【论文阅读+复现】AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation-程序员宅基地
技术标签: 论文阅读 talking face
AniPortrait:音频驱动的逼真肖像动画合成。
code:Zejun-Yang/AniPortrait: AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation (github.com)
paper:[2403.17694] AniPortrait: Audio-Driven Synthesis of Photorealistic Portrait Animation (arxiv.org)
出处:腾讯,2024.3.26
论文阅读
总结:
AniPortrait,一个由音频和参考肖像图像驱动的动画生成框架。方法分为两个阶段:
- 首先,从音频中提取3D中间表示,并将其投影到 根据参考图片生成的面部2D landmarks 序列。
- 随后,用扩散模型+motion module,将landmark序列转换为时间一致的肖像动画。
实验结果表明AniPortrait在面部自然度、姿态多样性和视觉质量方面具有优势,从而提供了增强的感知体验。此外在灵活性和可控性方面表现出相当大的潜力,可以有效地应用于面部动作编辑或面部再现等领域。
1. 介绍
生成肖像动画的挑战:唇部动作、面部表情和头部位置的复杂协调,以创造出逼真的效果。它们依赖于有限容量的生成器来创建视觉内容,如gan[3,17]、NeRF[14,13]或基于运动的解码器[16,8]。这些网络泛化能力有限,并且在生成高质量内容时缺乏稳定性。最近,扩散模型的出现[2,5,9]促进了高质量图像的生成。一些研究在此基础上结合了时间模块。
建立在扩散模型的进步,介绍AniPortrait,分为两个不同的阶段。
- 第一阶段,使用基于transformer的模型提取来自音频输入的3D面部mesh和头部pose序列,投影到2D面部landmark中。这个阶段能够从音频中捕捉细微的表情和嘴唇动作,以及与音频节奏同步的头部动作。
- 第二阶段,利用鲁棒扩散模型[9],结合运动模块[4],将面部transformer序列转换为时间一致且逼真的动画肖像。具体来说,借鉴了AnimateAnyone[6]的网络架构,使用Stable diffusion 1.5,基于身体运动序列和参考图像生成流体和逼真的视频。(我们在这个网络中重新设计的姿态引导模块。这种修改不仅保持了轻量化的设计,而且在产生唇运动时也表现出更高的精度。)

图1:pipeline。分为两个阶段:首先,从音频中提取三维面部mesh和头部姿态序列,然后投影到二维关键点上。第二阶段,用扩散模型将2D关键点转换为人像视频。两个阶段同时训练。
2. 方法
提出的框架包括两个模块:Audio2Lmk和Lmk2Video。
Audio2Lmk:从音频输入中提取一系列landmark,捕捉复杂的面部表情和嘴唇动作。
Lmk2Video:利用这个landmark序列,生成具有时间稳定性的高质量人像视频。
2.1 Audio2Lmk
![]() 表示语音片段序列,目标是预测相应的3D人脸网格序列
表示语音片段序列,目标是预测相应的3D人脸网格序列![]() (其中mT∈R N×3)和姿态序列
(其中mT∈R N×3)和姿态序列![]() ,p T是一个6维向量,表示旋转和平移。
,p T是一个6维向量,表示旋转和平移。
1. 音频提取3D面部mesh:先用预训练的wav2vec[1]来提取音频特征,再由两个fc层组成的简单架构将提取的音频特征转换为3D面部网格。这种简单的设计不仅保证了准确性,而且提高了推理过程的效率。
2. 音频提取姿态:同样用wav2vec网络作为主干,但不和音频到mesh模块共享权重,因为姿势与音频中的节奏和音调联系更紧密,这与音频到网格任务的重点不同。然后,考虑先前状态的影响,用transformer作为decoder,来解码pose序列。其中,音频特征通过交叉注意机制集成到decoder中。
两个模块都用简单的L1 loss训练。
在获得mesh和pose序列后,用透视投影(perspective projection)将它们转换为2D facial landmarks 序列,用作下一阶段的输入信号。
2.2 Lmk2Video
给定:参考肖像图像Iref,提取面部landmark序列![]() ,其中l T∈R N×2。
,其中l T∈R N×2。
目的:创建肖像动画![]() ,将运动与关键点序列对齐,并保持与参考图像一致的外观。
,将运动与关键点序列对齐,并保持与参考图像一致的外观。
Lmk2Video的结构设计来自AnimateAnyone:
- 用SD1.5作为主干,结合了一个能够将多帧噪声输入转换为视频帧序列的时间运动模块。
- 采用参照SD1.5结构的ReferenceNet,从参考图像中提取外观信息并整合到backbone中。这种策略设计确保了面部ID在整个输出视频中保持一致。
与AnimateAnyone不同的是:
- 增强了pose guide设计的复杂性。原始版本仅包括了几个卷积层,之后将关键点特征与骨干网络的输入层的潜在特征合并。实验发现这种简单的设计无法捕捉嘴唇的复杂运动。因此,作者采用了ControlNet的多尺度策略,将相应尺度的关键点特征合并到backbone的不同block中。尽管进行了这些增强,还是保持了较低的参数数量。
- 额外的改进:将参考图像的landmark作为额外输入。PoseGuider的交叉注意力模块促进了参考图像的landmark与每帧的target landmark之间的交互。这个过程为网络提供了额外的线索,帮助理解面部landmark和外观之间的相关性,从而有助于生成具有更精确运动的肖像动画。
3. 实验
3.1 Implementation Details
Audio2Lmk阶段:
- wav2vec2.0作为骨干网络。
- MediaPipe[7]提取3D mesh和6D pose进行注释。
- 数据集:Audio2Mesh的训练数据来自我们的内部数据集,该数据集包含来自单个发言者的近一个小时的高质量语音数据。为了确保由MediaPipe提取的3D网格的稳定性,我们指示演员在整个录制过程中保持稳定的头部位置,面向摄像机。用HDTF[18]对Audio2Pose进行训练。
- 所有训练都在一块A100上进行,使用Adam优化器,学习率为1e-5。
Lmk2Video:两阶段训练。
- 初始阶段,专注训练ReferenceNet和Pose Guider,不涉及运动模块。
- 随后阶段,冻结所有其他组件,只训练运动模块。
- 数据集:VFHQ[12]和CelebV-HQ[19]。
- 所有数据都经过MediaPipe处理,以提取2D面部关键点。
- 为了增强网络对唇部运动的敏感性,在渲染从2D关键点得到的姿势图像时,我们用不同的颜色区分上下唇。
- 图像分辨率调整为512x512。
- 4块A100 GPU进行模型训练,每个阶段耗时两天。采用AdamW优化器,并使用恒定的学习率1e-5。
3.2 Results
利用中间的3D表示,可以对其进行编辑以操纵最终的输出。例如,我们可以从源图像中提取关键点并改变其ID,从而创建面部再现效果。(可以实现音频驱动、自驱动、面部重建)

4. 结论
本研究提出了一个基于扩散模型的肖像动画框架。通过输入音频片段和一个参考图像,能够生成具有平滑的嘴唇运动和自然的头部运动的肖像视频。
利用扩散模型强大的泛化能力,该框架创建的动画展示了令人印象深刻的逼真图像质量和逼真的运动。然而,这种方法需要使用中间的3D表示,而获得大规模、高质量的3D数据的成本相当高。因此,生成的肖像视频中的面部表情和头部姿势无法摆脱“反直觉谷”效应。在未来,我们计划遵循EMO[10]的方法,直接从音频中预测肖像视频。
代码复现
1. Inference
环境配置基本和 MooreThreads/Moore-AnimateAnyone (github.com) 相同
下载好的权重目录:
Self driven
值得注意的是可以任意设置-L为所需的生成帧数
pose2vid任务:
python -m scripts.pose2vid --config ./configs/prompts/animation.yaml -W 512 -H 512问题1:ImportError: libGL.so.1: cannot open shared object file: No such file or directory
解决:
sudo apt update
sudo apt install libgl1-mesa-glx
ok,显存占用量:

生成一段59s的视频,用时1h左右:

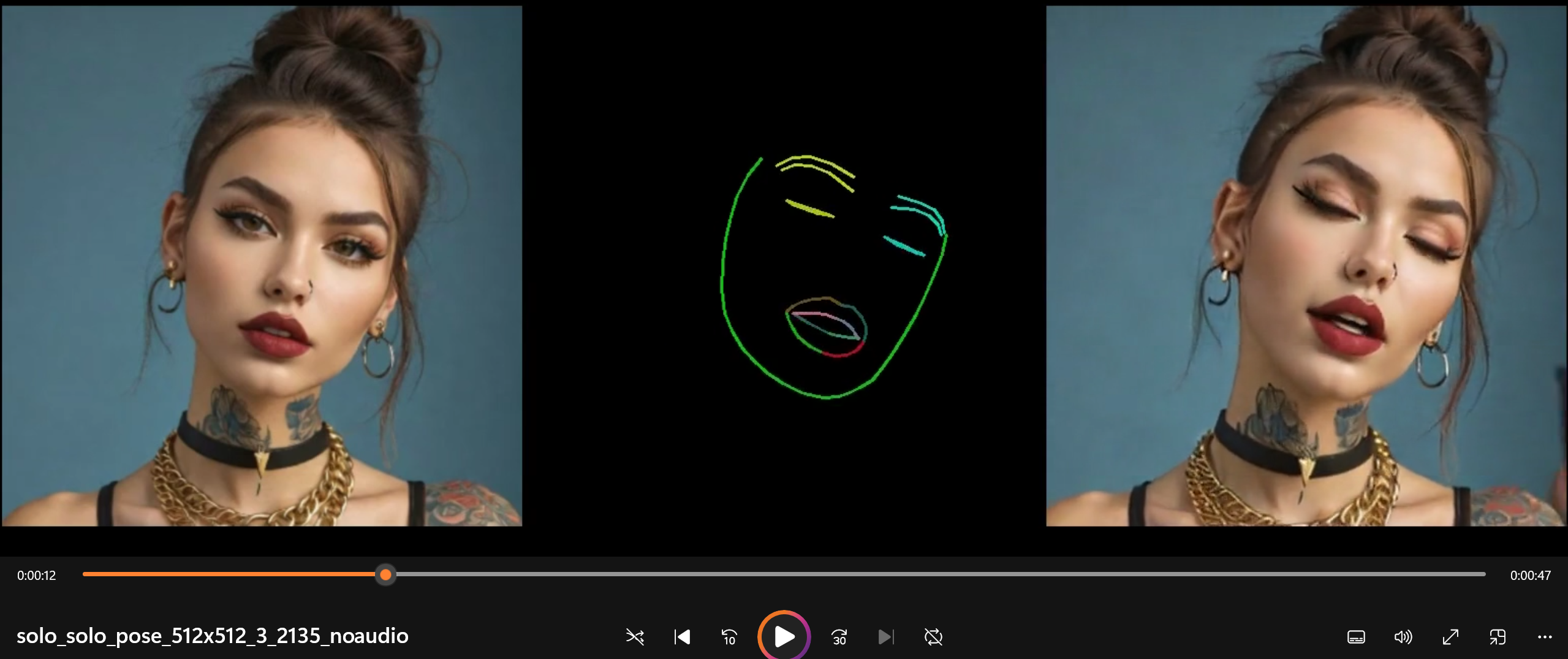
由一张身份图像和一段pose视频驱动:


效果很好,眨眼、嘴唇运动和牙齿都很自然,还实现了流畅的眼球转动和头部运动


Face reenacment
python -m scripts.vid2vid --config ./configs/prompts/animation_facereenac.yaml -W 512 -H 512问题1:
RuntimeError: CUDA error: device-side assert triggered
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.
没见过的报错,去看了看issue区也出现了这个问题,解决方法:换个驱动视频
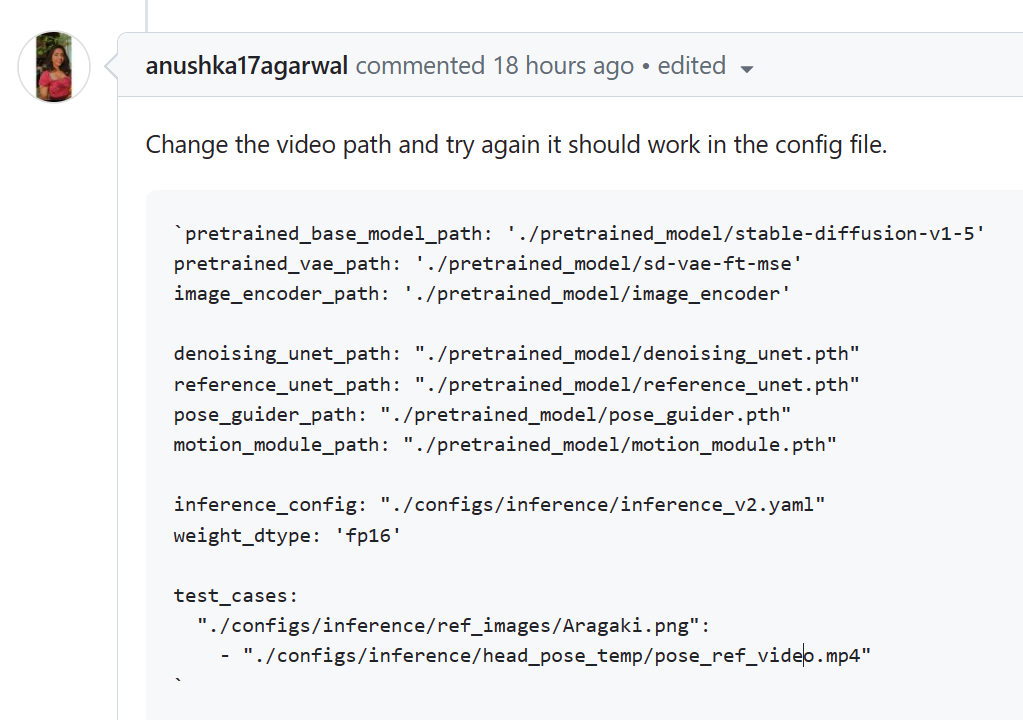
左:ref image,右: input video,中:生成结果

很奇怪为什么这样就解决了,视频的问题?作者的回复:
有个问题:参考video和参考图片可以任意搭配吗?二者需要有什么对齐关系吗?比如上下位置要一致?之后需要自己找个人脸mp4和ref_image验证一下。

Audio driven
python -m scripts.audio2vid --config ./configs/prompts/animation_audio.yaml -W 512 -H 512音频驱动生成好快,看示例只是一个7s的音频

效果不如pose驱动,牙齿略假,试听同步性一般:
2. train
Data preparation
python -m scripts.preprocess_dataset --input_dir VFHQ_PATH --output_dir SAVE_PATH --training_json JSON_PATH问题:GPU suport is not available: INTERNAL: ; RET_CHECK failure (mediapipe/gpu/gl_context_egl.cc:77) display != EGL_NO_DISPLAYeglGetDisplay() returned error 0x300c
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
I0000 00:00:1711775950.511664 83072 task_runner.cc:85] GPU suport is not available: INTERNAL: ; RET_CHECK failure (mediapipe/gpu/gl_context_egl.cc:77) display != EGL_NO_DISPLAYeglGetDisplay() returned error 0x300c
W0000 00:00:1711775950.512722 83072 face_landmarker_graph.cc:174] Sets FaceBlendshapesGraph acceleration to xnnpack by default.
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
I0000 00:00:1711775950.569749 83072 task_runner.cc:85] GPU suport is not available: INTERNAL: ; RET_CHECK failure (mediapipe/gpu/gl_context_egl.cc:77) display != EGL_NO_DISPLAYeglGetDisplay() returned error 0x300c这个错误消息显示了一些关于GPU支持的警告和一些与EGL显示相关的错误。具体来说,它表明在运行脚本时,出现了与GPU支持和EGL显示相关的问题。在这种情况下,警告可能是由于底层库或依赖项的配置问题导致的。
这个警告和错误通常与底层图形库或硬件加速相关。在这种情况下,您可能需要检查您的GPU驱动、图形库以及相关的依赖项是否正确配置和安装。可能需要更新或者调整相关的设置,以确保GPU支持和图形库正常运行。
另外,警告和错误信息可能也源自Mediapipe或TensorFlow的底层实现。您可能需要查看相关的文档或社区讨论,以了解如何正确配置和处理这些警告和错误。
找不到完全一样的报错解决方法,在检查GPU驱动程序和图形库是否正确安装和配置时,发现有可能是因为我正在用SSH远程连接服务器,并且服务器中没有可用的图形显示环境。于是在本地创建了环境,运行preprocess_dataset.py
记一个很常见的报错及其解决方法:
ERROR: Could not find a version that satisfies the requirement xxxx==0.xx (from versions: 0.8.11, 0.9.0, 0.9.0.1) ERROR: No matching distribution found for xxxx==0.xx
参考:
如果参照这里的方法仍旧解决不了,那就是python版本太低的问题,提高python解释器版本就可以了
报错:INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
WARNING: All log messages before absl::InitializeLog() is called are written to STDERR
W0000 00:00:1711786801.202315 17588 face_landmarker_graph.cc:174] Sets FaceBlendshapesGraph acceleration to xnnpack by default.
INFO: Created TensorFlow Lite XNNPACK delegate for CPU.
0it [00:00, ?it/s]t [00:00, ?it/s]
processing ...: 0it [00:00, ?it/s]
尝试1:参考Understanding Xnnpack warning · Issue #4944 · google/mediapipe (github.com)
modify base_options to be:
base_options = python.BaseOptions(model_asset_path='face_landmarker_v2_with_blendshapes.task', delegate= "GPU")报错:NotImplementedError: GPU Delegate is not yet supported for Windows

666,不支持windows
这个方法不管用,不建议参考
尝试解决2:
如何解决INFO: Created TensorFlow Lite XNNPACK delegate for CPU. - CSDN文库
安装TensorFlow
以及记录一个windows系统上常见的错误:torch.cuda.is_available()返回false
解决方法参考:torch.cuda.is_available()返回false——解决办法-程序员宅基地
本文代码所需的版本是:
下载后用pip install 离线安装,验证:
import torch print(torch.__version__) print(torch.version.cuda)输出:

更新:得到解答:是用cpu模式就好了,face_landmarker_v2_with_blendshapes这个任务只支持cpu跑
尝试解决3:改变环境变量:
export CUDA_VISIBLE_DEVICES=-1
export TF_FORCE_GPU_ALLOW_GROWTH=true

还是一样的报错T T
尝试解决4:
参考:python - RuntimeError: ; eglGetDisplay() returned error 0x3000ontext_egl.cc:157) - Stack Overflow
export DISPLAY=:0 && DRI_PRIME=1 <command>没有用
在mp.tasks.BaseOptions | MediaPipe | Google for Developers 看到了这样一句话:

GPU support is currently limited to Ubuntu platforms。。。那么在ubuntu系统上就只能用cpu来跑了,不能采用Understanding Xnnpack warning · Issue #4944 · google/mediapipe (github.com) 的方法
2024.4.2更新:作者回复:
请检查图片格式,是jpg还是png。还有视频目录组织方式,这份代码适用input_dir下多个子目录,每个子目录下是一系列png图片。如果与这个格式不对,请自己修改代码适配
原来是数据格式的问题,上面的提示信息也并不是报错,只是找不到图片数据而已,我应该直接看看代码的。。。修改了一下preprocess_dataset.py,令其能够直接处理mp4:

ok了
等待途中突然报错


我天呢,给我硬盘占满了。。这还是只处理了不到三分之一

改为服务器进行,HDTF数据集4.94G,历经46小时:
终于好了,大家如果用别的数据集可以把帧率调低一点,我这么慢的原因应该是生成帧率太高了,一段一分半的视频,分成了4000多帧。。。我这边修改了一下generate_training_json_mesh函数,令其每4帧信息保留一次,重新生成了training_data.json
stage1
accelerate launch train_stage_1.py --config ./configs/train/stage1.yaml问题1:RuntimeError: Stop_waiting response is expected
Traceback (most recent call last):
File "/root/anaconda3/envs/maa/bin/accelerate", line 8, in <module>
sys.exit(main())
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/accelerate/commands/accelerate_cli.py", line 45, in main
args.func(args)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/accelerate/commands/launch.py", line 970, in launch_command
multi_gpu_launcher(args)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/accelerate/commands/launch.py", line 646, in multi_gpu_launcher
distrib_run.run(args)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/run.py", line 785, in run
elastic_launch(
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 134, in __call__
return launch_agent(self._config, self._entrypoint, list(args))
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/launcher/api.py", line 241, in launch_agent
result = agent.run()
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/metrics/api.py", line 129, in wrapper
result = f(*args, **kwargs)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/agent/server/api.py", line 723, in run
result = self._invoke_run(role)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/agent/server/api.py", line 858, in _invoke_run
self._initialize_workers(self._worker_group)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/metrics/api.py", line 129, in wrapper
result = f(*args, **kwargs)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/agent/server/api.py", line 692, in _initialize_workers
self._rendezvous(worker_group)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/metrics/api.py", line 129, in wrapper
result = f(*args, **kwargs)
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/agent/server/api.py", line 546, in _rendezvous
store, group_rank, group_world_size = spec.rdzv_handler.next_rendezvous()
File "/root/anaconda3/envs/maa/lib/python3.10/site-packages/torch/distributed/elastic/rendezvous/static_tcp_rendezvous.py", line 55, in next_rendezvous
self._store = TCPStore( # type: ignore[call-arg]
RuntimeError: Stop_waiting response is expectedpytorch 分布式多卡训练的问题,枚举了一下可能的原因,发现是accelerate config配置的问题,一定要保证gpu有关的配置正确

看好了,这就是不用deepspeed的下场


8张3090说爆就爆
如果使用deepspeed的话显存是够用的,但是会报数据类型不一致错误:

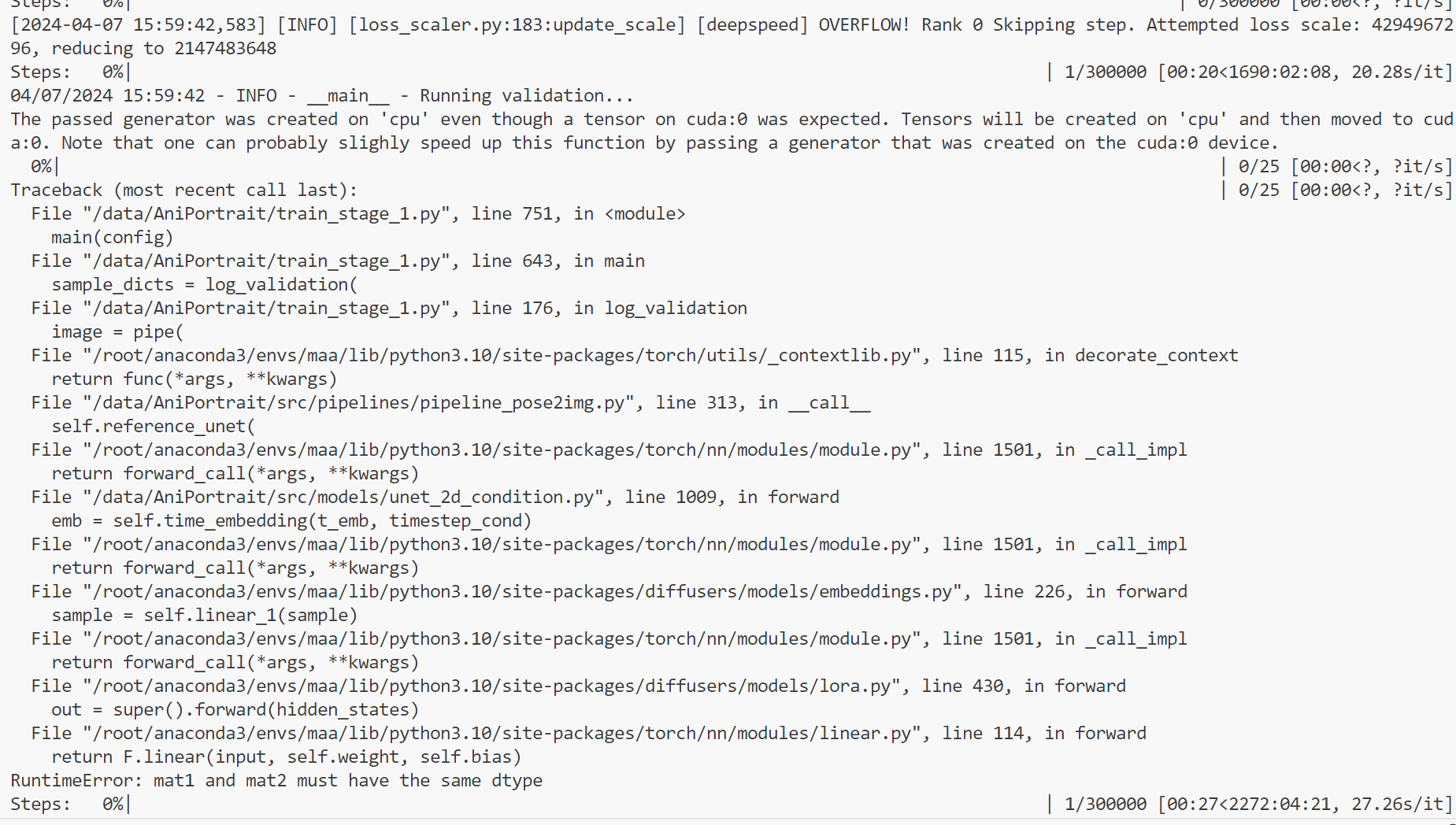
就很奇怪,我并没有修改模型,为什么会在torch里出现数据类型错误?根据报错的位置:
emb = self.time_embedding(t_emb, timestep_cond)调试看看这两个参数和模型分别是在什么device上
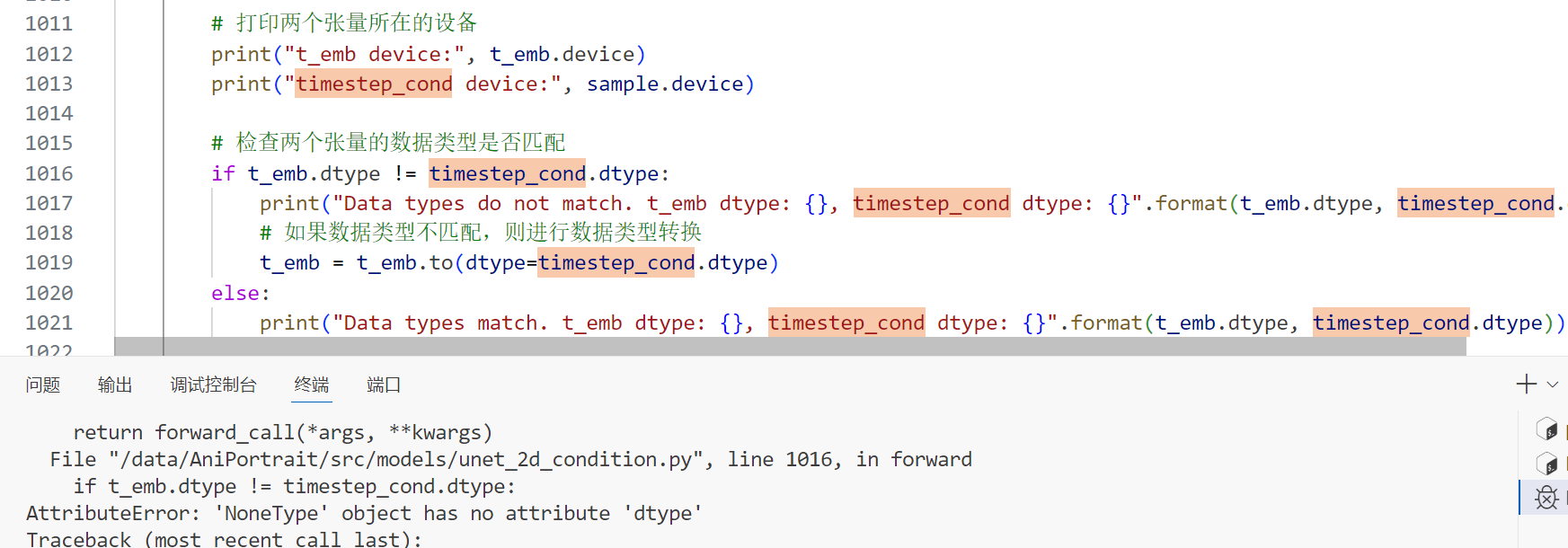

找到问题了,这里的timestep_cond是个NoneType,而t_emd是torch.float32
尝试调小batch size、如果在config里设置gradient_checkpointing: True会报错:

stage2
accelerate launch train_stage_2.py --config ./configs/train/stage2.yaml智能推荐
人工智能-即将引发创业热潮-程序员宅基地
文章浏览阅读197次。自2017年7月国务院发布《新一代人工智能发展规划》并提出三步走规划以来,已先后有多个省市出台相应的政策措施。 Python,最接近人工智能的语言!将被纳入高考内容! 浙江省信息技术课程改革方案已经出台,Python确定进入浙江省信息技术高考,从2018年起浙江省信息技术教材编程..._人工智能创业潮
ideaSSM 高校公寓交流员管理系统bootstrap开发mysql数据库web结构java编程计算机网页源码maven项目-程序员宅基地
文章浏览阅读1.3k次,点赞19次,收藏25次。一、源码特点idea 开发 SSM 高校公寓交流管理系统是一套完善的信息管理系统,结合SSM框架和bootstrap完成本系统,对理解JSP java编程开发语言有帮助系统采用SSM框架(MVC模式开发),系统具有完整的源代码和数据库,系统主要采用B/S模式开发。前段主要技术 bootstrap.css jquery后端主要技术 SpringMVC spring mybatis数据库 mysql开发工具 IDEA JDK1.8 TOMCAT 8.5。
C语言实现顺序表_顺序表c语言实现-程序员宅基地
文章浏览阅读1.6k次,点赞36次,收藏39次。1.2 SeqList.c1.3 test.c二、顺序表的实现2.1 顺序表创建一个顺序表结构体,成员包含顺序表地址、长度、大小,用于创建顺序表变量。 将顺序表变量的地址传参,通过指针接收对顺序表的顺序表数组初始化为空,长度为0,大小为0。同样传地址,要先断言指针是否为空,不然会出异常。然后判断顺序表大小是否为0,为0则代表顺序表中没有有效元素,打印提示,并返回函数,如果大于0,则有元素,从下标0开始,打印size个顺序表元素,并用空格相隔。当我们结束程序_顺序表c语言实现
谈谈ChatGPT对中国教育的影响与挑战,我们该怎么办?_chatgpt对教育的弊端-程序员宅基地
文章浏览阅读1.8k次。他们需要制定明确的指导政策,提供必要的培训资源,保护学生数据隐私,定期评估和收集反馈,以及推广批判性思维和信息素养的教育。他们需要教育学生如何正确使用这个工具,鼓励他们自主学习,监管他们的使用行为,教育他们保护数据隐私和安全,以及提供充足的社交环境。ChatGPT可以用作一个强大的辅助学习工具,帮助学生理解复杂的概念,解答疑难问题,或者为他们的学习提供个性化的建议。在一些资源匮乏的地区,这可能是一个挑战。家长需要监督孩子的ChatGPT使用情况,确保他们在使用这个工具的同时,也在进行其他重要的学习活动。_chatgpt对教育的弊端
vuepress 打包 :window is not defined_vuepress的config.js打包报错referenceerror: window is no-程序员宅基地
文章浏览阅读1.8k次。vuepress 打包报错 :window is not defined_vuepress的config.js打包报错referenceerror: window is not defined at useconfi
JavaEE框架学习笔记——SpringMVC篇,面试互联网公司怎么说-程序员宅基地
文章浏览阅读472次,点赞5次,收藏17次。学完之后,若是想验收效果如何,其实最好的方法就是可自己去总结一下。比如我就会在学习完一个东西之后自己去手绘一份xmind文件的知识梳理大纲脑图,这样也可方便后续的复习,且都是自己的理解,相信随便瞟几眼就能迅速过完整个知识,脑补回来。下方即为我手绘的MyBtis知识脑图,由于是xmind文件,不好上传,所以小编将其以图片形式导出来传在此处,细节方面不是特别清晰。但可给感兴趣的朋友提供完整的MyBtis知识脑图原件(包括上方的面试解析xmind文档)
随便推点
How Firewalls (Security Gateways) Handle the Packets? (Traffic Flow)-程序员宅基地
文章浏览阅读167次。Different firewall (security gateway) vendor has different solution to handle the passing traffic. This post compiles some useful Internet posts that interpret major vendors’ solutions including:1. C..._traffic@flow: nat:
基础设施即代码(Infrastructure as Code)-程序员宅基地
文章浏览阅读4.3k次,点赞2次,收藏7次。Infrastructure as Code(IaC)是一种IT基础设施管理流程,它将DevOps软件开发的最佳实践应用于云基础设施资源的管理。_infrastructure as code
Android二维码的创建、解析及NotFoundException_no multiformat readers were able to detect the cod-程序员宅基地
文章浏览阅读1.8k次。本篇博客主要记录一下Android生成及解析二维码的基本方法, 同时记录一下遇到的NotFoundException及对应解决方法。_no multiformat readers were able to detect the code.
java里nim游戏问题_使用Minimax算法的NIM游戏和AI玩家 - AI会失去动作-程序员宅基地
文章浏览阅读182次。我已经完成了与人类玩家和AI玩家一起编写NIM游戏的任务 . 该游戏是“Misere”(最后一个必须选择一根棒) . 人工智能应该是使用Minimax算法,但它正在进行移动,使其失去更快,我无法弄清楚为什么 . 我已经连续几天走到了尽头 . Minimax算法的目的是不输,如果它处于失败状态,延迟失去尽可能多的动作,对吧?考虑以下:NIMBoard board =新的NIMBoard(34,2)..._nim的 misere版本
MyBatis 中常用的 Mapper 相关注解和技巧,包括 @Select/@Insert/@Update/@Delete 和 @Options,并给出一些常见的优化方法_mapper @select-程序员宅基地
文章浏览阅读1.6k次。Mapper 是 MyBatis 中的一个重要概念,它用于封装复杂的 SQL 和参数映射关系,降低数据访问层与业务逻辑层之间的耦合度,方便后期维护和扩展。本系列教程主要基于 MyBatis3.x版本进行讲解,对 MyBatis-spring、MyBatis-mybatis、MyBatis-generator 等其他框架也会有所涉及。在 MyBatis 中,Mapper 是一个接口,这个接口提供了若干个方法,这些方法对应了我们执行数据库操作时需要执行的 SQL 语句或存储过程。_mapper @select
day01:Python安装详细教程_python 安装详细教程 csdn-程序员宅基地
文章浏览阅读35次。2023年最新Python安装详细教程。_python 安装详细教程 csdn