【python】数据挖掘机器学习模型——分类预测方法汇总_决策树分类预测代码-程序员宅基地
目录
本文链接:http://t.csdnimg.cn/CRgaS
数据挖掘系列:
缺失值处理方法汇总
离散化方法汇总
离群点(异常值)处理方法汇总
标准化(数据归一化)处理方法汇总
特征选择(特征筛选)方法汇总
特征选择筛选(降维)方法汇总
分类预测方法汇总
前言
数据挖掘常用的一些模型进行简单的汇总,可能不全,但是都是一些比较经典的预测模型。本文使用的是鸢尾花数据集进行展示模型。


一、分类
1.1 决策树分类
在决策树中,每个内部节点表示一个属性或特征,每个分支代表一个可能的特征值,而每个叶子节点表示一个类别标签或回归值。通过从根节点开始,沿着树的分支进行逐步决策,可以将数据点分类到特定的类别或预测数值输出。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建决策树分类器
clf = DecisionTreeClassifier()
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
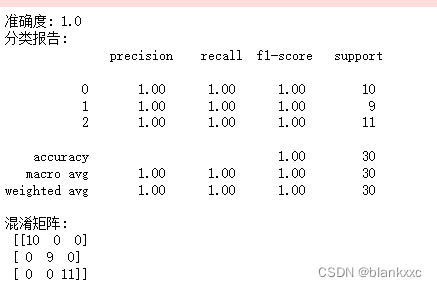
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
criterion 默认为 “gini”,表示使用基尼不纯度作为分裂标准。
splitter 默认为 “best”,表示选择最佳的分裂策略。
max_depth 默认为 None,即不限制树的深度。则扩展节点,直到所有叶子都是纯的或直到所有叶子包含少于 min_samples_split 样本
min_samples_split 默认为 2,表示节点分裂所需的最小样本数为2。如果是 int,则视为min_samples_split最小数。如果是浮点数,则min_samples_split是一个分数,并且 是每次分割的最小样本数。
min_samples_leaf 默认为 1,叶节点所需的最小样本数。min_samples_leaf仅当任何深度的分割点在左右分支中至少留下训练样本时,才会被考虑。这可能具有平滑模型的效果,尤其是在回归中。
min_weight_fraction_leaf 默认 0.0,浮点数,叶节点处所需的(所有输入样本的)权重总和的最小加权分数。当未提供sample_weight时,样本具有相同的权重。
max_features 寻找最佳分割时要考虑的特征数量。 默认为 “None”,表示考虑所有特征来进行分裂。
max_leaf_nodes 默认为 None,表示根据最大叶子节点来最佳的生成一个树,None表示不限制。
min_impurity_decrease 如果分裂导致杂质减少大于或等于该值,则节点将被分裂。浮点数,默认 0.0
random_state 默认为 None,表示不设置随机种子,随机性将根据系统时间产生。
ccp_alpha 非负浮点数 默认为None ,用于最小成本复杂性修剪的复杂性参数。将选择具有最大成本复杂度且小于ccp_alpha的子树 。默认情况下,不执行修剪。
class_weight 默认为 None,表示不应用类别权重,所有类别被视为平衡。与表格中的类别相关联的权重。如果没有,则所有类别的权重都应该为一。对于多输出问题,可以按照与 y 的列相同的顺序提供字典列表。{class_label: weight}
请注意,对于多输出(包括多标签),应为其自己的字典中每列的每个类定义权重。例如,对于四类多标签分类权重应为 [{0: 1, 1: 1}, {0: 1, 1: 5}, {0: 1, 1: 1}, {0: 1, 1: 1}] 而不是 [{1:1}、{2:5}、{3:1}、{4:1}]。
“平衡”模式使用 y 的值来自动调整与输入数据中的类别频率成反比的权重,如下所示n_samples / (n_classes * np.bincount(y))
对于多输出,y的每一列的权重都会相乘。
请注意,如果指定了sample_weight,这些权重将与sample_weight(通过fit方法传递)相乘。
具体可以看官方文档:决策树官网文档
1.2 SVC
SVC是一种强大的分类器,它通过构建一个决策边界(或超平面)来分离不同的类别。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC # 导入支持向量分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建支持向量机分类器
clf = SVC() # 默认情况下创建一个支持向量分类器
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
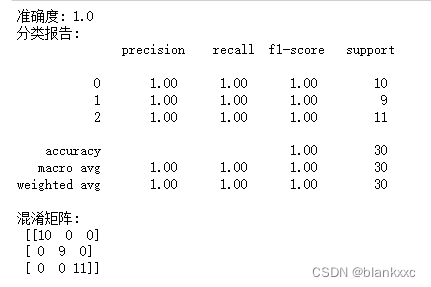
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
C(默认值为1.0):浮点数,正则化参数,必须为正数,控制决策边界的平滑度。较小的 C 值会导致边界更平滑,较大的 C 值会导致更严格的边界。这个惩罚项是l2惩罚项
kernel(默认值为’rbf’):内核函数,用于将原始特征映射到高维空间,可用的有{‘linear’, ‘poly’, ‘rbf’, ‘sigmoid’, ‘precomputed’} 。常见的内核函数包括:‘linear’:线性内核 ‘poly’:多项式内核 ‘rbf’:径向基函数(高斯核)
degree(默认值为3):多项式内核的次数,仅当内核为多项式时才有效。必须为非负数
gamma(默认值为’scale’):核函数的系数,影响径向基函数(‘rbf’)的形状。默认值 ‘scale’ 是基于特征数自动计算的,也可以使用 ‘auto’ 或具体的数值。“rbf”、“poly”和“sigmoid”的核系数。
如果gamma=‘scale’(默认)被传递,那么它使用 1 / (n_features * X.var()) 作为 gamma 值,
如果为“auto”,则使用 1 / n_features
如果是浮点数,则必须为非负数。
coef0(默认值为0.0):浮点数,内核函数的独立项(仅对某些内核有效)。它仅在“poly”和“sigmoid”中有意义。
shrinking(默认值为True):布尔值,控制是否使用缩小的启发式方法来加速训练。是否使用收缩启发式。
probability(默认值为False):布尔值,用于启用类别概率估计。如果设置为 True,则可以使用 predict_proba 方法获取类别概率。这必须在调用之前启用fit,会减慢该方法的速度,因为它内部使用 5 倍交叉验证,并且predict_proba可能与predict不一致 。
tol(默认值为1e-3):训练停止的容忍度,表示在优化过程中的收敛容忍度。
cache_sizefloat(默认值为200)指定内核缓存的大小(以 MB 为单位)。
class_weight(默认值为None):类别权重,用于处理不平衡类别问题。可以设置为字典或’balanced’,后者会自动平衡类别权重。
random_stateint(默认值为None)控制伪随机数生成,以打乱数据以进行概率估计。
以上是常用的一些常数,具体所有的参数可以看官方文档:SVC官方文档
1.3 MLP
多层感知器(Multilayer Perceptron,MLP)是一种人工神经网络模型,也被称为前馈神经网络(Feedforward Neural Network)
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neural_network import MLPClassifier
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建MLP模型
clf = MLPClassifier(hidden_layer_sizes=(128, 64), activation='relu', solver='adam', max_iter=1000, random_state=42)
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
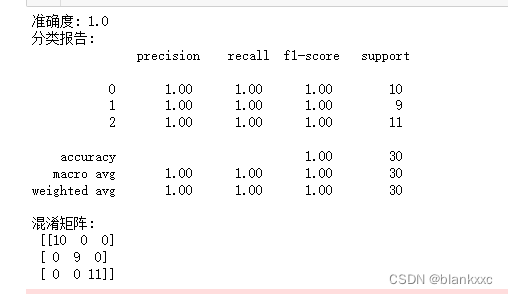
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)

hidden_layer_sizes(默认值为(100,)):表示隐藏层的结构,是一个元组,元组中的每个元素表示相应隐藏层中的神经元数量。例如,(100,) 表示一个包含100个神经元的单隐藏层。
activation(默认值为’relu’):激活函数的类型,可选值包括 ‘identity’、‘logistic’、‘tanh’ 和 ‘relu’ 等。
solver(默认值为’adam’):用于优化权重的求解器,可选值包括 ‘lbfgs’、‘sgd’ 和 ‘adam’。
alpha(默认值为0.0001):L2正则化项的参数,用于控制权重的正则化。
batch_size(默认值为’auto’):用于优化的小批量样本的大小。默认值 ‘auto’ 表示根据数据集自动选择。
learning_rate(默认值为’constant’):学习率的类型,可选值包括 ‘constant’、‘invscaling’ 和 ‘adaptive’。
learning_rate_init(默认值为0.001):初始学习率。
max_iter(默认值为200):最大迭代次数,即训练的最大轮数。
shuffle(默认值为True):是否在每次迭代中打乱训练数据。
random_state(默认值为None):用于初始化权重和偏差的随机种子。
tol(默认值为1e-4):迭代停止的容忍度,当两次迭代的损失值变化小于此值时停止。
momentum(默认值为0.9):动量参数,用于加速收敛。
以上是常用的一些常数,具体所有的参数可以看官方文档:MLP官方文档
1.4 逻辑回归
逻辑回归(Logistic Regression)是一种用于解决分类问题的统计学习方法,尽管名称中包含"回归"两个字,但实际上它是一种分类算法。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression # 导入逻辑回归分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建逻辑回归分类器
clf = LogisticRegression() # 默认情况下创建一个逻辑回归分类器
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
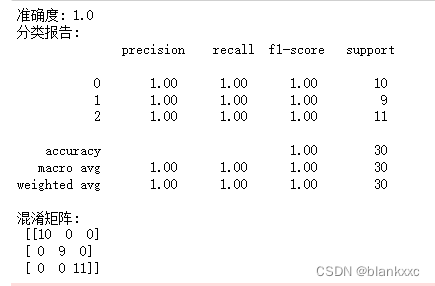
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
penalty(默认值为’l2’):正则化类型,可选值包括 ‘l1’、‘l2’、‘elasticnet’ 和 ‘none’。
C(默认值为1.0):正则化强度的倒数,较小的值表示更强的正则化。
fit_intercept(默认值为True):是否拟合截距项。
solver(默认值为’lbfgs’):用于优化的求解器,可选值包括 ‘newton-cg’、‘lbfgs’、‘liblinear’、‘sag’ 和 ‘saga’。
max_iter(默认值为100):算法的最大迭代次数。
multi_class(默认值为’auto’):多类别分类的策略,可选值包括 ‘auto’、‘ovr’(一对多)和 ‘multinomial’。
verbose(默认值为0):控制详细程度的输出。设置为大于1的值会增加详细信息。
n_jobs(默认值为None):并行计算的数量,设置为-1表示使用所有可用的CPU核心。
l1_ratio(默认值为None):当正则化类型为 ‘elasticnet’ 时,L1正则化的混合比例。
random_state(默认值为None):用于初始化随机数生成器的种子。
tol(默认值为1e-4):迭代停止的容忍度,当损失的变化小于此值时停止。
warm_start(默认值为False):如果设置为True,那么在调用fit方法时会重用前一个调用的解决方案。
class_weight(默认值为None):用于处理不平衡类别问题的权重。
dual(默认值为False):对偶问题的选择,当样本数大于特征数时,设置为True。
以上是常用的一些常数,具体所有的参数可以看官方文档:逻辑回归官方文档
1.5 KNN
KNeighborsClassifier 是 scikit-learn 中用于 K 最近邻(K-Nearest Neighbors,KNN)分类的类。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.neighbors import KNeighborsClassifier # 导入KNN分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建KNN分类器
clf = KNeighborsClassifier() # 默认情况下创建一个KNN分类器
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
n_neighbors(默认值为5):用于分类的最近邻居数量K。
weights(默认值为’uniform’):用于决定最近邻居对分类的权重,可选值包括 ‘uniform’(所有邻居权重相等)和 ‘distance’(根据距离赋予不同的权重)。
algorithm(默认值为’auto’):用于计算最近邻居的算法,可选值包括 ‘auto’、‘ball_tree’、‘kd_tree’ 和 ‘brute’。
leaf_size(默认值为30):用于树结构(如ball tree或kd tree)的叶子大小。
p(默认值为2):用于计算距离的闵可夫斯基距离的参数。当p=2时,使用欧氏距离;当p=1时,使用曼哈顿距离。
metric(默认值为’minkowski’):用于距离计算的度量标准。通常情况下,你不需要修改这个参数,因为它会根据选择的p值自动确定。
n_jobs(默认值为1):并行计算的数量,设置为-1表示使用所有可用的CPU核心。
algorithm(默认值为’auto’):用于计算最近邻居的算法,可选值包括 ‘auto’、‘ball_tree’、‘kd_tree’ 和 ‘brute’。
metric_params(默认值为None):度量标准的额外参数,通常不需要设置。
以上是常用的一些常数,具体所有的参数可以看官方文档:KNN官方文档
二、集成分类模型
2.1 随机森林
随机森林(Random Forest)是一种集成学习方法,它基于决策树构建了多个决策树模型,并通过集成它们的结果来提高预测性能。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier # 导入随机森林分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建随机森林分类器
clf = RandomForestClassifier() # 默认情况下会创建一组决策树
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
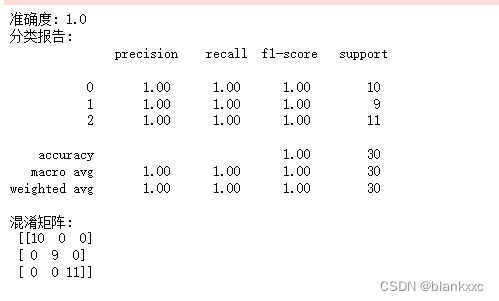
n_estimators(默认值为100):森林中树的数量,也就是要建立的决策树的数量。
criterion(默认值为’gini’):用于衡量分割质量的标准,可选值包括 ‘gini’ 和 ‘entropy’。
max_depth(默认值为None):每棵树的最大深度。如果为None,则树会一直扩展直到叶子节点包含的样本数小于min_samples_split。
min_samples_split(默认值为2):拆分内部节点所需的最小样本数。
min_samples_leaf(默认值为1):叶子节点所需的最小样本数。
min_weight_fraction_leaf(默认值为0.0):叶子节点的最小加权分数总和。
max_features(默认值为’auto’):寻找最佳分割时要考虑的特征数量。可选值包括 ‘auto’、‘sqrt’、‘log2’ 和一个整数。
max_leaf_nodes(默认值为None):每棵树上允许的最大叶子节点数。
min_impurity_decrease(默认值为0.0):要进行分割的最小不纯度减少。
bootstrap(默认值为True):是否使用自助采样(Bootstrap)。
oob_score(默认值为False):是否计算袋外(Out-of-Bag)分数。
n_jobs(默认值为None):并行计算的数量,设置为-1表示使用所有可用的CPU核心。
random_state(默认值为None):用于初始化随机数生成器的种子。
verbose(默认值为0):控制详细程度的输出。设置为大于1的值会增加详细信息。
以上是常用的一些常数,具体所有的参数可以看官方文档:随机森林官方文档
2.2 GBDT
GBDT,全称Gradient Boosting Decision Trees(梯度提升决策树),是一种集成学习方法
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.ensemble import GradientBoostingClassifier # 导入梯度提升决策树分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建梯度提升决策树分类器
clf = GradientBoostingClassifier() # 默认情况下会创建一组决策树
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
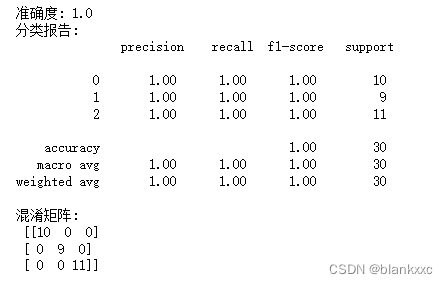
n_estimators:决策树的数量,默认是100。 learning_rate:学习速率,默认是0.1。
max_depth:每棵树的最大深度,默认是3。 min_samples_split:分裂内部节点所需的最小样本数,默认是2。
min_samples_leaf:叶子节点上的最小样本数,默认是1。
subsample:用于拟合每棵树的训练数据的子样本比例,默认是1.0(使用全部数据)。
max_features:每棵树的最大特征数,默认是None(表示使用所有特征)。
loss:损失函数,可以是"deviance"(对数似然损失)或"exponential"(指数损失),默认是"deviance"。
以上是常用的一些常数,具体所有的参数可以看官方文档:GBDT官方文档
2.3 XGBoost
XGBoost,全称Extreme Gradient Boosting,在各种数据科学竞赛和实际应用中表现出色,是梯度提升树的改进。
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from xgboost import XGBClassifier # 导入XGBoost分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建XGBoost分类器
clf = XGBClassifier() # 默认情况下会创建一组树模型
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
n_estimators:基本弱学习器的数量,默认为100。
learning_rate:每个基学习器的权重缩减系数,默认为0.3。
max_depth:每个基学习器的最大深度,默认为6。
min_child_weight:叶子节点的最小权重和,用于控制过拟合,默认为1。
subsample:用于训练每个基学习器的样本子采样比例,默认为1.0(使用全部样本)。
colsample_bytree:每个基学习器的特征子采样比例,默认为1.0(使用全部特征)。
gamma:用于控制树的生长,只有当损失函数的减小量超过gamma时才进行分裂,默认为0。
reg_alpha:L1正则化项的权重,默认为0。
reg_lambda:L2正则化项的权重,默认为1。
scale_pos_weight:正负权重平衡参数,默认为1。
objective:定义学习任务的目标函数,例如’binary:logistic’用于二分类,‘multi:softmax’用于多类分类,默认为’binary:logistic’。
num_class:多类分类时的类别数目,默认为1,用于’multi:softmax’。
random_state:随机种子,默认为0。
n_jobs:并行处理的CPU核数,默认为1(不并行)。
verbosity:控制日志输出级别,默认为1(显示信息)。

以上是常用的一些常数,具体所有的参数可以看官方文档:XGBoost官方文档
2.4 LightGBM
LightGBM(Light Gradient Boosting Machine)是一种梯度提升树(Gradient Boosting Decision Trees,GBDT)算法的变体,它具有出色的性能和高效的训练速度,
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier # 导入LightGBM分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建LightGBM分类器
clf = LGBMClassifier() # 默认情况下会创建一组树模型
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
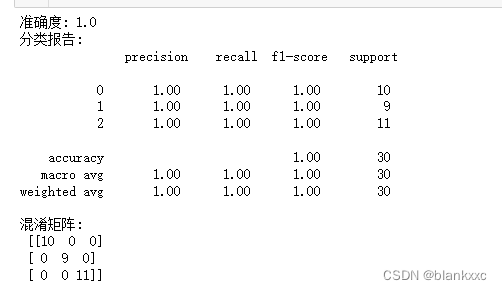
n_estimators:基本弱学习器的数量,默认为100。
learning_rate:每个基学习器的权重缩减系数,默认为0.1。
max_depth:每个基学习器的最大深度,默认为-1,表示没有限制。
num_leaves:每棵树的最大叶子节点数,默认为31。
min_child_samples:每个叶子节点的最小数据样本数,默认为20。
subsample:用于训练每个基学习器的样本子采样比例,默认为1.0(使用全部样本)。
colsample_bytree:每个基学习器的特征子采样比例,默认为1.0(使用全部特征)。
reg_alpha:L1正则化项的权重,默认为0。
reg_lambda:L2正则化项的权重,默认为0。
min_split_gain:执行分裂的最小增益,默认为0。
scale_pos_weight:正负权重平衡参数,默认为1。
objective:定义学习任务的目标函数,默认为’multiclass’(多类分类)。
class_weight:类别权重,默认为None,可以设置为’balanced’以平衡不均衡的类别分布。
random_state:随机种子,默认为None。
n_jobs:并行处理的CPU核数,默认为-1(使用所有可用核心)
以上是常用的一些常数,具体所有的参数可以看官方文档:LightGBM官方文档
2.5 CatBoost
CatBoost是一种高性能的梯度提升树(Gradient Boosting Decision Trees,GBDT)算法,专门用于分类和回归任务。它的名称CatBoost是"Categorical Boosting"的缩写,强调了其在处理分类特征时的优势
import numpy as np
import pandas as pd
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from catboost import CatBoostClassifier # 导入CatBoost分类器
from sklearn.metrics import accuracy_score, classification_report, confusion_matrix
# 加载鸢尾花数据集
iris = load_iris()
X = iris.data
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 创建CatBoost分类器
clf = CatBoostClassifier() # 默认情况下会创建一组树模型
# 拟合模型
clf.fit(X_train, y_train)
# 预测测试集
y_pred = clf.predict(X_test)
# 计算准确度
accuracy = accuracy_score(y_test, y_pred)
print("准确度:", accuracy)
# 打印分类报告
print("分类报告:\n", classification_report(y_test, y_pred))
# 打印混淆矩阵
conf_matrix = confusion_matrix(y_test, y_pred)
print("混淆矩阵:\n", conf_matrix)
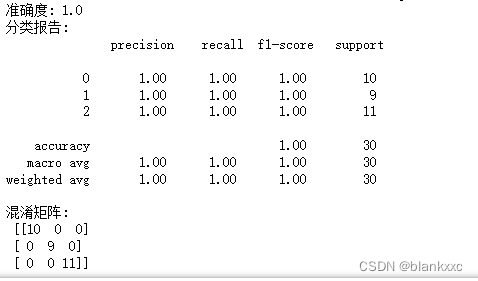
iterations:迭代次数,即基学习器的数量,默认为500。
learning_rate:学习速率,默认为0.03。
depth:每棵树的最大深度,默认为6。
l2_leaf_reg:L2正则化项的强度,默认为3.0。
border_count:特征值的分割点数量,默认为254。
verbose:控制训练过程中的详细程度,默认为0(不显示)。
loss_function:用于定义损失函数的字符串,默认为’Logloss’用于二分类,‘MultiClass’用于多类分类。
cat_features:指定分类特征的索引,默认为None,CatBoost会自动识别分类特征。
class_weights:用于类别不平衡时的权重,默认为None。
iterations_without_progress:在多少轮迭代后没有改进时停止训练,默认为30。
early_stopping_rounds:用于提前停止训练的轮数,默认为None(禁用提前停止)。
custom_metric:自定义评估指标的函数,默认为None。
random_seed:随机种子,默认为None。
task_type:任务类型,可选值包括’CPU’和’GPU’,默认为’CPU’。
devices:指定GPU设备的索引列表,默认为None,表示使用所有可用的GPU。
以上是常用的一些常数,具体所有的参数可以看官方文档:CatBoost官方文档
总结
目前总结都是目前比较经典和常用的一些模型了,内容很多,不乏有些错误,有发现错误的朋友,可以评论区指正,如果本文对你有所帮助的话,麻烦给个点赞收藏关注和评论,当然也可以打赏处请我喝杯咖啡!
智能推荐
Error:kCFStreamErrorCodeKey=-2102 Domain=kCFErrorDomainCFNetwork Code=-1001 - iOS-程序员宅基地
文章浏览阅读7k次。之前早已调通的接口,因有新业务叠加新增了一些数据字段,之后再次调试接口的时候请求等待延迟至设定超时时间后出现了如下异常:[discovery] errors encountered while discovering extensions: Error Domain=PlugInKit Code=13 "query cancelled" U..._kcferrordomaincfnetwork code=-1001
汇编语言 十六进制转换为二进制_十六进制转二进制小程序-程序员宅基地
文章浏览阅读2.5w次,点赞26次,收藏148次。汇编语言程序,十六进制转换为二进制_十六进制转二进制小程序
51nod-1279 扔盘子_51nod - 1279-程序员宅基地
文章浏览阅读364次。1279 扔盘子题目来源: Codility基准时间限制:1 秒 空间限制:131072 KB 分值: 10 难度:2级算法题 收藏 关注有一口井,井的高度为N,每隔1个单位它的宽度有变化。现在从井口往下面扔圆盘,如果圆盘的宽度大于井在某个高度的宽度,则圆盘被卡住(恰好等于的话会下去)。盘子有几种命运:1、掉到井底。2、被卡住_51nod - 1279
消融实验的目的_深度学习中为什么采用消融实验-程序员宅基地
文章浏览阅读307次。消融实验就是通过出去模型的某一模块或者是功能,然后与原来的模型进行比较运行结果,即削弱系统的某个组件后使其继续正常运行_深度学习中为什么采用消融实验
【linux】nvidia-smi 查看GPU使用率100%_centos gpu没跑程序使用率100%-程序员宅基地
文章浏览阅读5.5k次,点赞4次,收藏18次。linux服务器下使用nvidia-smi or nvidia-smi -l 1【数字表示输出间隔】命令查看GPU使用情况,三种情况1、没有进程,GPU使用率为空这种情况表示,没有进程占用GPU资源,属于为空的正常状态2、有进程,GPU使用率在变化我们如果想要终止进程ps -ef|grep pythonkill -9 58828 # 58828是该进程id当然,也可以杀死所有python进程killall -9 python以前写的博客有以上教程,戳我进入。3、看_centos gpu没跑程序使用率100%
reverse vs converse vs inverse_invert和reverse的区别-程序员宅基地
文章浏览阅读4.2k次。First, it helps to look at the verb usage: you can reverse something, but you cannot inverse or converse something. The distinctions between reverse, converse, and inverse can often be made by l_invert和reverse的区别
随便推点
在本地浏览器上查看远程服务器上的tensorboard_访问tensorboard的url post-程序员宅基地
文章浏览阅读673次,点赞2次,收藏4次。1. keras中生成tensorboard日志信息 由于tensorboard日志是记录并且可视化训练过程的各个指标和权重信息的,所以需要通过回调函数来实现训练过程中的记录,然后将相应的回调函数传给模型的fit方法即可。如下所示,tf.keras.callbacks中有现成的回调函数,然后将其传给fit方法的callback参数即可。训练完成后就会在logdir目录下生成相应的信息文件。log_dir = "logs/fit/" + datetime.datetime.n..._访问tensorboard的url post
解决git冲突步骤(超详细)_git解决冲突-程序员宅基地
文章浏览阅读2.7w次,点赞10次,收藏112次。本文介绍git冲突产生原因,详细介绍两种冲突的解决步骤(图文详细说明),包括merge冲突、push/pull冲突两种冲突类型的详细解决步骤_git解决冲突
java项目日常运维需要的文档资料_项目运维文档-程序员宅基地
文章浏览阅读791次,点赞11次,收藏12次。java项目开发完成,部署上线,进入项目运维阶段,日常工作需要准备哪些资料和文档?当项目上线后,运行一段时间,或多或少会遇到一些运维上的问题,比如服务器磁盘饱满,服务器CPU,内存使用率过高,应用存在安全漏洞,应用报错,临时需求编个变更等等。诸多问题。那么若想快速响应,平时就需要准备好与项目运维相关的文档和资料。我总结了以下一些内容。_项目运维文档
【树(Tree)详细介绍】_树的应用场景-程序员宅基地
文章浏览阅读175次。树是一种重要的非线性数据结构,它具有层级关系,由一组以边连接的节点组成。树有许多不同的分类和应用场景,每种树的类型都有其特定的特点和用途。了解树的基本概念和常见的树的分类,有助于我们在实际问题中选择合适的数据结构和算法,提高程序的效率和性能。_树的应用场景
java基础入门学习菜鸟入门第七天——java中的方法、变量_参数列表哪四种情况-程序员宅基地
文章浏览阅读266次。JAVA基础知识——方法、变量3.2方法3.2.1什么是方法?方法的定义:解决一类问题中代码的有序组合方法,是一个功能模板,也就是将很多行代码放置在一组 {} 中,形成一个代码块。3.2.2为什么需要使用方法?提高代码的复用性提高后期代码的扩展性、延展性提高代码后期的维护性案例://计算一个圆柱的表面积import java.util.Scanner;publi..._参数列表哪四种情况
SAP_ABAP_在SE11表中检查初始值initial value,ABAP中的初始值和空值_sap initial values-程序员宅基地
文章浏览阅读6.7k次。1、在开发中遇到这样的情况:一个表使用了一段时间之后需要增加一些字段,而表中已经存在数据了。2、SE16(N)查看数据时,SAP把具有初始值和空值的字段都显示为初始值,但是在查询语句中,它们在数据库中的行为是不一样的。_sap initial values