实验模拟 搭建elk 日志分析系统-程序员宅基地
技术标签: elk
目录
二 ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
2, 部署 Elasticsearch 软件(node1 node2)
3, 安装 Elasticsearch-head 插件(node1)
3.1 为什么要安装 Elasticsearch-head 插件
3.5 安装 Elasticsearch-head 数据可视化工具
4, 通过 Elasticsearch-head 查看 Elasticsearch 信息
5,测试Elasticsearch-head 的作用 (插入索引)
三 ELK Logstash 部署(在 Apache 节点99机器上操作)
4.2 使用 rubydebug 输出详细格式显示,codec 为一种编解码器
4.3 使用 Logstash 将信息写入 Elasticsearch 中
四 ELK Kiabana 部署(在 Node1 节点上操作)
一 实验环境
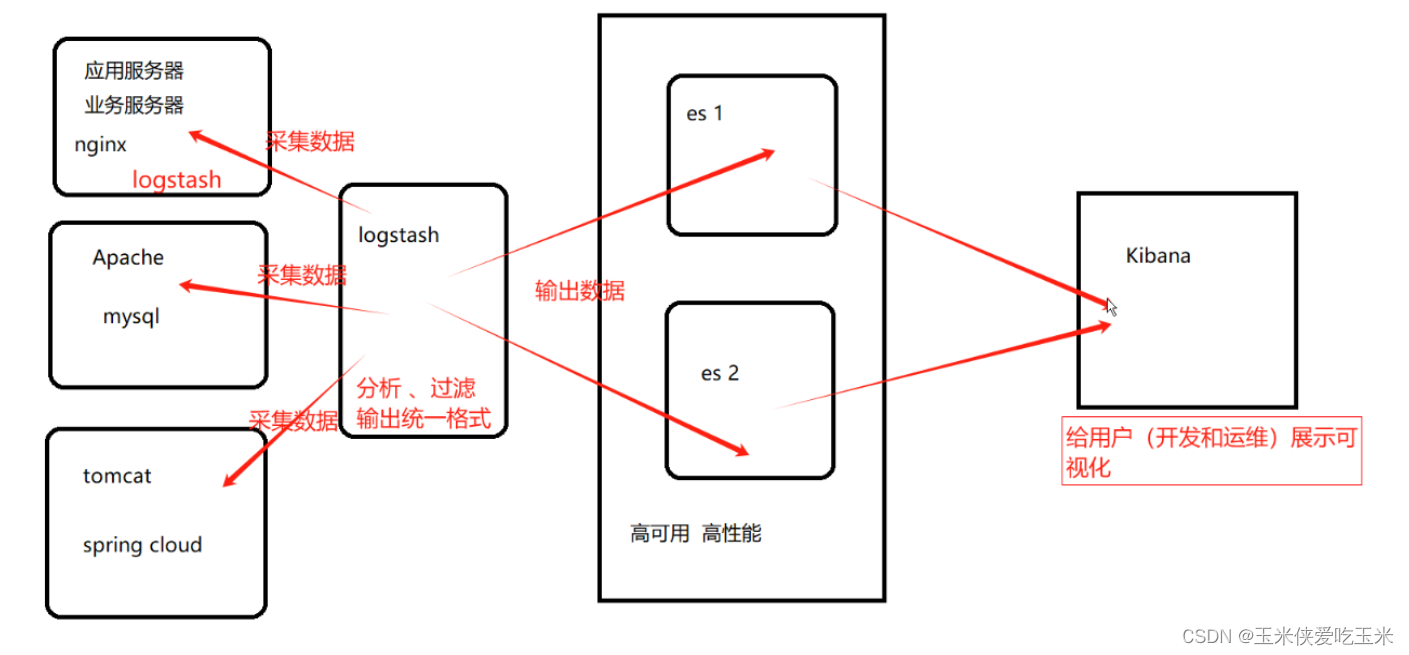
Node1节点(2C/4G):node1/192.168.217.77 Elasticsearch Kibana
Node2节点(2C/4G):node2/192.168.217.88 Elasticsearch
Apache节点: apache/192.168.217.99 Logstash Apache
二 ELK Elasticsearch 集群部署(在Node1、Node2节点上操作)
1,环境准备
关闭防火墙

改主机名

配置域名解析

查看java 环境 (生产环境建议使用jdk)

2, 部署 Elasticsearch 软件(node1 node2)
2.1安装es

2.2设置开机自启

2.3修改 elasticsearch主配置文件(先备份)

代码如下:
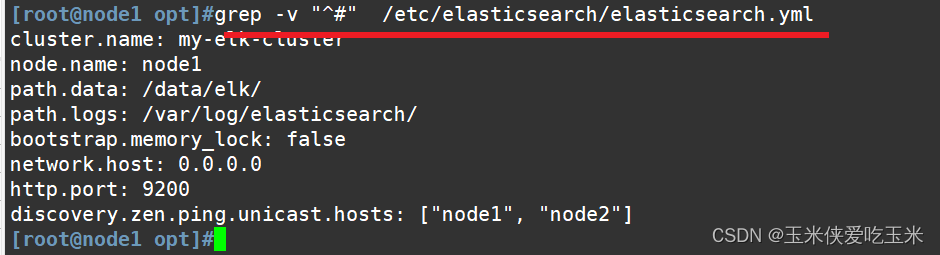
vim /etc/elasticsearch/elasticsearch.yml
--17--取消注释,指定集群名字
cluster.name: my-elk-cluster
--23--取消注释,指定节点名字:Node1节点为node1,Node2节点为node2
node.name: node1
--33--取消注释,指定数据存放路径
path.data: /data/elk_data
--37--取消注释,指定日志存放路径
path.logs: /var/log/elasticsearch/
--43--取消注释,改为在启动的时候不锁定内存
bootstrap.memory_lock: false
--55--取消注释,设置监听地址,0.0.0.0代表所有地址
network.host: 0.0.0.0
--59--取消注释,ES 服务的默认监听端口为9200
http.port: 9200
--68--取消注释,集群发现通过单播实现,指定要发现的节点 node1、node2
discovery.zen.ping.unicast.hosts: ["node1", "node2"]
没有问题,scp 传给 node2 (注意把node2的配置文件中的节点 改为node2)

2.4 创建数据存放路径并改属主,属组

2.5 启动elasticsearch是否成功开启
有点慢耐心等待一下
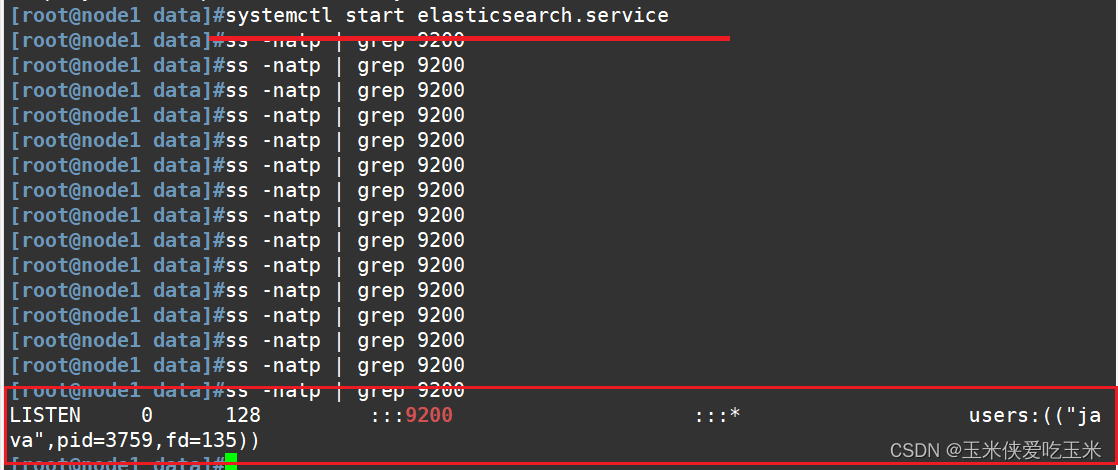
2.6 查看节点信息
浏览器访问 http://192.168.217.77:9200 、 http://192.168.217.88:9200 查看节点 Node1、Node2 的信息。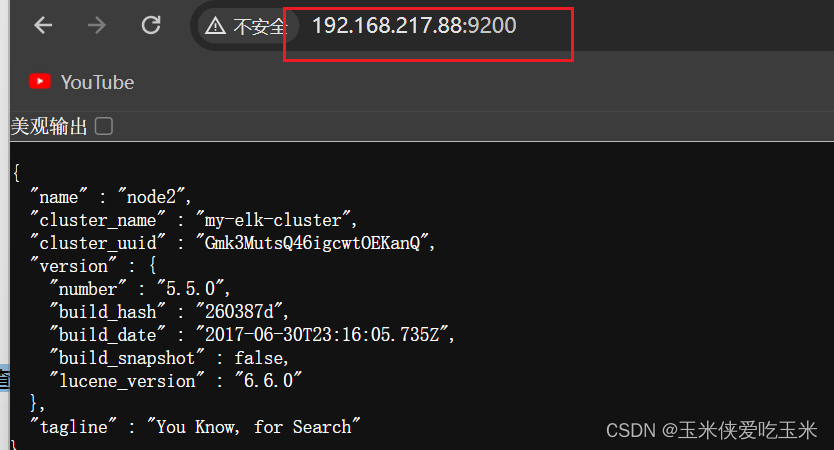
浏览器访问 http://192.168.217.77:9200/_cluster/health?pretty http://192.168.217.88:9200/_cluster/health?pretty查看群集的健康情况,可以看到 status 值为 green(绿色), 表示节点健康运行。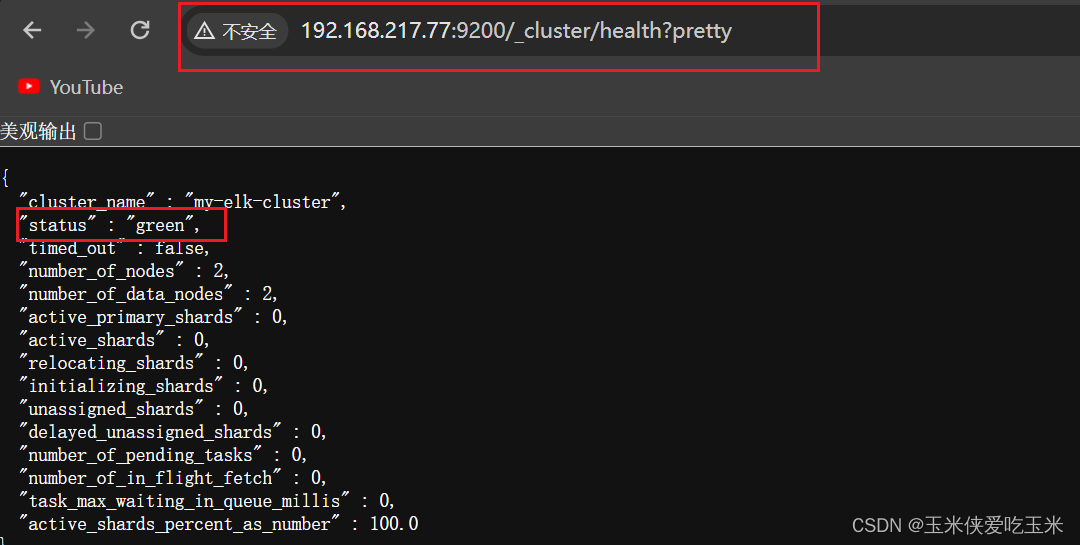
绿色:健康 数据和副本 全都没有问题
红色:数据都不完整
黄色:数据完整,但副本有问题
3, 安装 Elasticsearch-head 插件(node1)
3.1 为什么要安装 Elasticsearch-head 插件
使用上述方式查看群集的状态对用户并不友好,可以通过安装 Elasticsearch-head 插件,可以更方便地管理群集。
3.2 Elasticsearch-head 插件 是什么
Elasticsearch 在 5.0 版本后,Elasticsearch-head 插件需要作为独立服务进行安装,需要使用npm工具(NodeJS的包管理工具)安装。
安装 Elasticsearch-head 需要提前安装好依赖软件 node 和 phantomjs。
node:是一个基于 Chrome V8 引擎的 JavaScript 运行环境。
phantomjs:是一个基于 webkit 的JavaScriptAPI,可以理解为一个隐形的浏览器,任何基于 webkit 浏览器做的事情,它都可以做到。
3.3 编译安装 node
先安装 编译环境

编译安装node ./configure make && make install (有点慢 等一会)
3.4 安装 phantomjs(前端的框架)
PhantomJS 是一个基于 WebKit 渲染引擎的无头(headless)浏览器,即它是一个没有用户界面(UI)的浏览器环境
先解压 phantomjs 包

将可执行文件拷贝到 /usr/local/bin

3.5 安装 Elasticsearch-head 数据可视化工具
解压Elasticsearch-head

进到这个包里 安装npm install

(npm install 是 Node.js 环境中的一个命令,用于安装项目所需的依赖包
在项目根目录下运行此命令时,npm 会做以下两件事之一:
-
初始化新项目: 如果当前目录下不存在
package.json文件,npm install会创建一个新的空package.json文件,并将其设置为默认的 npm 初始化配置。这通常意味着生成一个简单的项目描述和初始的空白依赖列表。 -
安装依赖: 如果当前目录下已存在
package.json文件,npm install将读取该文件中定义的dependencies和(可选的)devDependencies字段,然后下载并安装这些依赖包及其子依赖到本地的node_modules目录。这个过程也被称为“npm install”。)
3.6 修改 Elasticsearch 主配置文件
跨域问题
由于安全原因,Elasticsearch 默认可能不允许跨域访问。如果您在访问 Elasticsearch Head 时遇到跨域问题,需要在 Elasticsearch 配置文件(通常位于 elasticsearch.yml)中添加以下配置:
vim /etc/elasticsearch/elasticsearch.yml
http.cors.enabled: true #开启跨域访问支持,默认为 false
http.cors.allow-origin: "*" #指定跨域访问允许的域名地址为所有

systemctl restart elasticsearch
3.7 启动 elasticsearch-head 服务
#必须在解压后的 elasticsearch-head 目录下启动服务,进程会读取该目录下的 gruntfile.js 文件,否则可能启动失败。
查看是否启动

4, 通过 Elasticsearch-head 查看 Elasticsearch 信息
通过浏览器访问 http://192.168.217.77:9100/ 地址并连接群集。如果看到群集健康值为 green 绿色,代表群集很健康。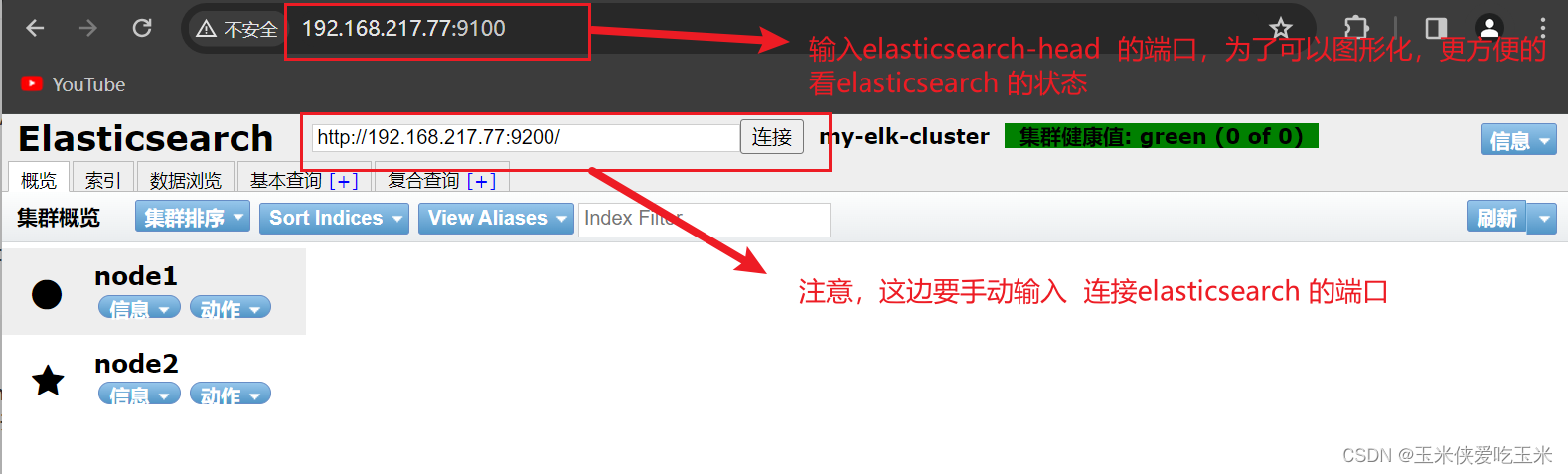
5,测试Elasticsearch-head 的作用 (插入索引)
通过命令插入一个测试索引,索引为 index-demo,类型为 test。
代码如下;
curl -X PUT 'localhost:9200/index-demo1/test/1?pretty&pretty' -H 'content-Type: application/json' -d '{"user":"zhangsan","mesg":"hello world"}'
这条 curl 命令的作用是向本地运行的 Elasticsearch 服务的 index-demo1 索引中,使用 PUT 方法更新或创建一个 ID 为 1、类型为 test 的文档。文档内容为一个包含 user 和 mesg 字段的 JSON 对象,并且请求期望接收格式化的 JSON 响应。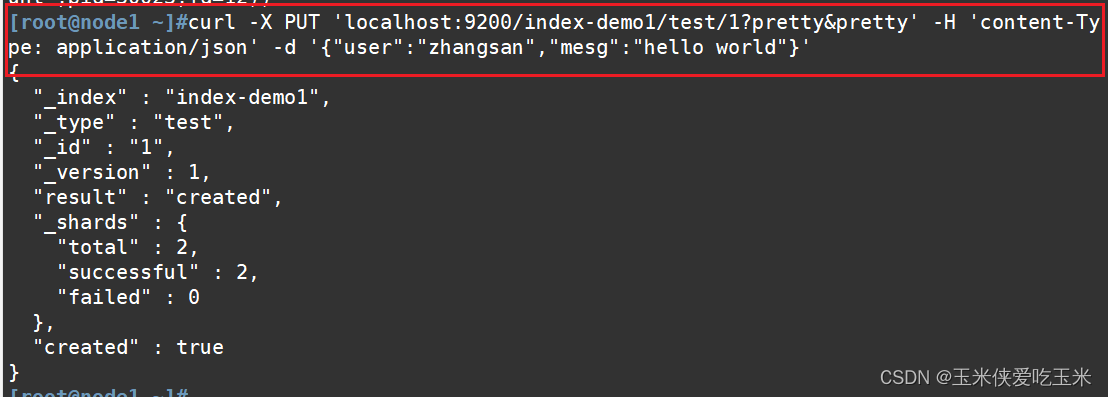
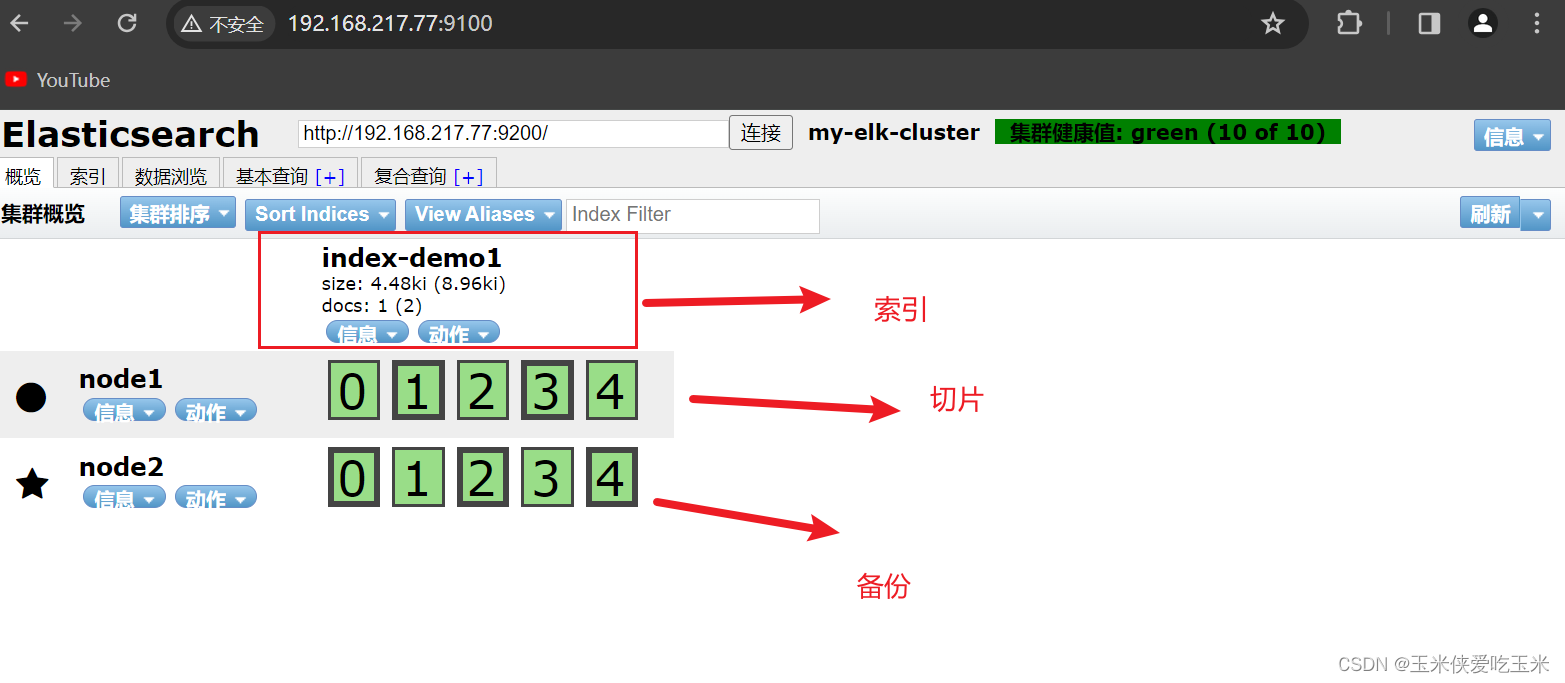
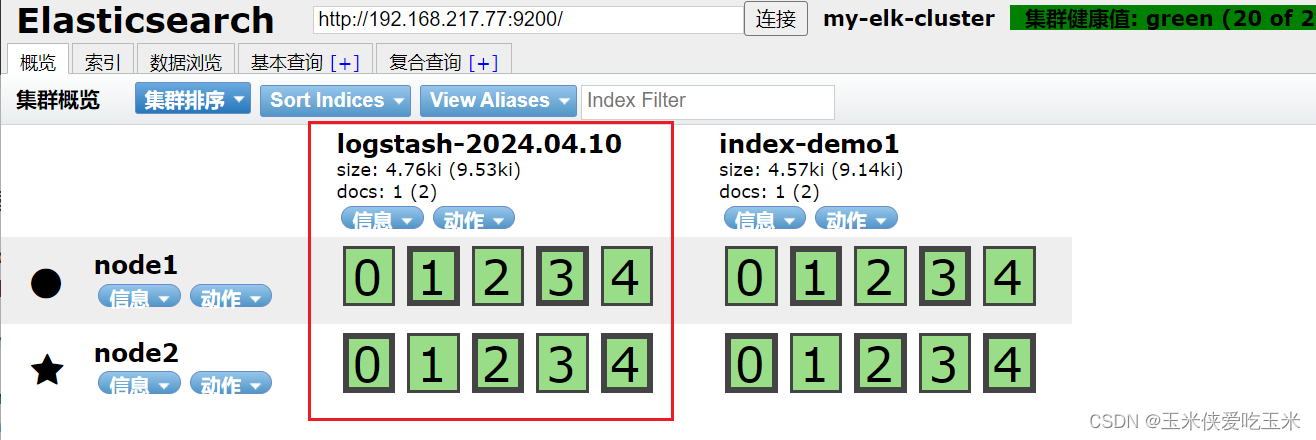
浏览器访问 http://192.168.217.77:9100/ 查看索引信息,可以看见索引默认被分片5个,并且有一个副本。
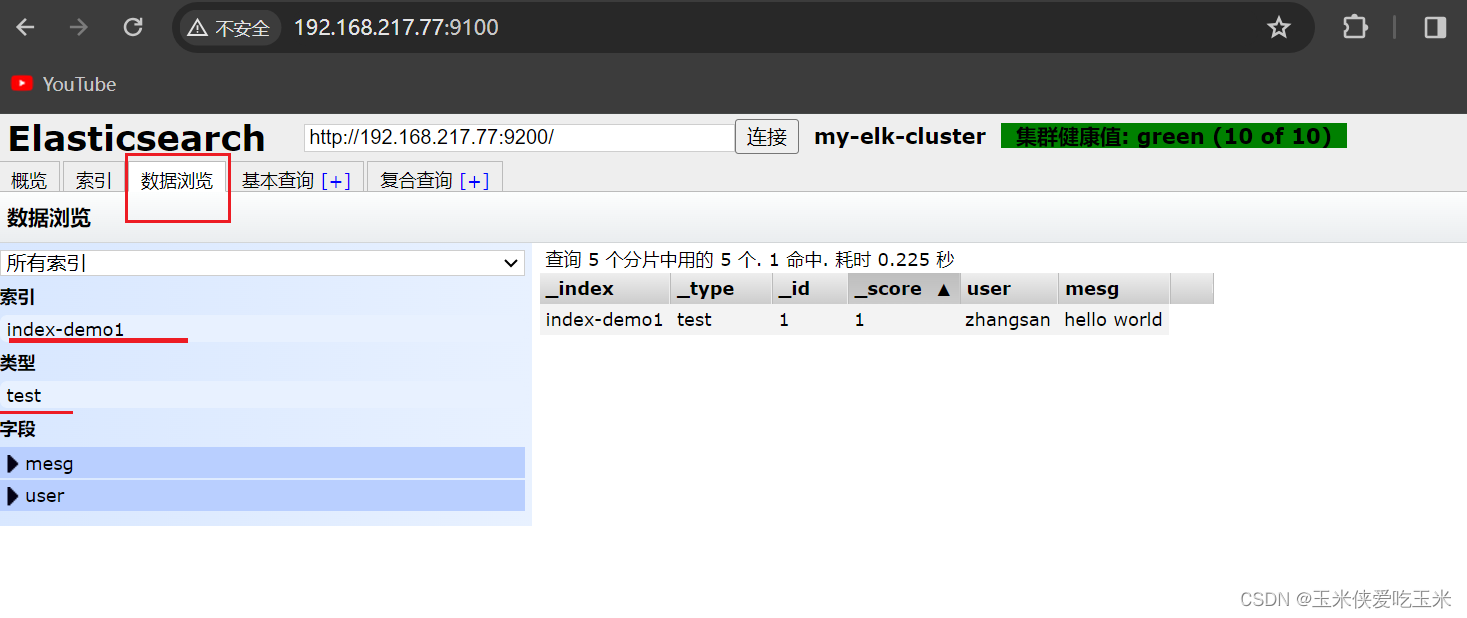
点击“数据浏览”,会发现在node1上创建的索引为 index-demo,类型为 test 的相关信息。
可以看到 索引类型
三 ELK Logstash 部署(在 Apache 节点99机器上操作)
1,Logstash 作用
Logstash 一般部署在需要监控其日志的服务器。在本案例中,Logstash 部署在 Apache 服务器上,用于收集 日志信息并发送到 Elasticsearch。
2,准备环境
改主机名

安装Apahce服务(httpd)

查看java 环境

3, 安装logstash
解压压缩包

做开机自启

做软连接

4,测试 Logstash
Logstash 命令常用选项:
-f:通过这个选项可以指定 Logstash 的配置文件,根据配置文件配置 Logstash 的输入和输出流。
-e:从命令行中获取,输入、输出后面跟着字符串,该字符串可以被当作 Logstash 的配置(如果是空,则默认使用 stdin 作为输入,stdout 作为输出)。
-t:测试配置文件是否正确,然后退出。
4.1 定义输入和输出流(基本测试)

logstash -e 'input { stdin{} } output { stdout{} }'是一条运行 Logstash 的命令,用于快速搭建一个简单的数据处理管道。以下是对此命令的中文解释:
logstash: 这是命令本身,代表了 Elastic Stack 中用于收集、转换和输出日志和其他事件数据的工具。
-e(或--config-string): 这是一个命令行选项,用于指定一个简短的 Logstash 配置字符串。这种方式适用于快速测试或临时运行简单的 Logstash 管道,而不必编写完整的配置文件。
'input { stdin{} } output { stdout{} }': 这是传递给-e选项的配置字符串,定义了一个基本的 Logstash 数据处理管道,由输入(input)和输出(output)两个阶段组成:输入阶段 (
input { ... }):
stdin{}: 表示使用stdin输入插件。这个插件从标准输入(通常指键盘输入或管道传输)读取数据。当运行此命令时,您可以直接在终端中输入文本,这些文本将作为 Logstash 处理的数据源。输出阶段 (
output { ... }):
stdout{}: 表示使用stdout输出插件。这个插件将 Logstash 处理后的数据输出到标准输出(通常指终端屏幕)。在本例中,经过 Logstash 处理的任何数据都会直接显示在终端上。综上所述,这条命令启动了一个 Logstash 实例,其配置为从标准输入读取数据,经过内部处理(默认情况下,不做任何转换),然后将处理结果输出到标准输出。这是一个最基础的 Logstash 管道示例,常用于快速测试 Logstash 的功能或验证自定义过滤器规则。在实际使用中,Logstash 配置通常会更复杂,包含多个输入源、复杂的过滤规则以及多种输出目的地。
4.2 使用 rubydebug 输出详细格式显示,codec 为一种编解码器

logstash -e 'input { stdin{} } output { stdout{ codec=>rubydebug } }'
输入阶段 (
input { ... }):
stdin{}: 与之前相同,表示使用stdin输入插件,从标准输入读取数据。输出阶段 (
output { ... }):
stdout{ codec=>rubydebug }: 这里仍然使用stdout输出插件,但添加了codec参数并赋值为rubydebug。codec(编码器/解码器)在 Logstash 中用于定义数据的序列化和反序列化方式。具体到rubydebug编码器,它提供了详细的、易于阅读的输出格式,特别适用于调试。当使用rubydebug编码器时,Logstash 输出的数据将包含事件的元数据(如时间戳、事件类型等)以及事件的具体内容,以一种结构清晰、易于理解的方式展示。综上所述,这条命令启动了一个 Logstash 实例,其配置与之前相似,但输出阶段使用了
rubydebug编码器。这意味着从标准输入读取的数据在经过 Logstash 处理后,将被格式化为详细且易于阅读的形式输出到标准输出(终端屏幕)。这种配置尤其适用于开发和调试阶段,因为您可以直观地查看每个事件的完整结构和处理细节。在实际生产环境中,可能会选择更适合日志存储或分析需求的输出目的地和编码器,如将数据输出到 Elasticsearch 或使用更紧凑的 JSON 编码格式。
4.3 使用 Logstash 将信息写入 Elasticsearch 中
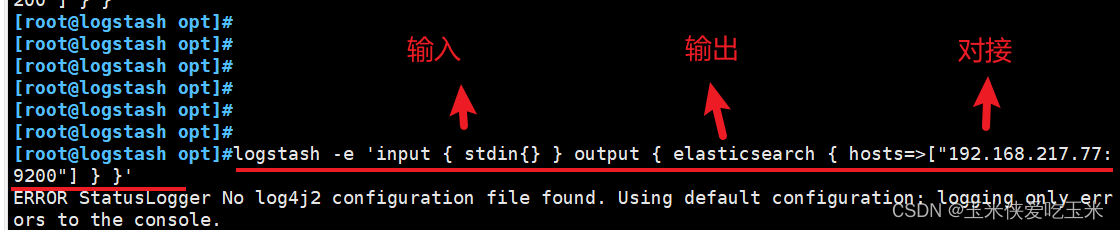
输入阶段 (
input { ... }):
stdin{}: 与之前相同,表示使用stdin输入插件,从标准输入读取数据。输出阶段 (
output { ... }):
Code
elasticsearch { hosts=>["192.168.217.77:9200"] }: 使用elasticsearch输出插件,将处理后的数据发送到指定的 Elasticsearch 服务器。这里的配置参数hosts指定了目标 Elasticsearch 服务器的地址和端口:1hosts => ["192.168.217.77:9200"]表示 Logstash 将连接到 IP 地址为
192.168.217.77、监听在端口9200的 Elasticsearch 实例。Logstash 会将从标准输入读取并处理过的数据作为事件发送到该 Elasticsearch 服务器,存储在相应的索引中。综上所述,这条命令启动了一个 Logstash 实例,其配置为从标准输入读取数据,经过内部处理(默认情况下,不做任何转换),然后将处理结果发送到 IP 地址为
192.168.217.77、端口为9200的 Elasticsearch 服务器。这种配置适用于将数据持久化存储到 Elasticsearch 中,便于后续进行日志搜索、分析和可视化。在实际使用中,可能还需要根据需求配置其他输出参数,如索引名、文档类型(对于旧版本 Elasticsearch)、映射模板等。
//结果不在标准输出显示,而是发送至 Elasticsearch 中,可浏览器访问 http://192.168.10.13:9100/ 查看索引信息和数据浏览。
5,定义 logstash配置文件
5.1, logstash配置文件组成
Logstash 配置文件基本由三部分组成:input、output 以及 filter(可选,根据需要选择使用)。
input:表示从数据源采集数据,常见的数据源如Kafka、日志文件等
filter:表示数据处理层,包括对数据进行格式化处理、数据类型转换、数据过滤等,支持正则表达式
output:表示将Logstash收集的数据经由过滤器处理之后输出到Elasticsearch。
5.2 logstash配置文件 语法
#格式如下:
input {...}
filter {...}
output {...}
#在每个部分中,也可以指定多个访问方式。例如,若要指定两个日志来源文件,则格式如下:
input {
file { path =>"/var/log/messages" type =>"syslog"}
file { path =>"/var/log/httpd/access.log" type =>"apache"}
}
5.3 修改 Logstash 配置文件
#修改 Logstash 配置文件,让其收集系统日志/var/log/messages,并将其输出到 elasticsearch 中。
首先给httpd 的日志加 可读的权限

写 子配置文件

子配置文件如下:

input {
file{
path =>"/var/log/messages" #指定要收集的日志的位置
type =>"system" #自定义日志类型标识
start_position =>"beginning" #表示从开始处收集
}
}
output {
elasticsearch { #输出到 elasticsearch
hosts => ["192.168.217.77:9200"] #指定 elasticsearch 服务器的地址和端口
index =>"system-%{+YYYY.MM.dd}" #指定输出到 elasticsearch 的索引格式
}
}
重启 systemctl restart logstash

浏览器访问 http://192.168.217.77:9100/ 查看索引信息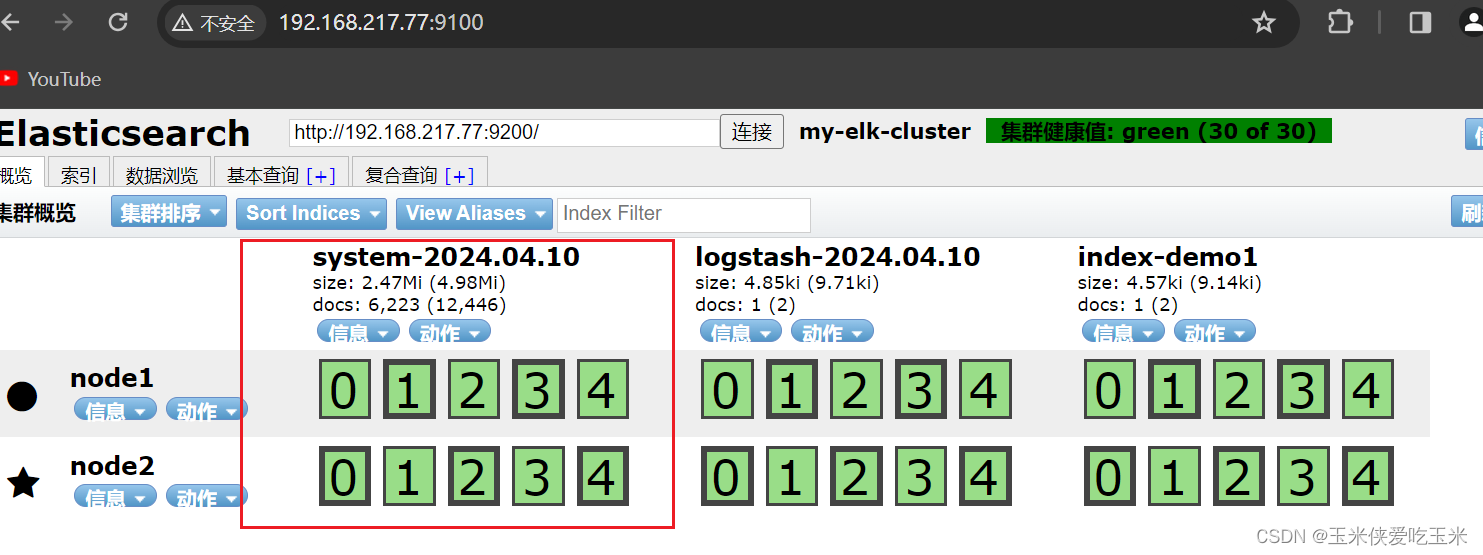
四 ELK Kiabana 部署(在 Node1 节点上操作)
1,安装kiabana

2, 修改配置文件
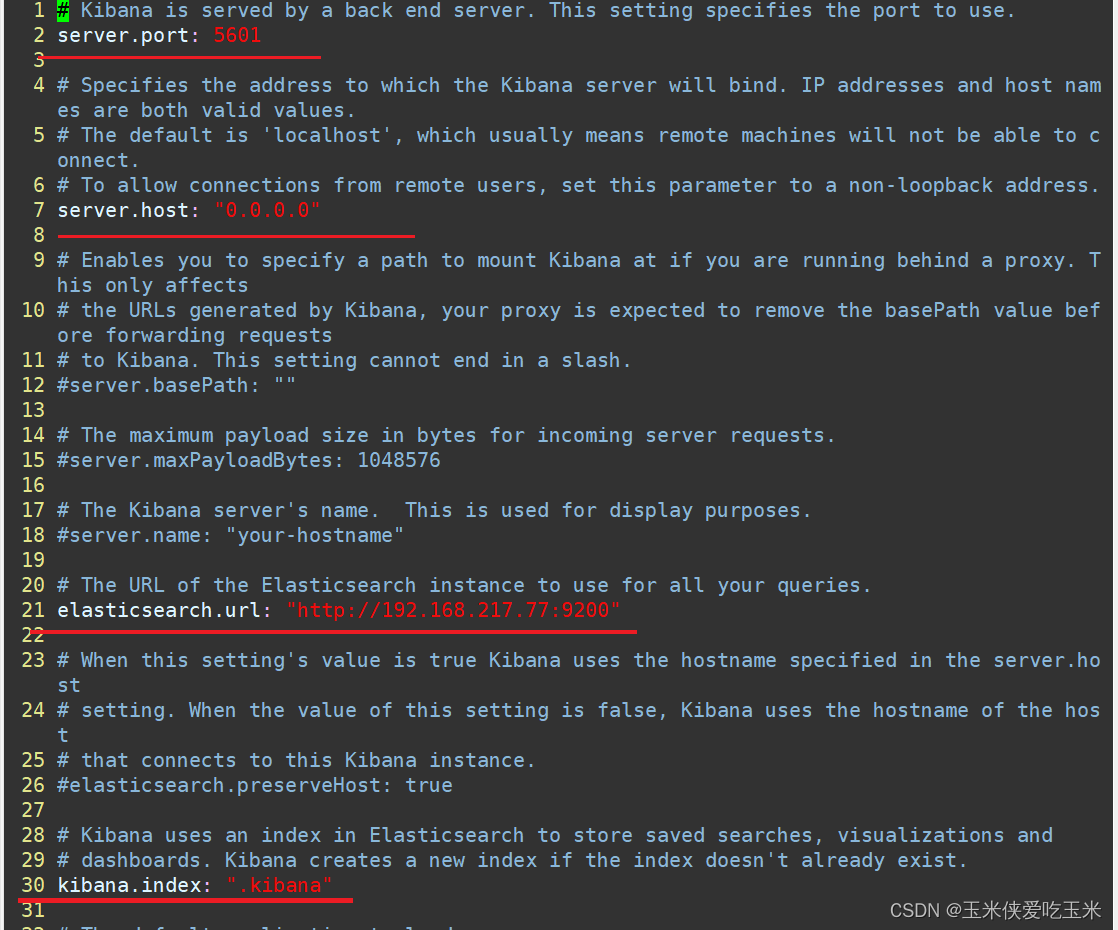
代码如下:
vim /etc/kibana/kibana.yml
--2--取消注释,Kiabana 服务的默认监听端口为5601
server.port: 5601
--7--取消注释,设置 Kiabana 的监听地址,0.0.0.0代表所有地址
server.host: "0.0.0.0"
--21--取消注释,设置和 Elasticsearch 建立连接的地址和端口
elasticsearch.url: "http://192.168.217.77:9200"
--30--取消注释,设置在 elasticsearch 中添加.kibana索引
kibana.index: ".kibana"
3,启动 Kibana 服务

4,验证 Kibana
浏览器访问 http://192.168.217.77:5601
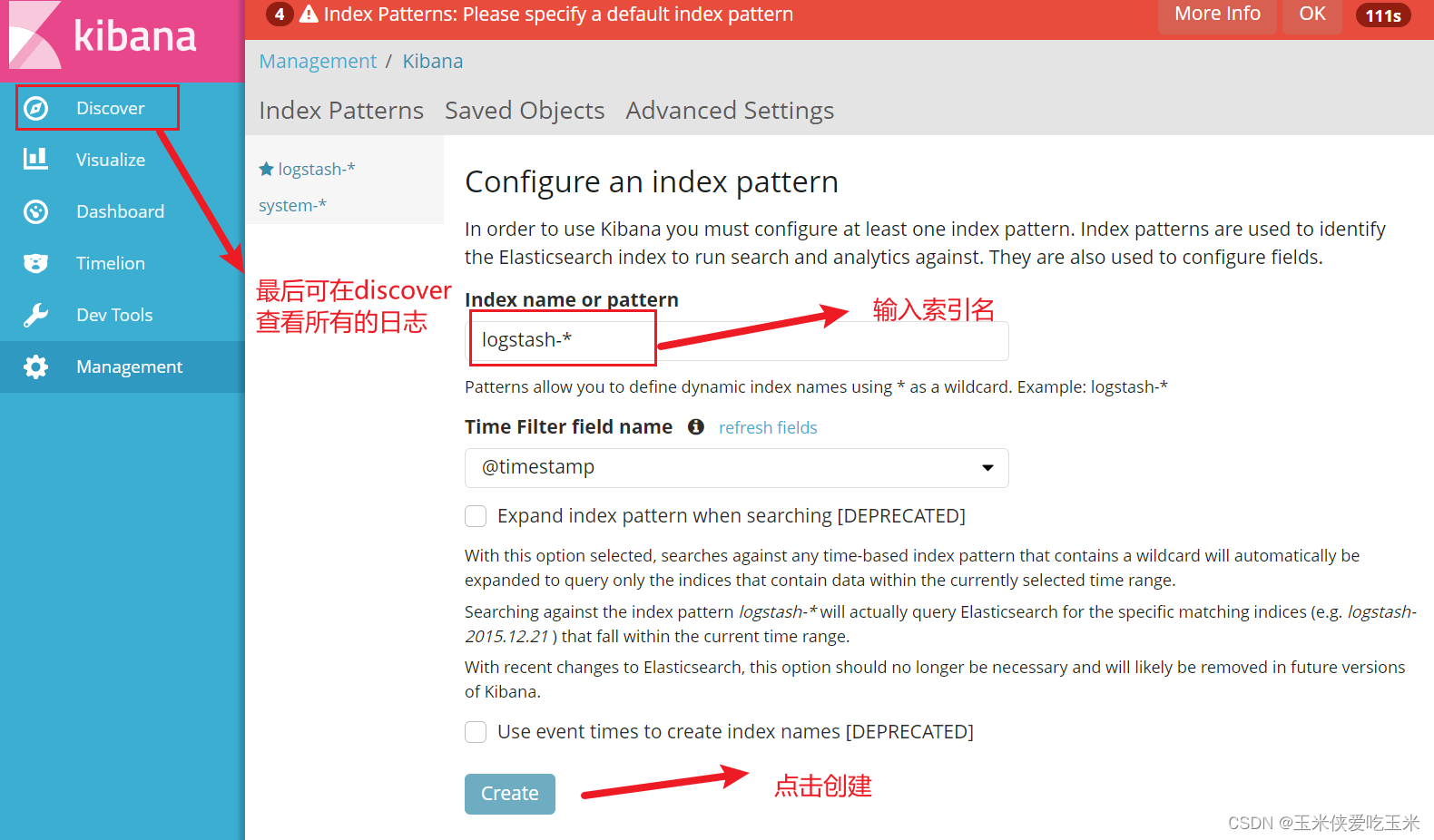
第一次登录需要添加一个 Elasticsearch 索引:
具体方法:
单击 “create” 按钮创建,单击 “Discover” 按钮可查看图表信息及日志信息。
数据展示可以分类显示,在“Available Fields”中的“host”,然后单击 “add”按钮,可以看到按照“host”筛选后的结果
点击创建索引

输入对应的索引,注意要es 机器上有的! kibana 只是显示es机器上有的
查看索引
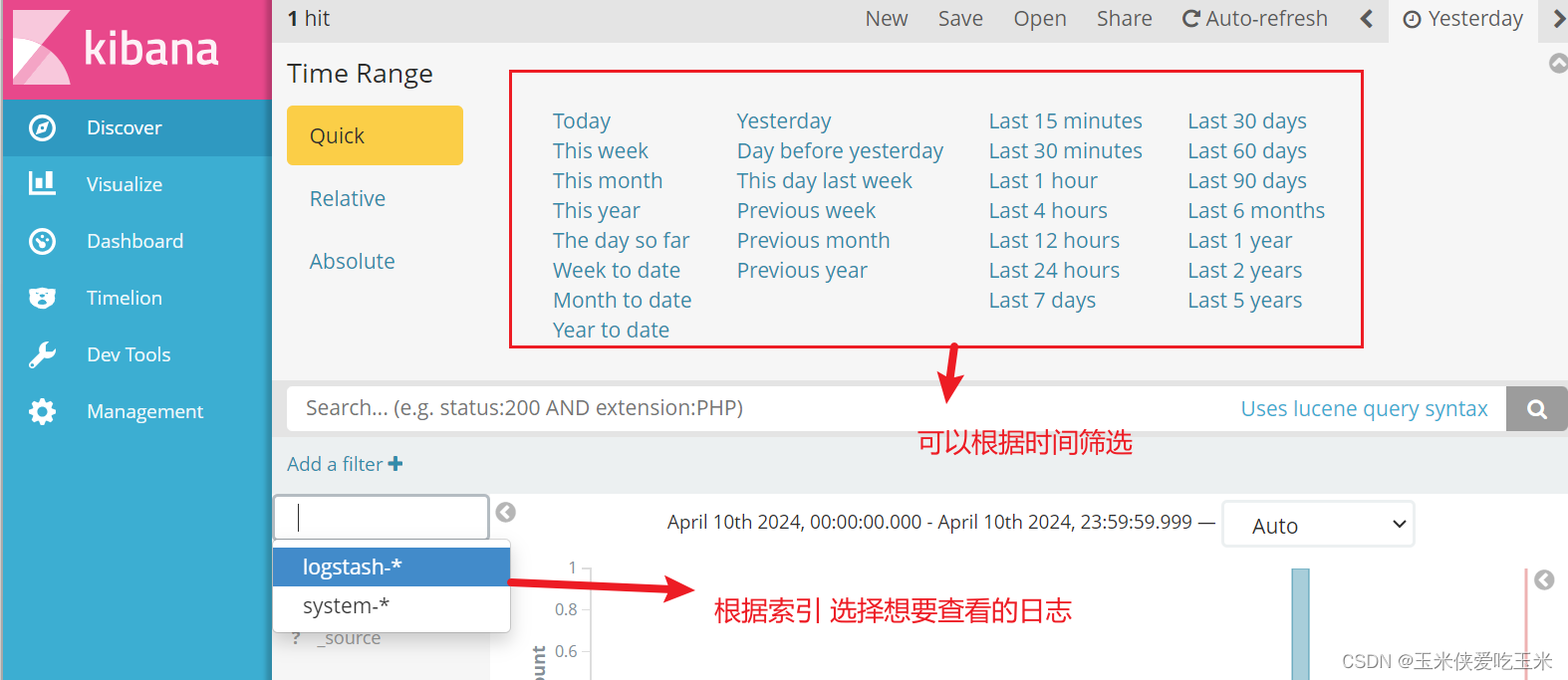
五 搭建一台完整的elk
即有logstash 搜集httpd的 日志,输出到两台es 机器上,最后通过kiabana 人性化显示
1,在logstash节点(99机器)写子配置文件
目的:将 Apache 服务器的日志(访问的、错误的)添加到 Elasticsearch 并通过 Kibana 显示

代码如下:
input {
file{
path => "/etc/httpd/logs/access_log"
type => "access"
start_position => "beginning"
}
file{
path => "/etc/httpd/logs/error_log"
type => "error"
start_position => "beginning"
}
}
output {
if [type] == "access" {
elasticsearch {
hosts => ["192.168.217.77:9200"]
index => "apache_access-%{+YYYY.MM.dd}"
}
}
if [type] == "error" {
elasticsearch {
hosts => ["192.168.217.77:9200"]
index => "apache_error-%{+YYYY.MM.dd}"
}
}
}
2,绝对路径启动logstash -f 指定配置文件
/usr/share/logstash/bin/logstash -f apache_log.conf
3,验证elk 框架是否成功
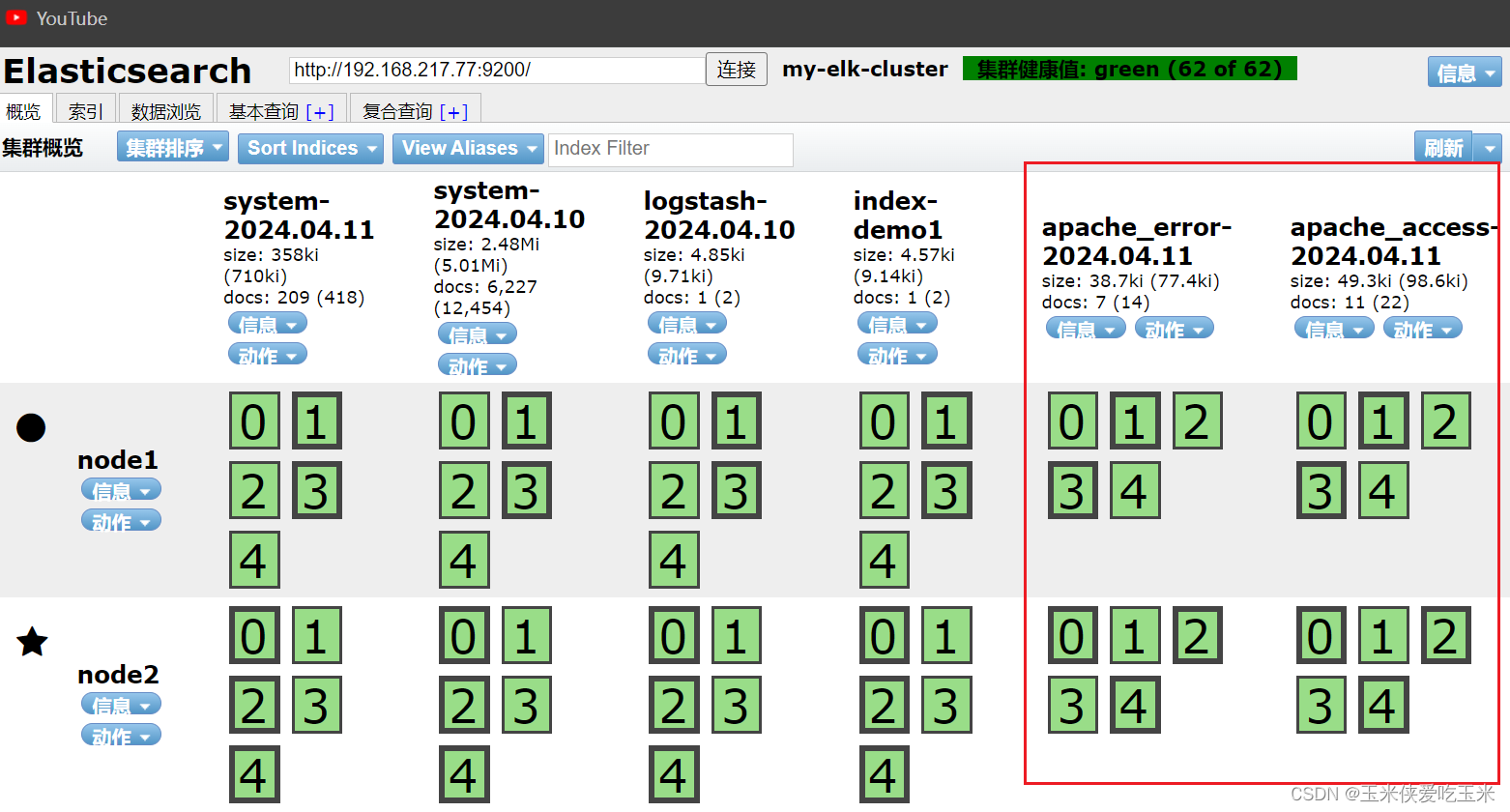
首先浏览器访问 http://192.168.217.77:9100 查看索引是否创建
即es机器上 是否有httpd的日志 logstash是否把日志传给es节点
因为es 节点没有的话, 你kiabana 也看不到
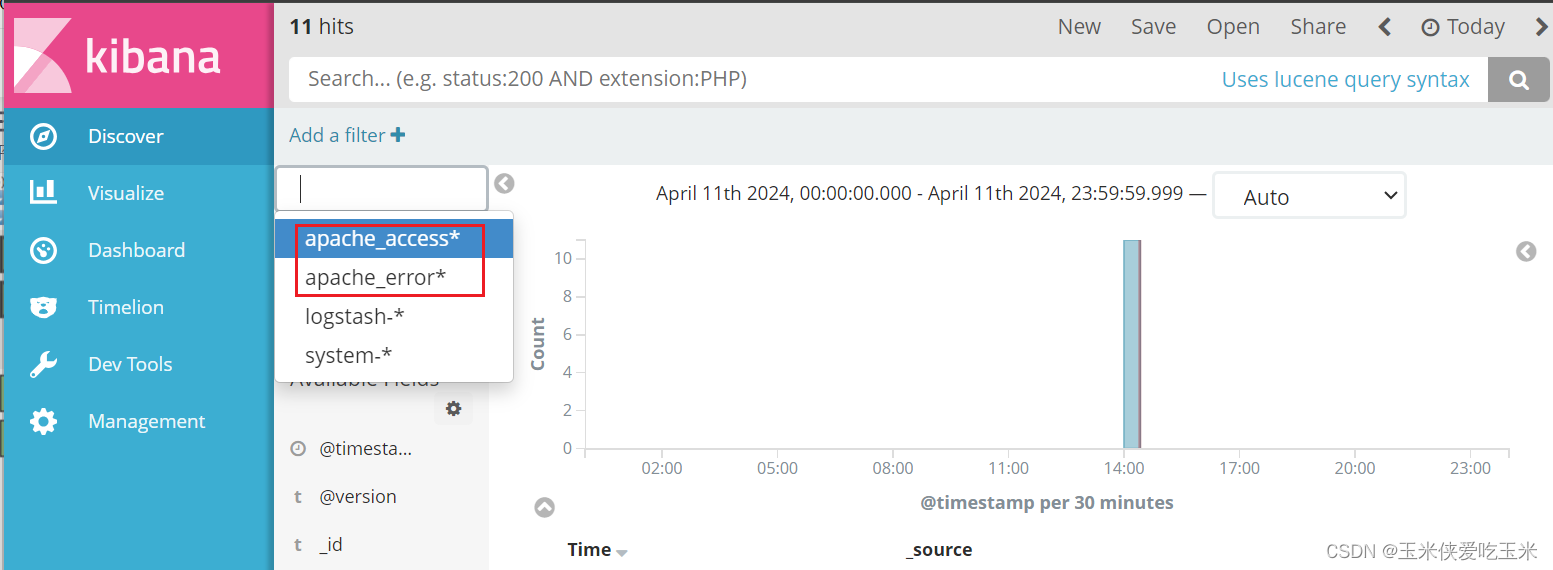
再去浏览器访问 http://192.168.217.77:5601 登录 Kibana,单击“Create Index Pattern”按钮添加索引, 在索引名中输入之前配置的 Output 前缀 apache_access-*,并单击“Create”按钮。在用相同的方法添加 apache_error-*索引。
选择“Discover”选项卡,在中间下拉列表中选择刚添加的 apache_access-* 、apache_error-* 索引, 可以查看相应的图表及日志信息。
六 总结
1,ELK日志分析系统
一套基于Elasticsearch、Logstash、Kibana三个开源的日志收集、存储、检索和可视化的解决方案
elk可以帮助用户快速定位和分析应用程序的故障,监控应用程序的性能和安全性,以及提供丰富的数据分析和展示功能。
2,Elasticsearch
Elasticsearch 是一个分布式和搜索和分析引擎,它可以对各种类型的数据进行近实时的索引和查询,支持高可用和水平扩展性
3, logstash
logstash:是一个数据处理管道,它可以从多个来源采集数据,对数据进行过滤、转换和增强,然后将数据发送到Easticsearch或者其他的目的地
4,Kibana
Kibana:是一个针对Elasticsearch的数据可视化平台,它可以通过各种图表、仪表盘和地图来展示和探索Elasticsearch中的数据
智能推荐
python编码问题之encode、decode、codecs模块_python中encode在什么模块-程序员宅基地
文章浏览阅读2.1k次。原文链接先说说编解码问题编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。 Eg:str1.decode('gb2312') #将gb2312编码的字符串转换成unicode编码str2.encode('gb2312') #将unicode编码..._python中encode在什么模块
Java数据流-程序员宅基地
文章浏览阅读949次,点赞21次,收藏15次。本文介绍了Java中的数据输入流(DataInputStream)和数据输出流(DataOutputStream)的使用方法。
ie浏览器无法兼容的问题汇总_ie 浏览器 newdate-程序员宅基地
文章浏览阅读111次。ie无法兼容_ie 浏览器 newdate
想用K8s,还得先会Docker吗?其实完全没必要-程序员宅基地
文章浏览阅读239次。这篇文章把 Docker 和 K8s 的关系给大家做了一个解答,希望还在迟疑自己现有的知识储备能不能直接学 K8s 的,赶紧行动起来,K8s 是典型的入门有点难,后面越用越香。
ADI中文手册获取方法_adi 如何查看数据手册-程序员宅基地
文章浏览阅读561次。ADI中文手册获取方法_adi 如何查看数据手册
React 分页-程序员宅基地
文章浏览阅读1k次,点赞4次,收藏3次。React 获取接口数据实现分页效果以拼多多接口为例实现思路加载前 加载动画加载后 判断有内容的时候 无内容的时候用到的知识点1、动画效果(用在加载前,加载之后就隐藏或关闭,用开关效果即可)2、axios请求3、map渲染页面4、分页插件(antd)代码实现import React, { Component } from 'react';//引入axiosimport axios from 'axios';//引入antd插件import { Pagination }_react 分页
随便推点
关于使用CryPtopp库进行RSA签名与验签的一些说明_cryptopp 签名-程序员宅基地
文章浏览阅读449次,点赞9次,收藏7次。这个变量与验签过程中的SignatureVerificationFilter::PUT_MESSAGE这个宏是对应的,SignatureVerificationFilter::PUT_MESSAGE,如果在签名过程中putMessage设置为true,则在验签过程中需要添加SignatureVerificationFilter::PUT_MESSAGE。项目中使用到了CryPtopp库进行RSA签名与验签,但是在使用过程中反复提示无效的数字签名。否则就会出现文章开头出现的数字签名无效。_cryptopp 签名
新闻稿的写作格式_新闻稿时间应该放在什么位置-程序员宅基地
文章浏览阅读848次。新闻稿是新闻从业者经常使用的一种文体,它的格式与内容都有着一定的规范。本文将从新闻稿的格式和范文两个方面进行介绍,以帮助读者更好地了解新闻稿的写作_新闻稿时间应该放在什么位置
Java中的转换器设计模式_java转换器模式-程序员宅基地
文章浏览阅读1.7k次。Java中的转换器设计模式 在这篇文章中,我们将讨论 Java / J2EE项目中最常用的 Converter Design Pattern。由于Java8 功能不仅提供了相应类型之间的通用双向转换方式,而且还提供了转换相同类型对象集合的常用方法,从而将样板代码减少到绝对最小值。我们使用Java8 功能编写了..._java转换器模式
应用k8s入门-程序员宅基地
文章浏览阅读150次。1,kubectl run创建pods[root@master ~]# kubectl run nginx-deploy --image=nginx:1.14-alpine --port=80 --replicas=1[root@master ~]# kubectl get podsNAME READY STATUS REST...
PAT菜鸡进化史_乙级_1003_1003 pat乙级 最优-程序员宅基地
文章浏览阅读128次。PAT菜鸡进化史_乙级_1003“答案正确”是自动判题系统给出的最令人欢喜的回复。本题属于 PAT 的“答案正确”大派送 —— 只要读入的字符串满足下列条件,系统就输出“答案正确”,否则输出“答案错误”。得到“答案正确”的条件是: 1. 字符串中必须仅有 P、 A、 T这三种字符,不可以包含其它字符; 2. 任意形如 xPATx 的字符串都可以获得“答案正确”,其中 x 或者是空字符串,或..._1003 pat乙级 最优
CH340与Android串口通信_340串口小板 安卓给安卓发指令-程序员宅基地
文章浏览阅读5.6k次。CH340与Android串口通信为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio移植的具体步骤CH340串口通信驱动函数通信过程中重难点还存在的问题为何要将CH340的ATD+Eclipse上的安卓工程移植到AndroidStudio为了在这个工程基础上进行改动,验证串口的数据和配置串口的参数,我首先在Eclipse上配置了安卓开发环境,注意在配置环境是..._340串口小板 安卓给安卓发指令