大模型PEFT技术原理(一):BitFit、Prefix Tuning、Prompt Tuning_peft中的主流技术方案-程序员宅基地
随着预训练模型的参数越来越大,尤其是175B参数大小的GPT3发布以来,让很多中小公司和个人研究员对于大模型的全量微调望而却步,近年来研究者们提出了各种各样的参数高效迁移学习方法(Parameter-efficient Transfer Learning),即固定住Pretrain Language model(PLM)的大部分参数,仅调整模型的一小部分参数来达到与全部参数的微调接近的效果(调整的可以是模型自有的参数,也可以是额外加入的一些参数)。本文将介绍一些常见的参数高效微调技术,比如:BitFit、Prefix Tuning、Prompt Tuning、P-Tuning、P-Tuning v2、Adapter Tuning及其变体、LoRA、AdaLoRA、QLoRA、MAM Adapter、UniPELT等。
1、BitFit
论文地址:https://aclanthology.org/2022.acl-short.1.pdf
代码地址:https://github.com/benzakenelad/BitFit
BitFIt只对模型的bias进行微调。在小规模-中等规模的训练数据上,BitFit的性能与全量微调的性能相当,甚至有可能超过,在大规模训练数据上,与其他fine-tuning方法也差不多。在大模型中bias存在Q,K,V,MLP,LayerNorm中,具体公式如下:
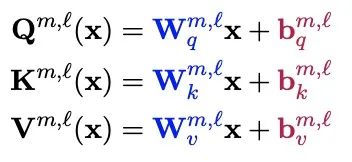
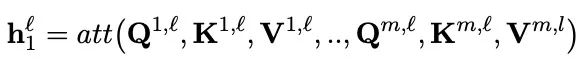
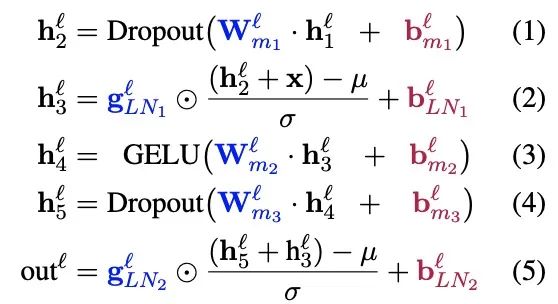
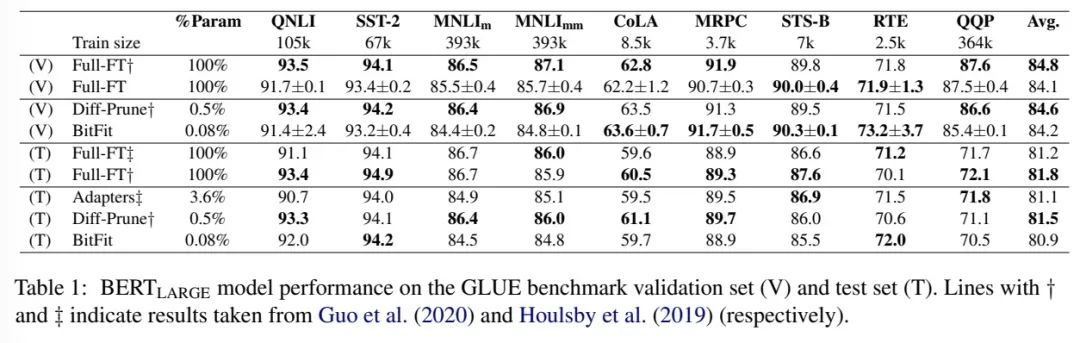
在Bert-Base/Bert-Large这种模型里,bias参数仅占模型全部参数量的0.08%~0.09%。但是通过在Bert-Large模型上基于GLUE数据集进行了 BitFit、Adapter和Diff-Pruning的效果对比发现,BitFit在参数量远小于Adapter、Diff-Pruning的情况下,效果与Adapter、Diff-Pruning想当,甚至在某些任务上略优于Adapter、Diff-Pruning。
通过Bitfit训练前后的参数对比,发现很多bias参数没有太多变化,例如跟计算key所涉及到的bias参数。发现其中计算query与中间MLP层的bias(将特征维度从N放大到4N的FFN层——将输入从768d转化为到3072d)变化最为明显,只更新这两类bias参数也能达到不错的效果,反之,固定其中任何一者,模型的效果都有较大损失。
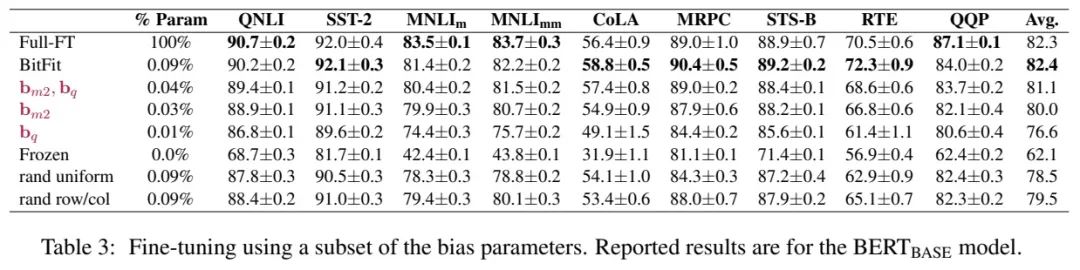
作者给出了Hugging Face与BitFit参数的映射关系表,如下所示:

2、Prefix Tuning
论文地址:https://arxiv.org/pdf/2101.00190.pdf
代码地址:https://github.com/XiangLi1999/PrefixTuning
prefix-tuning方法是一个轻量级的fine-tuning方法用于自然语言处理的生成任务。该方法可以保持预训练语言模型参数固定(frozen),而只需要在task-specific vector(称为prefix)上进行优化。即只需要少量(约0.1%)的优化参数,即可以在量和小量数据上达到不错的效果。
针对不同的模型结构,需要构造不同的Prefix。
-
针对自回归架构模型:在句子前面添加前缀,得到
z = [PREFIX; x; y],合适的上文能够在固定 LM 的情况下去引导生成下文(比如:GPT3的上下文学习)。 -
针对编码器-解码器架构模型:Encoder和Decoder都增加了前缀,得到
z = [PREFIX1; x; PREFIX2; y]。Encoder端增加前缀是为了引导输入部分的编码,Decoder 端增加前缀是为了引导后续token的生成。

如上图所示, 表示prefix indices序列,
表示prefix的长度。Prefix-tuning通过初始化可训练矩阵
(维度为
)来存储prefix参数:
training objective与Fine-tuning相同,但语言模型的参数 固定,仅仅prefix参数
是可训练参数。因此
是可训练的
的函数,当
时,
由
直接复制得到,对于
, 由于prefix activations始终在left context因此可以影响到
。
在实验上,直接更新 的参数会导致优化的不稳定以及表现上的极具下降。因此通过使用较小的矩阵
通过大型前馈神经网络(
)来reparametrize矩阵
:
其中, 和
在相同的行维度(也就是相同的prefix length), 但不同的列维度。当训练完成后,reparametrization参数被丢掉,仅仅
需要被保存下来。
实验中对比了Fine Tuning和Prefix Tuning在E2E、WebNLG和DART三个table-to-text任务上的效果:
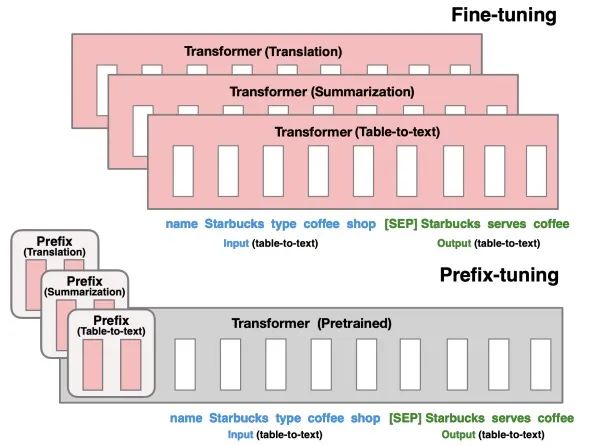
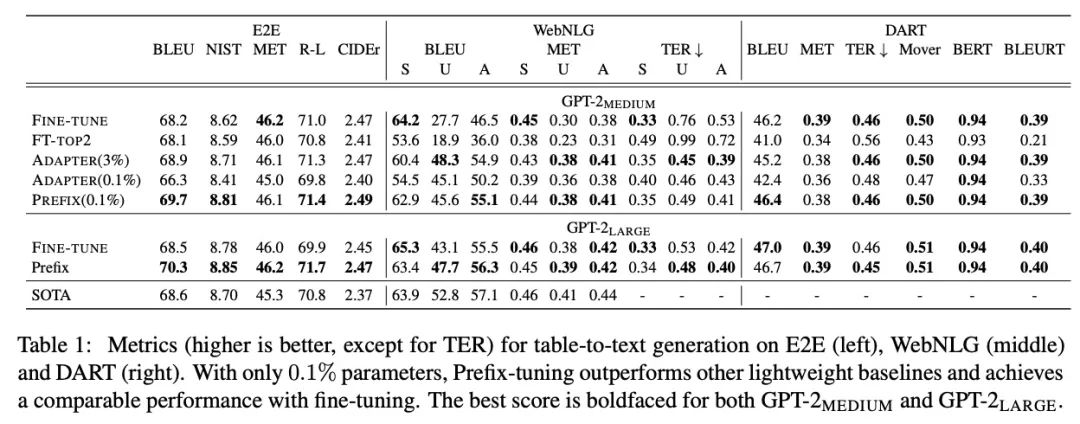
3、Prompt Tuning
论文地址:https://arxiv.org/pdf/2104.08691.pdf
代码地址:https://github.com/google-research/prompt-tuning
Prompt Tuning可以看作是Prefix Tuning的简化版本,面向NLU任务,进行了更全面的效果对比,并且在大模型上成功打平了LM微调的效果,它给每个任务定义了自己的Prompt,然后拼接到数据上作为输入,但只在输入层加入prompt tokens,并且不需要加入 MLP 进行调整来解决难训练的问题。通过反向传播更新参数来学习prompts,而不是人工设计prompts;同时冻结模型原始权重,只训练prompts参数,训练完以后,用同一个模型可以做多任务推理。
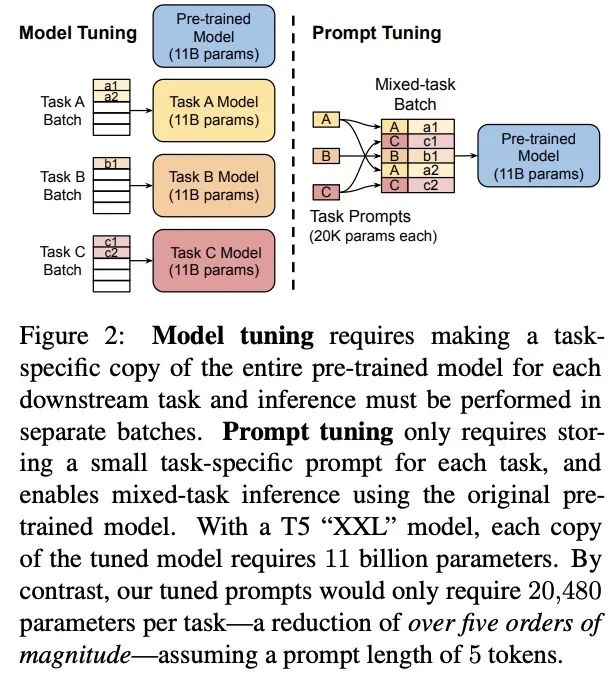
对比Prefix-Tunning,prompt-tuning的主要差异如下,
论文使用100个prefix token作为默认参数,大于以上prefix-tuning默认的10个token,不过差异在于prompt-Tunning只对输入层(Embedding)进行微调,而Prefix是对虚拟Token对应的上游layer全部进行微调。因此Prompt-Tunning的微调参数量级要更小,且不需要修改原始模型结构,这是“简化”的来源。相同的prefix长度,Prompt-Tunning(<0.01%)微调的参数量级要比Prefix-Tunning(0.1%~1%)小10倍以上,如下图所示
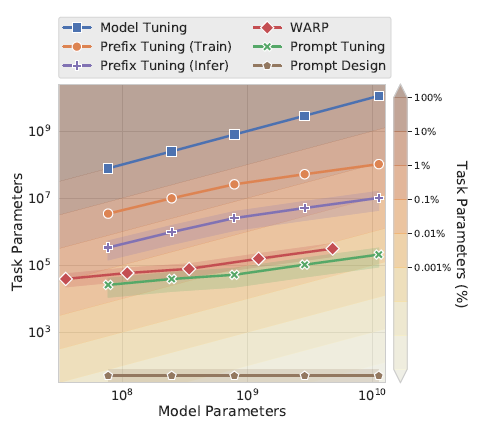
为什么上面prefix-tuning只微调embedding层效果就不好,放在prompt-tuning这里效果就好了呢?因为评估的任务不同无法直接对比,个人感觉有两个因素,一个是模型规模,另一个是继续预训练,前者的可能更大些,在下面的消融实验中会提到
效果&消融实验
在SuperGLUE任务上,随着模型参数的上升,PromptTunning快速拉近和模型微调的效果,110亿的T5模型(上面prefix-tuning使用的是15亿的GPT2),已经可以打平在下游多任务联合微调的LM模型,并且远远的甩开了Prompt Design(GPT3 few-shot)
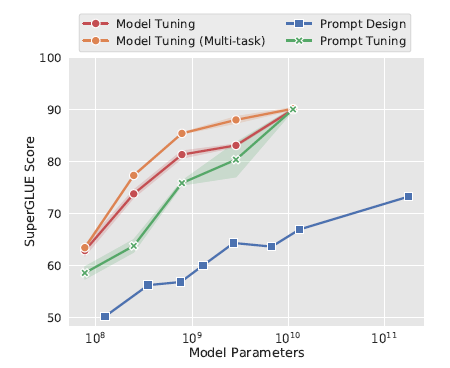
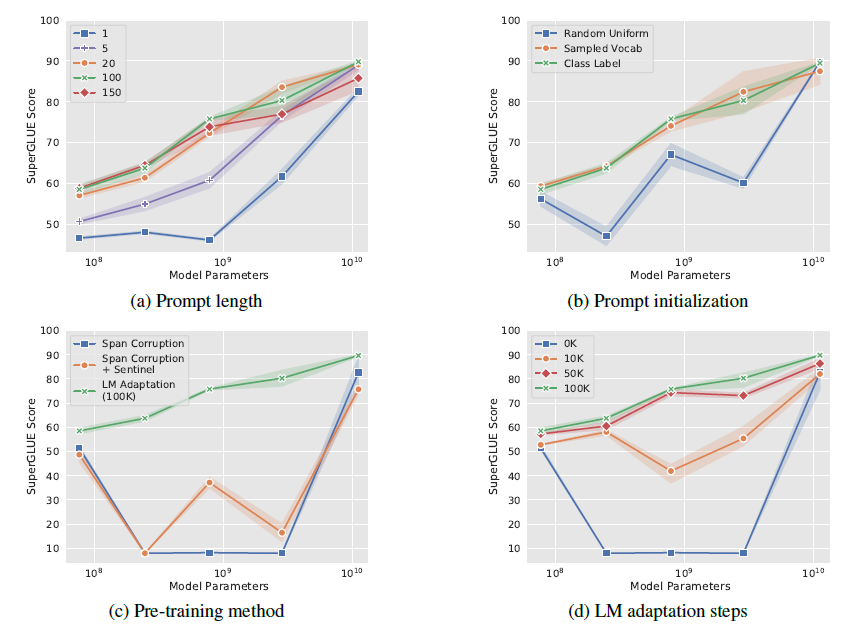
作者也做了全面的消融实验,包括以下4个方面,最核心的感受就是只要模型足够够大一切都好说
-
prompt长度(a):固定其他参数,作者尝试了{1,5,20,100,150}, Prompt token 的长度在20左右时的表现已经不错(超过20之后,提升Prompt token长度,对模型的性能提升不明显了),同样的,这个gap也会随着模型参数规模的提升而减小(即对于超大规模模型而言,即使 Prompt token 长度很短,对性能也不会有太大的影响);
-
Prompt初始化(b): 作者尝试了随机uniform初始化,用标签文本空间初始化,和用Top5K高频词采样初始化,在10^8规模,类标签词初始化效果最好。作者发现预测label也会在对应prompt空间内。不过到百亿规模后,初始化带来的影响就会消失;
-
T5继续预训练(c):作者认为T5本身的Span Corruption预训练目标和掩码词,并不适合冻结LM的场景,因为在微调中模型可以调整预训练目标和下游目标的差异,而只使用prompt可能无法弥合差异。其实这里已经能看出En-Dn框架在生成场景下没有GPT这样的Decoder来的自然。因此作者基于LM目标对T5进行继续预训练;
-
继续预训练step(d):以上的继续预训练steps,继续预训练步数越高,模型效果在不同模型规模上越单调;
可解释性
考虑Prompt-Tunning使用Embedding来表征指令,可解释性较差。作者使用cosine距离来搜索prompt embedding对应的Top5近邻。发现如下:
-
embedding的近邻出现语义相似的cluster,例如{ Technology / technology / Technologies/ technological / technologies }, 说明连续prompt实际可能是相关离散prompt词的聚合语义
-
当连续prompt较长(len=100), 存在多个prompt token的KNN相同:个人认为这和prefix-tuning使用MLP那里我的猜测相似,prompt应该是一个整体
-
使用标签词初始化,微调后标签词也大概率会出现在prompt的KNN中,说明初始化可以提供更好的prior信息加速收敛
智能推荐
获取大于等于一个整数的最小2次幂算法(HashMap#tableSizeFor)_整数 最小的2的几次方-程序员宅基地
文章浏览阅读2w次,点赞51次,收藏33次。一、需求给定一个整数,返回大于等于该整数的最小2次幂(2的乘方)。例: 输入 输出 -1 1 1 1 3 4 9 16 15 16二、分析当遇到这个需求的时候,我们可能会很容易想到一个"笨"办法:..._整数 最小的2的几次方
Linux 中 ss 命令的使用实例_ss@,,x,, 0-程序员宅基地
文章浏览阅读865次。选项,以防止命令将 IP 地址解析为主机名。如果只想在命令的输出中显示 unix套接字 连接,可以使用。不带任何选项,用来显示已建立连接的所有套接字的列表。如果只想在命令的输出中显示 tcp 连接,可以使用。如果只想在命令的输出中显示 udp 连接,可以使用。如果不想将ip地址解析为主机名称,可以使用。如果要取消命令输出中的标题行,可以使用。如果只想显示被侦听的套接字,可以使用。如果只想显示ipv4侦听的,可以使用。如果只想显示ipv6侦听的,可以使用。_ss@,,x,, 0
conda activate qiuqiu出现不存在activate_commandnotfounderror: 'activate-程序员宅基地
文章浏览阅读568次。CommandNotFoundError: 'activate'_commandnotfounderror: 'activate
Kafka 实战 - Windows10安装Kafka_win10安装部署kafka-程序员宅基地
文章浏览阅读426次,点赞10次,收藏19次。完成以上步骤后,您已在 Windows 10 上成功安装并验证了 Apache Kafka。在生产环境中,通常会将 Kafka 与外部 ZooKeeper 集群配合使用,并考虑配置安全、监控、持久化存储等高级特性。在生产者窗口中输入一些文本消息,然后按 Enter 发送。ZooKeeper 会在新窗口中运行。在另一个命令提示符窗口中,同样切换到 Kafka 的。Kafka 服务器将在新窗口中运行。在新的命令提示符窗口中,切换到 Kafka 的。,应显示已安装的 Java 版本信息。_win10安装部署kafka
【愚公系列】2023年12月 WEBGL专题-缓冲区对象_js 缓冲数据 new float32array-程序员宅基地
文章浏览阅读1.4w次。缓冲区对象(Buffer Object)是在OpenGL中用于存储和管理数据的一种机制。缓冲区对象可以存储各种类型的数据,例如顶点、纹理坐标、颜色等。在渲染过程中,缓冲区对象中存储的数据可以被复制到渲染管线的不同阶段中,例如顶点着色器、几何着色器和片段着色器等,以完成渲染操作。相比传统的CPU访问内存,缓冲区对象的数据存储和管理更加高效,能够提高OpenGL应用的性能表现。_js 缓冲数据 new float32array
四、数学建模之图与网络模型_图论与网络优化数学建模-程序员宅基地
文章浏览阅读912次。(1)图(Graph):图是数学和计算机科学中的一个抽象概念,它由一组节点(顶点)和连接这些节点的边组成。图可以是有向的(有方向的,边有箭头表示方向)或无向的(没有方向的,边没有箭头表示方向)。图用于表示各种关系,如社交网络、电路、地图、组织结构等。(2)网络(Network):网络是一个更广泛的概念,可以包括各种不同类型的连接元素,不仅仅是图中的节点和边。网络可以包括节点、边、连接线、路由器、服务器、通信协议等多种组成部分。网络的概念在各个领域都有应用,包括计算机网络、社交网络、电力网络、交通网络等。_图论与网络优化数学建模
随便推点
android 加载布局状态封装_adnroid加载数据转圈封装全屏转圈封装-程序员宅基地
文章浏览阅读1.5k次。我们经常会碰见 正在加载中,加载出错, “暂无商品”等一系列的相似的布局,因为我们有很多请求网络数据的页面,我们不可能每一个页面都写几个“正在加载中”等布局吧,这时候将这些状态的布局封装在一起就很有必要了。我们可以将这些封装为一个自定布局,然后每次操作该自定义类的方法就行了。 首先一般来说,从服务器拉去数据之前都是“正在加载”页面, 加载成功之后“正在加载”页面消失,展示数据;如果加载失败,就展示_adnroid加载数据转圈封装全屏转圈封装
阿里云服务器(Alibaba Cloud Linux 3)安装部署Mysql8-程序员宅基地
文章浏览阅读1.6k次,点赞23次,收藏29次。PS: 如果执行sudo grep 'temporary password' /var/log/mysqld.log 后没有报错,也没有任何结果显示,说明默认密码为空,可以直接进行下一步(后面设置密码时直接填写新密码就行)。3.(可选)当操作系统为Alibaba Cloud Linux 3时,执行如下命令,安装MySQL所需的库文件。下面示例中,将创建新的MySQL账号,用于远程访问MySQL。2.依次运行以下命令,创建远程登录MySQL的账号,并允许远程主机使用该账号访问MySQL。_alibaba cloud linux 3
excel离散度图表怎么算_excel离散数据表格-Excel 离散程度分析图表如何做-程序员宅基地
文章浏览阅读7.8k次。EXCEL中数据如何做离散性分析纠错。离散不是均值抄AVEDEV……=AVEDEV(A1:A100)算出来的是A1:A100的平均数。离散是指各项目间指标袭的离散均值(各数值的波动情况),数值较低表明项目间各指标波动幅百度小,数值高表明波动幅度较大。可以用excel中的离散公式为STDEV.P(即各指标平均离散)算出最终度离散度。excel表格函数求一组离散型数据,例如,几组C25的...用exc..._excel数据分析离散
学生时期学习资源同步-JavaSE理论知识-程序员宅基地
文章浏览阅读406次,点赞7次,收藏8次。i < 5){ //第3行。int count;System.out.println ("危险!System.out.println(”真”);System.out.println(”假”);System.out.print(“姓名:”);System.out.println("无匹配");System.out.println ("安全");
linux 性能测试磁盘状态监测:iostat监控学习,包含/proc/diskstats、/proc/stat简单了解-程序员宅基地
文章浏览阅读3.6k次。背景测试到性能、压力时,经常需要查看磁盘、网络、内存、cpu的性能值这里简单介绍下各个指标的含义一般磁盘比较关注的就是磁盘的iops,读写速度以及%util(看磁盘是否忙碌)CPU一般比较关注,idle 空闲,有时候也查看wait (如果wait特别大往往是io这边已经达到了瓶颈)iostatiostat uses the files below to create ..._/proc/diskstat
glReadPixels读取保存图片全黑_glreadpixels 全黑-程序员宅基地
文章浏览阅读2.4k次。问题:在Android上使用 glReadPixel 读取当前渲染数据,在若干机型(华为P9以及魅族某魅蓝手机)上读取数据失败,glGetError()没有抓到错误,但是获取到的数据有误,如果将获取到的数据保存成为图片,得到的图片为黑色。解决方法:glReadPixels实际上是从缓冲区中读取数据,如果使用了双缓冲区,则默认是从正在显示的缓冲(即前缓冲)中读取,而绘制工作是默认绘制到后缓..._glreadpixels 全黑