏览阅读6k次,点赞11次,收藏122次。2015年U-Net的出现使得原先需要数千个带注释的数据才能进行训练的深度学习神经网络大大减少了训练所需要的数据量,并且其针对神经网络在图像分割上的应用开创了先河。当时神经网络在图像分类任务上已经有了较好的成果,但在很多视觉的任务中由于输出需要进行定位,也就是每个像素需要分配一个类标签,这导致成千上万的训练图像在生物医学任务中通常难以获得,从而急需要一个神经网络,它不需要那么多的数据来进行训练却依旧有较好的效果,这就导致了U-Net的诞生。U-Net几乎是当前segmentation项目中应用最广的模型。_医学图像分割