Spark SQL中StructField和StructType-程序员宅基地
每一天都会进行更新,一起冲击未来
StructField和StructType
StructType---定义数据框的结构
StructType定义DataFrame的结构,是StructField对象的集合或者列表,通过printSchema可以打印出所谓的表字段名,StructType就是所有字段的集合。在创建dataframe的时候,将StructType作为字段的集合,按照顺序一一给各个字段。
StructField--定义DataFrame列的元数据
StructField来定义列名,列类型,可为空的列和元数据。
将StructField和StructType和DataFrame一起使用
首先创建样例类
case class StructType(fields: Array[StructField])
case class StructField(
name: String,
dataType: DataType,
nullable: Boolean = true,
metadata: Metadata = Metadata.empty)创建相关的数据以及字段名
//创建数据集合
val simpleData = Seq(
Row("James ","","Smith","36636","M",3000),
Row("Michael ","Rose","","40288","M",4000),
Row("Robert ","","Williams","42114","M",4000),
Row("Maria ","Anne","Jones","39192","F",4000),
Row("Jen","Mary","Brown","","F",-1) )
//创建StructType对象,里面是Array[StructField]类型
val simpleSchema = StructType(Array(
StructField("firstname",StringType,true),
StructField("middlename",StringType,true),
StructField("lastname",StringType,true),
StructField("id", StringType, true),
StructField("gender", StringType, true),
StructField("salary", IntegerType, true) ))
//创建dataFrame
val df = spark.createDataFrame(
spark.sparkContext.parallelize(simpleData),simpleSchema)
//打印Schema
df.printSchema()
代码很简答,需要一个数据集合,创建一个StructType对象,里面包含StructField对象。
前面说过,StructField对象里面包含的是列名以及各种信息。
创建DataFrame。此时,元数据就是simpleData,所谓的Schema就是simpleSchema。
看一下各个字段以及“表结构”
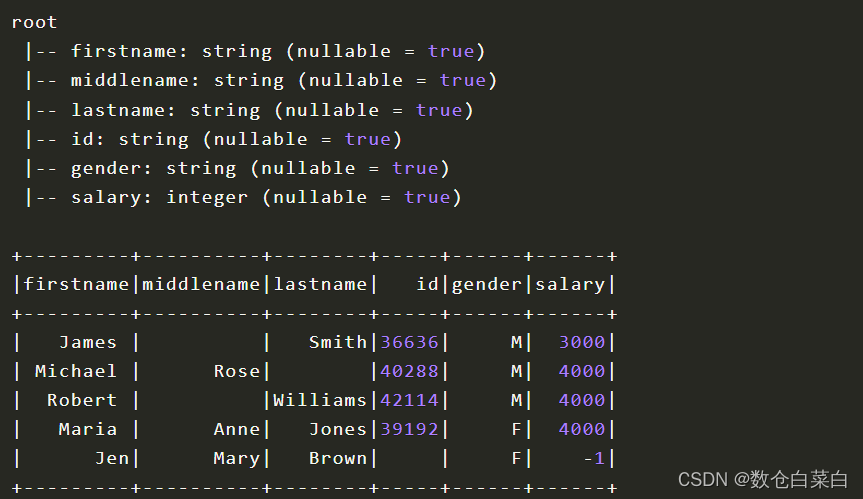
其实上面的案例也比较有一些麻烦,下面来看一下另外一种方法,不用创建样例类
通过StructType.add进行操作
通过StructType.add进行操作,意味着我们不用再去创建StructField对象,通过add方法,只需要写入字段名称和字段方法就可以完成这个操作。
//创建上下文环境 SparkSql环境
val sparkSQL = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val sparkSession = SparkSession.builder().config(sparkSQL).getOrCreate()
import sparkSession.implicits._
//数据集合
val simpData = Seq(Row("James", "", "Smith", "36636", "M", 3000),
Row("Michael", "Rose", "", "40288", "M", 4000),
Row("Robert", "", "Williams", "42114", "M", 4000),
Row("Maria", "Anne", "Jones", "39121", "F", 4000),
Row("Jen", "Mary", "Brown", "", "F", -1))
//创建StructType对象,将字段进行累加
val structType = new StructType()
.add("firstname", StringType)
.add("middlename", StringType)
.add("lastname", StringType)
.add("id", StringType)
.add("gender", StringType)
.add("salary", StringType)
//创建DataFrame
val dataFrame = sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(simpData), structType)
dataFrame.printSchema()
sparkSession.close()同样也是需要数据集合以及StructType对象。不过这种操作更加的简便,重要的是不会报错,用最上面的方法创建样例类可能会报错,需要导入不同的包。
使用StructType进行嵌套字段
//创建Spark SQL环境
val sparkSQL = new SparkConf().setMaster("local[*]").setAppName("SparkSQL")
val sparkSession = SparkSession.builder().config(sparkSQL).getOrCreate()
import sparkSession.implicits._
//创建数据集,其中最里面的Row对象就是嵌套对象
val structData = Seq( Row(Row("James ", "", "Smith"), "36636", "M", 3100),
Row(Row("Michael ", "Rose", ""), "40288", "M", 4300),
Row(Row("Robert ", "", "Williams"), "42114", "M", 1400),
Row(Row("Maria ", "Anne", "Jones"), "39192", "F", 5500),
Row(Row("Jen", "Mary", "Brown"), "", "F", -1))
//通过StructType的add方法进行添加字段
val structType = new StructType()
.add("name",new StructType()
.add("firstname",StringType)
.add("middlename",StringType)
.add("lastname",StringType))
.add("id",StringType)
.add("gender",StringType)
.add("salary",StringType)
//创建dataframe
val dataFrame =
sparkSession.createDataFrame(
sparkSession.sparkContext.parallelize(structData), structType)
//打印schema
dataFrame.printSchema()
sparkSession.close()因为name字段进行了嵌套,因此在"name"字段后面的类型里面不再是StringType.而是一个嵌套类型 StructType,这个嵌套类型里面再继续进行add。在这里面嵌套了三个字段。

可以看上面Schema。那么字段的类型是Struct结构。这个Struct结构里面嵌套了三个字段。
其实上面写错了,纠正一下,最后一个字段应该是IntegerType类型
如果写StringType类型,虽然打印Schema没有报错,但是进行select的时候就会报错。所以需要进行修改,在这里说明一下。
dataFrame.select("name").show(false)
看一下嵌套字段的name

本来以为Spark SQL的知识只有一点点,没有想到的是Spark SQL里面的知识很多很多,不单单是SQL语言,虽然可以结合Hive或者Mysql写SQL,但是结构化数据使用本身的DSL+SQL更加的简单。
SQL是重中之重,SQL能解决90%问题,剩下解决不了的问题就交给RDD把
智能推荐
ASA与PIX的区别-程序员宅基地
文章浏览阅读68次。很多年来,Cisco PIX一直都是Cisco确定的防火墙。但是在2005年5月,Cisco推出了一个新的产品——适应性安全产品(ASA,Adaptive Security Appliance)。不过,PIX还依旧可用。我已听到很多人在多次询问这两个产品线之间的差异到底是什么。让我们来看一看。Cisco PIX是什么?Cisco PIX是一种专用的硬件防火墙。所有版本..._pix asa区别
TensorFlow conv2d原理及实践-程序员宅基地
文章浏览阅读235次。tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, data_format=None, name=None)官方教程说明:给定四维的input和filtertensor,计算一个二维卷积Args:input: ATensor. type必须是以下几种类型之一:half,float32,..._conv2d原理 l
linux服务器初始化(防火墙、内核优化、时间同步、打开文件数)-程序员宅基地
文章浏览阅读83次。#!/bin/bashread -p 'enter the network segment for visiting the server:' ips# 关闭firewalld和selinuxsystemctl stop firewalldsystemctl disable firewalldsed -i 's\SELINUX=enforcing\SEL..._服务器是不是没做打开文件数优化
solr7集群 springboot_springboot整合solr-程序员宅基地
文章浏览阅读116次。一、本文将solr安装在linux上。首先先安装好jdk和tomcat。配置环境:jdk8,tomcat8.5,solr7.2.1.。二、复制Solr文件夹中的一些文件到apache-tomcat下:1)将 solr 压缩包中 solr\server\solr-webapp\文件夹下有个webapp文件夹,将之复制到tomcat\webapps\目录下,文件夹名改成solr(任意) ;cp -R ..._springboot solr7
在java中已经规定数据类型是长整形为什么数字后面还要加一个"l"啊?前面不是有long吗?_java数字后面加l是什么意思-程序员宅基地
文章浏览阅读2.6k次,点赞2次,收藏5次。说到这就不得不谈java的内存体制,建议你好好研究下这个。example:long l1 = 10000000000L;实际上内存中l1只是一个long类型的变量,它存在于向stack(栈)中,数值并不在其中存放,它指向heap(堆)中另一块真正存放数值的内存,加L的目的就是为了让heap中也创建一块long类型所需要的内存,用来来放数值。所以说=前后两者其实是在不同的两块内存,只不过有..._java数字后面加l是什么意思
最完整的RocketMq部署程序,包括rocketmq-console部署和测试程序的介绍_rocketmq-console-test-程序员宅基地
文章浏览阅读4k次。文章目录1.RocketMq部署准备工作RocketMq程序的获取启动NameServer启动Broker查看log日志2.运维工具部署获取程序参数配置运行程序3.实际测试代码获取运行4.开始学习~1.RocketMq部署本文详细介绍了安装rocketMq 前后的方法和一些注意事项 ,设备为centos7,话不多说,begin。准备工作RocketMq程序的获取首先需要获取rocketM..._rocketmq-console-test
随便推点
20 个最重要的 DevOps 面试题-程序员宅基地
文章浏览阅读2.5k次。点击下方公众号「关注」和「星标」回复“1024”获取独家整理的学习资料!DevOps 代表开发和运营。这是一种新的软件开发形式,彻底改变了软件产品的开发和分发方式。DevOps方法论着眼于..._devops面试题
根据时间生成分配批次号-程序员宅基地
文章浏览阅读1.3k次。1 /** 2 * 根据当前时间生成分配批次号 3 * 4 * @return 5 */ 6 private String createBatchNo() { 7 // 批次号第一部分:时间 8 DateFormat dateFormat = new SimpleD..._java根据时间生成批注号
Nodejs之事件驱动+非阻塞io模型_了基于事件驱动和非阻塞 i/o 的模型-程序员宅基地
文章浏览阅读6.5k次,点赞2次,收藏8次。1什么是i/o? io input、output 输入输出,电脑的输入输出,例如音频录音表示声音输入、听音乐是声音的输出 网络上的传输全部是在传字符串,i/o在服务器上可以理解为读写操作。2什么是并发? 一个时间段中有几个程序都处于已启动运行到运行完毕之间。3异步i/o与事件驱动3.1什么是进程?进程是为运行当中的应用程序提供运行环境的一个运行当中的应用程序就会有一个进程与之相对应3_了基于事件驱动和非阻塞 i/o 的模型
tv端h5_H5在三端开发遇到的问题(TV/PC/MOBILE)-程序员宅基地
文章浏览阅读1.1k次。项目简介公司最近开发会员体系项目,前端利用H5技术嵌入三端开发页面,TV端原生技术是C++,PC端原生技术是JAVA。传值问题Javascript与安卓/IOS进行交互。原生把方法暴露给window。前端只需要下window对象调用方法,进行传值即可。notice:function(token,uuid){var pattern = new RegExp('iPhone|iPad', 'ig');..._电视端app可以用h5写吗
python下mqtt服务器的搭建_转 【MQTT】在Windows下搭建MQTT服务器-程序员宅基地
文章浏览阅读498次。MQTT简介MQ 遥测传输 (MQTT) 是轻量级基于代理的发布/订阅的消息传输协议,设计思想是开放、简单、轻量、易于实现。这些特点使它适用于受限环境。该协议的特点有:使用发布/订阅消息模式,提供一对多的消息发布,解除应用程序耦合。对负载内容屏蔽的消息传输。使用 TCP/IP 提供网络连接。小型传输,开销很小(固定长度的头部是 2 字节),协议交换最小化,以降低网络流量。使用 Last Will ..._python window环境搭建 mqtt服务端
win10安装python详细过程_win10怎么正确安装python-程序员宅基地
文章浏览阅读10w+次,点赞53次,收藏173次。关于python的安装一切语言皆为工具接下来咱们就开始吧一切语言皆为工具既然你决定安装它,那就已经告知自己要掌握这门工具,但是有一定你一定要铭记于心那就是:python 是个工具时刻想着如何用它解决你的问题【哪怕是一个简单的想法】接下来咱们就开始吧下载安装软件包登录官网 :https://www.python.org/downloads/release/python-373..._win10怎么正确安装python