高级分布式系统-第15讲 分布式机器学习--分布式机器学习算法_分布式 机器学习系统-程序员宅基地
技术标签: 算法 机器学习 人工智能 高级分布式系统 分布式
高级分布式系统汇总:高级分布式系统目录汇总-程序员宅基地
分布式机器学习算法
按照通信步调,大致可以分为同步算法和异步算法两大类。
同步算法下,通信过程中有一个显式的全局同步状态,称之为同步屏障。当工作节点运行到同步屏障 ,就会进入等待状态,直到其工作节点均运行到同步屏障为止。接下来不同工作节点的信息被聚合并分发回来,然后各个工作节点据此开展下一轮的模型训练。
异步算法下,各个工作节点不再需要等待,而是以一个或多个全局服务器为作为中介,实现对全局模型的更新和读取。这样可以显著减少通信时间,从而获得更好的多机扩展性。

同步算法--同步SGD算法(SSGD)
同步算法--同步SGD算法(SSGD)最基础的同步算法,将SGD套用到同步的BSP框架中。
实际上就是将各个工作节点依据本地训练数据所得到的梯度叠加起来,整个过程等价于一个批量大小增加K倍的单机SGD算法。
特点:由于在每一个小批量更新之后都有一个同步过程,通信频率较高。

同步SGD算法优点与缺点
优点:在每个小批量计算的计算量很大,模型规模不大的情况下,可以获得理想的加速性能。
缺点:小批量中样本较少,模型规模较大时,可能会花费数倍于计算时间的代价进行通信。
解决方法:
在通信环节加入时空滤波,减少通信量
扩大本地学习时的批量大小,拉长本地训练时间
启发:
随着批量大小的增加,随机梯度的方差变小,会降低算法跳出某些局部最优解的可能。
当批量大小较大,模型比较容易收敛到优化曲面比较尖锐的局部最优;当批量大小较小时,会收敛到优化曲面
相对平缓的的局部最优点。
考虑到小批量中的样本较多时求得的梯度更加准确,我们可以相应地增加习率使得每步更新得更多一些,从而
解决收敛变慢的问题。

同步和异步的融合
同步和异步算法有各自的优缺点和适用场景,如果可以把它们结合起来应用,取长补短,或许可以更好地达到收敛速率与收敛精度的平衡。
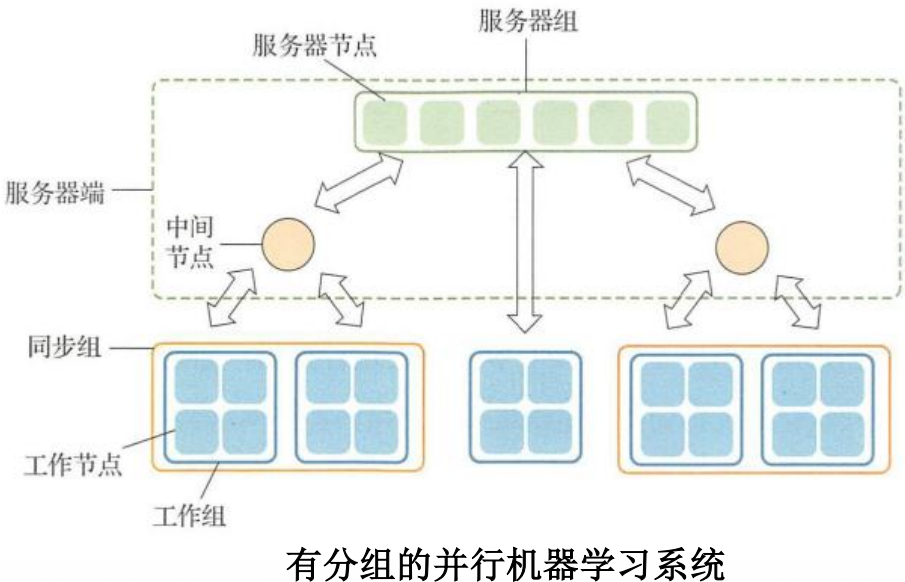
分布式机器学习理论
分布式机器学习的目标:适用大规模计算资源,充分利用大数据来训练数据,从而加速训练速度或者实现训练规模的突破。
收敛性:具有良好的收敛性质,能够以可接受的收敛速率收敛到(正则化)经验风险的最优模型;
加速比:相比与对应的单机优化算法,达到同样的模型精度所需要的时间明显降低,甚至随着工作节点的增加,需要的时间以线性的阶数减少;
泛化性:不出现过拟合现象,不仅训练性能好,测试性能也好。
为了达到更好的加速比,会人为的减少工作节点之间的通信量。
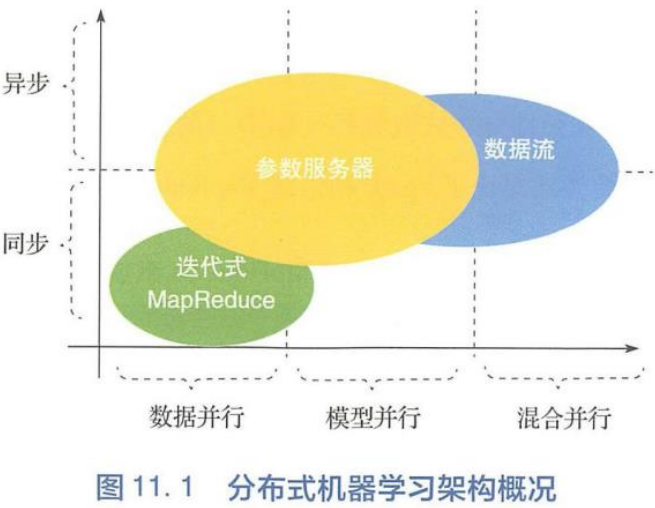
分布式机器学习系统
目前使用的分布式机器学习系统大多可以被三种架构所覆盖,可分为三种:基于IMR的系统、基于参数服务器的系统和基于数据流的系统。
基于IMR的系统主要的适用场景是“同步数据并行。它从大数据处理平台演化而来,运行逻辑比较简单。
基于参数服务器的系统可以同时支持同步和异步的并行算法。它的接口简单明了、逻辑清晰,可以很方便、灵活地与单机算法相结合。
基于数据流的系统由一个有向无环图定义,可以灵活地描述复杂地并行模式。
基于参数服务器的系统--Multiverso参数服务器
采用数据表的结构存储参数。依据模型的不同,数据有不同的具体形式:可以是简单向量,也可以是矩阵、张量或哈希表;可以使稠密的形式,也可以稀疏的形式。
Multiverso系统使用消息驱动的服务模式,也就是用一个消息队列接收并保存来向工作节点的请求。服务器端会监听队列中的消息,并按照请求的类别由相应的消息响应函数完成服务。为了提高服务器端处理的效率,Multiverso系统采用线程池对请求并行处理。
Multiverso系统实现同步和异步算法

Multiverso系统的客户端逻辑
包含的功能:用户接口(API),客户端的存储逻辑和客户端的发送逻辑。
客户端的存储逻辑
包含两个部分:一是用来存储从参数服务器端获得的全局参数,二是用来保存本地产生的模型。
客户端的发送逻辑
在网络传输前对数据进行分包和聚合。在接受参数服务器端传来的最新参数时,客户端也需要将来自不同服务器的信息汇总,然后把信息存储到本地模型容器之中。


智能推荐
GIS地理空间数据免费获取_diva gis-程序员宅基地
文章浏览阅读1.1w次,点赞20次,收藏183次。GIS地理空间数据免费获取国内:一、测绘地理信息局会提供权威的数据。需要进入全国地理信息资源目录服务系统网站(http://www.webmap.cn/main.do?method=index),该网站提供:30米全球地表覆盖数据,GlobeLand30能够提供包括:地理位置、分布范围和景观格局等直观的陆表地表覆盖的空间分布和信息。1:100万全国基础地理数据库全国1:100万基础地理数..._diva gis
王者竞速游戏服务器维护了,《王者荣耀》不停机更新维护-程序员宅基地
文章浏览阅读170次。今天王者荣耀的服务器似乎出了点小问题,玩家在游戏里出现了许多BUG,所以官方对全服的玩家进行了一次不停机的更新,那么此次更新的内容相信大家都很想知道吧,小编为大家整理了相关的资讯,感兴趣的玩家就跟着小编一起来看看吧,希望能帮到你。王者荣耀7月17日进行了不停机更新维护,下面给大家带来具体的更新内容,一起来看看吧。亲爱的召唤师:我们计划在2019年7月17日 8:30-9:30 对全服进行不停机更新..._为什么王者荣耀今天不停机
将LGBM用作二分类问题之上_matlablgbm模型-程序员宅基地
文章浏览阅读460次,点赞8次,收藏9次。LGBM(Light Gradient Boosting Machine)可以用于解决二分类问题。事实上,LGBM在实际应用中被广泛用于分类问题,包括二分类问题。在使用LGBM进行二分类问题时,你可以指定目标变量的类型和相关参数。对于二分类问题,你可以使用。指定了二分类问题的目标。你可以根据具体问题和数据集的特点调整其他参数,以优化模型性能。表示使用对数损失作为损失函数,是二分类问题的默认设置。被用于创建一个二分类模型,_matlablgbm模型
Java包装类;基本数据类型与字符串的相互转换_java 基本类型转包装类-程序员宅基地
文章浏览阅读531次。Java包装类;基本数据类型与字符串的相互转换_java 基本类型转包装类
【重构架构设计】_重构设计-程序员宅基地
文章浏览阅读368次,点赞9次,收藏9次。通过以上两个示例,可以看到领域驱动设计的特点:每个领域都有自己的模型(User和Order类),聚合根(User和Order类的实例)和业务逻辑(changePassword、addItem等方法)。引入领域驱动设计(DDD):DDD是一种面向领域模型设计的方法,通过将业务领域划分为多个小的子领域来进行解耦。通过使用微服务架构,可以将系统解耦为多个独立的服务,提高系统的可用性和可伸缩性。通过以上的步骤,可以有效进行业务解耦,提高代码的高可用性和可维护性。在订单管理领域中,专注于订单的信息、行为和业务规则。_重构设计
cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration的解决-程序员宅基地
文章浏览阅读2.3w次,点赞7次,收藏12次。导入了一个工程,编译什么的都还好,但是报了一个XML的错误。cvc-complex-type.2.4.c: The matching wildcard is strict, but no declaration can be found for element 'dubbo:application'. 具体错误如下:Multiple annotations found at this line: ..._cvc-complex-type.2.4.c: the matching wildcard is strict, but no declaration
随便推点
Android 实现QQ第三方登录_安卓代码怎么实现qq登录页面-程序员宅基地
文章浏览阅读1.3k次。Android 实现QQ第三方登录Android 实现QQ第三方登录首先肯定是去下载SDK和DEMOhttp://wiki.open.qq.com/wiki/mobile/SDK下载本文是我自己整合后的简单DEMO。先看下效果图吧原理:我们要使用QQ登录我们的应用,不是不用注册,是我们在后台为用户注册了,但是用户不知道,注_安卓代码怎么实现qq登录页面
druid完成数据库列表和分页展示和增删改查_apache druid 分页-程序员宅基地
文章浏览阅读789次。一、basedao + druid数据库连接池c3p0druid:魔鬼,号称最好的java 连接池为什么要用数据连接池?1.避免重复创建链接,链接创建不关闭情况 数据库链接非常宝贵/资源有限2.可以提高查选效率(以前频繁创建链接)3.便于对链接的同一管理和监控,便于优化应用线程池和数据库连接池统称为 池化技术1、创建servelt工程commons-beanutils-1.8.3.jar 将map 转化为对象工具类commons-dbutils-1.7.jar qu_apache druid 分页
Solidworks装配体打包/Pack and Go和另存为两种方法的区别-程序员宅基地
文章浏览阅读7.6k次。Solidworks装配体打包/Pack and Go和另存为两种方法的区别_pack and go
戴尔笔记本怎么安装统信uos系统?戴尔笔记本安装统信uos+win双系统_win7和uos双系统-程序员宅基地
文章浏览阅读2.6k次。答案是肯定的,还有的网友问,能不能保留本地windows系统然后再安装统信uos形成双系统,答案也是肯定的,下面小编就教大家在保留本地windows系统的同时安装统信uos系统形成双系统的方法教程。1,插入制作好的统信uos系统盘,重启按F12或FN+F12调出启动管理对话框,默认因为是uefi的引导,所以要选择uefi开头的USB HDD识别到U盘启动进入统信uos系统安装界面,如下图所示;3,接着进入统信uos系统安装界面后,因为我们要保留本地的windows系统,所以这里选择自定义安装,如下图所示;_win7和uos双系统
react-router v6实现动态的title(react-router-dom v6)_react router v6 改 title-程序员宅基地
文章浏览阅读5.2k次,点赞3次,收藏2次。react-router v6实现动态的title(react-router-dom v6)_react router v6 改 title
掌握之分布式-6.分布式数据库-程序员宅基地
文章浏览阅读162次。掌握高并发、高可用架构第三章 分布式本章介绍分布式架构的底层技术。主要说明面试过程中可能被问到的技术点。第六节 分布式数据库MyCat分库分表 Sharding1. 分库分表的方法垂直切分,也就是因为表多而数据多,将关系紧密(比如统一模块)的表切分出来放到一个服务器中水平切分,表不多,而是表中数据量庞大,也就是把表的数据按照某种规则切分到多个服务器中现实中多是这两种的混合2. 分..._分布式数据库使用group by 代价大吗