泰坦尼克乘客生存预测实战_首先查看clads的缺失值,各等级乘客数量,查看各等级乘客存活率,用seadorn.f-程序员宅基地
泰坦尼克乘客生存预测实战(决策树篇)
大纲
1.读取数据及预处理
2.构建决策树模型
3.在测试集上预测
4.输出预测结果
5. 决策树可视化
算法背景:
- 决策树的核心环节:构造和剪枝
构造:选择划分的特征和特征值
剪枝:预剪枝和后剪枝用于避免模型过拟合现象,提高泛化能力
- 选择特征的依据:纯度、信息熵(构建决策树的过程就是样本纯度不断提升、信息熵不断下降的过程)
- 由此引申出了三类构造算法:ID3 C4.5 CART
概略介绍:
ID3:
以信息增益(大)为依据选择特征;
优:简单方便
缺:倾向于选择取值比较多的属性,只能处理类别特征
C4.5:
以信息增益率(大)为依据选择特征;
优:采用了后剪枝策略(悲观剪枝PEP)、离散化处理连续特征、可以处理缺失值、
CART:分类回归决策树
以基尼系数(小)/(回归用最小二乘偏差MSE或最小绝对偏差MAE)为依据选择特征,且只会生成二叉树;
优:使用CCP后剪枝(代价复杂度剪枝策略–剪枝前后的误差率变化/减去的叶子数量)
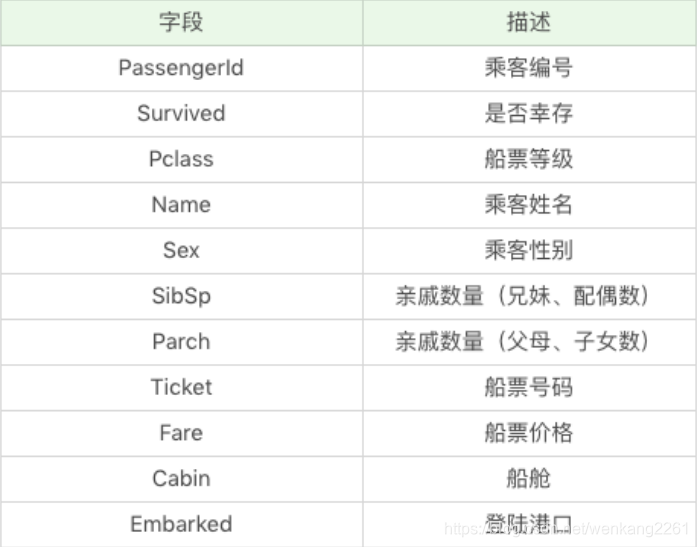
问题导入:泰坦尼克问题是一个比较经典的案例,此次实验的目的在于用决策树进行乘客的生存预测,数据集中的具体字段为:
#导入可能用到的工具包
import numpy as np
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import cross_val_score
import warnings
warnings.filterwarnings('ignore')
- 读取数据、展示、简单的预处理
traindata = pd.read_csv("train.csv",engine="python")
testdata = pd.read_csv("test.csv",engine="python")
print("train's shape:",traindata.shape)
print("test's shape:",testdata.shape)
traindata.describe()
traindata.describe(include=["O"])
traindata.info()
testdata.info()
根据info()可以看出数据的缺失情况主要出现在#缺失值:age Fare Cabin Embarked,并且Cabin缺失的过多,没办法补救了可以考虑直接剔除,其他的特征使用填充的方式补全。
del traindata['Cabin']
del testdata['Cabin']
age_mean = traindata['Age'].mean()
fare_mean = traindata['Fare'].mean()
embarked_mode = traindata.Embarked.mode()
traindata['Age'].fillna(age_mean,inplace=True)
testdata['Age'].fillna(age_mean,inplace=True)
testdata['Fare'].fillna(fare_mean,inplace=True)
traindata['Embarked'].fillna(embarked_mode,inplace=True)
testdata['Embarked'].fillna(embarked_mode,inplace=True)
traindata.head()
testdata.head()
该数据集的任务为预测乘客是否存活,其中乘客ID ,姓名以及票编号其实对分类不具有参考意义,把他们加入到模型中可能会影响决策树的构建(如ID3算法的一个弊端:倾向于选择划分类别多的特征 e.g.日期,ID,学号等)
delte_features = ['PassengerId','Name','Ticket']
for feature in delte_features:
del traindata[feature]
del testdata[feature]
print("train's shape:",traindata.shape)
print("test's shape:",testdata.shape)
对训练集和测试集做相同的编码操作:
all_data = pd.concat((traindata,testdata),axis=0)
all_data.shape
y_train = traindata['Survived']
del all_data['Survived']
all_data = pd.get_dummies(all_data)
x_train = all_data[:len(traindata)]
x_test = all_data[len(traindata):]
print("x_train's shape:",x_train.shape)
print("x_test's shape:",x_test.shape)
预览一下,操作是否正确
x_train.head()
- 构建决策树模型
# ID3算法
id3_model = DecisionTreeClassifier(criterion='entropy')
id3_model.fit(x_train,y_train)
accuracy_id3 = id3_model.score(x_train,y_train)
print("id3算法的分类准确率为(训练集):{}".format(accuracy_id3))
# 交叉验证
print("ID3算法-10折交叉验证的平均结果为:",np.mean(cross_val_score(id3_model,x_train,y_train,cv=10)))
# CART算法
cart_model = DecisionTreeClassifier(criterion='gini')
cart_model.fit(x_train,y_train)
accuracy_cart = cart_model.score(x_train,y_train)
print("CART算法的分类准确率为(训练集):{}".format(accuracy_cart))
# 交叉验证
print("CART算法-10折交叉验证的平均结果为:",np.mean(cross_val_score(cart_model,x_train,y_train,cv=10)))
- 在测试集上预测
predict_result_CART = cart_model.predict(x_test)
predict_result_ID3 = id3_model.predict(x_test)
predict_result_CART
- 输出预测结果
result = pd.DataFrame({
'Survived':predict_result_CART})
summit = pd.concat((x_test,result),axis=1)
summit.head()
summit.to_csv("predict_summit.csv",index=None)
- 决策树可视化
from sklearn import tree
import matplotlib.pyplot as plt
fig,axes = plt.subplots(nrows=1,ncols=1,dpi=600)
tree.plot_tree(cart_model,feature_names=x_train.columns,class_names=['0','1'],filled=True);
fig.savefig('tree.png')
结果展示:

小结:本实验完成了《数据分析实战45讲》的第19讲内容(泰坦尼克乘客生存预测),源数据参见github链接,整体来说挖掘的比较粗糙,并没有做调优工作以及深入的分析挖掘工作,当基本流程还是比较明确的,有一个小tips:sklearn0.23版(好像21以上都可吧)已经可以支持直接用tree.plot_tree(model,……)来可视化决策树了,记得该行代码后要加上分号“;”,保存的图片还是蛮清晰的就是太大了不好看,也亏我白搞了老半天的graphviz haha,当作一个教训吧!~~~~
智能推荐
R语言广义线性模型_lrm在r代码-程序员宅基地
文章浏览阅读9.6k次。转载自:http://blog.csdn.net/lilanfeng1991/article/details/361857391.广义线性模型和glm()函数广义线性模型扩展了线性模型的框架,它包含了非正态因变量的分析。广义线性模型通过拟合响应变量的条件均值的一个函数(不是响应变量的条件均值),假设响应变量服从指数分布族中的某个分布(并不仅限于正态分布),极大地扩展了标_lrm在r代码
咂题-程序员宅基地
文章浏览阅读209次。CODEVS1064虫食算题目描述Description所谓虫食算,就是原先的算式中有一部分被虫子啃掉了,需要我们根据剩下的数字来判定被啃掉的字母。来看一个简单的例子: 43#9865#045+8468#6633 44445506978其中#号代表被虫子啃掉的数字。根据算式,我们很容易判断:第一行的两个数字分别是5和3,第二行的数字是..._26个大写字母都至少出现一次。输出这个区间长度的最小值。
水星1200r服务器无响应,【求助】水星MAC1200R TTL刷机中断u-boot失败-程序员宅基地
文章浏览阅读1.2k次。U-Boot 1.1.3 (Feb 28 2015 - 13:28:42)Board: Ralink APSoC DRAM:64 MBrelocate_code Pointer at: 83fb8000flash manufacture id: ef, device id 40 17find flash: W25Q64BV*** Warning - bad CRC, using default...
彻底理解js是单线程的-程序员宅基地
文章浏览阅读2.2k次,点赞4次,收藏13次。js单线程、宏任务 微任务
设计模式-结构性05-桥接模式(Bridge Pattern)-程序员宅基地
文章浏览阅读80次。桥接模式就是把事物和其具体实现分开,使他们可以各自独立的变化。桥接的用意是:将抽象化与实现化解耦,使得二者可以独立变化,它是用组合关系代替继承关系来实现,从而降低了抽象和实现这两个可变维度的耦合度。像我们常用的JDBC桥DriverManager一样,JDBC进行连接数据库的时候,在各个数据库之间进行切换,基本不需要动太多的代码,甚至丝毫不用动,原因就是JDBC提供统一接口,每个数据库提供各自的实现,用一个叫做数据库驱动的程序来桥接就行了。我们来看看关系图:实现代码:先定义接口:pub
Uncaught NetworkError: Failed to execute 'send' on 'XMLHttpRequest': Failed to load 'file:///E:/test-程序员宅基地
文章浏览阅读1.6w次。这个不能用地址的方式直接访问html网页来运行的js。要开启web服务,然后通过访问web地址的方式运行。这是web的请求,要在服务器中运行才正常运行_networkerror: failed to execute 'send' on 'xmlhttprequest': failed to load
随便推点
MySQL存储函数之如何用in查询_mysql中的in查询-程序员宅基地
文章浏览阅读1k次。MySQL 存储过程_mysql中的in查询
安装Ubuntu后无法启动_ubuntu安装后无法启动-程序员宅基地
文章浏览阅读7.4k次。安装完Ubuntu20.04后,重启,只有一个下划线在左上角闪烁。或者有一个grub引导命令。_ubuntu安装后无法启动
微信公众号--发送模板消息_公众号模板消息-程序员宅基地
文章浏览阅读2.8k次,点赞2次,收藏5次。官网提示为AppSecret错误或者AppSecret不属于这个公众号,请开发者确认AppSecret的正确性。后台代码如下,用到的字段根据自己的项目进行修改,各类id自行获取(AppID可在基本配置中查看)1、点击模板消息后点击从历史模板库中添加即可选择模板。若已开通则如下图,在已开通中可查看。开通需要费用以及验证,开通后如下图。2、点击新的功能后,找到模板消息。将自己电脑的ip地址加上去即可。1、在左侧菜单栏找到模板消息。2、扫码登录后即可跳转。若找不到则点击新的功能。1、搜索微信公众平台。_公众号模板消息
C语言:程序中的预处理、编译、汇编和链接过程_编译 cc as-程序员宅基地
文章浏览阅读1.1k次。编译compile:源文件->中间代码文件ObjectFile(Windows下是.obj,Unix/Linux下是.o)链接link:把大量的ObjectFile合成执行文件备注:01 编译时,编译器需要检查语法、函数与变量声明的正确,语法的正确是对于每个文件中基本指令的准确性,函数与变量的声明则需要告诉编译器头文件所在的位置。(声明在头文件,定义在C/C++文件),所有的语法正确,..._编译 cc as
socket服务器与客户端的理解_socket服务端和客户端的区别-程序员宅基地
文章浏览阅读1.3k次。服务器端:socket bind listen accept服务器端需要知道端口号,自己的ip(IP也可以不用,可以使用 INADDR_ANY,即绑定本机的任意IP)。使用INADDR_ANY的好处是,当更改了服务器装置的IP地址时,服务器程序不用再更改IP了,当然客户端中还是需要跟着更改IP一般来说,服务器端程序较容易,服务器端处于listen状态,等待客户端来连接即可。而客户端则是需要循环的去连接服务器,当连接上了,则进行收发操作,没有连接上则,继续连接(因为服务器端程序可..._socket服务端和客户端的区别
CMake库依赖关系传递_cmake动态库依赖其他动态库-程序员宅基地
文章浏览阅读1.9k次,点赞2次,收藏3次。记录一次linux下调用openvino+opencv库的问题。主要是忽略了CMake的库依赖关系传递,即target_link_libraries时 PUBLIC、PRIVATE、INTERFACE这些字段没有使用,默认使用PUBLIC。如果你发现你编译的时候,报了一堆未引用错误,而且你还没调用这个库,那没跑了,就是依赖设置的问题。主要就是记录一下CMake中target_link_libraries更完整的用法,踩了个坑。_cmake动态库依赖其他动态库