数据结构概念/名词解释以及简答题(适用于电子信息计算机考研复试面试以及期末考试)_考研题数据结构的含义包含哪些方面-程序员宅基地
绪论
- 数据:数据是信息的载体,信息是数据的内涵。
- 数据元素:数据的基本单位。
- 数据项:构成数据元素不可分割的最小单位。
- 数据对象:性质相同的数据元素的集合,是数据的子集。
- 数据类型:一个值的集合以及定义在此集合上一组操作的总称。原子类型、结构类型、抽象数据类型ADT。
- 抽象数据类型ADT:只关系逻辑结构,无需关系具体实现、存储结构。由数据对象、数据关系、基本操作组成。
- 数据结构:相互之间存在一种或多种特定关系的数据元素的集合。数据结构=数据元素+数据关系。
- 数据结构三要素:逻辑结构、物理结构、数据运算。
- 逻辑结构:数据元素之间的逻辑关系。线性结构、非线性结构。
线性结构:线性表1:1、栈、队列、串、数组。
非线性结构:集合,除同属一个集合别无其他关系;树,1:n;图,m:n。 - 存储结构:数据结构在计算机上的表示,顺序存储、链式存储、索引存储、散列存储。
- 数据运算:运算的定义依赖于逻辑结构,运算的实现依赖于物理结构。
- 算法:特定问题求解步骤的描述。
- 算法五特性:确定性、可行性、有穷性、输入、输出。
- 优质算法特性:正确性、健壮性、可读性、高效率、低存储(时空复杂度低)。
- 算法分析:时间复杂度、空间复杂度、稳定性。
- S(n)=O(1):算法原地工作指算法所需要的辅助空间为常量。
- 程序=数据结构+算法:数据结构是要处理的信息,算法是处理信息的步骤。
线性表
- 顺序表:线性表的顺序存储,逻辑顺序和物理顺序相同。随机访问,存储密度高,插入删除需要移动大量元素。静态顺序表、动态顺序表。
静态线性表:数组、大小固定、少则内存溢出、多则资源浪费。
动态线性表:动态分配存储空间。 - 链表:线性表的链式表示,不要求存储地址联系,失去了随机访问的特性。适合插入删除。单链表、双链表、循环链表、静态链表。
- 单链表:链表结点存放后继指针。访问后继结点时间复杂度为O(1),前驱为O(n)。
- 双链表:链表结点存放前驱和后继指针,这样就克服了单链表不能从后往前遍历的缺陷。prior、next
- 循环链表:循环单链表、循环双链表。循环单链表需要将尾结点指针指向头结点,这样就可以形成环。循环双链表还需要将头结点的prior指针指向尾结点。
- 静态链表:借助数组实现的链表。
- 线性表基本操作:创销、CRUD、判空、判表长、输出。
- 线性结构和非线性结构区别:线性结构除第一个和最后一个节点外,其余结点有唯一前驱和后继,第一个节点无前驱,最后一个结点无后继,结点之间是一对一关系。非线性结构结点前驱后继不具有唯一性,结点之间关系为一对多或者多对多。
- 顺序存储结构特点:存储密度大,空间利用率高;随机访问,随机存取;不适合插入删除操作,因为需要移动大量元素;预分配存储空间难以确定。
- 顺序存储结构与链式存储结构比较
| 顺序存储结构 | 链式存储结构 | |
|---|---|---|
| 优点 | 存储密度高、随机访问、随机存取 | 插入删除方便、动态分配存储空间 |
| 缺点 | 不适合插入删除,因为需要移动大量元素;预分配存储空间难以确定 | 存储密度小、访问需要从头遍历链表 |
- 顺序表和链表的比较
| 区别 | 顺序表 | 链表 |
|---|---|---|
| 存储结构 | 顺序存储 | 链式存储 |
| 存取/访问速率 | 随机存取,随机访问,方便O(1) | 不方便,需要遍历O(n) |
| 存储密度 | 高 | 低 |
| 插入删除 | 不方便,需要移动大量元素 | 方便,修改指针 |
- 数组和链表的比较
| 区别 | 数组 | 链表 |
|---|---|---|
| 分配空间 | 静态分配/栈分配 | 动态分配/堆分配 |
| 访问速率 | 根据数组下标直接访问 | 从头遍历 |
| 插入删除 | 不方便,需要移动大量元素 | 方便,只需修改指针 |
- 头指针和头结点区分
| 区分 | 头指针 | 头结点 |
|---|---|---|
| 概念 | 指向链表第一个结点的指针 | 带头结点链表的第一个结点,是链表在表头附加的结点 |
| 是否必须 | 是 | 否,只是为了统一操作 |
| 引入头结点作用 | 头指针就是链表名字、标记链表 | 空表非空表头结点都指向头结点/统一了第一个数据结点和其余结点的操作 |
- 单链表双链表的区别
| 单链表 | 双链表 |
|---|---|
| 存放后继指针next ,只能从前往后遍历 | 存放前驱后继指针prior、next,双向遍历 |
受限线性表/特殊线性表(栈、队列、串)
- 栈:限定表尾插入删除,顺序栈、链栈、共享栈。
- 顺序栈:栈的顺序表示。
- 链栈:栈的链式存储。
- 共享栈两个栈共享同一片空间。
- 队列:一段插入、一段删除,顺序队列(循环队列)、链队、双端队列。
- 循环队列:把顺序队列的尾指针指向头结点形成环。
- 链队:队列链式存储。
- 双端队列:两端都可以插入删除的队列。
- 输入受限的双端队列:只允许一端插入,两端删除。
- 输出受限的双端队列:只允许一端删除,两端插入。
- 串:限制数据元素为字符的线性表。
- 串的存储结构:定长顺序存储、堆分配、块链存储。
- 串的模式匹配暴力匹配算法、KMP、改进KMP。
- 顺序队列相比,循环队列有哪些优点?解决假溢出现象。
- 栈的应用:括号匹配、表达式求值、递归。
- 队列应用:图的广度优先遍历,树的层次遍历,FCFS先来先服务。
- 多栈共享技术:两栈共享空间、利用“栈底位置不变、栈顶动态变化”特性。
- 串和线性表的区别?串是特殊线性表,限制数据元素为字符,并且串的操作和线性表有较大差别,线性表操作大多以数据元素为操作对象,而串大多以串的整体或模式串作为操作对象。
- 简述KMP算法
KMP算法是在简单模式匹配算法的基础上对串的模式匹配进行优化。也就说KMP是改进的暴力匹配算法。
主要的思路是每趟比较过程中让子串先滑动到一个合适的位置。
当发生不匹配时,不同于简单模式匹配的右移一位,而是移动到适合的位置。
这里所移动的位置依靠NEXT[]数组,求next[]数组的方法是比较前后缀相同元素。 - 栈和队列区别
| 栈 | 队列 |
|---|---|
| 先入后出 | 先入先出 |
| 只许表尾插入删除 | 一段插入一段删除 |
线性表推广(数组、广义表)
- 数组:相同数据类型的数据元素的有限序列。
- 矩阵:二位数组即矩阵,数组可以是数字、字符等,矩阵数据元素只能是数字。对称矩阵、对角矩阵、三角矩阵、三对角矩阵、稀疏矩阵。按行优先存储、按列优先存储。
- 压缩存储:相同数值分配一个存储空间、零不分配存储空间,目的节约存储空间。
- 稀疏矩阵:绝大部分数据元素为0的矩阵,通过三元组压缩存储。但压缩存储后失去了随机存取的特性。稀疏矩阵的三元组既可以采用数组存储,也可以采用十字链表存储。
- 广义表:放松了对表元素原子性的限制,容许表元素有自身结构。
树
- 二叉树:结点的度最多为二,有左右子树之分。
- 完全二叉树:结点从上到下,从左到右。
- 满二叉树:每一层结点数都达到最大值。特殊的完全二叉树。
- 二叉排序树BST:左子树所有结点值小于根值,右大于根,也可以为空树。
- 平衡二叉树AVL:改进的二叉排序树,平衡因子不大于1。
- 平衡调整:LL调整、RR调整、LR调整、RL调整。
- B-树:平衡二叉树扩展,结点多关键字的平衡树。
- B+树:B-树的变形,叶子结点存储关键字以及记录地址,非叶子结点只有索引作用。
- B-树和B+树区别:B-树分支从关键字两端引出、B+树分支从关键字引出;B-树中每个结点都存储信息,B+树只有根节点存储关键字和记录,非叶结点只有索引作用,另外B+树可以用指针指向关键字最小的结点,并把所有结点链接成单链表。
- 哈夫曼树:树的带权路径长度最小的二叉树,也称最优二叉树。
- 遍历二叉树:按某种搜索路径寻访二叉树每个结点,使得每个结点只被访问一次。
- 线索二叉树:可以像遍历单链表一样遍历二叉树,加快查找前驱和后继结点。
- 二叉树存储结构:顺序存储结构、链式存储结构;完全二叉树和满二叉树采用顺序存储,其他二叉树如需要顺序存储需要添加空结点,一般二叉树采用链式存储结构。
- 树的三种存储方法:孩子表示法、双亲表示法、孩子兄弟表示法。
- 树的遍历:先序遍历,后续遍历
- 二叉树遍历:先序遍历,中序遍历,后续遍历,层次遍历
- 树、森林、二叉树的转换:左孩子右兄弟
- 树的应用-并查集:管理一些不相交集合,并支持两种操作,合并和查询,其重要思想在于用集合中一个元素代表整个集合。
- 简述哈夫曼树:主要内容分为概念、性质、构造、哈夫曼编码、平均码长、作用。
概念:哈夫曼树是WPL最小的二叉树,也称最优二叉树。
性质:离根越近结点权值越大,没有度为1的结点,原结点都是叶子结点,结点总数2n-1,度为二的结点数为n-1。
构造:将集合中两个权值最小的结点相加结合生成一个新节点,放入集合,把原来的两个结点删除,在找两个最小的结点重复进行。
哈夫曼编码:可变长最短前缀编码。
平均码长:各初始结点权值乘路径长度的总和。
作用:数据压缩
图
- 有向边、无向边:有向边是弧,无向边是边。
- 完全图:该有的边都有,有向完全图边的个数为n(n-1),无向完全图边的个数为n(n-1)/2。
- 简单图,多重图:是否有自环和平行边。
- 连通图、强连通图:有向图任意两个顶点都有路径相通,无向图任意两点之间都有来回路径。
- 极大连通子图、极小连通子图、极大强连通子图、极小强连通子图:极大连通子图即连通分量,极小连通子图即边最少的连通子图,极大强连通子图即强连通分量、极小强连通子图在保持任意两结点来回互通的情况下弧最少的连通子图。
- 生成树:无向图的一个极小连通子图。
- 图的遍历:从某一顶点按需访问图中所有结点,每个结点只被访问一次。
- DAG:有向无环图,包括AOE和AOV。
- AOE:以弧为活动,顶点表示事件的有向网。边有权值,用于关键路径。
- AOV:以顶点表示活动、弧表示事件的有向网。边无权值,用于拓扑排序。
- 图的存储结构:邻接矩阵、邻接表、十字链表、邻接多重表。
- 邻接矩阵:适用于稠密图,无向图对称矩阵,有向图不是对称矩阵。包含顶点集和边集。
- 邻接表:适用于稀疏图,通过顶点表和边表组成。顶点表顺序,边表链式。有向图邻接表和逆邻接表的结合。
- 十字链表:适用于有向图,对邻接表查找入度的改进,方便快速查找入度。
- 邻接多重表:适用于无向图,对邻接表删除一个结点需要删除两个边表结点。
- 图的遍历:深度优先遍历DFS、广度优先遍历BFS。
- DFS:类似于树的先序遍历。工作栈实现,从初始点v开始访问任意一个未被访问的邻接顶点m1,顶点m1访问一个未被访问的邻接顶点m2,依次进行同样操作,直到该顶点没有未被访问的邻接顶点,则返回上一层,重复操作。
- BFS:类似于树的层次遍历。队列+辅助数组,从初始点出发,访问所有邻接顶点m1,m2…然后依次访问m1未被访问的邻接顶点,m2未被访问的邻接顶点…重复上述操作。
- 最小生成树:无向网中边权值之和最小的生成树,最小生成树MST不一定唯一。prim、克鲁斯卡尔。
- Prim:从点找边,先将初始点放入结果集,从初始顶点出发找到一个未被访问的权值最小的边所邻接的顶点,放入结果集,然后再找和这两个顶点未被访问的权值最小边所邻接顶点,放入集合,依次进行。
- 克鲁斯卡尔:从边找点,先找一个权值最小的边,然后找与这个边上顶点所邻接的最小边,这之间不能形成环,依次进行。
- 最短路径:迪杰斯特拉、弗洛伊德。
- 克鲁斯卡尔:求单源最短路径。
- 弗洛伊德Floyd:求各顶点之间的最短路径。
- 拓扑结构:将入度为0的顶点取出,可用于检测AOV网是否有环。
- 关键路径:在AOE网中,从源点到汇点的最长路径。
查找
- 查找分类:
按功能:静态查找表适合查询,如顺序查找,折半查找;动态查找表适合插入删除,如BST、AVL、B-树、B+树。
按结构:线性表、树表、散列表。 - 查找表:同一类型数据元素的集合。
- 线性表查找:顺序查找、折半查找、分块查找。
- 顺序查找:可以对有序表、也可以无序表。适用于顺序和链式存储。
- 折半查找:对有序表的查找。用到折半查找判定树。适用于顺序存储。
- 分块查找:顺序查找和折半查找的结合,块内无序、块间有序。
- 树表查找:二叉排序树、平衡二叉树、B-树、B+树。
- 二叉排序树:可以为空树,当有左子树,左子树所有结点的值小于根结点的值,若有右子树,则右子树上结点的值大于根值,左子树,右子树同理。
- 平衡二叉树:二叉排序树的改进,还要求平衡因子不大于1。
- 关键字:数据元素中某个数据项的值,用它可以标识一个数据元素。
- B-树:平衡二叉树的推广,多关键字平衡树。
- B+树:B-树变形,叶子结点存放关键字和记录地址,非叶子结点只有索引作用,且可以用一个指针指向最小关键字的叶子结点,把各叶子结点链接成单链表。
- 散列表:根据关键字直接进行访问的数据结构,建立了关键字和物理存储的直接映射。
- 散列函数:把关键字映射成物理地址的函数。
- 散列函数构造方法:直接定址法、平方取中法、初留取余法、数字分析法、叠加法。
- 冲突:不同关键之映射到同一地址的情况。
- 解决冲突的方法:解决冲突的方法就是解决增量序列的问题。
开放定址法:线性探查发、平方探查发、再散列法、伪随机法。不适用于删除,因为删除的数据元素存储位置为空,他后面的数据元素就无法遍历查询到了。平方取中法解决了线性探查发堆积现象。
拉链法:通过链表把映射到相同地址的关键字链接存储。适用于插入删除。 - 散列查找效率影响因素:填装因子,散列函数,处理冲突的方法。平均查找长度ASL依赖于填装因子。填装因子是所存储的数据元素和整个申请存储空间的比值,即表的装满程度。
- 各查找方法的基本思想以及ASL:
顺序查找:给定的关键字k从前往后对比线性表中记录的关键字,如果该几率关键字等于k,则查找成功,否则查找失败。ASL=3(n+1)/4
折半查找:将给定的关键字和表中中间记录关键字比较,如相等则成功,若小于中间关键字则说明要查找的关键字在表的前半部分,若大于同理,如此进行,直达找到,查找成功,否则查找失败。ASL=log2 (n+1)-1
分块查找:顺序查找或折半查找索引表、顺序查找块内元素。
散列查找:通过散列函数求关键字存储地址,看是否为空,如果空就失败,否则比较该记录关键字,若采用开放定址法则若不等则通过增量序列找到下一个存储地址进行对比,若拉链法,遍历查找链表。
排序
- 算法评价:时间空间复杂度、稳定性。
- 内部排序、外部排序:内部排序利用内存;外部排序内存+外存,适用于大文件。
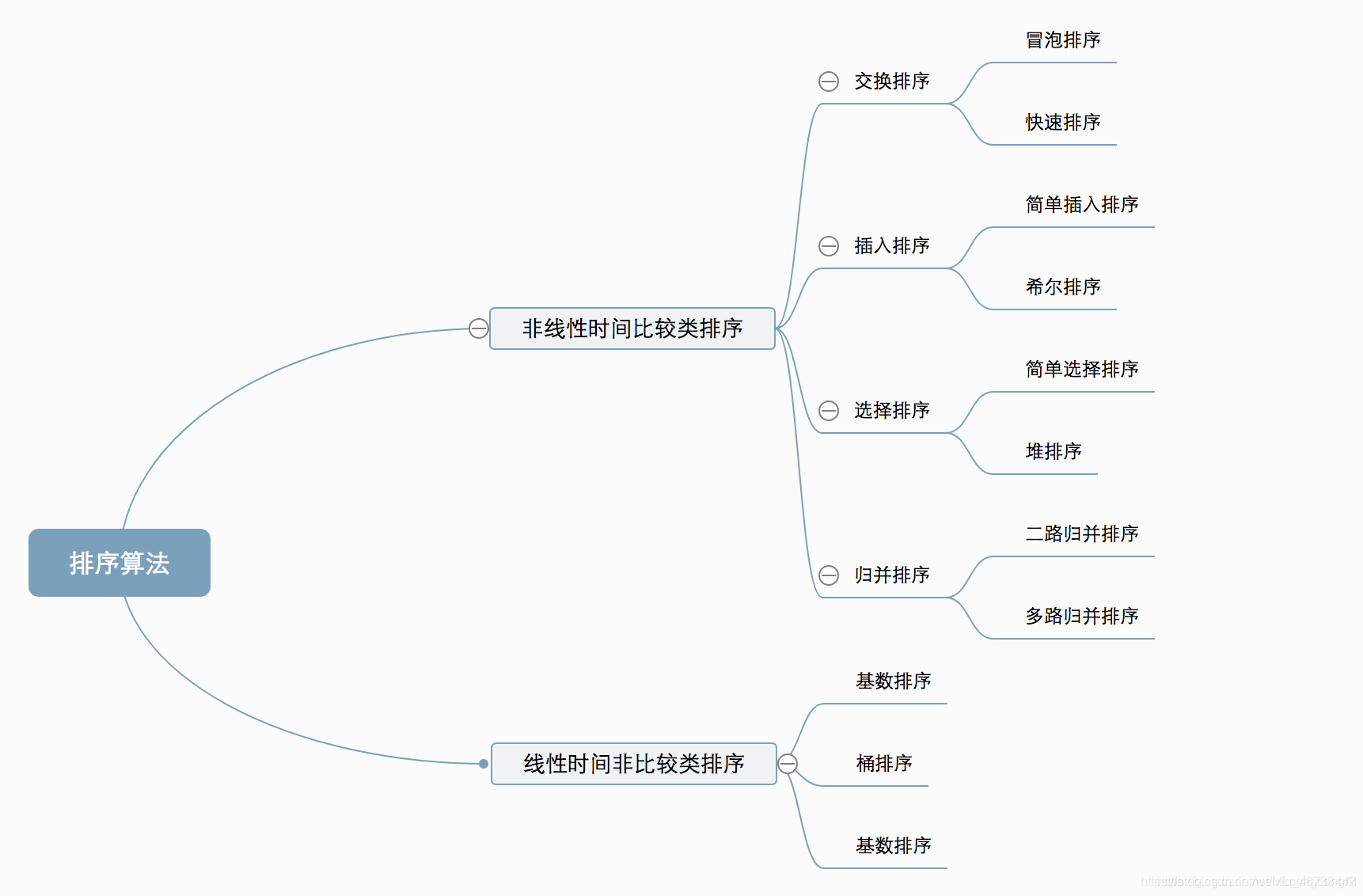
- 排序种类:
插入排序:直接插入排序、希尔排序
交换排序:冒泡排序、快速排序
选择排序:直接选择排序、堆排序
归并排序:二路归并,多路归并排序(外排序)
基数排序、计数排序、桶排序
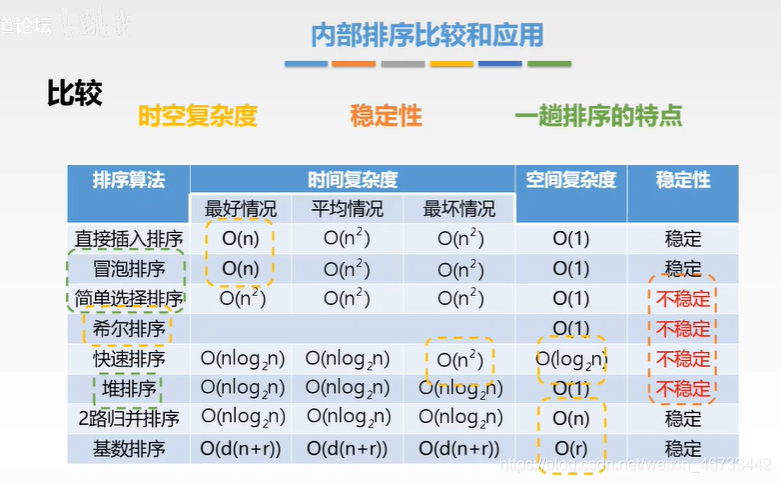
- 排序算法稳定性:相同数字在排序前后相对位置不变。
不稳定:希尔排序、快速排序、直接选择排序、堆排序
不稳定:直接选择排序、冒泡排序、归并排序、基数排序、计数排序、桶排序 - 排序算法时间复杂度:
T(n)=O(n^2)直接插入排序、直接选择排序、冒泡排序
T(n)=O(nlog2 n)希尔排序、快速排序、堆排序、归并排序
T(n)=O(n)基数排序、计数排序、桶排序 - 排序算法空间复杂度:
S(n)=O(1)直接插入排序、希尔排序、冒泡排序、直接插入排序、堆排序
S(n)=O(log2 n)快速排序
S(n)=O(n)归并排序
S(n)=O( r)基数排序
- 直接插入排序:和打扑克牌一样,把未排序的部分按序取出一个元素插入到已经排序好的有序序列中,插入位置从前往后找。时间复杂度O(n^2),空间复杂度O(1)
- 希尔排序:分组直接插入排序,将排序元素按增量序列分为几组,组内直接插入排序,缩减增量,使得元素基本有序,在进行一次直接插入排序。时间复杂度O(nlog2 n),空间复杂度O(1)
- 冒泡排序:比较相邻元素的值。时间复杂度O(n^2),空间复杂度O(1)
- 快速排序:从左到右的元素都能一次性找到自己最终位置。piovt基准,low,high。时间复杂度O(nlog2 n),空间复杂度O(log2 n)
- 直接选择排序:在给定的一组记录中选择最小的和第一个记录交换,然后从第二个记录到最后记录中找最小的和第二个记录交换,如此下去。方式可选小放前面、选大放后面。时间复杂度O(n^2),空间复杂度O(1)
- 堆排序:大根堆、小根堆。时间复杂度O(nlon2 n),空间复杂度O(1)
- 二路归并排序:两两归并,排序成一个个有序序列。时间复杂度O(nlog2 n),空间复杂度O(n)
- 基数排序:实现方法为最高位优先、最低为优先。利用辅助队列按位收集和分配。时间复杂度O(n),空间复杂度O(r )
智能推荐
python 批量下载 GPM 数据_python批量下载gpm-程序员宅基地
文章浏览阅读2.7k次,点赞3次,收藏22次。前期准备:我是从 GES DISC 下载GPM数据,首先是注册账号,这个就不用说了。然后,注意按说明获取授权,这个教程很详细啦,不再过多介绍。下载过程:1. 手动下载 list of links。选择你要下载的数据时间范围、区域、等等,然后下载包含所有下载连接的 txt 文件。2. 在用户目录(windows,linux为根目录~)创建 .netrc 文件, 内容就是自己的账号和密码.netrc 文件的内容:machine urs.earthdata.nasa.g.._python批量下载gpm
吴恩达机器学习作业(一):线性回归(python实现)_机器学习ex1data sklearn-程序员宅基地
文章浏览阅读1.8k次,点赞6次,收藏13次。在本部分的练习中,您将使用一个变量实现线性回归,以预测食品卡车的利润。假设你是一家餐馆的首席执行官,正在考虑不同的城市开设一个新的分店。该连锁店已经在各个城市拥有卡车,而且你有来自城市的利润和人口数据。您希望使用这些数据来帮助您选择将哪个城市扩展到下一个城市。梯度下降法import numpy as npimport pandas as pdimport matplotlib.pypl..._机器学习ex1data sklearn
苹果手机怎么用计算机打出字,使用苹果手机的注意啦!iphone输入法不好用?这些使用技巧教给你...-程序员宅基地
文章浏览阅读4.8k次。作为高端手机的象征,iphone已经成功收获了不少用户的青睐。但是美中不足的是,苹果手机自带的输入法却十分鸡肋。让不少人转投第三方输入法的怀抱。但其实只要熟练掌握了使用技巧,苹果原生输入法照样好用。今天就给大家带来几个iphone输入法实用的小技巧,绝对实用!看完别忘了分享给使用苹果手机的朋友!1.一键get超多特殊符号经常听到有人因为“iPhone 输入法能选择的符号太少”而转投第三方。在此我想..._苹果手机打字第一个字母看不到
Redis之Redisson原理详解_redission原理-程序员宅基地
文章浏览阅读2.5k次,点赞3次,收藏15次。Redisson顾名思义,Redis的儿子,本质上还是Redis加锁,不过是对Redis做了很多封装,它不仅提供了一系列的分布式的Java常用对象,还提供了许多分布式服务。_redission原理
TP-LINK-TL-WR703N刷Breed用Openwrt固件挂MP288打印机服务共享手机打印服务_703breed固件-程序员宅基地
文章浏览阅读3.2w次,点赞17次,收藏87次。TP-LINK-TL-WR703N刷Breed用Openwrt固件挂MP288打印机服务共享手机打印服务参考资料:U-Boot 刷机方法大全:https://www.right.com.cn/forum/thread-154561-1-1.htmlopenwrt官网703N说明https://openwrt.org/toh/tp-link/tl-wr703nopenw..._703breed固件
python函数_def add-程序员宅基地
文章浏览阅读1.5k次。一、函数定义与调用"""定义一个函数"""def add(): print("this is a test function!")add()#调用函数add二、函数的返回值(返回值不会直接输出,只有在需要的时候可以进行输出和相关运算)"""定义一个函数add返回两个数的相加结果"""def add(): n=2 m=5 return n+mcount=add()#调用函数addprint(count)#打印返回值7三、函数的参数_def add
随便推点
浅谈数据指标以及指标体系_数据指标体系实用-程序员宅基地
文章浏览阅读3.2k次。作者介绍@Albert就职于某知名大数据服务公司;专注于数据产品、数据埋点和用户行为数据分析和应用;“数据人创作者联盟”成员。00导语笔者之前就用户行为数据写过一篇科普文《用户行为数据入门理论与实例》,里面有对用户行为分析的整体介绍,其中包括数据指标以及指标体系搭建这个重要的环节;但是受文章篇幅所限,不能完整、体系化地介绍数据指标、指标体系以及其搭建方法。于是笔者结合自己工作经验撰写了这篇文章,希望能给各位同学带来启发和思考。至于为何这篇文章被命名为“浅谈”,主要还._数据指标体系实用
微信小程序云开发增删改查_微信小程序增删改查实例代码-程序员宅基地
文章浏览阅读384次。#####查询语句的第二种写法。_微信小程序增删改查实例代码
R语言使用lm函数构建简单线性回归模型(建立线性回归模型)、拟合回归直线、使用plot函数可视化模型诊断图(第二幅图可视化QQ图、判断残差是否符合正态分布)-程序员宅基地
文章浏览阅读393次。R语言使用lm函数构建简单线性回归模型(建立线性回归模型)、拟合回归直线、使用plot函数可视化模型诊断图(第二幅图可视化QQ图、判断残差是否符合正态分布)
加密文件如何解密?_文件解密-程序员宅基地
文章浏览阅读1.1k次。加密文件如何解密?_文件解密
腾讯面试之软件测试_腾讯广研软件测试复试-程序员宅基地
文章浏览阅读4.4k次,点赞3次,收藏5次。前期准备:看了一个星期的程序员面试宝典,并且参考了数据结构书籍。网申填写了一份电子简历,之后就按部就班的学习。结果简历筛选为过,未收到腾讯短信通知,有点郁闷,想就此结束,准备百度实习招聘。但是经过思想斗争,最后还会决定和同学一块参加了霸笔。笔试:霸笔的人被安排在一个房间,按填报岗位,分区入座。结果偌大的教室里竟然绝大部分都是研发。监考人员说这个房间的人不一定每人都有试卷。我来的较晚_腾讯广研软件测试复试
从零配置webpack-vue项目(2)-程序员宅基地
文章浏览阅读899次,点赞28次,收藏21次。const path = require(‘path’) //需要引入node模块const VueLoaderPlugin = require(‘vue-loader/lib/plugin’) //vue插件const HtmlWebpackPlugin = require(‘html-webpack-plugin’) //html插件//自动清理打包后文件插件entry:{},output:{ //导出文件配置。