技术标签: 算法
import requests
from bs4 import BeautifulSoup
from pandas.core.frame import DataFrame
import re
import time
class Graduate:
def __init__(self, province, category):
self.head = {
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKi"
"t/537.36 (KHTML, like Gecko) Chrome/64.0.3282.186 Safari/537.36"
}
self.data = []
self.province = province
self.category = category
def get_list_fun(self, url, name):
"""获取提交表单代码"""
response = requests.get(url, headers=self.head)
province = response.json()
with open("{}.txt".format(name), "w") as f:
for x in province:
f.write(str(x))
f.write("\n")
def get_list(self):
"""
分别获取省,学科门类,专业编号数据
写入txt文件
"""
self.get_list_fun("http://yz.chsi.com.cn/zsml/pages/getSs.jsp", "province")
self.get_list_fun('http://yz.chsi.com.cn/zsml/pages/getMl.jsp', "category")
self.get_list_fun('http://yz.chsi.com.cn/zsml/pages/getZy.jsp', 'major')
def get_school_url(self):
"""
输入省份,
发送post请求,获取数据
提取数据
必填省份,学科门类,专业可选填
返回学校网址
"""
url = "http://yz.chsi.com.cn/zsml/queryAction.do"
data = {
"ssdm": self.province,
"yjxkdm": self.category,
}
response = requests.post(url, data=data, headers=self.head)
html = response.text
reg = re.compile(r'(<tr>.*? </tr>)', re.S)
content = re.findall(reg, html)
schools_url = re.findall('<a href="(.*?)" target="_blank">.*?</a>',str(content))
return schools_url
def get_college_data(self, url):
"""返回一个学校所有学院数据"""
response = requests.get(url, headers=self.head)
html = response.text
colleges_url = re.findall('<td class="ch-table-center"><a href="(.*?)" target="_blank">查看</a>',html)
return colleges_url
def get_final_data(self, url):
"""输出一个学校一个学院一个专业的数据"""
temp = []
response = requests.get(url, headers=self.head)
html = response.text
soup = BeautifulSoup(html, features='lxml')
summary = soup.find_all('td',{"class":"zsml-summary"})
for x in summary:
temp.append(x.get_text())
self.data.append(temp)
def get_schools_data(self):
"""获取所有学校的数据"""
url = "http://yz.chsi.com.cn"
schools_url = self.get_school_url()
amount = len(schools_url)
i = 0
for school_url in schools_url:
i +=1
url_ = url + school_url
# 找到一个学校对应所有满足学院网址
colleges_url = self.get_college_data(url_)
print("已完成第"+str(i)+"/"+ str(amount)+ "学院爬取")
time.sleep(1)
for college_url in colleges_url:
_url = url + college_url
self.get_final_data(_url)
def get_data_frame(self):
"""将列表形数据转化为数据框格式"""
data = DataFrame(self.data)
data.to_csv("查询招生信息.csv", encoding="utf_8_sig")
if __name__ == '__main__':
province = input("请输入查询学校省份编号:")
category = input("请输入查询专业代码:")
#province = "11"
#category = "0812"
spyder = Graduate(province, category)
spyder.get_schools_data()
spyder.get_data_frame()文章浏览阅读296次。题目:一张名为workersalary的表,要求查询出全部信息,并且salary最高的三个人按升序排列在结果的最开头,其余的人按原有顺序排列。这个sql如何写?解答:(1)题意理解假如原先的表是这样的namesalaryLiuYi2000ChenEr1000ZhangSan5000LiSi4000WangWu8000ZhaoLiu6000SunQi7000ZhouBa3000题目要求变成这样nam..._sql面试必会6题经典oracle必问的面试题
文章浏览阅读1.1k次,点赞8次,收藏9次。有关LoRA模型的原理_下面哪个参数用来控制lora适配器的矩阵大小
文章浏览阅读241次。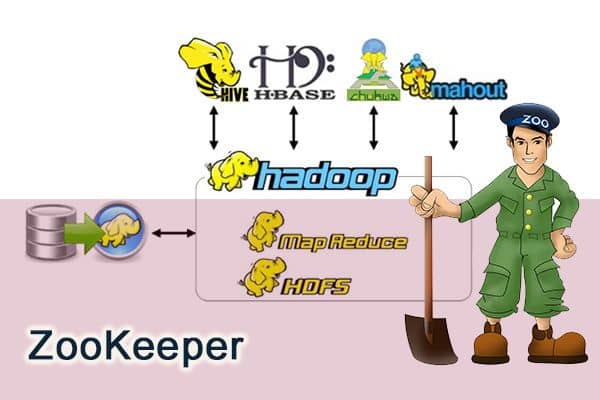## 前言相信大家对 ZooKeeper 应该不算陌生。但是你真的了解 ZooKeeper 是个什么东西吗?如果别人/面试官让你给他讲讲 ZooKeeper 是个什么东西,你能回答到什么地步呢?我本人曾经使用过 ZooKeeper 作为...
文章浏览阅读7.5k次,点赞16次,收藏62次。句子在上面简单句五种句型句中起名词作用,充当主语、宾语、表语和同位语等的各种从句,统称为名词性从句。c. 表变化:become, grow, turn, go, get, fall;b. 表感官:feel, smell, sound, taste, look;d. 表状态:remain, keep, hold, stay, seem.宾语是谓语动词动作的承受者。并列句中的各个简单句彼此独立,互不依从,但它们表达的意思之间有一定的关系。a. be 动词,am, is, are, was, were;_英语成分 do oc
文章浏览阅读485次。在进行数据库备份导入的时候遇到如下问题:IMP-00003: ORACLE error 439 encounteredORA-00439: feature not enabled: Partitioning查询v$option视..._imp-00003: oracle error 439 encountered ora-00439: feature not enabled: part
文章浏览阅读355次。使用adb 命令安装1 打开cmd 命令 win+r 输入cmd 命令 打开控制面板输入adb install 然后把把apk 拖拽进去然后回车即可 安装2 adb 卸载apk输入adb uninstall + 包名 即可。。..._安卓安装包绑设备
文章浏览阅读65次。http://forums.sdn.sap.com/thread.jspa?tstart=0&threadID=798957&messageID=5120111 ..._datasource的enhancement
文章浏览阅读1.6w次,点赞39次,收藏168次。深入理解Java虚拟机:JVM高级特性与最佳实践(第3版)— — 读书笔记_深入理解java虚拟机 第几版
文章浏览阅读1.4k次。vue这块我就不说了,直接讲openlayers。1.openlayers是什么?Openlayers是一个专为Web GIS客户端开发提供的JavaScript类库包,用于实现标准格式发布的地图访问。Openlayers支持的地图来源包括Google Maps、Yahoo、Map、微软Virtual Earth、天地图等,用户还可以用简单的图片地图作为背景,与其他的图层在Openlayers中进行叠加,在这一方面OpenLayers提供了非常多的选择。除此之外,OpenLayers实现访问地理空间_vue openlayers 某个省的地图
文章浏览阅读94次。《计算机组成原理》作业(一)一、CPU:Central Processing Unit 中央处理单元 执行存放在主存储器中的程序即机器指令.CPU是由控制器和运算器.PC:Personal Computer 个人电脑 能独立运行、完成特定功能的个人计算机 IR:Immediate Rendering 直接渲染CU:本文来自: 疯狂英语([url]http://doc..._北师大 计算机组成
文章浏览阅读5k次,点赞6次,收藏23次。微信小程序创建表格今天小编遇到了这样一个需求,用户想要列表信息,找了好多地方,才发现微信没有H5中的table标签,所以自己画了一个表格。发现效果还不错,分享给大家。以下是我的效果图(内容仅为参考):以下是这个样式的wxml代码:<view class="table" > <view class="tab_th"> <v..._微信小程序 根据日期生成表格
文章浏览阅读225次。Python爬虫第五课:BeautifulSoup库的使用上一篇文章的正则,其实对很多人来说用起来是不方便的,加上需要记很多规则,所以用起来不是特别熟练,而这节我们提到的beautifulsoup就是一个非常强大的工具,爬虫利器。beautifulSoup “美味的汤,绿色的浓汤”一个灵活又方便的网页解析库,处理高效,支持多种解析器。利用它就不用编写正则表达式也能方便的实现网页信息的抓取快速使用通过下面的一个例子,对bs4有个简单的了解,以及看一下它的强大之处:复制代码from bs4 im