SHAP: 在我眼里,没有黑箱_python对shap的计算只能针对大数值吗-程序员宅基地
技术标签: 零基础入门数据挖掘 SHAP 竞赛学习笔记 特征选择 Feature import
1. 写在前面
很多高级的机器学习模型(xgboost, lgb, cat)和神经网络模型, 它们相对于普通线性模型在进行预测时往往有更好的精度,但是同时也失去了线性模型的可解释性, 所以这些模型也往往看作是黑箱模型, 在2017年,Lundberg和Lee的论文提出了SHAP值这一广泛适用的方法用来解释各种模型(分类以及回归), 使得前面的黑箱模型变得可解释了,这篇文章主要整理一下SHAP的使用, 这个在特征选择的时候特别好用。
这次整理, 主要是在xgboost和lgb等树模型上的使用方式, 并且用一个真实的数据集进行演示, 详细的内容参考SHAP的原地址:https://github.com/slundberg/shap
2. 简单回忆特征选择
一般在机器学习中, 我们想看哪些特征对目标变量有重要作用的时候, 常用的有下面几种方式:
-
求相关性
这个往往可以判别出某些特征和目标变量之间是否有线性相关关系, 从而去看某些特征的重要性程度, 一般我们喜欢保留线性相关关系大的一些特征。 -
包裹式
这个说白了, 就是直接把数据放到像xgboost和lgb这种模型中训练, 训练完了之后, 再用feature importance可视化每个特征的重要性, 从而看哪些特征对最终的模型影响较大, But, 这种方式无法判断特征与最终预测结果的关系是如何的, 即不知道怎么影响的,待会给出真实例子来演示。 -
permutation importance
这是在kaggle比赛中学习到的一种特征筛选的方式, 所以也借机整理一下, 这个方式还是很不错的, 这个思路就是用所有的特征训练模型, 然后再在验证集上得到验证误差, 然后遍历每一个特征, 随机打乱这个特征的值, 再计算验证误差, 用后面的验证误差和前面的验证误差进行对比, 就可以看出该特征对于减少误差的贡献程度, 也就能看出特征的重要性。这里整理一下这种方式(思路):# 首先我们先建立一个模型, 然后写一个训练模型的函数 lgb_params = { 'boosting_type': 'gbdt', # Standart boosting type 'objective': 'mae', # Standart loss for RMSE 'metric': ['mae'], # as we will use rmse as metric "proxy" 'subsample': 0.8, 'subsample_freq': 1, 'learning_rate': 0.05, # 0.5 is "fast enough" for us 'num_leaves': 2**7-1, # We will need model only for fast check 'min_data_in_leaf': 2**8-1, # So we want it to train faster even with drop in generalization 'feature_fraction': 0.8, 'n_estimators': 5000, # We don't want to limit training (you can change 5000 to any big enough number) 'early_stopping_rounds': 30, # We will stop training almost immediately (if it stops improving) 'seed': 2020, 'verbose': -1, } def make_fast_test(sel_data): train_ready = sel_data[sel_data['time'] < pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_train = train_ready.drop(columns = ['TTI']) y_train = train_ready['TTI'] val_ready = sel_data[sel_data['time'] >= pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_val = val_ready.drop(columns = ['TTI']) y_val = val_ready['TTI'] train_data = lgb.Dataset(x_train, label=y_train) val_data = lgb.Dataset(x_val, label=y_val) estimator = lgb.train(lgb_params, train_data, valid_sets=[train_data, val_data], verbose_eval=500) return estimator # 调用函数建立训练好的模型 test_model = make_fast_test(sel_data) # 做一个验证集 features_columns = sel_data.drop(columns='time').columns.tolist() features_columns.remove('TTI') val_ready = val_ready = sel_data[sel_data['time'] >= pd.to_datetime('2019-12-10')].drop(columns = ['time']) x_val = val_ready.drop(columns = ['TTI']) y_val = val_ready['TTI'] pre = test_model.predict(x_val) base_score = mean_absolute_error(pre, y_val) print('startscore: ', base_score) # 这里会得到模型在验证集上的分数 # 接下来就是尝试筛选特征,对于每个特征, # 把那一列的值进行随机打乱, 然后再用之前的模型进行预测, 得到验证误差 # 对比这俩误差的不同, 就会发现每个特征对于模型来说,是有利于模型表现好还是表现差 for col in features_columns: temp_df = x_val.copy() temp_df[col] = np.random.permutation(temp_df[col].values) pre = test_model.predict(temp_df) cur_score = mean_absolute_error(pre, y_val) print(col, np.round(cur_score-base_score, 4))这个方式,其实就能够既判断出特征的重要性, 也能判断出特征是怎么影响模型的。
而有了SHAP之后, 貌似是这一切变得更加简单。
下面通过一个真实的例子, 来看一下之前的Feature importance和SHAP的具体使用, 这里用的数据集是一个数据竞赛的数据集
3. Feature importance VS SHAP
3.1 Feature importance
在SHAP被广泛使用之前,我们通常用feature importance或者partial dependence plot来解释xgboost等机器学习模型。 feature importance是用来衡量数据集中每个特征的重要性。每个特征对于提升整个模型的预测能力的贡献程度就是特征的重要性。
下面根据这个案例来看看, 先导入包和数据, 然后训练xgb和lgb。
import xgboost as xgb
import lightgbm as lgb
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
plt.style.use('seaborn')
# 读取数据
data = pd.read_csv('data/train.csv', index_col=0)
# 获得球员的年龄
today = pd.to_datetime('2018-01-01')
data['birth_date'] = pd.to_datetime(data['birth_date'])
data['age'] = np.round((today-data['birth_date']).apply(lambda x:x.days) / 365., 1)
# 选择部分特征举例
# 特征依次为身高(厘米)、潜力、速度、射门、传球、带球、防守、体格、国际知名度、年龄
cols = ['height_cm', 'potential', 'pac', 'sho', 'pas', 'dri', 'def', 'phy',
'international_reputation', 'age']
model1 = xgb.XGBRegressor(max_depth=4, learning_rate=0.05, n_estimators=150)
model2 = lgb.LGBMRegressor()
model1.fit(data[cols], data['y'])
model2.fit(data[cols], data['y'])
下面我们可以画出每个特征的重要性程度:
# 获取feature importance
plt.figure(figsize=(20, 10))
plt.subplot(1, 2, 1)
plt.bar(range(len(cols)), model1.feature_importances_)
plt.xticks(range(len(cols)), cols, rotation=-45, fontsize=14)
plt.title('Xgb Feature importance', fontsize=14)
plt.subplot(1, 2, 2)
plt.bar(range(len(cols)), model2.feature_importances_)
plt.xticks(range(len(cols)), cols, rotation=-45, fontsize=14)
plt.title('Lgb Feature importance', fontsize=14)
plt.show()
结果如下:
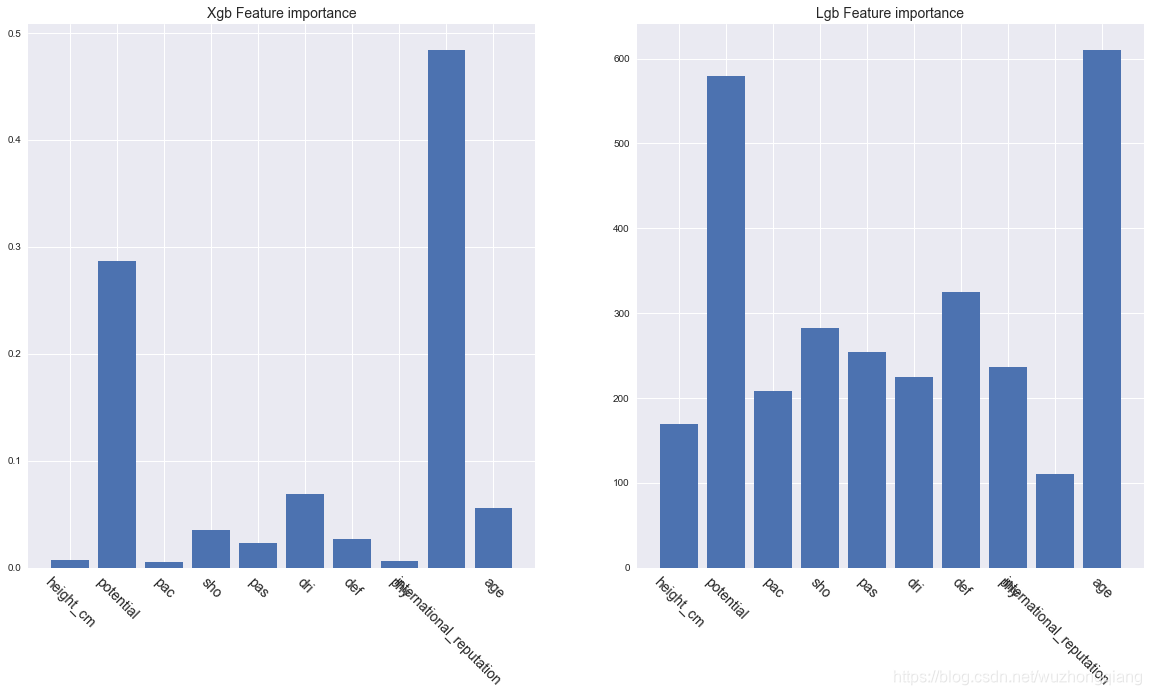
对于xgboost来说,我们可以看出国际知名度、潜力和年龄是影响球员身价最重要的三个因素。而LGB来说, 潜力和年龄很重要, 但是这些因素和身价是正相关、负相关还是其他更复杂的相关性,我们无法从上图得知。我们也无法解读每个特征对每个个体的预测值的影响。
3.2 SHAP value
SHAP的名称来源于SHapley Additive exPlanation。
Shapley value起源于合作博弈论。比如说甲乙丙丁四个工人一起打工,甲和乙完成了价值100元的工件,甲、乙、丙完成了价值120元的工件,乙、丙、丁完成了价值150元的工件,甲、丁完成了价值90元的工件,那么该如何公平、合理地分配这四个人的工钱呢?Shapley提出了一个合理的计算方法(有兴趣地可以查看原论文),我们称每个参与者分配到的数额为Shapley value。
SHAP是由Shapley value启发的可加性解释模型。对于每个预测样本,模型都产生一个预测值,SHAP value就是该样本中每个特征所分配到的数值。假设第 i i i个样本为 x i x_i xi, 第 i i i个样本的第 j j j个特征为 x i j x_{ij} xij, 模型对于第 i i i个样本的预测值为 y i y_i yi, 整个模型的基线(通常是所有样本目标变量的均值)为 y b a s e y_{base} ybase, 那么SHAP value服从以下等式。
y i = y b a s e + f ( x i 1 ) + f ( x i 2 ) + f ( x i 3 ) + . . . . + f ( x i k ) y_i = y_{base}+f(x_{i1})+f(x_{i2})+f(x_{i3})+....+f(x_{ik}) yi=ybase+f(xi1)+f(xi2)+f(xi3)+....+f(xik)
其中, f ( x i k ) f(x_{ik}) f(xik)为 x i k x_{ik} xik的SHAP值。 直观上看, f ( x i k ) f_(x_{ik}) f(xik)就是第 i i i个样本中第 k k k个特征对最终预测值 y i y_i yi的贡献值, 当 f ( x i k ) > 0 f_(x_{ik})>0 f(xik)>0, 说明该特征提升了预测值, 也是正向的作用, 反之, 说明该特征使得预测值降低, 有反作用。很明显可以看出,与前面的feature importance相比,SHAP value最大的优势是SHAP能对于反映出每一个样本中的特征的影响力,而且还表现出影响的正负性。
那么怎么用呢?
3.3 SHAP的python实现
Python中SHAP值的计算由shap这个package实现,可以通过pip install shap安装。
import shap
# 导入package, 就可以用shape获得一个解释器
explainer_xgb = shap.TreeExplainer(model1)
explainer_lgb = shap.TreeExplainer(model2)
# 获取训练集data各个样本各个特征的SHAP值
shape_values = explainer_lgb.shap_values(data[cols])
shape_values.shape # data中有10441个样本10个特征, 所以这里的SHAP值是每个样本每个特征的shap值
# 获得基线ybase
ybase_xgb = explainer_xgb.expected_value
ybase_lgb = explainer_lgb.expected_value
print(ybase_lgb, ybase_xgb) # 229.28876544209956 [229.1682549]
## 基线值等于训练集的目标变量的拟合值的均值
pred_xgb = model1.predict(data[cols])
pred_lgb = model2.predict(data[cols])
print(pred_lgb.mean(), pred_xgb.mean()) # 229.28876544209956 229.16826
3.3.1 单个样本的SHAP的值
可以随机检查某一个球员身价的预测值以及各个特征对其预测值的影响。
j = 30
player_explainer = pd.DataFrame()
player_explainer['feature'] = cols
player_explainer['feature_values'] = data[cols].iloc[j].values
player_explainer['shap_value'] = shape_values[j]
player_explainer
结果如下:

# 一个样本中各个特征SHAP的值的和加上基线值应该等于该样本的预测值
print(ybase_lgb+player_explainer['shap_value'].sum(), pred_lgb[j])
shap还提供了强大的数据可视化功能。
shap.initjs()
shap.force_plot(explainer_lgb.expected_value, shape_values[j], data[cols].iloc[j])
结果如下:

蓝色表示该特征的贡献是负数, 红色表示该特征的贡献是正数。
3.3.2 对特征的总体分析
除了能对单个样本的SHAP值进行可视化之外,还能对特征进行整体的可视化。
shap.summary_plot(shape_values, data[cols])
结果如下:

图中每一行代表一个特征,横坐标为SHAP值。一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。
我们可以直观地看出潜力potential是一个很重要的特征,而且基本上是与身价成正相关的。年龄age也会明显影响身价,蓝色点主要集中在SHAP小于0的区域,可见年纪小会降低身价估值,另一方面如果年纪很大,也会降低估值,甚至降低得更明显,因为age这一行最左端的点基本上都是红色的。
我们也可以把一个特征对目标变量影响程度的绝对值的均值作为这个特征的重要性。因为SHAP和feature_importance的计算方法不同,所以我们这里也得到了与前面不同的重要性排序。
shap.summary_plot(shape_values, data[cols], plot_type='bar')
结果如下:

3.3.3 部分依赖图
SHAP也提供了部分依赖图的功能,与传统的部分依赖图不同的是,这里纵坐标不是目标变量y的数值而是SHAP值。
shap.dependence_plot('age', shape_values, data[cols], interaction_index=None, show=False)
结果如下:

年纪大概呈现出金字塔分布,也就是25到32岁这个年纪对球员的身价是拉抬作用,小于25以及大于32岁的球员身价则会被年纪所累。
3.3.4 对多个变量的交互进行分析
可以多个变量的交互作用进行分析。
shap_interaction_values = shap.TreeExplainer(model1).shap_interaction_values(data[cols])
shap.summary_plot(shap_interaction_values, data[cols], max_display=4)
结果如下:

3.3.5 两个变量交互下的变量对目标值的影响
shap.dependence_plot('potential', shape_values, data[cols], interaction_index='international_reputation', show=False)
结果如下:

4. 小总
小总一下, SHAP在特征选择里面挺常用的, 让很多模型变得有了可解释性。当然, 也不仅适用于机器学习模型, 同样也适用于深度学习的一些模型, 这个具体的可以看下面的GitHub链接。
参考:
智能推荐
51单片机的中断系统_51单片机中断篇-程序员宅基地
文章浏览阅读3.3k次,点赞7次,收藏39次。CPU 执行现行程序的过程中,出现某些急需处理的异常情况或特殊请求,CPU暂时中止现行程序,而转去对异常情况或特殊请求进行处理,处理完毕后再返回现行程序断点处,继续执行原程序。void 函数名(void) interrupt n using m {中断函数内容 //尽量精简 }编译器会把该函数转化为中断函数,表示中断源编号为n,中断源对应一个中断入口地址,而中断入口地址的内容为跳转指令,转入本函数。using m用于指定本函数内部使用的工作寄存器组,m取值为0~3。该修饰符可省略,由编译器自动分配。_51单片机中断篇
oracle项目经验求职,网络工程师简历中的项目经验怎么写-程序员宅基地
文章浏览阅读396次。项目经验(案例一)项目时间:2009-10 - 2009-12项目名称:中驰别克信息化管理整改完善项目描述:项目介绍一,建立中驰别克硬件档案(PC,服务器,网络设备,办公设备等)二,建立中驰别克软件档案(每台PC安装的软件,财务,HR,OA,专用系统等)三,能过建立的档案对中驰别克信息化办公环境优化(合理使用ADSL宽带资源,对域进行调整,对文件服务器进行优化,对共享打印机进行调整)四,优化完成后..._网络工程师项目经历
LVS四层负载均衡集群-程序员宅基地
文章浏览阅读1k次,点赞31次,收藏30次。LVS:Linux Virtual Server,负载调度器,内核集成, 阿里的四层SLB(Server Load Balance)是基于LVS+keepalived实现。NATTUNDR优点端口转换WAN性能最好缺点性能瓶颈服务器支持隧道模式不支持跨网段真实服务器要求anyTunneling支持网络private(私网)LAN/WAN(私网/公网)LAN(私网)真实服务器数量High (100)High (100)真实服务器网关lvs内网地址。
「技术综述」一文道尽传统图像降噪方法_噪声很大的图片可以降噪吗-程序员宅基地
文章浏览阅读899次。https://www.toutiao.com/a6713171323893318151/作者 | 黄小邪/言有三编辑 | 黄小邪/言有三图像预处理算法的好坏直接关系到后续图像处理的效果,如图像分割、目标识别、边缘提取等,为了获取高质量的数字图像,很多时候都需要对图像进行降噪处理,尽可能的保持原始信息完整性(即主要特征)的同时,又能够去除信号中无用的信息。并且,降噪还引出了一..._噪声很大的图片可以降噪吗
Effective Java 【对于所有对象都通用的方法】第13条 谨慎地覆盖clone_为继承设计类有两种选择,但无论选择其中的-程序员宅基地
文章浏览阅读152次。目录谨慎地覆盖cloneCloneable接口并没有包含任何方法,那么它到底有什么作用呢?Object类中的clone()方法如何重写好一个clone()方法1.对于数组类型我可以采用clone()方法的递归2.如果对象是非数组,建议提供拷贝构造器(copy constructor)或者拷贝工厂(copy factory)3.如果为线程安全的类重写clone()方法4.如果为需要被继承的类重写clone()方法总结谨慎地覆盖cloneCloneable接口地目的是作为对象的一个mixin接口(详见第20_为继承设计类有两种选择,但无论选择其中的
毕业设计 基于协同过滤的电影推荐系统-程序员宅基地
文章浏览阅读958次,点赞21次,收藏24次。今天学长向大家分享一个毕业设计项目基于协同过滤的电影推荐系统项目运行效果:项目获取:https://gitee.com/assistant-a/project-sharing21世纪是信息化时代,随着信息技术和网络技术的发展,信息化已经渗透到人们日常生活的各个方面,人们可以随时随地浏览到海量信息,但是这些大量信息千差万别,需要费事费力的筛选、甄别自己喜欢或者感兴趣的数据。对网络电影服务来说,需要用到优秀的协同过滤推荐功能去辅助整个系统。系统基于Python技术,使用UML建模,采用Django框架组合进行设
随便推点
你想要的10G SFP+光模块大全都在这里-程序员宅基地
文章浏览阅读614次。10G SFP+光模块被广泛应用于10G以太网中,在下一代移动网络、固定接入网、城域网、以及数据中心等领域非常常见。下面易天光通信(ETU-LINK)就为大家一一盘点下10G SFP+光模块都有哪些吧。一、10G SFP+双纤光模块10G SFP+双纤光模块是一种常规的光模块,有两个LC光纤接口,传输距离最远可达100公里,常用的10G SFP+双纤光模块有10G SFP+ SR、10G SFP+ LR,其中10G SFP+ SR的传输距离为300米,10G SFP+ LR的传输距离为10公里。_10g sfp+
计算机毕业设计Node.js+Vue基于Web美食网站设计(程序+源码+LW+部署)_基于vue美食网站源码-程序员宅基地
文章浏览阅读239次。该项目含有源码、文档、程序、数据库、配套开发软件、软件安装教程。欢迎交流项目运行环境配置:项目技术:Express框架 + Node.js+ Vue 等等组成,B/S模式 +Vscode管理+前后端分离等等。环境需要1.运行环境:最好是Nodejs最新版,我们在这个版本上开发的。其他版本理论上也可以。2.开发环境:Vscode或HbuilderX都可以。推荐HbuilderX;3.mysql环境:建议是用5.7版本均可4.硬件环境:windows 7/8/10 1G内存以上;_基于vue美食网站源码
oldwain随便写@hexun-程序员宅基地
文章浏览阅读62次。oldwain随便写@hexun链接:http://oldwain.blog.hexun.com/ ...
渗透测试-SQL注入-SQLMap工具_sqlmap拖库-程序员宅基地
文章浏览阅读843次,点赞16次,收藏22次。用这个工具扫描其它网站时,要注意法律问题,同时也比较慢,所以我们以之前写的登录页面为例子扫描。_sqlmap拖库
origin三图合一_神教程:Origin也能玩转图片拼接组合排版-程序员宅基地
文章浏览阅读1.5w次,点赞5次,收藏38次。Origin也能玩转图片的拼接组合排版谭编(华南师范大学学报编辑部,广州 510631)通常,我们利用Origin软件能非常快捷地绘制出一张单独的绘图。但是,我们在论文的撰写过程中,经常需要将多种科学实验图片(电镜图、示意图、曲线图等)组合在一张图片中。大多数人都是采用PPT、Adobe Illustrator、CorelDraw等软件对多种不同类型的图进行拼接的。那么,利用Origin软件能否实..._origin怎么把三个图做到一张图上
51单片机智能电风扇控制系统proteus仿真设计( 仿真+程序+原理图+报告+讲解视频)_电风扇模拟控制系统设计-程序员宅基地
文章浏览阅读4.2k次,点赞4次,收藏51次。51单片机智能电风扇控制系统仿真设计( proteus仿真+程序+原理图+报告+讲解视频)仿真图proteus7.8及以上 程序编译器:keil 4/keil 5 编程语言:C语言 设计编号:S0042。_电风扇模拟控制系统设计