Docker学习之路06:基于 Docker 在Ubuntu系统部署Hadoop、Hbase以及Spark_ubuntu spark docker-程序员宅基地
技术标签: 练习 笔记 Docker ubuntu spark hadoop hbase docker
基于 Docker 在Ubuntu系统部署Hadoop、Hbase以及Spark
Docker学习路线传送门:
Docker学习之路01:Docker的安装
Docker学习之路02:阿里云镜像加速器
Docker学习之路03:Docker的常用命令
Docker学习之路04:创建定制Nginx镜像
Docker学习之路05:五分钟用docker compose搭建一个自己的个人博客网站!
Docker学习之路06:基于 Docker 在Ubuntu系统部署Hadoop、Hbase以及Spark
一、准备工作
前期需要安装docker和配置镜像加速器
如果还不会的同学可以看下我的《Docker学习之路01:Docker的安装》和《Docker学习之路02:阿里云镜像加速器》
然后今天我们需要基于Docker构建Hadoop平台,通过此平台我们可以更加方便地完成MapReduce等操作
提醒!!!
由于此项目需要在一台虚拟机上部署3个节点,因此比较消耗内存,需要大家将虚拟机内存调到4G以上!
其中,我们是使用 Ubuntu 16.04 系统,如果需要使用其他的系统,则对此篇文章的操作稍作修改即可!
二、启动Docker
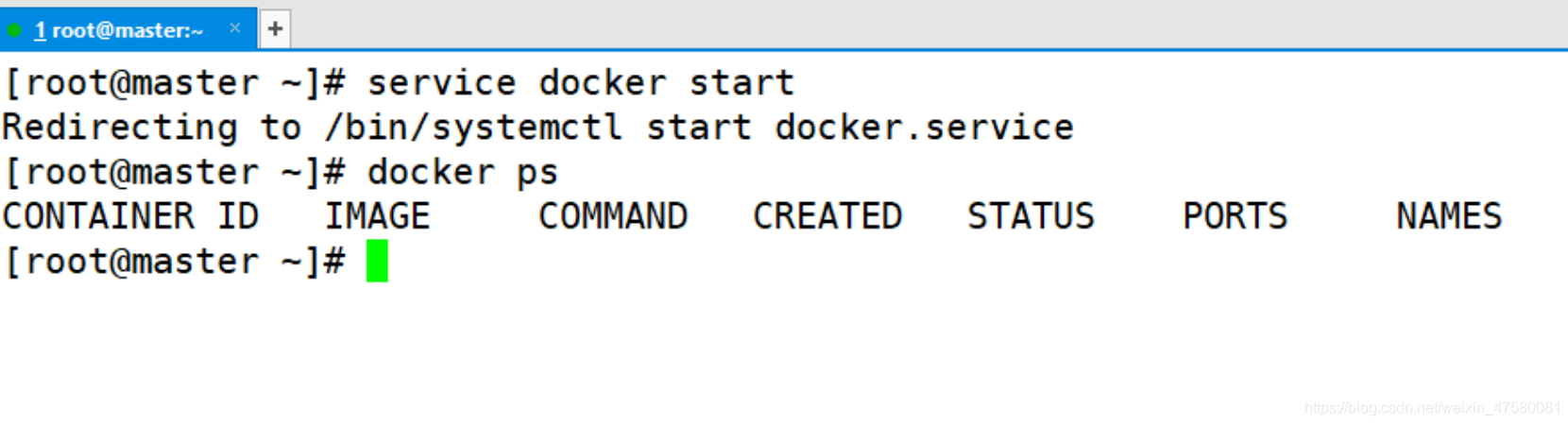
1.启动 Docker 服务
[root@master ~]# service docker start
2.显示 Docker 中所有正在运行的容器
[root@master ~]# docker ps
由于 Docker 刚刚才安装,我们没有运行任何容器,所以显示结果如下所示
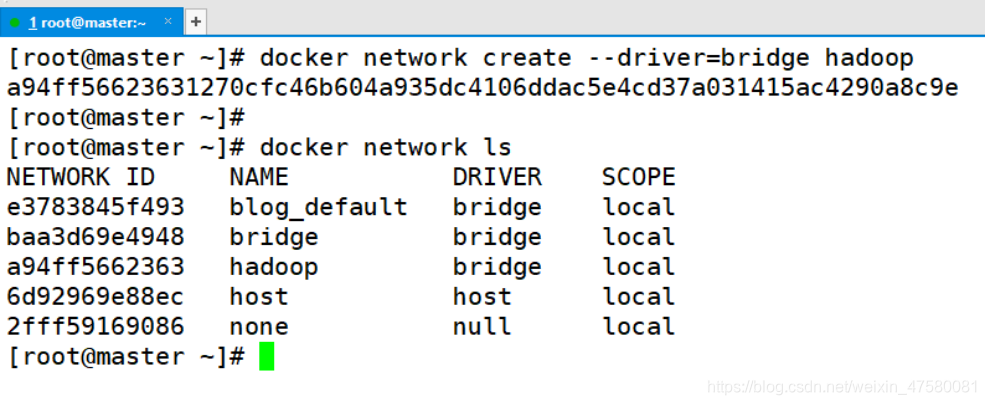
3.Hadoop 集群单独构建一个虚拟的网络
[root@master ~]# docker network create --driver=bridge hadoop
查看 Docker 中的网络
[root@master ~]# docker network ls
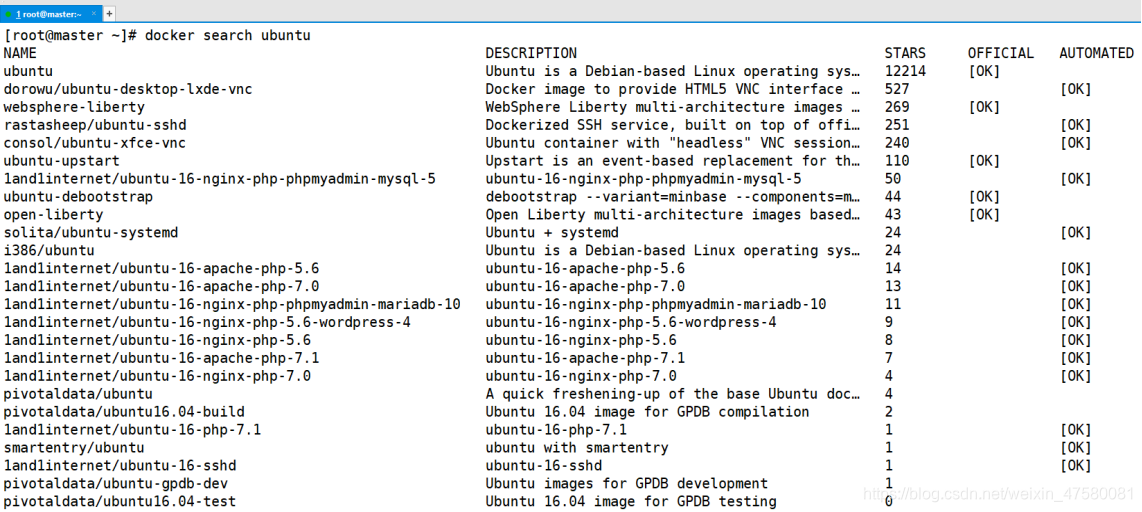
4.查找 ubuntu 容器
[root@master ~]# docker search ubuntu
5.下载 ubuntu 16.04 版本的镜像文件
[root@master ~]# docker pull ubuntu:16.04
16.04: Pulling from library/ubuntu
92473f7ef455: Pull complete
fb52bde70123: Pull complete
64788f86be3f: Pull complete
33f6d5f2e001: Pull complete
Digest: sha256:eed7e1076bbc1f342c4474c718e5438af4784f59a4e88ad687dbb98483b59ee4
Status: Downloaded newer image for ubuntu:16.04
docker.io/library/ubuntu:16.04
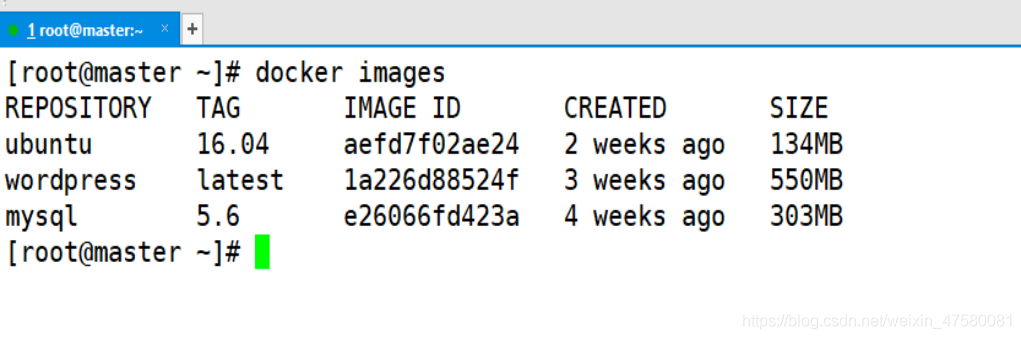
6.查看已经下载的镜像
[root@master ~]# docker images
7.修改 apt 源
7.1 备份一份apt源,防止丢失
root@b426059fcd58:/# cp /etc/apt/sources.list /etc/apt/sources_init.list
7.2 先删除就源文件,这个时候没有 vim 工具
root@b426059fcd58:/# rm /etc/apt/sources.list
7.3 使用 echo 命令将阿里源写入新文件
root@b426059fcd58:/# echo " deb http://mirrors.aliyun.com/ubuntu/ xenial main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
> deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
>
> deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
> deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
> deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe" > /etc/apt/sources.list
阿里源如下:
deb http://mirrors.aliyun.com/ubuntu/ xenial main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial main
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates main
deb http://mirrors.aliyun.com/ubuntu/ xenial universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-updates universe
deb http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security main
deb http://mirrors.aliyun.com/ubuntu/ xenial-security universe
deb-src http://mirrors.aliyun.com/ubuntu/ xenial-security universe
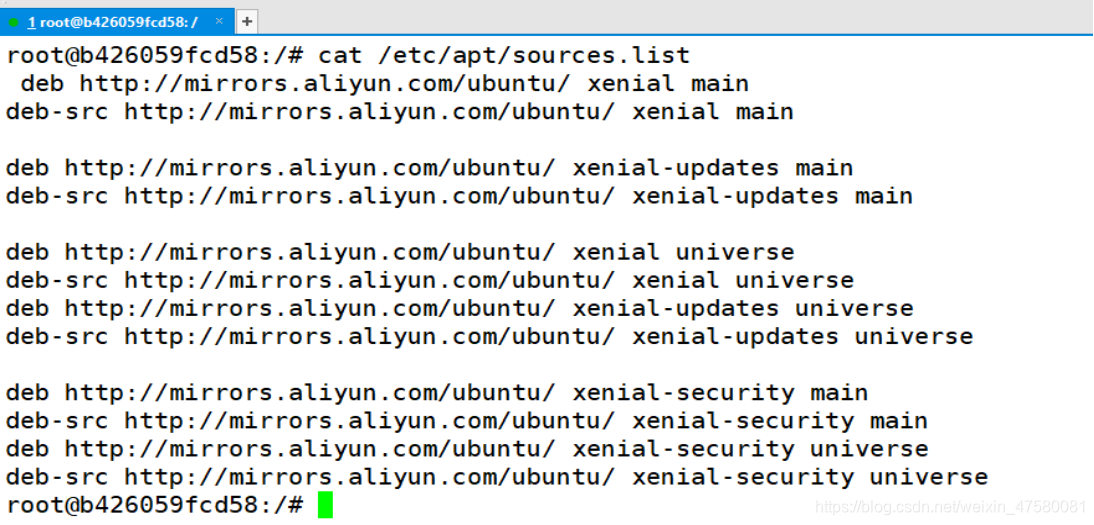
7.4 查看sources.list文件
root@b426059fcd58:/# cat /etc/apt/sources.list
7.5 再使用 apt update 来更新
root@b426059fcd58:/# apt update
三、容器部署Java与Scala
1.安装 jdk 1.8
root@b426059fcd58:/# apt install openjdk-8-jdk
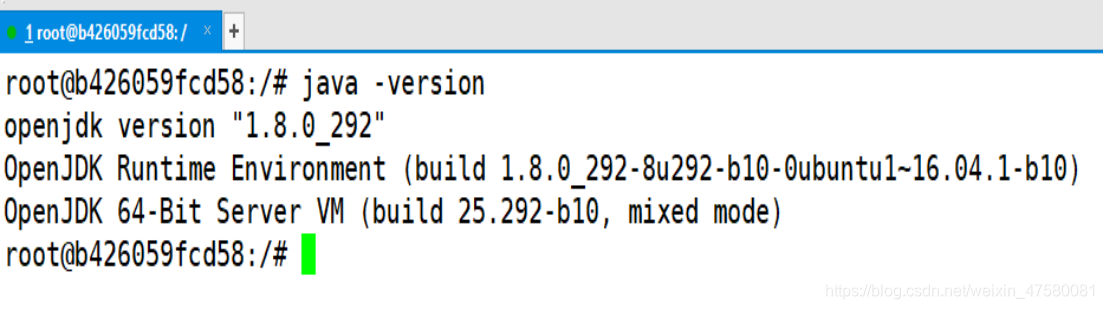
测试一下安装结果
root@b426059fcd58:/# java -version
2.安装 Scala
root@b426059fcd58:/# apt install scala
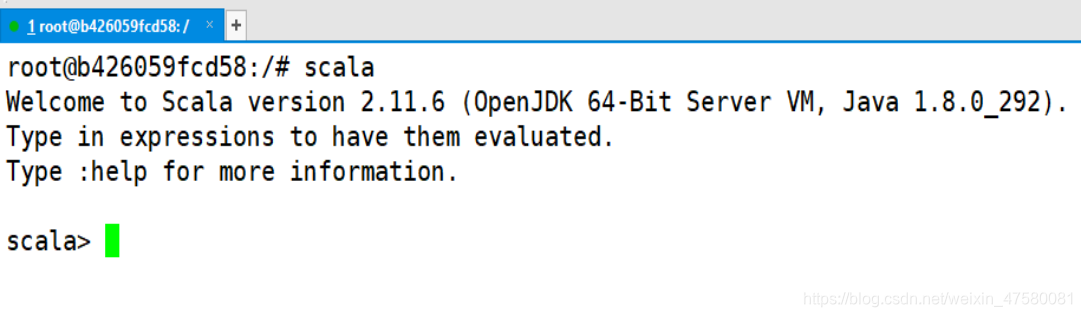
测试一下安装结果
root@b426059fcd58:/# scala
四、容器部署Hadoop
1.安装 vim,用来编辑文件
root@b426059fcd58 :/# apt install vim
2.安装 net-tools
root@b426059fcd58 :/# apt install net-tools
3.安装 SSH
root@b426059fcd58 :/# apt-get install openssh-server
4.安装 SSH 的客户端
root@b426059fcd58 :/# apt-get install openssh-client
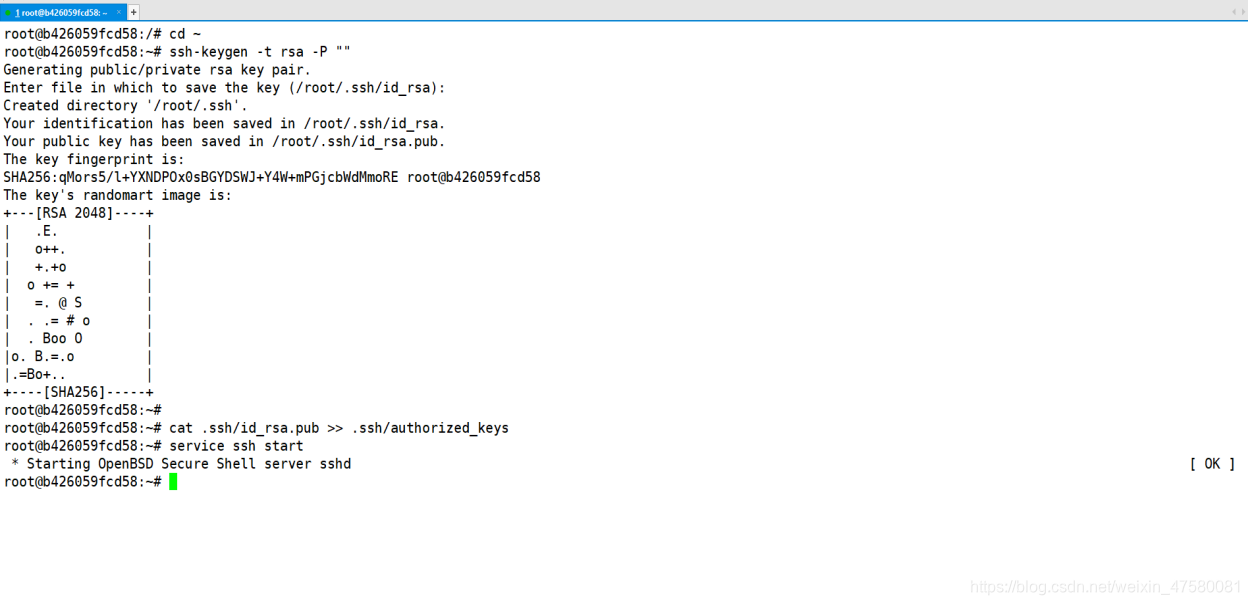
root@b426059fcd58:/# cd ~
root@b426059fcd58:~# ssh-keygen -t rsa -P "„
5.启动 SSH 服务
root@b426059fcd58:~# service ssh start
6.免密登录自己
root@b426059fcd58:~# ssh 127.0.0.1
7.设置自启SSH服务
root@b426059fcd58:~# vim ~/.bashrc
添加内容如下:
service ssh start
7.安装 Hadoop
7.1下载 Hadoop 的安装文件并传入docker
[root@master software]# docker cp hadoop-3.2.0.tar.gz b426059fcd58:/opt/software
7.2解压到 /usr/local 目录下面并重命名文件夹
root@b426059fcd58:# mkdir /opt/software
root@b426059fcd58:/opt/software# tar -zxvf hadoop-3.2.0.tar.gz -C /usr/local/
root@b426059fcd58:/opt/software# cd /usr/local/
root@b426059fcd58:/usr/local# mv hadoop-3.2.0 hadoop
7.3 配置profile 文件
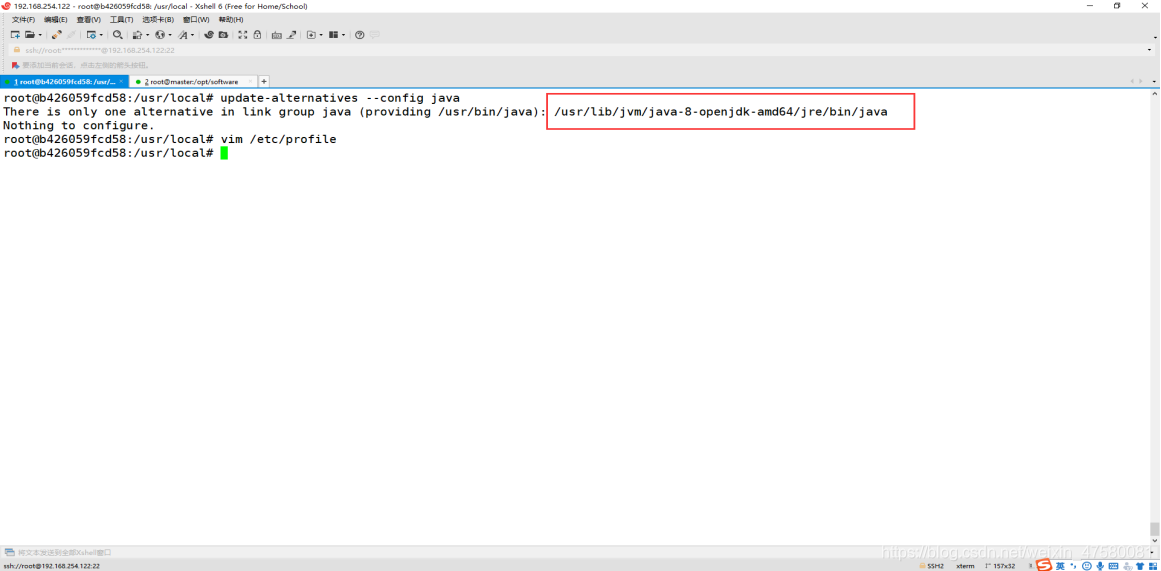
查看使用apt安装java的路径
root@b426059fcd58:/usr/local# update-alternatives --config java
root@b426059fcd58:/usr/local# vim /etc/profile
将apt安装java的路径复制
将apt安装java的路径赋值给JAVA_HOME
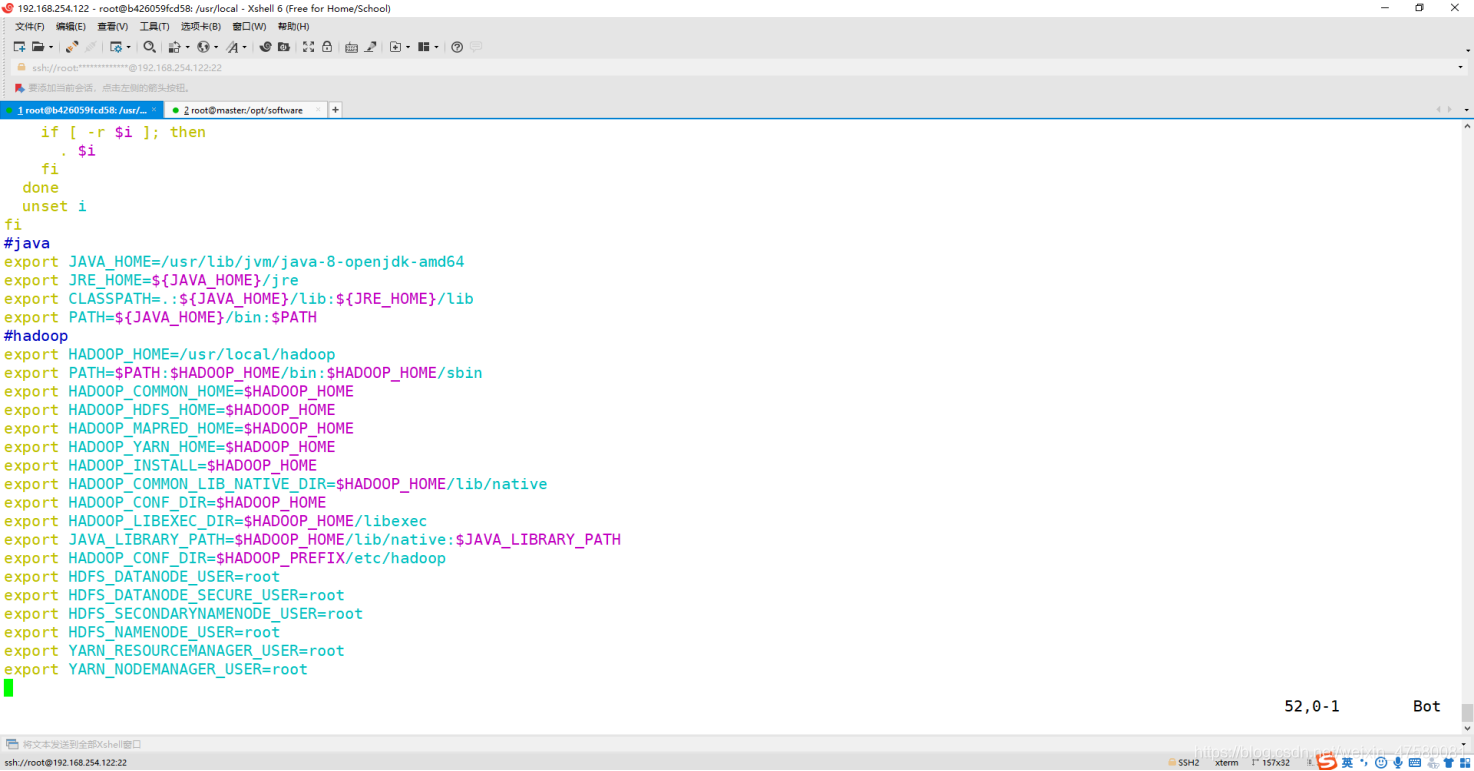
添加内容如下:
#java
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export JRE_HOME=${
JAVA_HOME}/jre
export CLASSPATH=.:${
JAVA_HOME}/lib:${
JRE_HOME}/lib
export PATH=${
JAVA_HOME}/bin:$PATH
#hadoop
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_YARN_HOME=$HADOOP_HOME
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_CONF_DIR=$HADOOP_HOME
export HADOOP_LIBEXEC_DIR=$HADOOP_HOME/libexec
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
export HADOOP_CONF_DIR=$HADOOP_PREFIX/etc/hadoop
export HDFS_DATANODE_USER=root
export HDFS_DATANODE_SECURE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export HDFS_NAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
使环境变量生效
root@b426059fcd58:/usr/local# source /etc/profile
7.4在目录 /usr/local/hadoop/etc/hadoop 下修改hadoop配置文件
需要修改的配置文件如下:
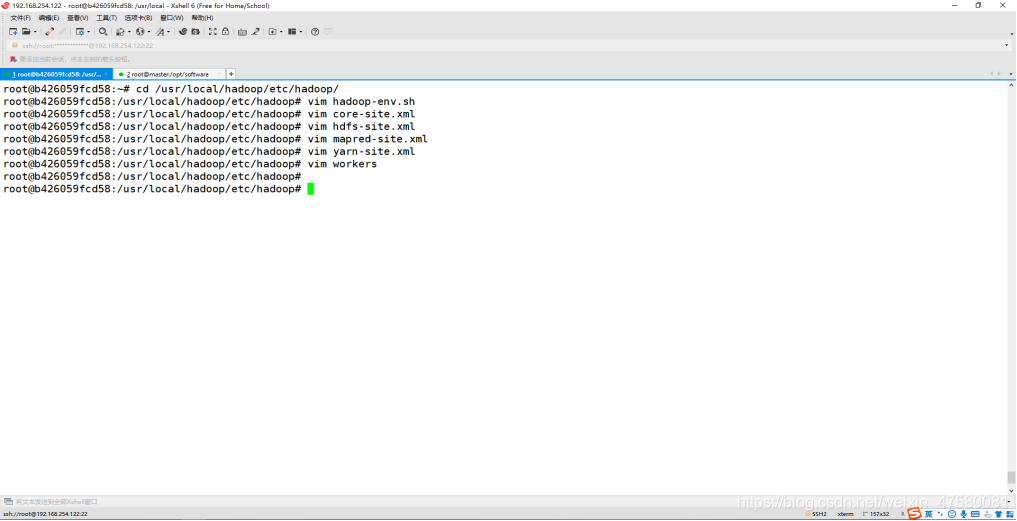
修改 hadoop-env.sh 文件
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim hadoop-env.sh
添加内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
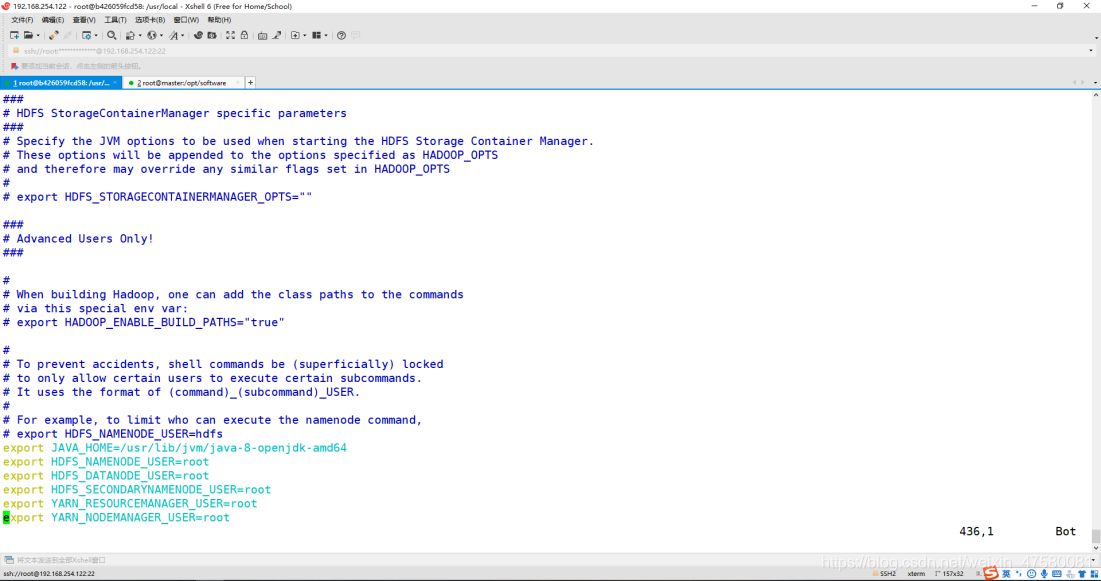
修改 core-site.xml
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim core-site.xml
添加内容如下:
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://h01:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop3/hadoop/tmp</value>
</property>
</configuration>
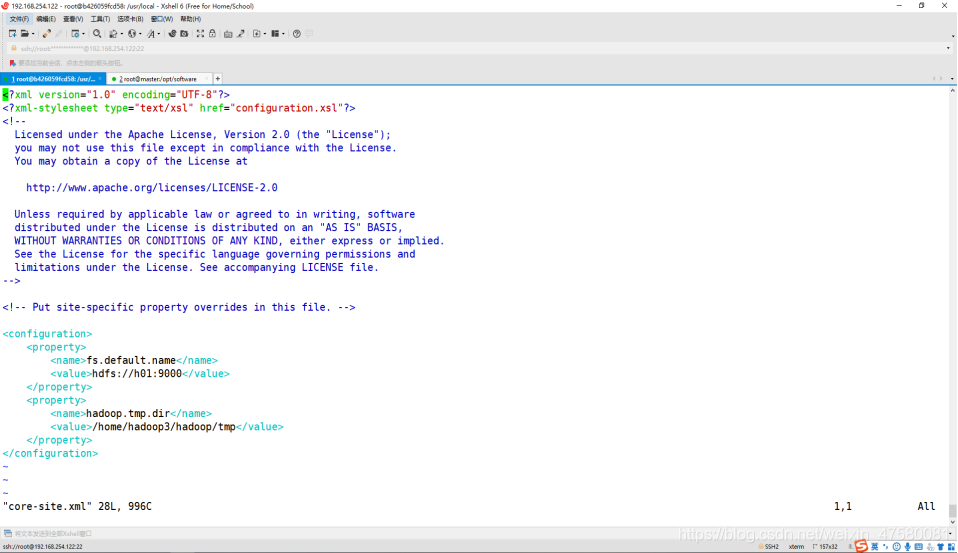
修改 hdfs-site.xml
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim hdfs-site.xml
添加内容如下:
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hadoop3/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.namenode.data.dir</name>
<value>/home/hadoop3/hadoop/hdfs/data</value>
</property>
</configuration>

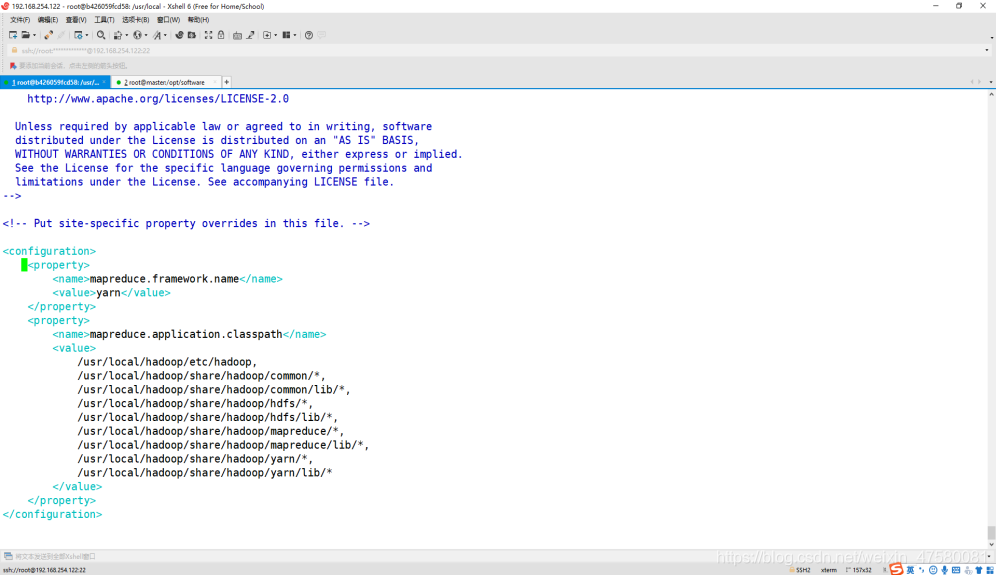
修改 mapred-site.xml
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim mapred-site.xml
添加内容如下:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>
/usr/local/hadoop/etc/hadoop,
/usr/local/hadoop/share/hadoop/common/*,
/usr/local/hadoop/share/hadoop/common/lib/*,
/usr/local/hadoop/share/hadoop/hdfs/*,
/usr/local/hadoop/share/hadoop/hdfs/lib/*,
/usr/local/hadoop/share/hadoop/mapreduce/*,
/usr/local/hadoop/share/hadoop/mapreduce/lib/*,
/usr/local/hadoop/share/hadoop/yarn/*,
/usr/local/hadoop/share/hadoop/yarn/lib/*
</value>
</property>
</configuration>
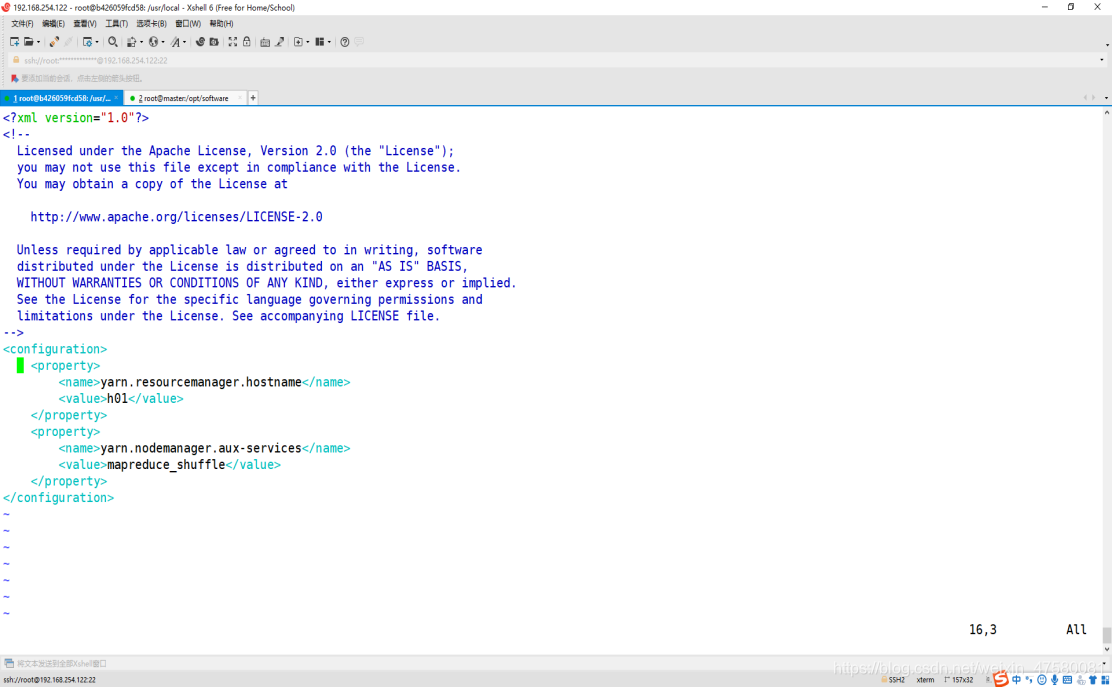
修改 yarn-site.xml
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim yarn-site.xml
添加内容如下:
<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>h01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
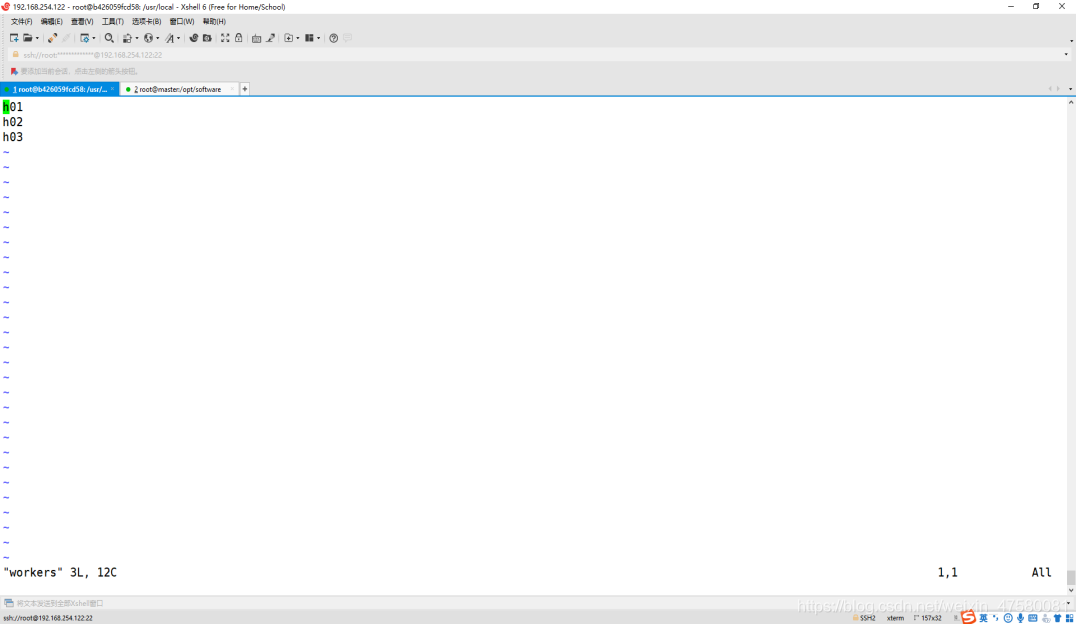
修改 worker
root@b426059fcd58:/usr/local/hadoop/etc/hadoop# vim worker
添加内容如下:
h01
h02
h03
此时,hadoop已经配置好了!
五、Docker构建镜像并启动集群
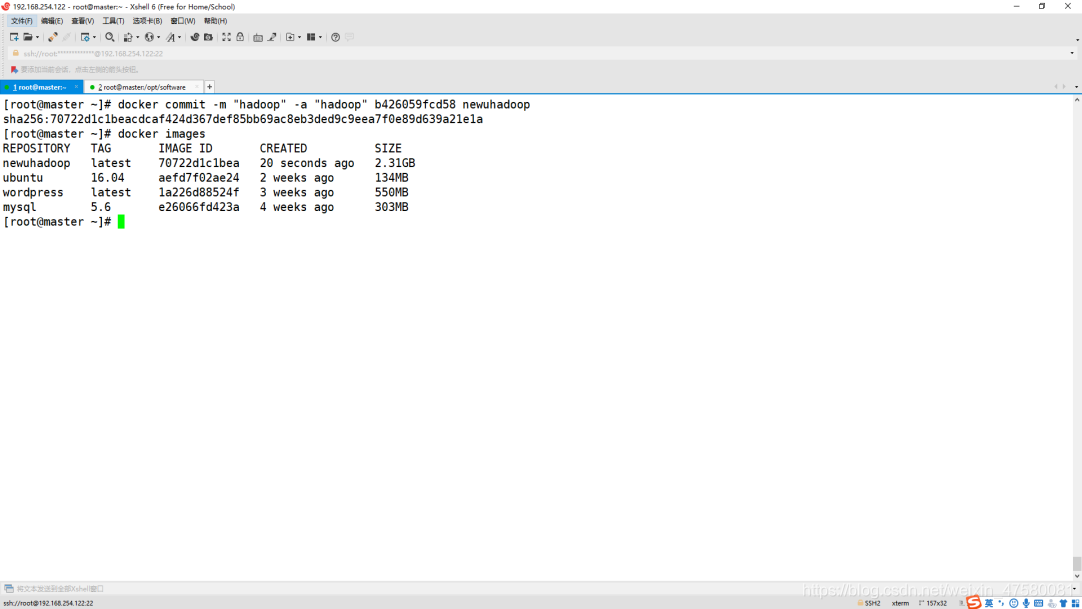
1.先将当前容器导出为镜像,并查看当前镜像
[root@master ~]# docker commit -m "hadoop" -a "hadoop" b426059fcd58 newuhadoop
[root@master ~]# docker images
2.启动3个终端
第一个终端
[root@master ~]# docker run -it --network hadoop -h "h01" --name "h01" -p 9870:9870 -p 8088:8088 newuhadoop /bin/bash
* Starting OpenBSD Secure Shell server sshd [ OK ]
第二个终端
[root@master ~]# docker run -it --network hadoop -h "h02" --name "h02" newuhadoop /bin/bash
* Starting OpenBSD Secure Shell server sshd [ OK ]
第三个终端
[root@master ~]# docker run -it --network hadoop -h "h03" --name "h03" newuhadoop /bin/bash
* Starting OpenBSD Secure Shell server sshd [ OK ]
六、Hadoop集群测试
1.在 h01 主机中进行格式化操作
root@h01:/# /usr/local/hadoop/bin/hadoop namenode –format
2.启动Hadoop
root@h01:/# cd /usr/local/hadoop/sbin/
root@h01:/usr/local/hadoop/sbin# ./start-all.sh
此时 Hadoop 集群到这已经构建好了,我们开始测试!
3.运行内置WordCount例子
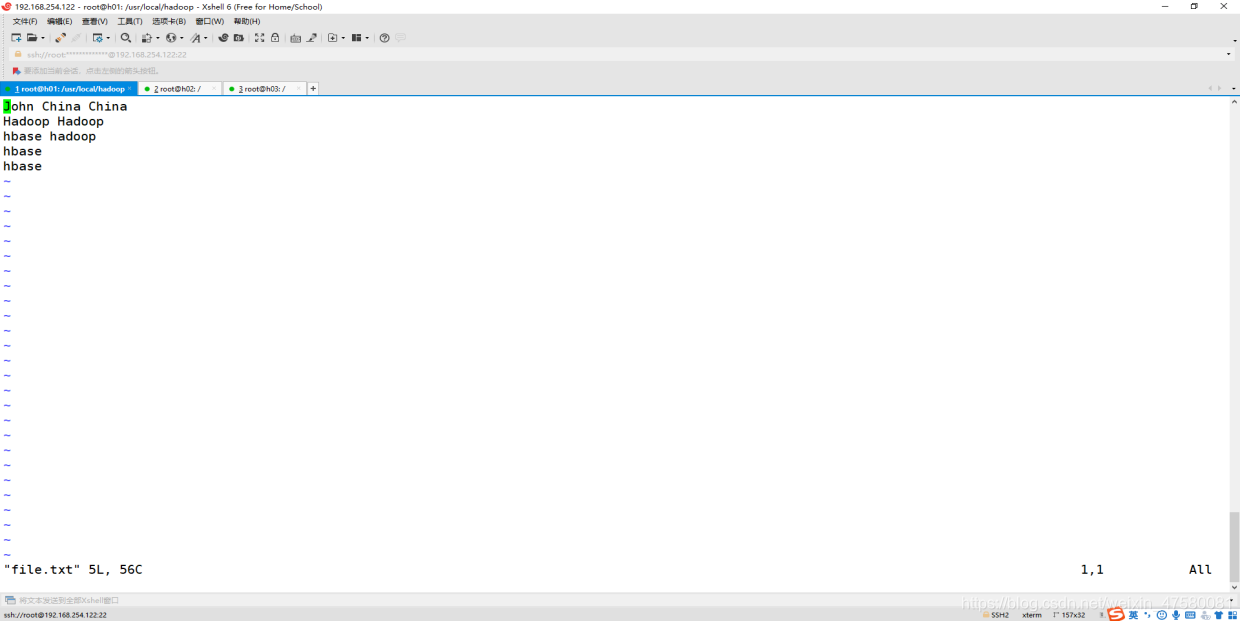
3.1把file作为需要统计的文件
root@h01:/usr/local/hadoop# cd /usr/local/hadoop/
root@h01:/usr/local/hadoop# vim file.txt
3.2在 HDFS 中创建 input 文件夹
root@h01:~# cd /usr/local/hadoop/bin/
root@h01:/usr/local/hadoop/bin# ./hadoop fs -mkdir /input
3.3上传 file.txt 文件到 HDFS 中
root@h01:/usr/local/hadoop/bin# ./hadoop fs -put /opt/software/file.txt /input
3.4查看 HDFS 中 input 文件夹里的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -ls /input
Found 1 items
-rw-r--r-- 2 root supergroup 38 2021-05-10 06:36 /input/file.txt
3.5运作 wordcount 例子程序
root@h01:/usr/local/hadoop/bin# ./hadoop jar ../share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.0.jar wordcount /input /output
3.6查看 HDFS 中的 /output 文件夹的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -ls /output
Found 2 items
-rw-r--r-- 2 root supergroup 0 2019-03-19 11:18 /output/_SUCCESS
-rw-r--r-- 2 root supergroup 35324 2019-03-19 11:18 /output/part-r-00000
3.7查看 part-r-00000 文件的内容
root@h01:/usr/local/hadoop/bin# ./hadoop fs -cat /output/part-r-00000
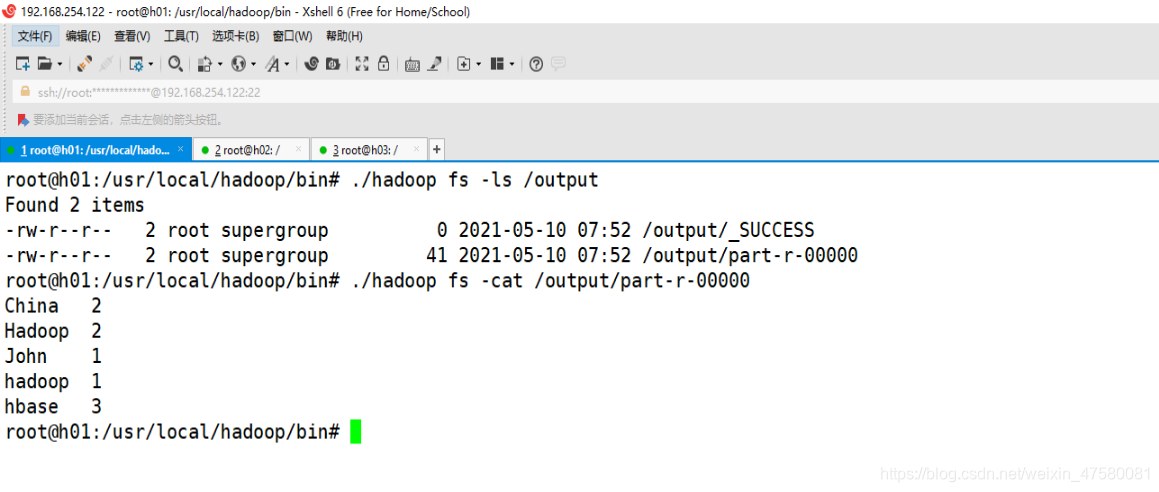
可以看到wordcount计算的结果正确,那么 Hadoop 部分结束了!
七、Hadoop集群上部署Hbase
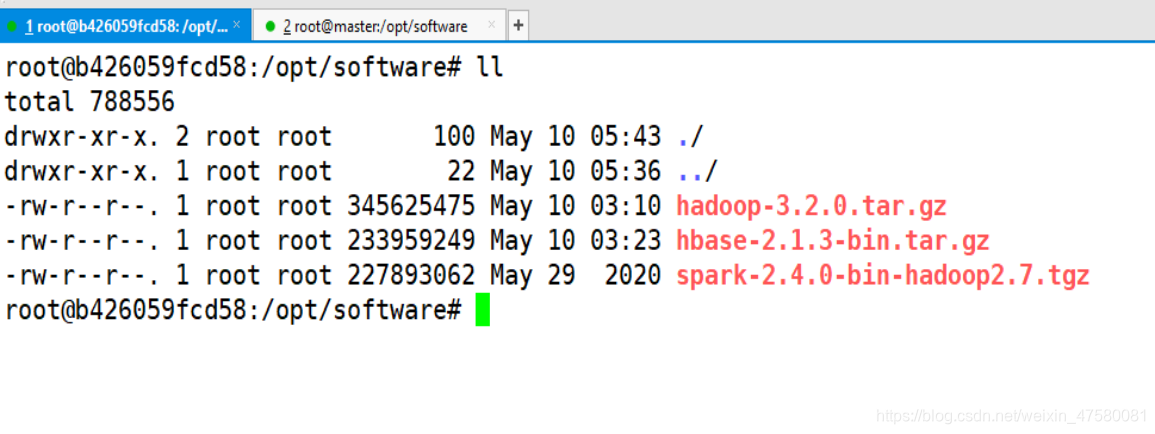
1.下载 Hbase 的安装文件并传入docker
[root@master software]# docker cp hbase-2.1.3-bin.tar.gz b426059fcd58:/opt/software
2.解压到 /usr/local 目录下面
root@h01:/opt/software# cd /opt/software/
root@h01:/opt/software# tar -zxvf hbase-2.1.3-bin.tar.gz -C /usr/local/
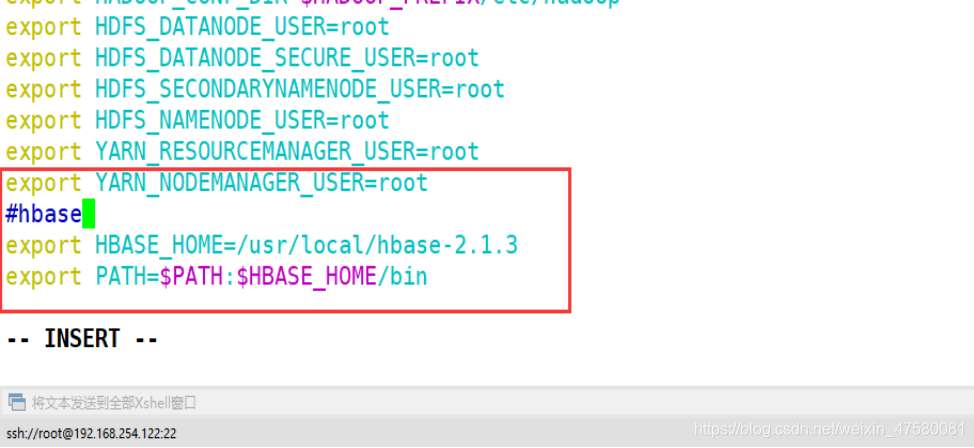
3.修改 /etc/profile 环境变量文件
root@h01:/opt/software# vim /etc/profile
添加 Hbase 的环境变量,追加下述代码
#hbase
export HBASE_HOME=/usr/local/hbase-2.1.3
export PATH=$PATH:$HBASE_HOME/bin
使环境变量配置文件生效
root@h01:/opt/software# source /etc/profile
4.在目录 /usr/local/hbase-2.1.3/conf 修改配置文件
root@h01:/opt/software# cd /usr/local/hbase-2.1.3/conf
修改 hbase-env.sh
root@h01:/opt/software# vim hbase-env.sh
添加内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HBASE_MANAGES_ZK=true

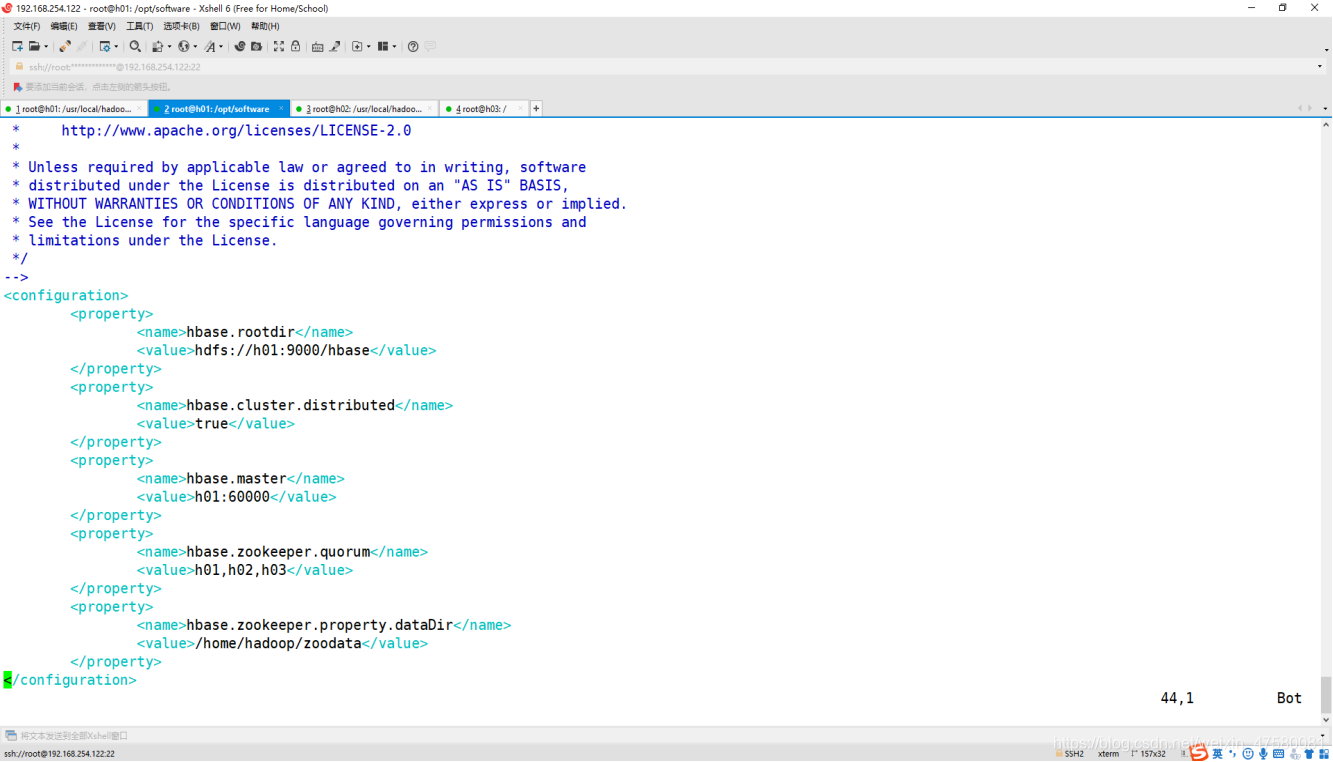
修改 hbase-site.xml
root@h01:/opt/software# vim hbase-site.xml
修改内容如下:
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://h01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.master</name>
<value>h01:60000</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>h01,h02,h03,h04,h05</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/home/hadoop/zoodata</value>
</property>
</configuration>
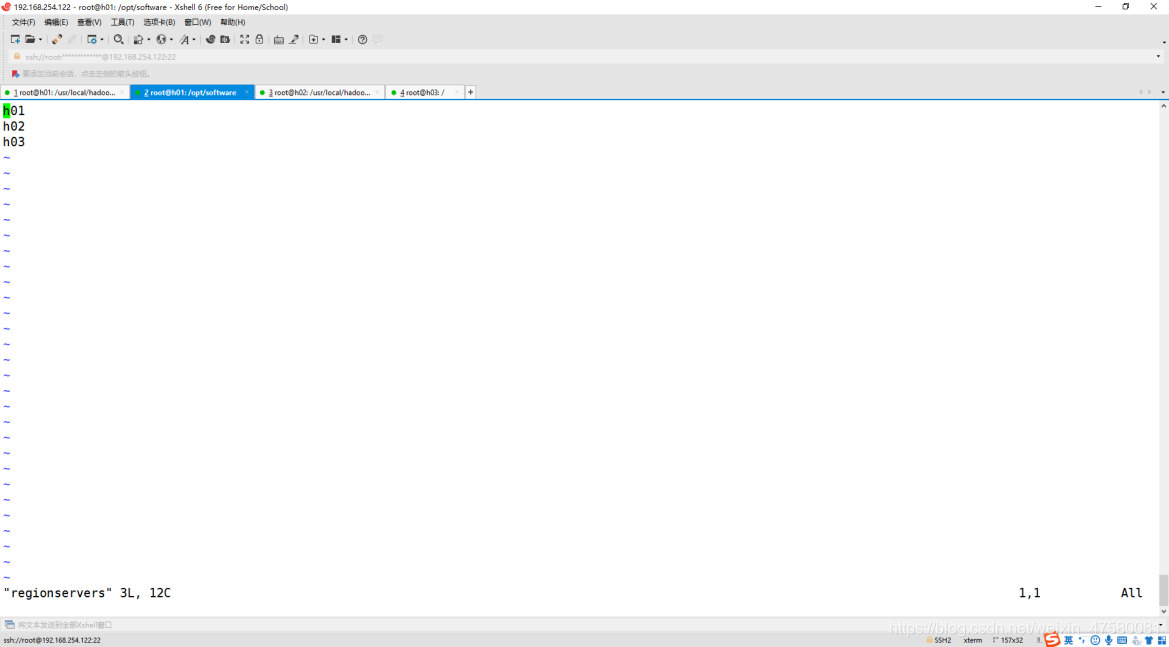
修改 regionservers 文件
root@h01:/opt/software# vim regionservers
添加内容如下:
h01
h02
h03
5.使用 scp 命令将配置好的 Hbase 复制到其他 4 个容器中
root@h01:~# scp -r /usr/local/hbase-2.1.3 root@h02:/usr/local/
root@h01:~# scp -r /usr/local/hbase-2.1.3 root@h03:/usr/local/
root@h01:~# scp -r /etc/profile root@h02:/etc/profile
root@h01:~# scp -r /etc/profile root@h03:/etc/profile
h02和h03 记得source一下Profile文件哦~
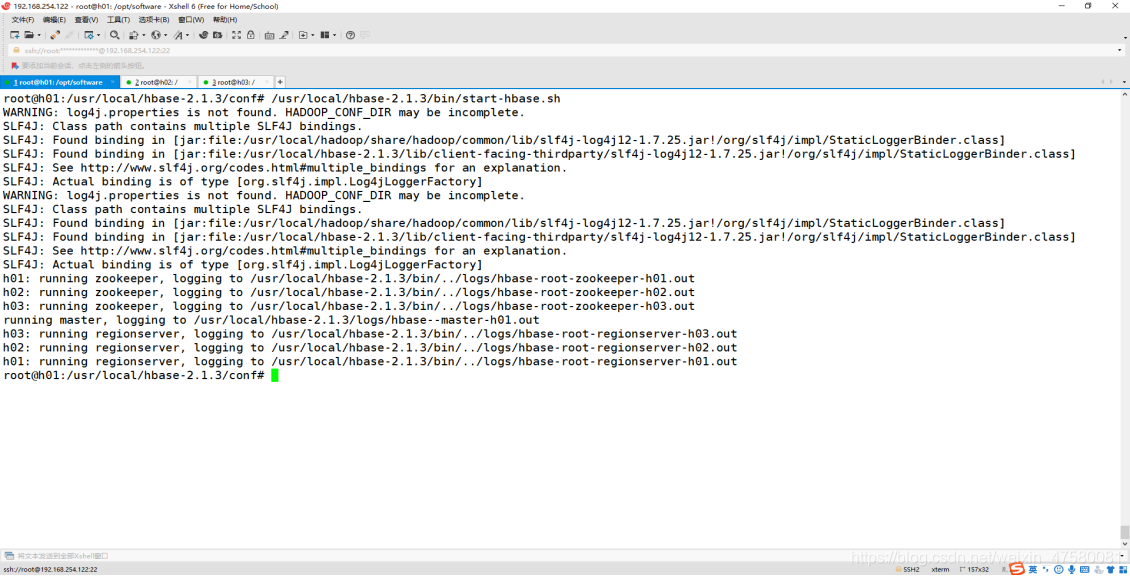
6.启动 Hbase
root@h01:~# /usr/local/hbase-2.1.3/bin/start-hbase.sh
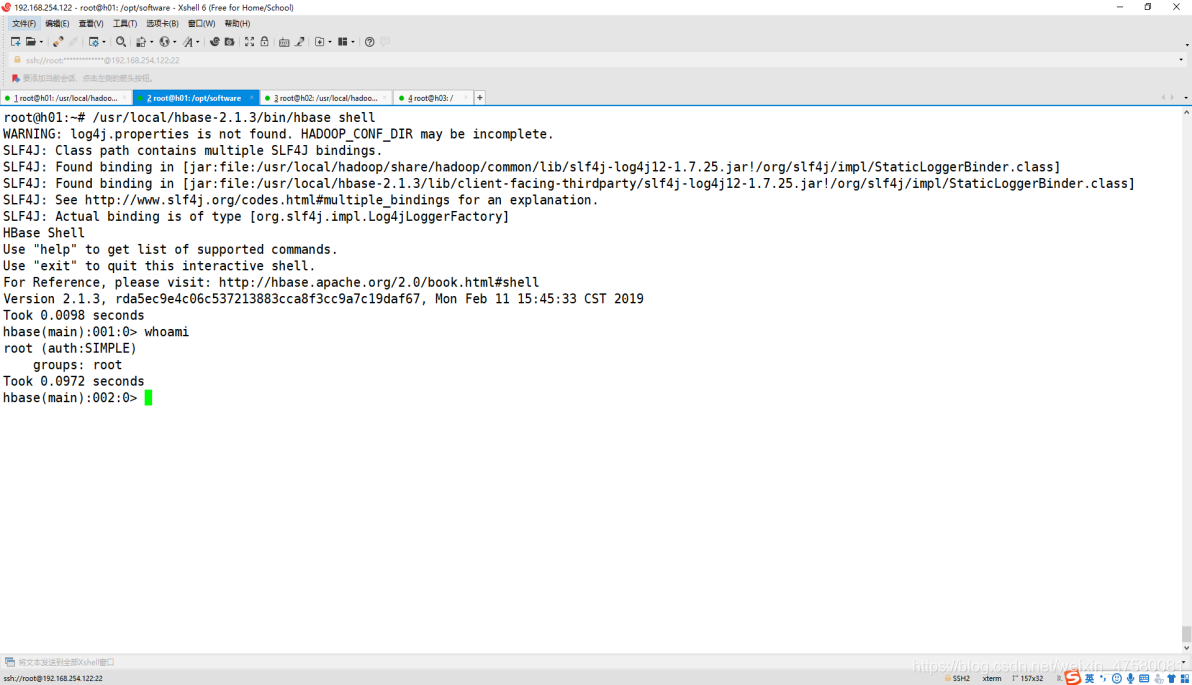
7.打开 Hbase 的 shell
root@h01:~# /usr/local/hbase-2.1.3/bin/hbase shell
到此Hbase就部署成啦!
八、Hadoop集群上部署Spark
1.下载 Hadoop 的安装文件并传入docker
[root@master software]# docker cp spark-2.4.0-bin-hadoop2.7.tgz b426059fcd58:/opt/software
2.解压到 /usr/local 目录下面
root@h01:~# tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz -C /usr/local/
3.修改文件夹的名字
root@h01:/opt/software# cd /usr/local/
root@h01:/usr/local# mv spark-2.4.0-bin-hadoop2.7 spark-2.4.0
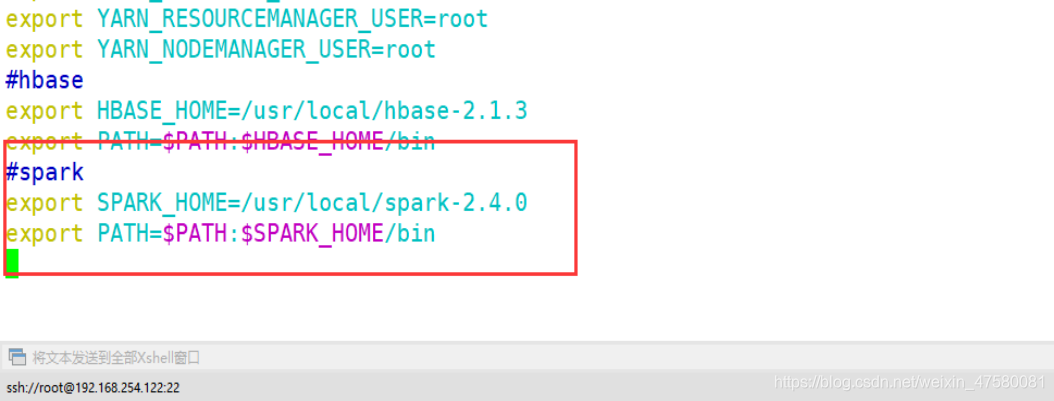
4.修改 /etc/profile 环境变量文件
root@h01:/opt/software# vim /etc/profile
export SPARK_HOME=/usr/local/spark-2.4.0
export PATH=$PATH:$SPARK_HOME/bin
5.使环境变量配置文件生效
root@h01:/usr/local# source /etc/profile
5.在目录 /usr/local/spark-2.4.0/conf 修改配置
root@h01:/usr/local/spark-2.4.0/conf# cd /usr/local/spark-2.4.0/conf/
root@h01:/usr/local/spark-2.4.0/conf# mv spark-env.sh.template spark-env.sh
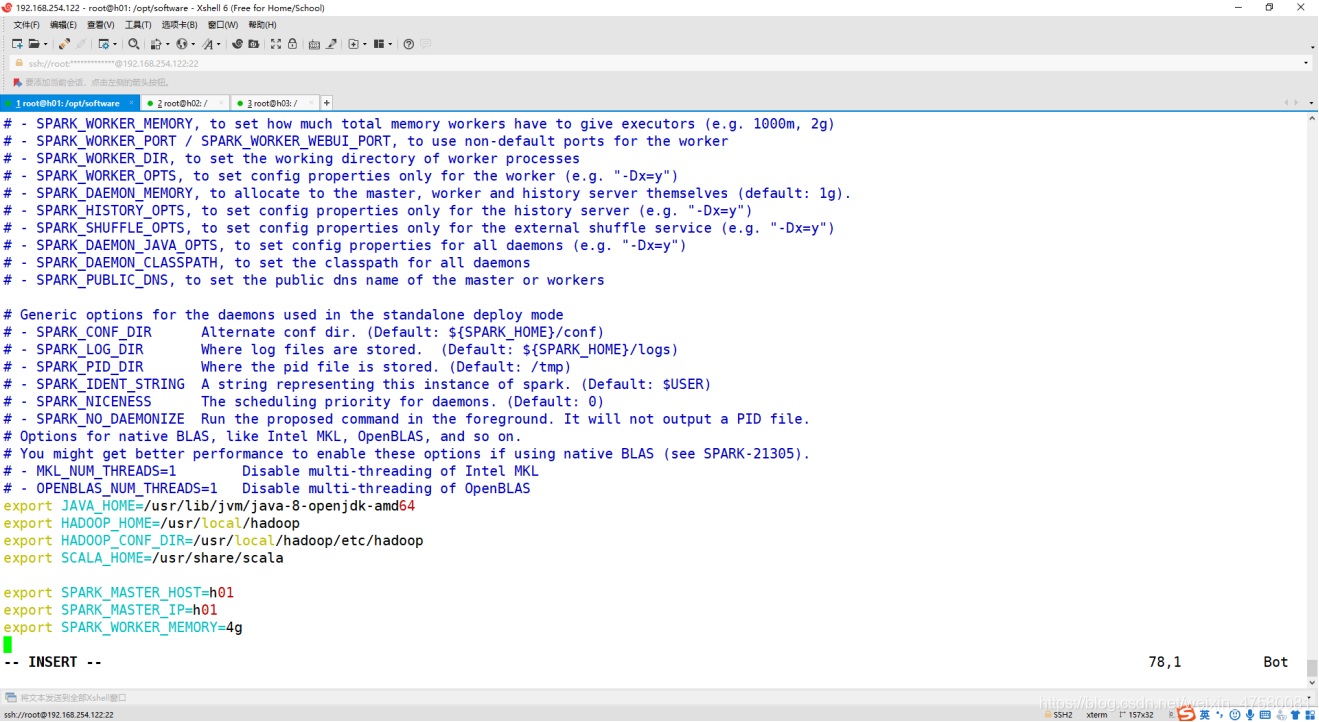
修改 spark-env.sh
root@h01:/opt/software# vim spark-env.sh
追加内容如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_CONF_DIR=/usr/local/hadoop/etc/hadoop
export SCALA_HOME=/usr/share/scala
export SPARK_MASTER_HOST=h01
export SPARK_MASTER_IP=h01
export SPARK_WORKER_MEMORY=4g
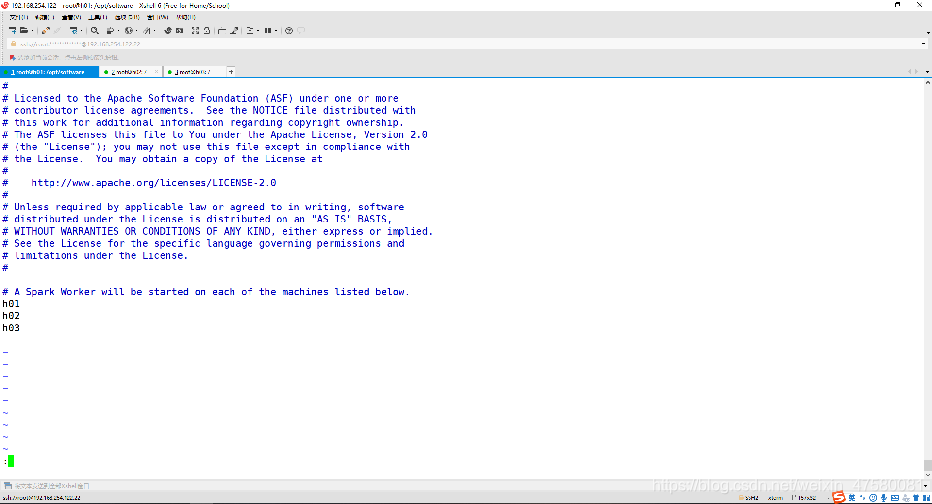
修改 slaves
root@h01:/opt/software# vim slaves
修改内容如下:
h01
h02
h03
6.使用 scp 命令将配置好的 Hbase 复制到其他 4 个容器中
root@h01:~# scp -r /usr/local/spark-2.4.0 root@h02:/usr/local/
root@h01:~# scp -r /usr/local/spark-2.4.0 root@h03:/usr/local/
root@h01:~# scp -r /etc/profile root@h02:/etc/profile
root@h01:~# scp -r /etc/profile root@h02:/etc/profile
h02和h03 记得source一下Profile文件哦~
7.启动 Spark
root@h01:~# cd /usr/local/spark-2.4.0/
root@h01:/usr/local/spark-2.4.0# sbin/start-all.sh
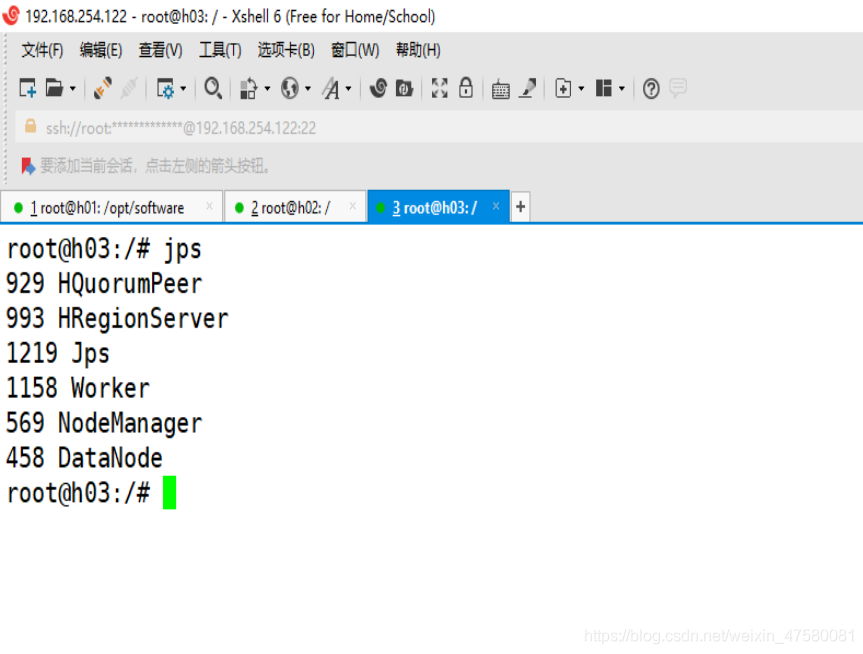
查看各节点的进程
h01
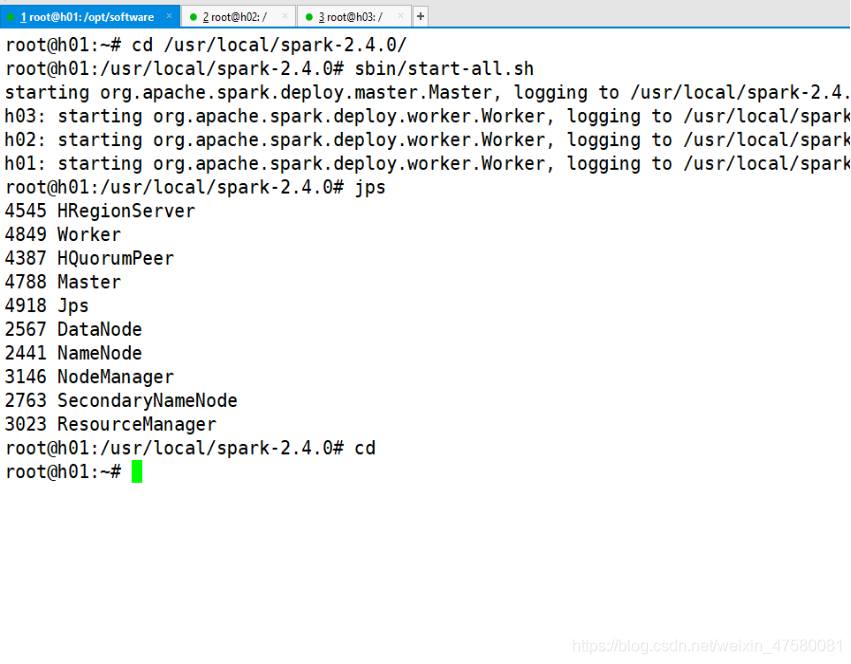
h02
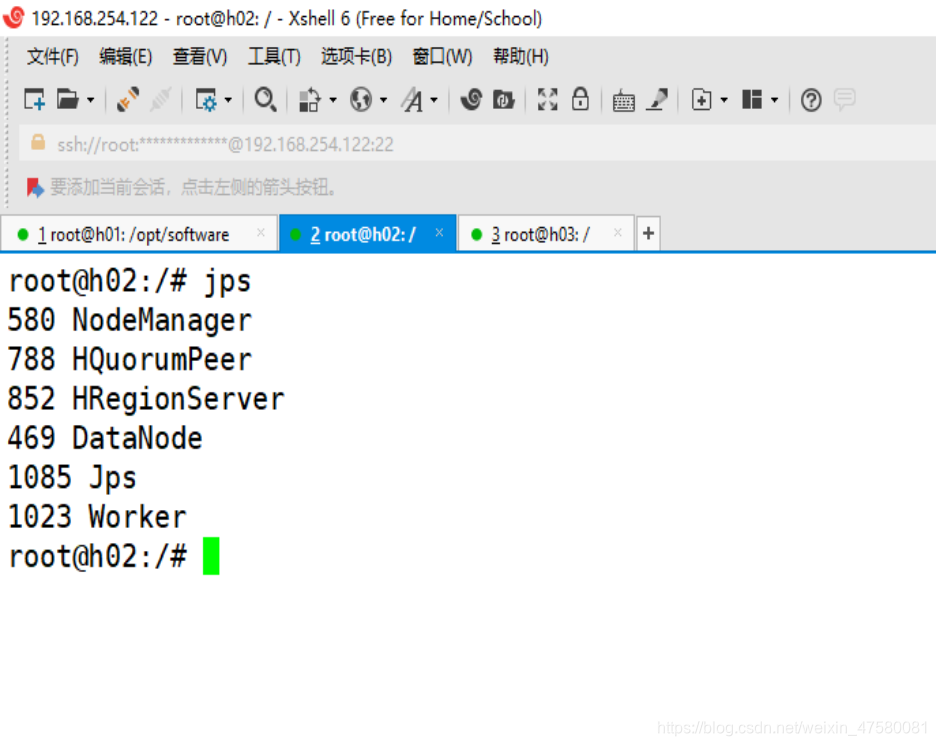
h03
8.Spark客户端连接
root@h01:~# cd /usr/local/spark-2.4.0/bin/
root@h01:/usr/local/spark-2.4.0/bin# spark-shell --master spark://h01:7077
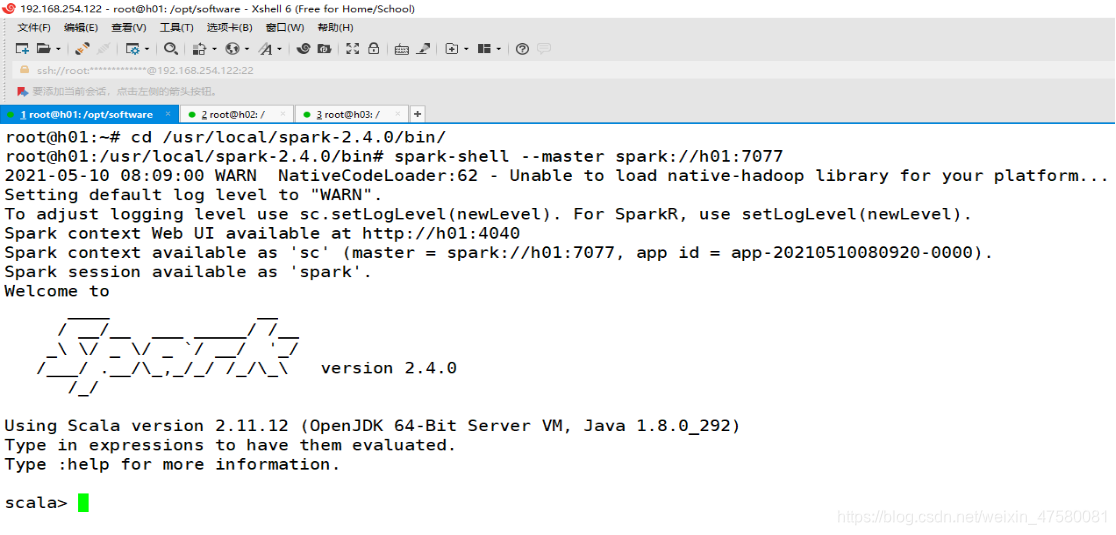
到此Spark就部署成啦!
九、实验中的问题
1.关于内存:
的确这个项目对单个节点的内存要求还是蛮大的,如果前期没有将内存拉到6G,估计在mapreduce的时候就会卡住,甚至在构建镜像的时候就显示 “no space left on device” 的报错,导致整个项目不能继续进行!
2.关于配置:
由于与正常搭建过程有存在一些差异,配置文件中不是特别完整,导致格式化和集群启动时会报一些警告,不过不会特别影响正常操作,实际操作的时候得将配置调试正确后再进行使用!
3.关于 Running job 跑不动:
跑了几次mapreduce之后,如果重新启动hadoop再执行jar时,就会一直卡在Running job不继续mapreduce,很大的原因是在于内存的不足,导致yarn不能正常的运行!
十、总结
在这段时间对docker的学习,我总结了docker的以下三点优势:
快
节约时间,快速部署和启动,VM启动一般是分钟级,Docker容器启动是秒级,而且Docker将应用和系统“容器化”,只要最核心的操作系统。
省
节约成本,以前一个虚拟机至少需要几个G的磁盘空间,Docker容器可以减少到MB级。
稳
Docker的图标是集装箱,集装箱可以有效做到货物之间的隔离,使化学物品和食品可以堆砌在一起运输。Docker可以隔离不同应用程序之间的相互影响,而且比虚拟机开销更小。
智能推荐
java中所有的类都继承于_Java中所有的类都是通过直接或间接地继承( )类得到的...-程序员宅基地
文章浏览阅读4.2k次。Java中所有的类都是通过直接或间接地继承( )类得到的答:java.lang.Object关于主机地址 192.168.19.125 (子网掩码: 255.255.255.248 ),以下说法正确答:广播地址为:192.168.19.127 ; 网络地址为:192.168.19.120 ;在小儿基本手法中,逆运内八卦的功效是?(??)答:宽胸利膈,行滞消食对事物的知觉是答:人脑对直接作用感官的..._java中所有的类都是通过直接或间接地继承( )类得到的。 2分 a、java.lang.object
【幻化万千戏红尘】qianfengDay21-java基础学习:进程、线程、Timer-程序员宅基地
文章浏览阅读222次。课程回顾:面向对象数组异常常用类集合IO流今日内容:进程:应用程序运行时,产生的独立的应用程序,拥有独立的代码和存储空间多进程:操作系统可以并发的执行多个进程线程:进程内部的一条执行路径多线程:java语言支持程序内部进行多线程开发进程内部可以有多个线程线程的作用:可以分担压力,提高性能主要用来完成耗时
重生奇迹mu武器镶嵌顺序-程序员宅基地
文章浏览阅读71次。例如:雷1J10%冰技能+37火每等级,这样就可以30%出现属性,如果没有出,可以破坏某一个洞,继续镶嵌同属性的宝石,直到定现为止,由于1J雷和37技能冰的比较贵,所以可以破坏火荧石,不断镶嵌到出现属性为止。荧光宝石可从以前的物品中获得。从上到下的镶嵌顺寻按照雷、冰、火镶嵌,就有30%的概率出现技能攻击力加11的幸运荧光属性。从上到下的镶嵌顺寻按照土、风、水镶嵌,就有30%的概率出现最大生命值+29的幸运荧光属性。从上到下的镶嵌顺寻按照火、冰、雷镶嵌,就有30%的概率出现攻击力加11的幸运荧光属性。
人工智能第三章(1)——无信息搜索(盲目搜索) (附书本资料)_无信息搜索又称为-程序员宅基地
文章浏览阅读8.8k次,点赞21次,收藏51次。这篇文章的意义在于哪里呢?1)向大家展示如何形式化定义一个搜索问题,又如何去求解;2)通过讲述各种盲目搜索算法,帮大家梳理无信息搜索的脉络。_无信息搜索又称为
【图像重建】基于小波变换结合BP、OMP、StOMP实现图像重建含MSE PSNR附Matlab代码-程序员宅基地
文章浏览阅读847次,点赞18次,收藏20次。图像重建是数字信号处理领域的一个重要问题,它涉及到从损坏或不完整的图像数据中恢复出高质量的图像。在图像重建的研究中,小波变换结合各种重建算法已经成为一个热门的研究方向。本文将介绍基于小波变换结合BP、OMP、StOMP算法实现图像重建,并对重建效果进行评估,包括均方误差(MSE)和峰值信噪比(PSNR)。小波变换是一种多尺度分析方法,它可以将信号分解成不同尺度的频率成分,从而更好地捕捉信号的局部特征。在图像重建中,小波变换可以将图像分解成不同尺度的小波系数,然后利用这些小波系数进行重建。
指针数组 数组指针 的判断_int*做参数如何判断是整型还是数组-程序员宅基地
文章浏览阅读685次。用变量a给出下面的定义:一个有10个指针的数组,该指针指向一个函数,该函数有一个整形参数并返回一个整型数*int a[10];这是一个指针数组。数组a里存放的是10个int型指针*int (a)[10];这是一个数组指针。a是指针,指向一个数组。数组a有10个int型元素。*int (a)(int);这个表示一个内存空间,这个空间用来存放一个指针,这个指针指向一个函数,这个函数有一个类..._int*做参数如何判断是整型还是数组
随便推点
Android 单独抽取 WebRtc-VAD(语音端点检测) 模块_android webrtc vad-程序员宅基地
文章浏览阅读3.7k次,点赞3次,收藏10次。本文基于webrtc最新源码进行抽取编译做简单讲解。最终目的是Android 单独抽取 WebRtc-VAD 模块,封装好JNI层,并且ndk-build出so库。希望对大家有所帮助,有需要看JNI层实现和完整demo的,请加我V:15092216090先来看一下vad模块的头文件,webrtc_vad.h,该文件路径为common_audio\vad\include\webrtc_v..._android webrtc vad
夏天到,装饰器让Python秀出性感属性:Property+Decorators+-+Getters,+Setters,+and+Deleters_@property (decorators)-程序员宅基地
文章浏览阅读262次。John Smith曾经是我的好基友,没有之一,今天我们拿他做个试验:初始代码,我们做一个打印员工John Smith信息的类,实例emp_1会用类属性输出:class Employee: def __init__(self, first, last): self.first = first self.last = last self.email = first + "." + last + '@email.com' def fullnam_@property (decorators)
Oracle单个字段多记录拼接_oracle 一个字段多条记录的拼接-程序员宅基地
文章浏览阅读2.4k次。sql查询中,一个字段多个结果拼接的两种方式_oracle 一个字段多条记录的拼接
vue 项目中 html中出现clear错误_[vue/comment-directive] clear-程序员宅基地
文章浏览阅读934次。clear报错_[vue/comment-directive] clear
科大讯飞离线关键词识别(语法识别)(2)_科大讯飞构建语法树-程序员宅基地
文章浏览阅读2.7k次。关键词识别和语音听写还是有差别的,语音听写是直接将所说的话转化成语音,至于识别的准确率看所说的话是否是常用的,如果遇到不常见的词比如背身腿降这个指令,识别出来的就是乱七八糟的。而关键词识别也就是针对这种关键词识别有很好的效果,在于你自己构建一个.bnf文件,然后写上关键词#BNF+IAT 1.0 UTF-8;!grammar call;!slot <contact>;!slo..._科大讯飞构建语法树
DeepCache:Principled Cache for Mobile Deep Vision (MobiCom2018)-程序员宅基地
文章浏览阅读701次。提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档文章目录DeepCache:Principled Cache for Mobile Deep Vision (MobiCom2018)一、摘要二、缓存的思想和挑战1. 缓存思想的引入1) CNN是视频处理的常用算法,但在资源有限的设备端受限2) 如何解决设备端受限这一问题——缓存2. 挑战1) 缓存中的可重用结果查找2) CNN中间特征图的细粒度重用3) 平衡可缓存性、模型准确性和高速缓存开销4) 对抗缓存侵蚀(cache erosion._deepcache