Flask-SQLAlchemy_flask_sqlalchemy-程序员宅基地
认识Flask-SQLAlchemy
- Flask-SQLAlchemy 是一个为 Flask 应用增加 SQLAlchemy 支持的扩展。它致力于简化在 Flask 中 SQLAlchemy 的使用。
- SQLAlchemy 是目前python中最强大的 ORM框架, 功能全面, 使用简单。
ORM优缺点
优点
- 有语法提示, 省去自己拼写SQL,保证SQL语法的正确性
- orm提供方言功能(dialect, 可以转换为多种数据库的语法), 减少学习成本
- 防止sql注入攻击
- 搭配数据迁移, 更新数据库方便
- 面向对象, 可读性强, 开发效率高
缺点
- 需要语法转换, 效率比原生sql低
- 复杂的查询往往语法比较复杂 (可以使用原生sql替换)
环境安装
pip install flask-sqlalchemy
- flask-sqlalchemy 在安装/使用过程中, 如果出现 ModuleNotFoundError: No module named 'MySQLdb’错误, 则表示缺少mysql依赖包, 可依次尝试下列两个方案后重试:
方案1: 安装 mysqlclient依赖包 (如果失败再尝试方案2)
pip install mysqlclient
方案2: 安装pymysql依赖包
pip install pymysql
mysqlclient 和 pymysql 都是用于mysql访问的依赖包, 前者由C语言实现的, 而后者由python实现, 前者的执行效率比后者更高, 但前者在windows系统中兼容性较差, 工作中建议优先前者。
组件初始化
基本配置
flask-sqlalchemy 的相关配置也封装到了 flask 的配置项中, 可以通过app.config属性 或 配置加载方案 (如config.from_object) 进行设置
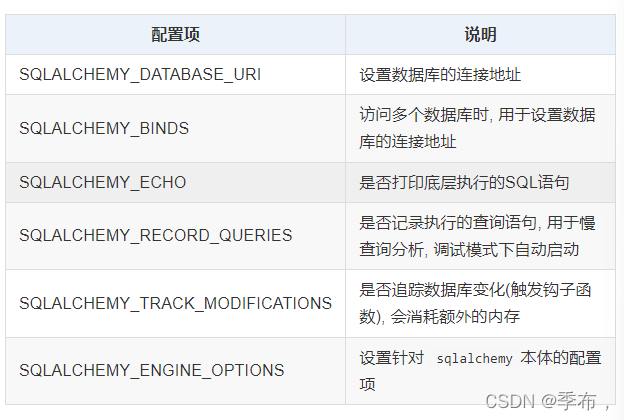
- 数据库URI(连接地址)格式: 协议名://用户名:密码@数据库IP:端口号/数据库名, 如:
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
注意点
- 如果数据库驱动使用的是 pymysql, 则协议名需要修改为
mysql+pymysql://xxxxxxx
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 设置数据库连接地址
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
# 是否追踪数据库修改(开启后会触发一些钩子函数) 一般不开启, 会影响性能
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# 是否显示底层执行的SQL语句
app.config['SQLALCHEMY_ECHO'] = True
两种初始化方式
.方式1
flask-sqlalchemy 支持两种组件初始化方式:
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 应用配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 方式1: 初始化组件对象, 直接关联Flask应用
db = SQLAlchemy(app)
方式2: 先创建组件, 延后关联Flass应用
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
# 方式2: 初始化组件对象, 延后关联Flask应用
db = SQLAlchemy()
def create_app(config_type):
"""工厂函数"""
# 创建应用
flask_app = Flask(__name__)
# 加载配置
config_class = config_dict[config_type]
flask_app.config.from_object(config_class)
# 关联flask应用
db.init_app(app)
return flask_app
构建模型类
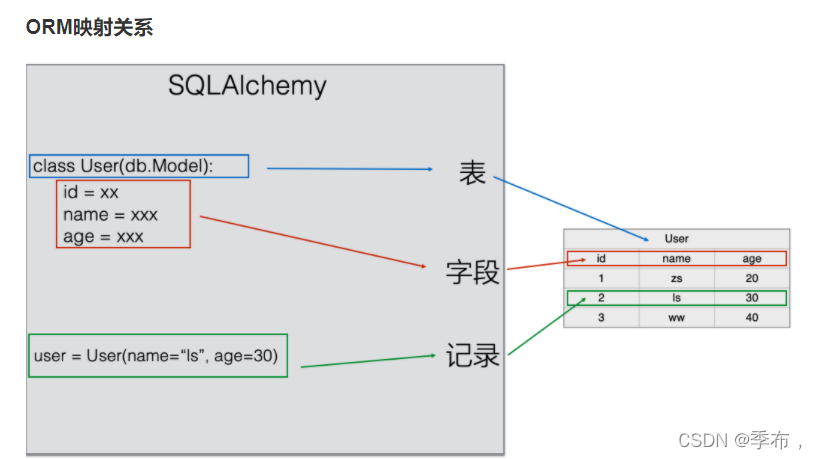
flask-sqlalchemy 的关系映射和 Django-orm 类似
- 类 对应 表
- 类属性 对应 字段
- 实例对象 对应 记录
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 类->表 类属性->字段 实例对象->记录
class User(db.Model):
__tablename__ = 't_user' # 设置表名, 表名默认为类名小写
id = db.Column(db.Integer, primary_key=True) # 设置主键, 默认自增
name = db.Column('username', db.String(20), unique=True) # 设置字段名 和 唯一约束
age = db.Column(db.Integer, default=10, index=True) # 设置默认值约束 和 索引
if __name__ == '__main__':
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
app.run(debug=True)
注意点
- 模型类必须继承 db.Model, 其中 db 指对应的组件对象
- 表名默认为类名小写, 可以通过 __tablename__类属性 进行修改
- 类属性对应字段, 必须是通过 db.Column() 创建的对象
- 可以通过 create_all() 和 drop_all()方法 来创建和删除所有模型类对应的表
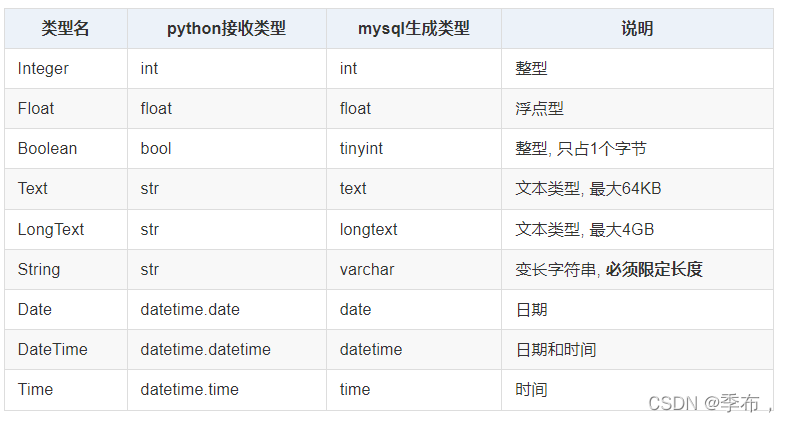
常用的字段类型
常用的字段选项
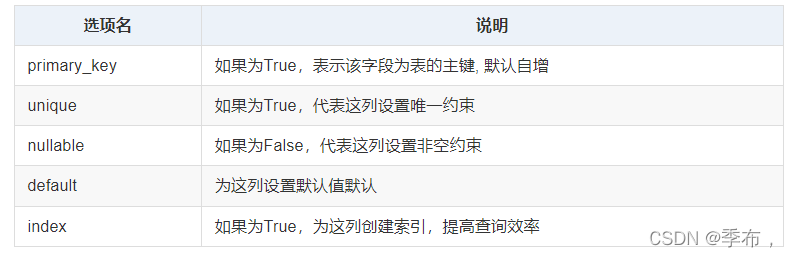
注意点: 如果没有给对应字段的类属性设置default参数, 且添加数据时也没有给该字段赋值, 则sqlalchemy会给该字段设置默认值 None
数据操作
增加数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
age = db.Column(db.Integer, index=True)
@app.route('/')
def index():
"""增加数据"""
# 1.创建模型对象
user1 = User(name='zs', age=20)
# user1.name = 'zs'
# user1.age = 20
# 2.将模型对象添加到会话中
db.session.add(user1)
# 添加多条记录
# db.session.add_all([user1, user2, user3])
# 3.提交会话 (会提交事务)
# sqlalchemy会自动创建隐式事务
# 事务失败会自动回滚
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
注意点:
- 这里的 会话 并不是 状态保持机制中的 session,而是 sqlalchemy 的会话。它被设计为 数据操作的执行者, 从SQL角度则可以理解为是一个 加强版的数据库事务
- sqlalchemy 会 自动创建事务, 并将数据操作包含在事务中, 提交会话时就会提交事务
- 事务提交失败会自动回滚
查询数据
# hm_03_数据查询.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config["SQLALCHEMY_DATABASE_URI"] = "mysql://root:[email protected]:3306/test31"
app.config["SQLALCHEMY_TRACK_MODIFICATIONS"] = False
app.config["SQLALCHEMY_ECHO"] = False
db = SQLAlchemy(app)
# 自定义类 继承db.Model 对应 表
class User(db.Model):
__tablename__ = "users" # 表名 默认使用类名的小写
# 定义类属性 记录字段
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(64))
email = db.Column(db.String(64))
age = db.Column(db.Integer)
def __repr__(self): # 自定义 交互模式 & print() 的对象打印
return "(%s, %s, %s, %s)" % (self.id, self.name, self.email, self.age)
@app.route('/')
def index():
"""
查询所有用户数据
查询有多少个用户
查询第1个用户
查询id为4的用户[3种方式]
查询名字结尾字符为g的所有用户[开始 / 包含]
查询名字和邮箱都以li开头的所有用户[2种方式]
查询age是25 或者 `email`以`itheima.com`结尾的所有用户
查询名字不等于wang的所有用户[2种方式]
查询id为[1, 3, 5, 7, 9]的用户
所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
查询年龄从小到大第2-5位的数据
分页查询, 每页3个, 查询第2页的数据
查询每个年龄的人数 select age, count(name) from t_user group by age 分组聚合
只查询所有人的姓名和邮箱 优化查询 默认使用select *
"""
return 'index'
if __name__ == '__main__':
# 删除所有表
db.drop_all()
# 创建所有表
db.create_all()
# 添加测试数据
user1 = User(name='wang', email='[email protected]', age=20)
user2 = User(name='zhang', email='[email protected]', age=33)
user3 = User(name='chen', email='[email protected]', age=23)
user4 = User(name='zhou', email='[email protected]', age=29)
user5 = User(name='tang', email='[email protected]', age=25)
user6 = User(name='wu', email='[email protected]', age=25)
user7 = User(name='qian', email='[email protected]', age=23)
user8 = User(name='liu', email='[email protected]', age=30)
user9 = User(name='li', email='[email protected]', age=28)
user10 = User(name='sun', email='[email protected]', age=26)
# 一次添加多条数据
db.session.add_all([user1, user2, user3, user4, user5, user6, user7, user8, user9, user10])
db.session.commit()
app.run(debug=True)
# 查询所有用户数据
User.query.all() 返回列表, 元素为模型对象
# 查询有多少个用户
User.query.count()
# 查询第1个用户
User.query.first() 返回模型对象/None
# 查询id为4的用户[3种方式]
# 方式1: 根据id查询 返回模型对象/None
User.query.get(4)
# 方式2: 等值过滤器 关键字实参设置字段值 返回BaseQuery对象
# BaseQuery对象可以续接其他过滤器/执行器 如 all/count/first等
User.query.filter_by(id=4).all()
# 方式3: 复杂过滤器 参数为比较运算/函数引用等 返回BaseQuery对象
User.query.filter(User.id == 4).first()
# 查询名字结尾字符为g的所有用户[开始 / 包含]
User.query.filter(User.name.endswith("g")).all()
User.query.filter(User.name.startswith("w")).all()
User.query.filter(User.name.contains("n")).all()
User.query.filter(User.name.like("w%n%g")).all() # 模糊查询
# 查询名字和邮箱都以li开头的所有用户[2种方式]
User.query.filter(User.name.startswith('li'), User.email.startswith('li')).all()
from sqlalchemy import and_
User.query.filter(and_(User.name.startswith('li'), User.email.startswith('li'))).all()
# 查询age是25 或者 `email`以`itheima.com`结尾的所有用户
from sqlalchemy import or_
User.query.filter(or_(User.age==25, User.email.endswith("itheima.com"))).all()
# 查询名字不等于wang的所有用户[2种方式]
from sqlalchemy import not_
User.query.filter(not_(User.name == 'wang')).all()
User.query.filter(User.name != 'wang').all()
# 查询id为[1, 3, 5, 7, 9]的用户
User.query.filter(User.id.in_([1, 3, 5, 7, 9])).all()
# 所有用户先按年龄从小到大, 再按id从大到小排序, 取前5个
User.query.order_by(User.age, User.id.desc()).limit(5).all()
# 查询年龄从小到大第2-5位的数据 2 3 4 5
User.query.order_by(User.age).offset(1).limit(4).all()
# 分页查询, 每页3个, 查询第2页的数据 paginate(页码, 每页条数)
pn = User.query.paginate(2, 3)
pn.pages 总页数 pn.page 当前页码 pn.items 当前页的数据 pn.total 总条数
# 查询每个年龄的人数 select age, count(name) from t_user group by age 分组聚合
from sqlalchemy import func
data = db.session.query(User.age, func.count(User.id).label("count")).group_by(User.age).all()
for item in data:
# print(item[0], item[1])
print(item.age, item.count) # 建议通过label()方法给字段起别名, 以属性方式获取数据
# 只查询所有人的姓名和邮箱 优化查询 User.query.all() # 相当于select *
from sqlalchemy.orm import load_only
data = User.query.options(load_only(User.name, User.email)).all() # flask-sqlalchem的语法
for item in data:
print(item.name, item.email)
data = db.session.query(User.name, User.email).all() # sqlalchemy本体的语法
for item in data:
print(item.name, item.email)
更新数据
flask-sqlalchemy 提供了两种更新数据的方案
- 先查询, 再更新
对应SQL中的 先select, 再update - 基于过滤条件的更新 (推荐方案)
对应SQL中的 update xx where xx = xx (也称为 update子查询 )
先查询, 再更新
这种方式的缺点
- 查询和更新分两条语句, 效率低
- 如果并发更新, 可能出现更新丢失问题(Lost Update)
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good' # 设置表名
id = db.Column(db.Integer, primary_key=True) # 设置主键
name = db.Column(db.String(20), unique=True) # 商品名称
count = db.Column(db.Integer) # 剩余数量
@app.route('/')
def purchase():
"""购买商品"""
# 更新方式1: 先查询后更新
# 缺点: 并发情况下, 容易出现更新丢失问题 (Lost Update)
# 1.执行查询语句, 获取目标模型对象
goods = Goods.query.filter(Goods.name == '方便面').first()
# 2.对模型对象的属性进行赋值 (更新数据)
goods.count = goods.count - 1
# 3.提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 删除所有继承自db.Model的表
db.drop_all()
# 创建所有继承自db.Model的表
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
基于过滤条件的更新
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 查询和更新在一条语句中完成, 单条SQL具有原子性, 不会出现更新丢失问题
- 会对满足过滤条件的所有记录进行更新, 可以实现批量更新处理
操作步骤如下:
- 配合 查询过滤器filter() 和 更新执行器update() 进行数据更新
- 提交会话
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/')
def purchase():
"""购买商品"""
# 更新方式2: update子查询 可以避免更新丢失问题
# update t_good set count = count - 1 where name = '方便面';
Goods.query.filter(Goods.name == '方便面').update({
'count': Goods.count - 1})
# 提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 重置数据库数据
db.drop_all()
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
删除数据
类似更新数据, 也存在两种删除数据的方案
先查询, 再删除
- 对应SQL中的 先select, 再delete
基于过滤条件的删除 (推荐方案)
- 对应SQL中的 delete xx where xx = xx (也称为 delete子查询 )
这种方式的缺点:
- 查询和删除分两条语句, 效率低
@app.route('/del')
def delete():
"""删除数据"""
# 方式1: 先查后删除
goods = Goods.query.filter(Goods.name == '方便面').first()
# 删除数据
db.session.delete(goods)
# 提交会话 增删改都要提交会话
db.session.commit()
return "index"
基于过滤条件的删除
这种方式的优点:
- 一条语句, 被网络IO影响程度低, 执行效率更高
- 会对满足过滤条件的所有记录进行删除, 可以实现批量删除处理
操作步骤如下:
- 配合 查询过滤器filter() 和 删除执行器delete() 进行数据删除
- 提交会话
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
# 创建组件对象
db = SQLAlchemy(app)
# 构建模型类 商品表
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/del')
def delete():
"""删除数据"""
# 方式2: delete子查询
Goods.query.filter(Goods.name == '方便面').delete()
# 提交会话
db.session.commit()
return "index"
if __name__ == '__main__':
# 重置数据库数据
db.drop_all()
db.create_all()
# 添加一条测试数据
goods = Goods(name='方便面', count=1)
db.session.add(goods)
db.session.commit()
app.run(debug=True)
- 增删改操作都需要提交会话, 对应事务中进行数据库变化后提交事务
刷新数据
- Session 被设计为数据操作的执行者, 会先将操作产生的数据保存到内存中
- 在执行 flush刷新操作 后, 数据操作才会同步到数据库中
- 有两种情况下会 隐式执行刷新操作
提交会话
执行查询操作 (包括 update 和 delete 子查询)
开发者也可以 手动执行刷新操作 session.flush()
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class Goods(db.Model):
__tablename__ = 't_good'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20), unique=True)
count = db.Column(db.Integer)
@app.route('/')
def purchase():
goods = Goods(name='方便面', count=20)
db.session.add(goods)
# 主动执行flush操作, 立即执行SQL操作(数据库同步)
db.session.flush()
# Goods.query.count() # 查询操作会自动执行flush操作
db.session.commit() # 提交会话会自动执行flush操作
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
多表查询

案例中包含两个模型类: User用户模型 和 Address地址模型, 并且一个用户可以有多个地址, 两张表之间存在一对多关系
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 主表(一) 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 从表(多)
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/')
def index():
"""添加并关联数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush() # 需要手动执行flush操作, 让主表生成主键, 否则外键关联失败
# db.session.commit() # 有些场景下, 为了保证数据操作的原子性不能分成多个事务进行操作
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关联查询
关联查询步骤: (以主查从为例)
- 先查询主表数据
- 再通过外键字段查询 关联的从表数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/demo')
def demo():
"""查询多表数据 需求: 查询姓名为"张三"的所有地址信息"""
# 1.先根据姓名查找到主表主键
user1 = User.query.filter_by(name='张三').first()
# 2.再根据主键到从表查询关联地址
adrs = Address.query.filter_by(user_id=user1.id).all()
for adr in adrs:
print(adr.detail)
return "demo"
@app.route('/')
def index():
"""添加并关联数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
return "index"
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关系属性
关系属性是 sqlalchemy 封装的一套查询关联数据的语法, 其目的为 让开发者使用 面向对象的形式 方便快捷的获取关联数据
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一 一个用户可以有多个地址
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
addresses = db.relationship('Address') # 1.定义关系属性 relationship("关联数据所在的模型类")
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
# 2. 外键字段设置外键参数 db.ForeignKey('主表名.主键')
user_id = db.Column(db.Integer, db.ForeignKey('t_user.id'))
@app.route('/')
def index():
"""添加数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2])
db.session.commit()
"""查询多表数据 需求: 查询姓名为"张三"的所有地址信息"""
# 先根据姓名查找用户主键
user1 = User.query.filter_by(name='张三').first()
# 3.使用关系属性获取关系数据
for address in user1.addresses:
print(address.detail)
return "index"
if __name__ == '__main__':
# 重置所有继承自db.Model的表
db.drop_all()
db.create_all()
app.run(debug=True)
连接查询
- 开发中有 联表查询需求 时, 一般会使用 join连接查询
- sqlalchemy 也提供了对应的查询语法
db.session.query(主表模型字段1, 主表模型字段2, 从表模型字段1, xx.. ).join(从表模型类, 主表模型类.主键 == 从表模型类.外键)
- join语句 属于查询过滤器, 返回值也是 BaseQuery 类型对象
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test31'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = False
# 创建组件对象
db = SQLAlchemy(app)
# 用户表 一
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column(db.String(20))
# 地址表 多
class Address(db.Model):
__tablename__ = 't_adr'
id = db.Column(db.Integer, primary_key=True)
detail = db.Column(db.String(20))
user_id = db.Column(db.Integer) # 定义外键
@app.route('/demo')
def demo():
"""查询多表数据 需求: 查询姓名为"张三"的用户id和地址信息"""
# sqlalchemy的join查询
data = db.session.query(User.id, Address.detail).join(Address, User.id == Address.user_id).filter(User.name == '张三').all()
for item in data:
print(item.detail, item.id)
return "demo"
@app.route('/')
def index():
"""添加数据"""
user1 = User(name='张三')
db.session.add(user1)
db.session.flush()
adr1 = Address(detail='中关村3号', user_id=user1.id)
adr2 = Address(detail='华强北5号', user_id=user1.id)
db.session.add_all([adr1, adr2, user1])
db.session.commit()
return 'index'
if __name__ == '__main__':
db.drop_all()
db.create_all()
app.run(debug=True)
关联查询的性能优化
- 通过前边的学习, 可以发现 无论使用 外键 还是 关系属性 查询关联数据, 都需要查询两次, 一次查询用户数据, 一次查询地址数据
- 两次查询就需要发送两次请求给数据库服务器, 如果数据库和web应用不在一台服务器中, 则 网络IO会对查询效率产生一定影响
- 可以考虑使用 连接查询 join 使用一条语句就完成关联数据的查询
# 使用join语句优化关联查询
adrs = Address.query.join(User, Address.user_id == User.id).filter(User.name == '张三').all() # 列表中包含地址模型对象
Session机制
生命周期
flask-sqlalchemy 对于 sqlalchemy本体 的 Session 进行了一定的封装:
Session的生命周期和请求相近
- 请求中的首次数据操作会创建Session
- 整个请求过程中使用的Session为同一个, 并且线程隔离
- 请求结束时会自动销毁Session(释放内存)
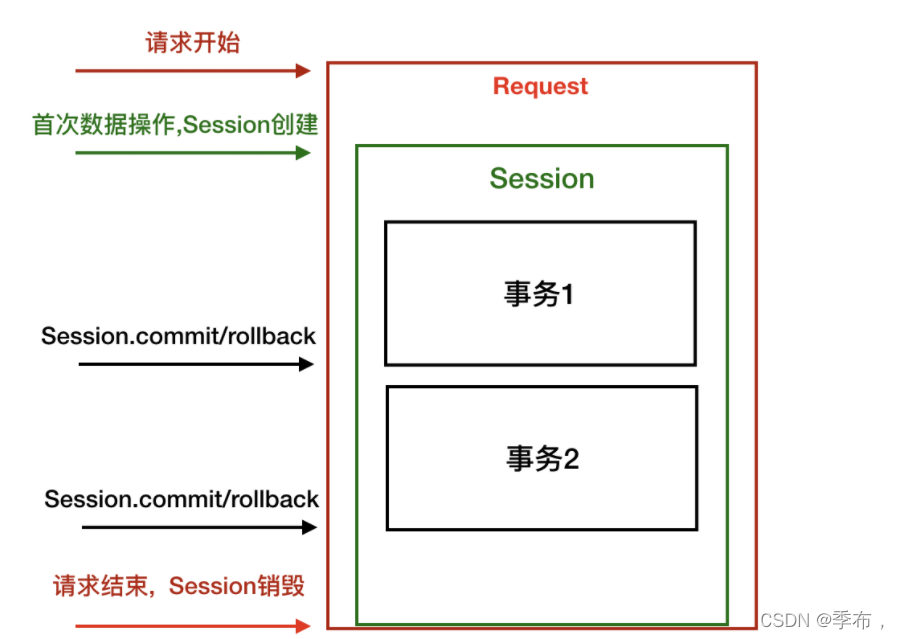
Session和事务
- Session中可以包含多个事务, 提交事务失败后, 会自动执行SQL的回滚操作
- 同一个请求中, 想要在前一个事务失败的情况下创建新的事务, 必须先手动回滚事务 Session.rollback
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/toutiao'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
app.config['SQLALCHEMY_ECHO'] = True
db = SQLAlchemy(app)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
age = db.Column(db.Integer, default=0, index=True)
@app.route('/')
def index():
"""事务1"""
try:
user1 = User(name='zs', age=20)
db.session.add(user1)
db.session.commit()
except BaseException:
# 手动回滚 同一个session中, 前一个事务如果失败, 必须手动回滚, 否则无法创建新的事务
db.session.rollback()
"""事务2"""
user1 = User(name='lisi', age=30)
db.session.add(user1)
db.session.commit()
return "index"
if __name__ == '__main__':
"""为了进行测试, 首次运行 建表并添加一条测试数据后, 注释下方代码, 并重新运行测试"""
# 重置所有继承自db.Model的表
# db.drop_all()
# db.create_all()
# 添加一条测试数据
# user1 = User(name='zs', age=20)
# db.session.add(user1)
# db.session.commit()
app.run(debug=True)
数据迁移
- flask-migrate组件 为flask-sqlalchemy提供了数据迁移功能, 以便进行数据库升级, 如增加字段、修改字段类型等
- 安装组件 pip install flask-migrate
# hm_数据迁移.py
from flask import Flask
from flask_sqlalchemy import SQLAlchemy
from flask_migrate import Migrate
app = Flask(__name__)
# 相关配置
app.config['SQLALCHEMY_DATABASE_URI'] = 'mysql://root:[email protected]:3306/test32'
app.config['SQLALCHEMY_TRACK_MODIFICATIONS'] = False
# SQlalchemy组件初始化
db = SQLAlchemy(app)
# 迁移组件初始化
Migrate(app, db)
# 构建模型类
class User(db.Model):
__tablename__ = 't_user'
id = db.Column(db.Integer, primary_key=True)
name = db.Column('username', db.String(20), unique=True)
# age= db.Column(db.Integer, default=10, index=True)
@app.route('/')
def index():
return "index"
if __name__ == '__main__':
app.run(debug=True)
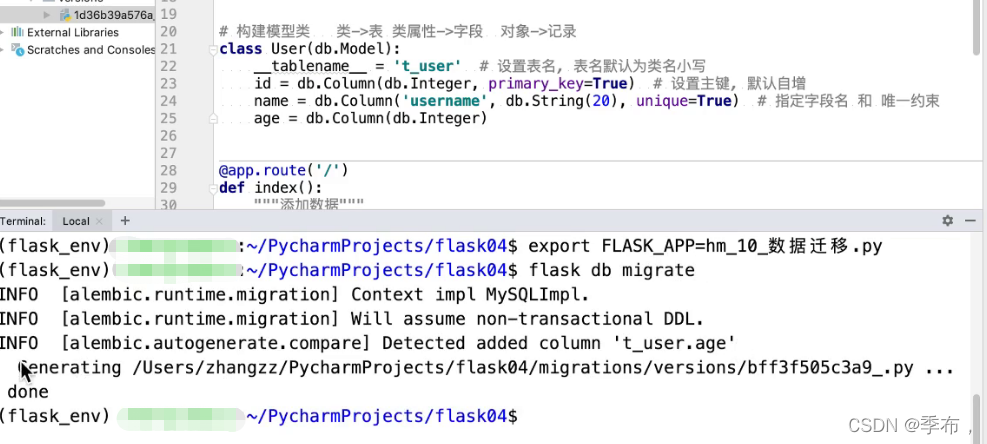
执行迁移命令
export FLASK_APP=hm_数据迁移.py # 设置环境变量指定启动文件
flask db init # 生成迁移文件夹 只执行一次
flask db migrate # ⽣成迁移版本, 保存到迁移文件夹中
flask db upgrade # 执行迁移
执行迁移命令前需要先设置环境变量指定启动文件
添加age字段
这里连接查询,比如User表连接address表,join后面的条件正常可以写Address,但是也可以写User,需要注意的是如果写User,那么User.id这个条件需要放在等号后面

智能推荐
Web应用程序_基于web的应用程序-程序员宅基地
文章浏览阅读94次,点赞2次,收藏3次。随着 Web3.0、社交网络、微博、移动 APP、微信小程序等等一系列新型的互联网产品的诞生,基于 Web 环境的互联网应用越来越广泛,企业信息化的过程中各种应用都架设在 web 平台上,网站内的信息可以直接和其他网站相关信息进行交互和倒腾,能通过第三方信息平台同时对多家网站的信息进行整合使用。用户在互联网上能拥有自己的数据,并能在不同网站上使用,用浏览器即可以实现复杂的系统程序才具有的功能。_基于web的应用程序
html5 新技术,关于HTML5你必须知道的28个新特性,新技巧以及新技术-程序员宅基地
文章浏览阅读184次。25. 哪些不是HTML51)SVG2)CSS33)Geolocation4)Client Storage5)Web Sockets26. Data属性Bla BlaCSS中使用:h1:hover:after {content: attr(data-hover-response);color: black;position: absolute;left: 0;}Don’t Tou ch Me 27..._html的新技术是啥
兼容解决 IE 、火狐、谷歌浏览器中 Iframe框架的页面缓存的方法-程序员宅基地
文章浏览阅读136次。兼容解决 IE 、火狐、谷歌浏览器中 Iframe框架的页面缓存的方法_兼容解决 ie 、火狐、谷歌浏览器中 iframe框架的页面缓存
记一次WPF集成SemanticKernel+OneAPI+讯飞星火认知大模型实践_semantickernel oneapi-程序员宅基地
文章浏览阅读1k次,点赞19次,收藏26次。Semantic Kernel 是一个开源 SDK,可让您轻松构建可以调用现有代码的代理。作为高度可扩展的 SDK,可以将语义内核与 OpenAI、Azure OpenAI、Hugging Face 等模型一起使用!通过将现有的 C#、Python 和 Java 代码与这些模型相结合,可以生成用于回答问题和自动执行流程的代理。_semantickernel oneapi
嵌入式毕设分享 STM32与wifi的天气预报网时钟系统_基于单片机和wifi的天气预报自动校时系统论文-程序员宅基地
文章浏览阅读219次。这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是基于STM32与wifi的天气预报网时钟系统学长这里给一个题目综合评分(每项满分5分)难度系数:3分工作量:3分创新点:3分。_基于单片机和wifi的天气预报自动校时系统论文
Android NuPlayer播放框架-程序员宅基地
文章浏览阅读3k次。①Android NuPlayer播放框架[时间:2016-09] [状态:Open][关键词:android,nuplayer,开源播放器,播放框架,nuplayerdriver]0 NuPlayer简介Android2.3时引入流媒体框架,而流媒体框架的核心是NuPlayer。在之前的版本中一般认为Local Playback就用Stagefrightp_android nuplayer播放框架
随便推点
myEclipse8.0或者8.5 svn插件配置-程序员宅基地
文章浏览阅读588次。1、先下载svnmyeclipse插件;2、装好myEclipse8.0或者8.5;3、在myEclipse安装目录下,(我的为D:/Program Files/Genuitec/)有两个文件夹MyEclipse 8.x Latest和Common,在D:/Program Files/Genuitec下创建一个文件夹,名字叫做myPlugin;4、在myPlugin下面再创建一个文件夹eclipse;5、把刚才下载的svn插件features和plugins复制到eclipse文件夹下;6、在D:/Prog
HTML5手机开发——滚动和惯性缓动_html 适配手机 允许滚动-程序员宅基地
文章浏览阅读240次。1. 滚动以下是三种实现方式:1) 利用原生的css属性 overflow: scroll<div id="parent" style="overflow:scroll;> <div id='content'>内容区域</div></div>Notice: 在android 有bug, 滚动完后会回退到最顶端的内容区域,解决办法是..._html 适配手机 允许滚动
打造企业级自动化运维平台系列(二十):云服务器 ECS 进阶(SLB/弹性伸缩)...-程序员宅基地
文章浏览阅读37次。戳下方名片,关注并星标!回复“1024”获取2TB学习资源!前面介绍了服务发现与配置管理平台 Nacos、分布式的对象存储系统 MinIO、容器管理工具 Rancher、kubernetes包管理工具 Helm、服务网格 Istio、链路追踪工具 SkyWalking、influxDB、cAdvisor、Grafana、云服务器 ECS 入门等相关的知识点,今天我将详细的为大家介绍 云服..._云主机自动化运维平台
被科技盗去的时光_ccmm123-程序员宅基地
文章浏览阅读812次。在21世纪的明天,我们在生射中的相当大一局部工夫里都在和互联网打交道。一项早先的研讨标明,人终身中至多有5年工夫用于上彀,更确实地说,是在“网上冲浪”。你一定晓得“网上冲浪”吧,就是漫无目标、跟着觉得走地在网上“瞎逛”,平日毫有意义,纯属糜费工夫。可明天上午我就曾经花了两个小时上彀,我乃至想都懒得想我的终身中有若干工夫花在这下面了。古代生涯中,其他糜费工夫的行动还有:_ccmm123
Windows10远程连接Ubuntu,通过局域网IP地址,使用teamviewer软件_windows使用teamviewer链接ubuntu-程序员宅基地
文章浏览阅读3.9k次。在Ubuntu和Windows端同时安装好teamviewer软件之后(这儿要求两个系统teamviewer的版本一致:13 或者14)。在在Ubuntu端的teamviewer设置:接受局域网连接,默认是不接受的。 在呼入的LAN连接那儿选择接受,默认是取消激活。然后点击确定。之后就可以使用windows端的teamviewer通过局域网IP地址连接Ubuntu了。同理Ubunt..._windows使用teamviewer链接ubuntu
异常捕获(二)自定义全局异常捕获-程序员宅基地
文章浏览阅读414次。异常捕获