yolov5训练自己的数据集(一文搞定训练)_yolov5 补充训练-程序员宅基地
1 yolov5
下载yolov5:github链接。
1.1 环境配置
下载好yolov5文件后,cd到文件路径创建yolov5的环境,终端输入conda create -n yolov5 python==3.7,进入环境conda activate yolov5,安装requirements中的环境pip install -r requirements.txt。
1.2 测试代码
按照需求更改测试代码中的参数,这里我直接测试几张照片。
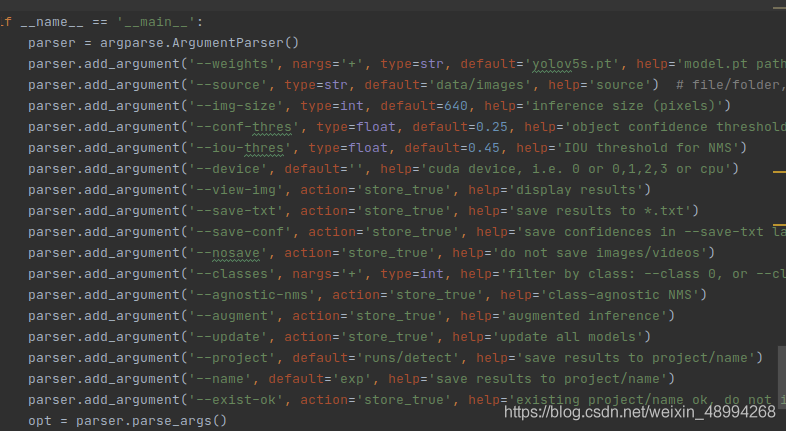
python detect.py输出结果保存在runs文件夹下
 测试成功,说明环境建立正确,接着制作自己的数据集进行训练。
测试成功,说明环境建立正确,接着制作自己的数据集进行训练。
2 数据集制作
2.1 官网数据集结构
我们可以看下官方给出的训练数据的传入方式,有两种,如图,第一种直接将训练文件的路径写入txt文件传入。第二种直接传入训练文件所在文件夹。
第一种:
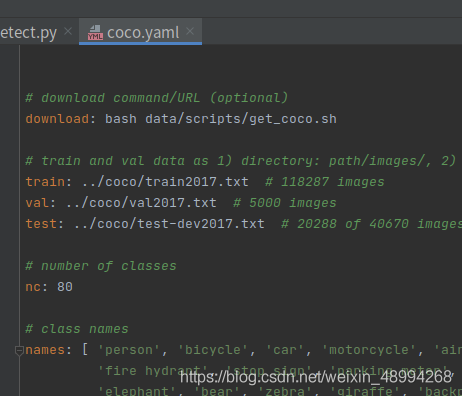 第二种:
第二种:
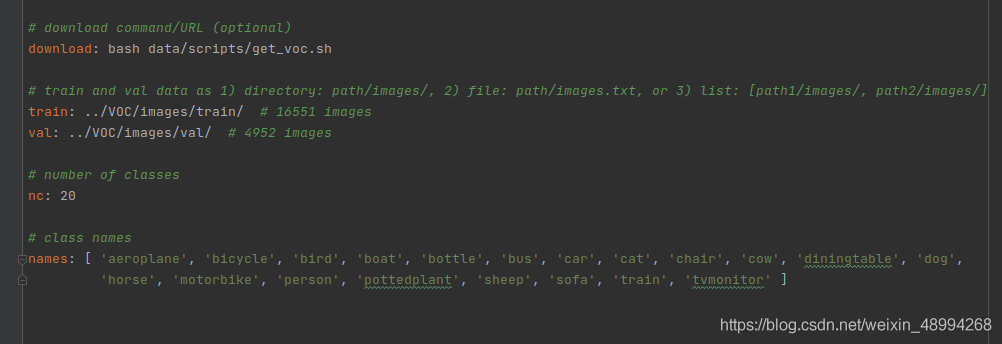 这里我们按照第二种建立数据集,官网提供了数据集的tree:
这里我们按照第二种建立数据集,官网提供了数据集的tree:
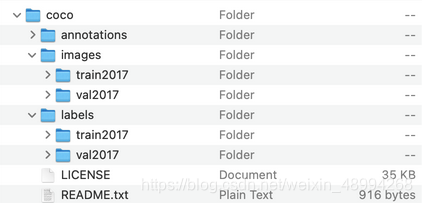
也就是下面的树状结构:
mytrain
├── mycoco
│ ├── images
│ │ ├── train
│ │ └── val
│ └── labels
│ ├── train
│ └── val
└── yolov52.2 训练数据集制作
首先建立一个自己的数据文件夹:mycoco

其目录结构如下:(剩下的文件架构代码生成)
mycoco
├── all_images
├── all_xml
├── make_txt.py
└── train_val.py
其中all_images文件夹下放置所有图片,all_xml文件夹下放置所有与之对应的xml文件。
make_txt.py文件是用来划分数据集使用,内容如下:
import os
import random
trainval_percent = 0.1
train_percent = 0.9
xmlfilepath = 'all_images'
txtsavepath = 'ImageSets'
total_xml = os.listdir(xmlfilepath)
num = len(total_xml)
list = range(num)
tv = int(num * trainval_percent)
tr = int(tv * train_percent)
trainval = random.sample(list, tv) #从所有list中返回tv个数量的项目
train = random.sample(trainval, tr)
if not os.path.exists('ImageSets/'):
os.makedirs('ImageSets/')
ftrainval = open('ImageSets/trainval.txt', 'w')
ftest = open('ImageSets/test.txt', 'w')
ftrain = open('ImageSets/train.txt', 'w')
fval = open('ImageSets/val.txt', 'w')
for i in list:
name = total_xml[i][:-4] + '\n'
if i in trainval:
ftrainval.write(name)
if i in train:
ftest.write(name)
else:
fval.write(name)
else:
ftrain.write(name)
ftrainval.close()
ftrain.close()
fval.close()
ftest.close()划分完的数据分布为:
├── train 占90%
└── trainval 占10%
├── test 占90%*10%
└── val 占10%*10%该目录终端下运行:
python make_txt.py
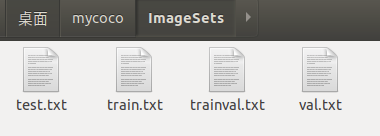
运行结果,生成四个只包含图片名称的txt文件:
接着运行train_val.py,该文件一方面将all_xml中xml文件转为txt文件存于all_labels文件夹中,另一方面生成训练所需数据存放架构。(这里如果你的数据直接是txt的标签的话将标签转化的功能注释掉即可)代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
import shutil
from os import listdir, getcwd
from os.path import join
sets = ['train', 'trainval']
classes = ['car','chemicals vehicle','truck','bus','triangle warning sign','warning sign','warning slogan']
def convert(size, box):
dw = 1. / size[0]
dh = 1. / size[1]
x = (box[0] + box[1]) / 2.0
y = (box[2] + box[3]) / 2.0
w = box[1] - box[0]
h = box[3] - box[2]
x = x * dw
w = w * dw
y = y * dh
h = h * dh
return (x, y, w, h)
def convert_annotation(image_id):
in_file = open('all_xml/%s.xml' % (image_id))
out_file = open('all_labels/%s.txt' % (image_id), 'w')
tree = ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
for obj in root.iter('object'):
difficult = obj.find('difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult) == 1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text),
float(xmlbox.find('ymax').text))
bb = convert((w, h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
wd = getcwd()
print(wd)
for image_set in sets:
if not os.path.exists('all_labels/'):
os.makedirs('all_labels/')
image_ids = open('ImageSets/%s.txt' % (image_set)).read().strip().split()
image_list_file = open('images_%s.txt' % (image_set), 'w')
labels_list_file=open('labels_%s.txt'%(image_set),'w')
for image_id in image_ids:
image_list_file.write('%s.jpg\n' % (image_id))
labels_list_file.write('%s.txt\n'%(image_id))
convert_annotation(image_id) #如果标签已经是txt格式,将此行注释掉,所有的txt存放到all_labels文件夹。
image_list_file.close()
labels_list_file.close()
def copy_file(new_path,path_txt,search_path):#参数1:存放新文件的位置 参数2:为上一步建立好的train,val训练数据的路径txt文件 参数3:为搜索的文件位置
if not os.path.exists(new_path):
os.makedirs(new_path)
with open(path_txt, 'r') as lines:
filenames_to_copy = set(line.rstrip() for line in lines)
# print('filenames_to_copy:',filenames_to_copy)
# print(len(filenames_to_copy))
for root, _, filenames in os.walk(search_path):
# print('root',root)
# print(_)
# print(filenames)
for filename in filenames:
if filename in filenames_to_copy:
shutil.copy(os.path.join(root, filename), new_path)
#按照划分好的训练文件的路径搜索目标,并将其复制到yolo格式下的新路径
copy_file('./images/train/','./images_train.txt','./all_images')
copy_file('./images/val/','./images_trainval.txt','./all_images')
copy_file('./labels/train/','./labels_train.txt','./all_labels')
copy_file('./labels/val/','./labels_trainval.txt','./all_labels')该目录终端下运行:
python train_val.py
运行结果:
mytrain
├── mycoco
│ ├── all_images
│ ├── all_labels
│ ├── all_xml
│ ├── ImageSets
│ │ ├── train.txt
│ │ ├── test.txt
│ │ ├── trainval.txt
│ │ └── val.txt
│ ├── images
│ │ ├── train
│ │ └── val
│ ├── labels
│ ├── train
│ └── val
│ ├── images_train.txt
│ ├── images_trainval.txt
│ ├── labels_train.txt
│ ├── labels_trainval.txt
│ ├── make_txt.py
│ └── train_val.py
└── yolov5至此数据集已经完全建好。将制作好的mycoco文件夹与下载好的yolov5文件夹放入同一级文件夹中:
接着按照yolov5-master/data/coco128.yaml文件,制作mycoco.yaml文件(与coco128.yaml文件同目录):
# Default dataset location is next to /yolov5:
# /parent_folder
# /mycoco
# /yolov5
# train and val data as 1) directory: path/images/, 2) file: path/images.txt, or 3) list: [path1/images/, path2/images/]
train: ../mycoco/images/train/
val: ../mycoco/images/val/
# number of classes
nc: 7
# class names
names: ['car','chemicals vehicle','truck','bus','triangle warning sign','warning sign','warning slogan' ]3 开始训练
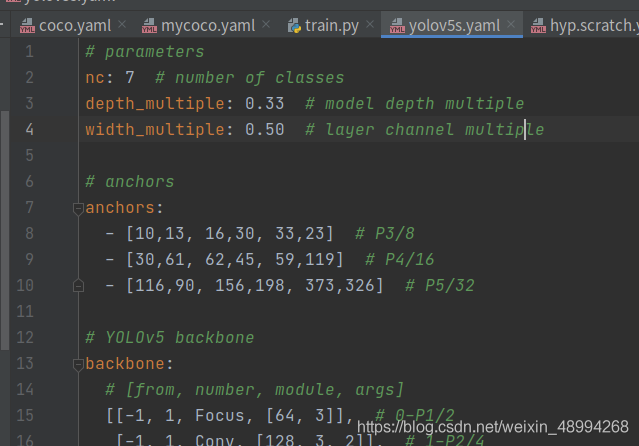
接着打开train.py文件,train.py文件详解,更改相应的参数(预训练模型,训练的数据集),这里使用yolov5s.pt为预训练模型,更改yolov5s.yaml文件中的参数(自己的类别数)。

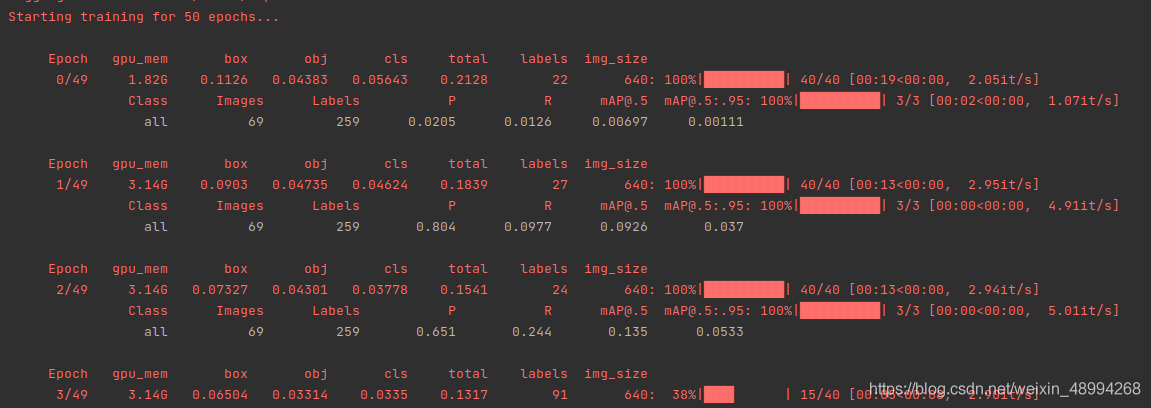
 然后就可以开始训练了。
然后就可以开始训练了。
4 测试效果
训练完以后可以看到在runs/train/exp/weights下生成了训练好的权重文件best.pt和last.pt,接着我们用训练好的权重文件进行测试,打开detect.py文件
修改权重文件路径和输入测试文件,然后run
 runs/detect/exp下我们看看测试效果(这里为了走流程,我的训练参数设置的简单,所以精度肯定不行)
runs/detect/exp下我们看看测试效果(这里为了走流程,我的训练参数设置的简单,所以精度肯定不行)

5 补充训练过程的可视化
首先在该环境的终端下安装工具:
pip install wandb终端下输入:
然后训练,如果报错:wandb.errors.error.UsageError: api_key not configured (no-tty). Run wandb login
那么需要终端初始化以下:
wandb init 按照提示复制api
按照提示复制api
然后启动重新训练,我们可以再下面的连接中观察训练的动态信息:

 或者直接上https://wandb.ai/home观看自己的训练。
或者直接上https://wandb.ai/home观看自己的训练。
关于tensorboard的的使用可以看Github.
关于yolo的参数设置可以参看link.
关于训练可视化可参看link.
智能推荐
kodi android 卡顿,解决KODI v17/16在电视上不能打开&4K播放卡顿的问题-程序员宅基地
文章浏览阅读1.2w次。本帖最后由 sziboy 于 2018-4-5 16:16 编辑接下来,解决4K片源播放卡顿的问题。以为就可以开开心心看片了是吧?非也,1080P的还好,4K,特别是高码率4K的问题就来了,那个卡顿啊…因为KODI默认是直接读取,不缓存。试过本地的USB3.0接口接移动硬盘播放,没问题,但通过网络就有点卡了。为什么?因为这17年下半年发布的破海信电视居然是个100M网卡!无线虽然是支持5G,也没说..._kodi 16
双机热备概念原理及实现步骤_双机热备 csdn-程序员宅基地
文章浏览阅读4.4k次,点赞6次,收藏15次。1.双机热备对于双机热备这一概念,我搜索了很多资料,最后,还是按照大多数资料所讲分成广义与狭义两种意义来说。从广义上讲,就是对于重要的服务,使用两台服务器,互相备份,共同执行同一服务。当一台服务器出现故障时,可以由另一台服务器承担服务任务,从而在不需要人工干预的情况下,自动保证系统能持续提供服务。从狭义上讲,双机热备就是使用互为备份的两台服务器共同执行同一服务,其中一台主机为工作机(P_双机热备 csdn
java+Springboot+mysql动物领养系统43565-计算机毕业设计项目选题推荐(赠源码)-程序员宅基地
文章浏览阅读482次。动物领养系统是基于浏览器与服务器架构平台,采用跨平台的JAVA语言开发,利用springboot框架进行逻辑控制,MySQL数据库存储数据,最后Tomcat服务器完成发布,系统可在多个环境下运行。
uniapp使用教程(包括下载、初次使用以及使用中的一些细节总结)-程序员宅基地
文章浏览阅读2.4w次,点赞19次,收藏132次。记录,以防后面忘记感觉uniapp就是vue的语法结构、小程序的api和标签 这两者混合起来使用1、下载,参考之前的博文https://blog.csdn.net/mao871863224/article/details/1093287492、开始使用:(1)一般在pages.json里面进行页面的全局配置(参照官方文档https://uniapp.dcloud.io/collocation/pages)pages.json这里面配置的主要内容包括:所有页面路径、全局的外观、底部tabBar、生_uniapp
我的完整版mbti职业性格测试-程序员宅基地
文章浏览阅读2.2k次。分析报告[您的类型趋向为:INTP (内向 直觉 思维 知觉)] 您的基本数据(图): 您的(INTP)总得分为: 311 + I80 N80 T91 P60本报告的目的:帮助你开始了解和分析最真实的自己,协助你迈出职业定位和职业规划的第一步,从人格类型的角度描述了个体的适合岗位特质和你的发展建议。..._怎么做mbti性格测试功能及报告结果
自我介绍--第一次写博客_自己的博客介绍语-程序员宅基地
文章浏览阅读142次。【自我介绍–第一次写博客】在当今这个信息社会作为一名软件工程专业的学生尤其是进入大三的学生我感到了更加的焦虑,担心凭借自己当前的知识储备还不足以在大四找到一份令自己满意的工作。而在这已经过去的两年大学生活中自己在编程上并没有花太多的时间进行细致的学习以致于自己现在编程能力特别差。过去无可厚非,只能把握现在尽自己的最大的努力提升自己的技能。在接下来的一年中我打算尽自己最大的努力去学好一门编程语言,当然学好的前提是自己每天都可以抽出时间进行编程学习以及编码,只有多写代码才能使自己更好的掌握一门编程语言并且提_自己的博客介绍语
随便推点
慢查询分析-MySQL执行计划explain_mysql ref为null代表什么-程序员宅基地
文章浏览阅读416次。通常来说, 我们的查询不应该出现 ALL 类型的查询, 因为这样的查询在数据量大的情况下, 对数据库的性能是巨大的灾难。这个类型通常出现在 =, , >, >=, _mysql ref为null代表什么
读取BMP图像每一像素点RGB数据-程序员宅基地
文章浏览阅读6k次,点赞3次,收藏17次。对于24位bmp图片,每一个像素点存放着此点的RGB值。首先定义一个结构体,包含红(red)、绿(green)、蓝(blue)这三个字段,如下:[html] view plaincopy//像素颜色值 typedef struct tagPOINT{ BYTE b; BYTE g; BYTE r_读取bmp图像每一像素
随笔-对软件工程的想法-程序员宅基地
文章浏览阅读138次。一、结缘计算机推荐博客:博客A你为什么选择计算机专业?你认为你的条件如何?和这些博主比呢? 在一开始我比较不喜欢写字,而计算机只需要敲键盘和点击鼠标就可以实现很多事情了,而且我本人就很喜欢电脑游戏啊、看视频啊之类的,用电脑就可以很方便来实现这些,然后就想着投其所好就选择了计算机了。我认为我的条件不好,基础也不好,跟博主相比起来就更大的差别了,我是到了..._软件工程的技术道路,职业道路和社会道路
JavaWeb - 2 - HTML、CSS-程序员宅基地
文章浏览阅读1k次。JavaWeb - 2 - HTML、CSS
深度学习物体检测(一)——RCNN_深度学习计算图片中某一部分的面积-程序员宅基地
文章浏览阅读3.8k次,点赞2次,收藏10次。RCNN(Region CNN) 是用深度学习进行物体检测的开山之作。先将候选区域通过selective search检测出来(2000个左右),然后根据cnn提取的每一个候选区域特征送入svm进行分类,得到一个物体类别和边框,最后利用回归算法微调得到具体的边框。_深度学习计算图片中某一部分的面积
react组件children变化不触发视图更新_react.children不刷新-程序员宅基地
文章浏览阅读1.3k次。文章目录一、文章参考二、props.children2.1 快速入门2.2 函数组件获取children2.3 class组件获取children三、React.Children3.1 API 介绍四、react组件children变化不触发视图更新4.1 问题介绍4.2 问题分析4.3 渲染知识点4.4 解决办法一、文章参考React.Children API 介绍二、props.children它包含组件的开始标签和结束标签之间的内容2.1 快速入门在组件之间,添加元素内容,例如:_react.children不刷新