Flink 实时写入数据到 ElasticSearch 性能调优-程序员宅基地
背景说明
线上业务反应使用 Flink 消费上游 kafka topic 里的轨迹数据出现 backpressure,数据积压严重。单次 bulk 的写入量为:3000/50mb/30s,并行度为 48。针对该问题,为了避免影响线上业务申请了一个与线上集群配置相同的 ES 集群。本着复现问题进行优化就能解决的思路进行调优测试。
测试环境
Elasticsearch 2.3.3
Flink 1.6.3
flink-connector-elasticsearch 2_2.11
八台 SSD,56 核 :3 主 5 从
Rally 分布式压测 ES 集群
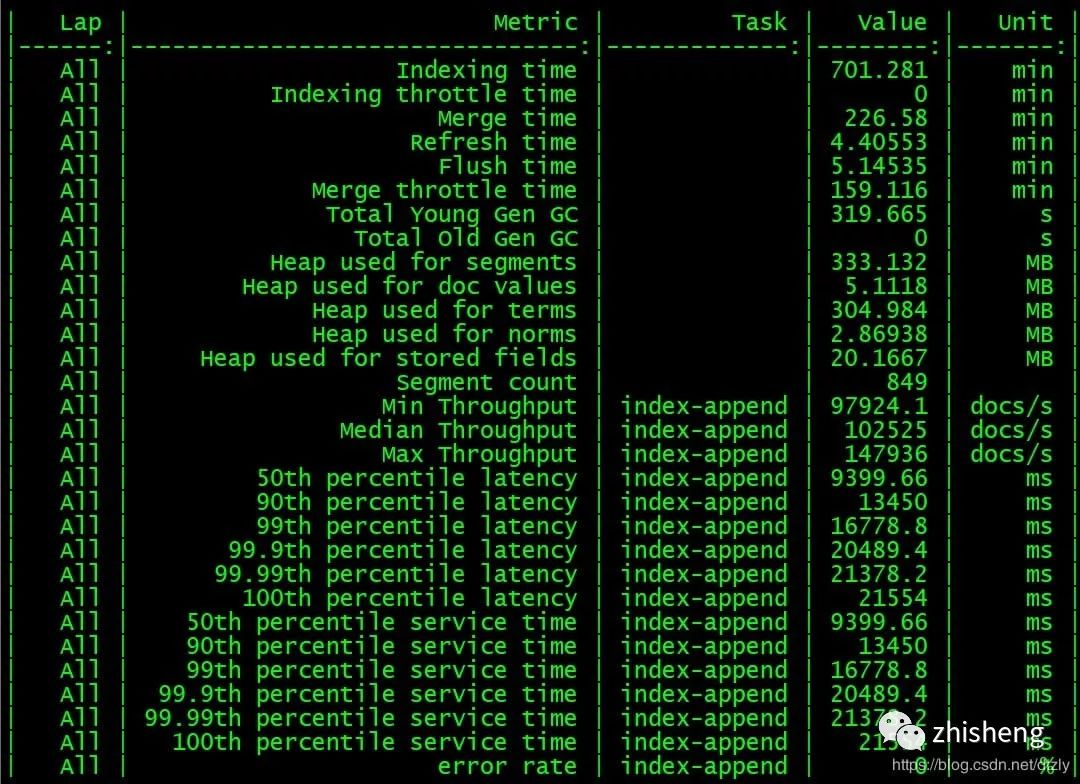
从压测结果来看,集群层面的平均写入性能大概在每秒 10 w+ 的 doc。
Flink 写入测试
配置文件
1config.put("cluster.name", ConfigUtil.getString(ES_CLUSTER_NAME, "flinktest"));
2config.put("bulk.flush.max.actions", ConfigUtil.getString(ES_BULK_FLUSH_MAX_ACTIONS, "3000"));
3config.put("bulk.flush.max.size.mb", ConfigUtil.getString(ES_BULK_FLUSH_MAX_SIZE_MB, "50"));
4config.put("bulk.flush.interval.ms", ConfigUtil.getString(ES_BULK_FLUSH_INTERVAL, "3000"));执行代码片段
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
initEnv(env);
Properties properties = ConfigUtil.getProperties(CONFIG_FILE_PATH);
//从kafka中获取轨迹数据
FlinkKafkaConsumer010<String> flinkKafkaConsumer010 =
new FlinkKafkaConsumer010<>(properties.getProperty("topic.name"), new SimpleStringSchema(), properties);
//从checkpoint最新处消费
flinkKafkaConsumer010.setStartFromLatest();
DataStreamSource<String> streamSource = env.addSource(flinkKafkaConsumer010);
10//Sink2ES
streamSource.map(s -> JSONObject.parseObject(s, Trajectory.class))
.addSink(EsSinkFactory.createSinkFunction(new TrajectoryDetailEsSinkFunction())).name("esSink");
env.execute("flinktest");运行时配置
任务容器数为 24 个 container,一共 48 个并发。savepoint 为 15 分钟:
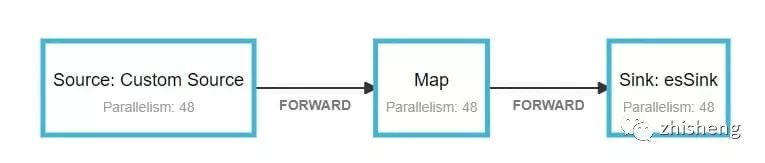
运行现象
(1)source 和 Map 算子均出现较高的反压
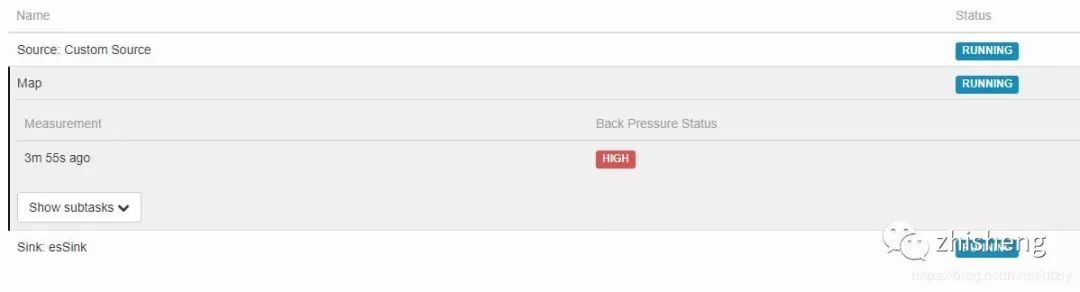
(2)ES 集群层面,目标索引写入速度写入陡降
平均 QPS 为:12 k 左右。
(3)对比取消 sink 算子后的 QPS
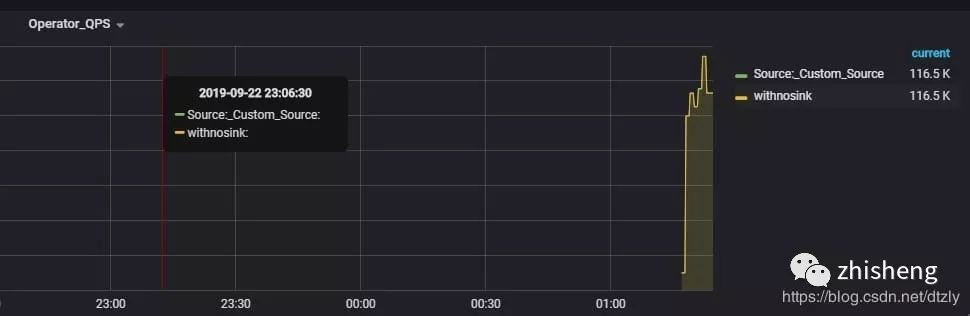
平均QPS为:116 k 左右。
有无sink参照实验的结论:
取消 sink 2 ES 的操作后,QPS 达到 110 k,是之前 QPS 的十倍。由此可以基本判定: ES 集群写性能导致的上游反压
优化方向
索引字段类型调整
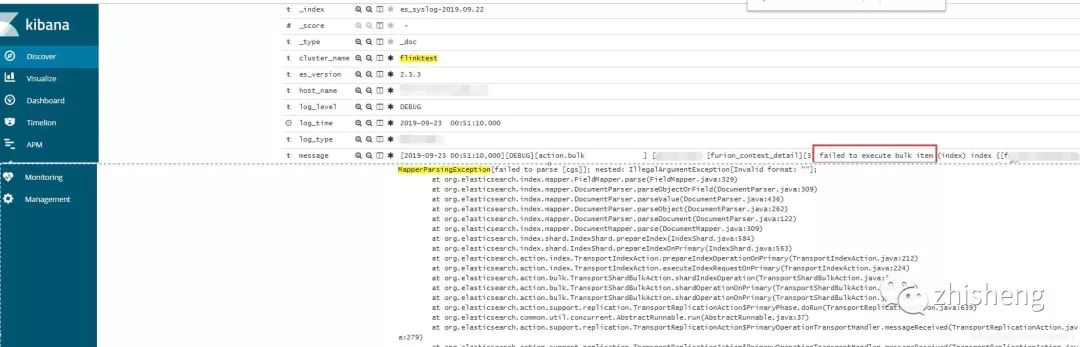
bulk 失败的原因是由于集群 dynamic mapping 自动监测,部分字段格式被识别为日期格式而遇到空字符串无法解析报错。
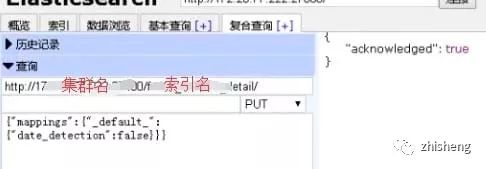
解决方案:关闭索引自动检测。
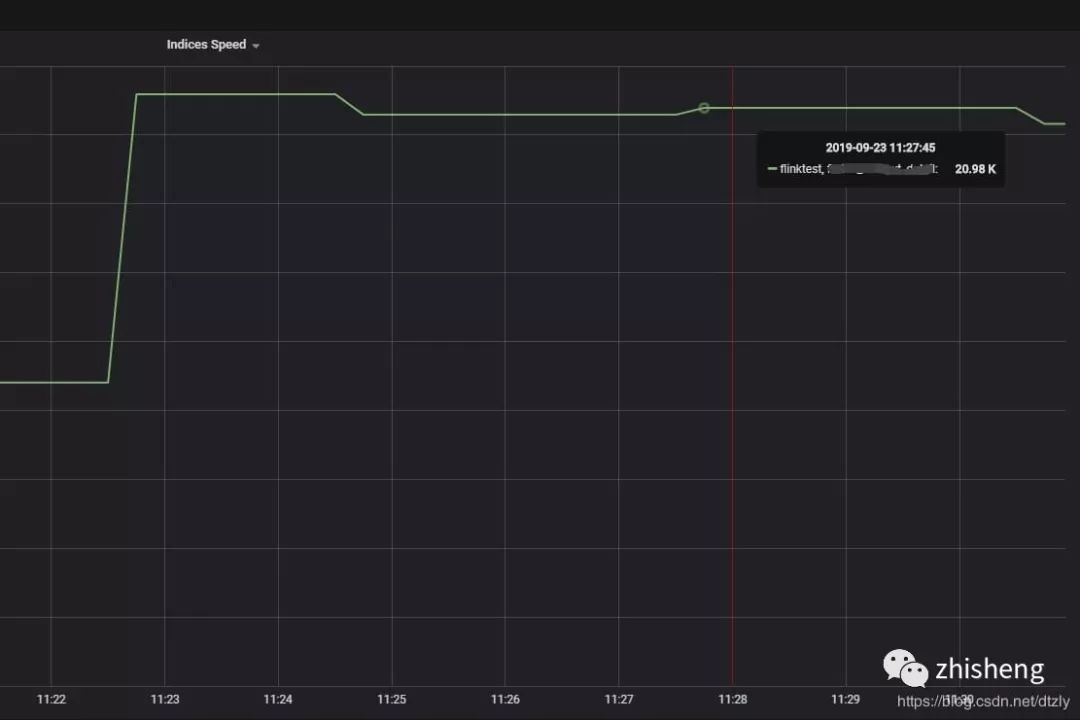
效果: ES 集群写入性能明显提高但 Flink operator 依然存在反压:
降低副本数
提高 refresh_interval
针对这种 ToB、日志型、实时性要求不高的场景,我们不需要查询的实时性,通过加大甚至关闭 refresh_interval 的参数提高写入性能。
检查集群各个节点 CPU 核数
在 Flink 执行时,通过 Grafana 观测各个节点 CPU 使用率以及通过 Linux 命令查看各个节点 CPU 核数。发现 CPU 使用率高的节点 CPU 核数比其余节点少。为了排除这个短板效应,我们将在这个节点中的索引 shard 移动到 CPU 核数多的节点。
curl -XPOST {集群地址}/_cluster/reroute -d'{"commands":[{"move":{"index":"{索引名称}","shard":5,"from_node":"源node名称","to_node":"目标node名称"}}]}' -H "Content-Type:application/json"以上优化的效果:
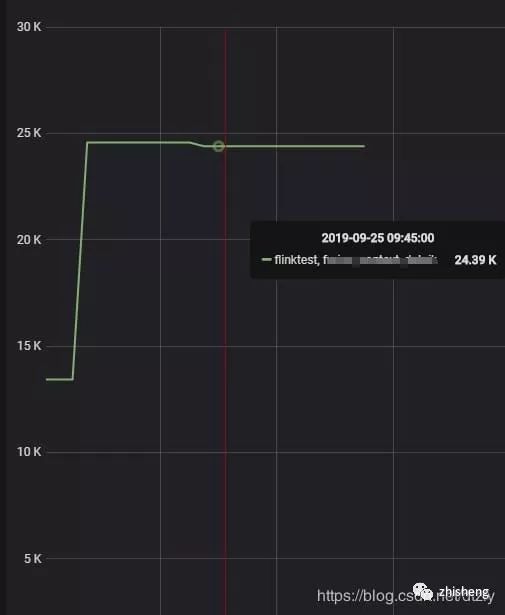
经过以上的优化,我们发现写入性能提升有限。因此,需要深入查看写入的瓶颈点。
在 CPU 使用率高的节点使用 Arthas 观察线程
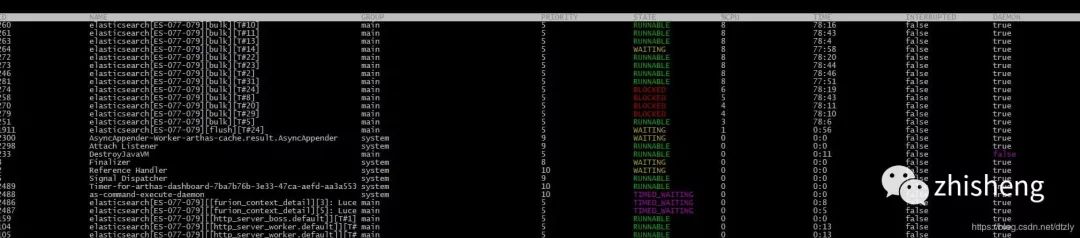
打印阻塞的线程堆栈
"elasticsearch[ES-077-079][bulk][T#3]" Id=247 WAITING on java.util.concurrent.LinkedTransferQueue@369223fa
at sun.misc.Unsafe.park(Native Method)
- waiting on java.util.concurrent.LinkedTransferQueue@369223fa
at java.util.concurrent.locks.LockSupport.park(LockSupport.java:175)
at java.util.concurrent.LinkedTransferQueue.awaitMatch(LinkedTransferQueue.java:737)
at java.util.concurrent.LinkedTransferQueue.xfer(LinkedTransferQueue.java:647)
at java.util.concurrent.LinkedTransferQueue.take(LinkedTransferQueue.java:1269)
at org.elasticsearch.common.util.concurrent.SizeBlockingQueue.take(SizeBlockingQueue.java:161)
at java.util.concurrent.ThreadPoolExecutor.getTask(ThreadPoolExecutor.java:1067)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1127)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)从上面的线程堆栈我们可以看出线程处于等待状态。
关于这个问题的讨论详情查看 https://discuss.elastic.co/t/thread-selection-and-locking/26051/3,这个 issue 讨论大致意思是:节点数不够,需要增加节点。于是我们又增加节点并通过设置索引级别的 total_shards_per_node 参数将索引 shard 的写入平均到各个节点上。
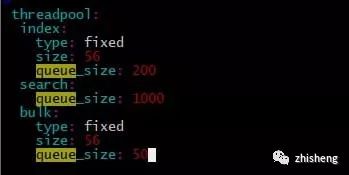
线程队列优化
ES 是将不同种类的操作(index、search…)交由不同的线程池执行,主要的线程池有三:index、search 和 bulk thread_pool。线程池队列长度配置按照官网默认值,我觉得增加队列长度而集群本身没有很高的处理能力线程还是会 await(事实上实验结果也是如此在此不必赘述),因为实验节点机器是 56 核,对照官网:

因此修改 size 数值为 56。
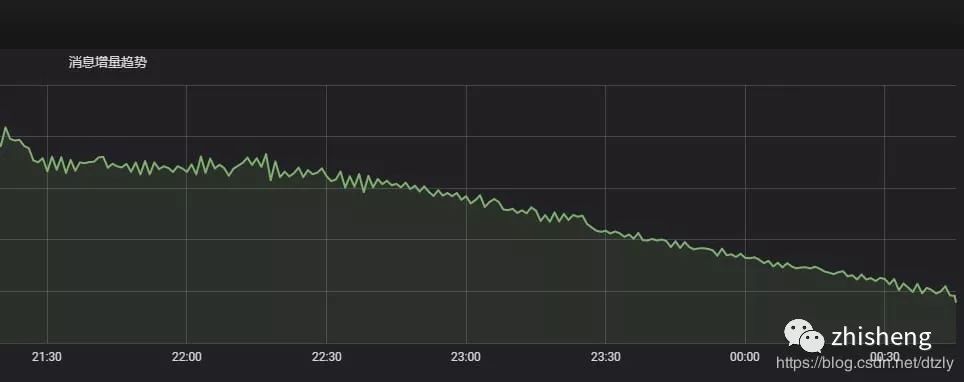
经过以上的优化,我们发现在 kafka 中的 topic 积压有明显变少的趋势:
index buffer size 的优化
参照官网:

translog 优化:
索引写入 ES 的基本流程是:
数据写入 buffer 缓冲和 translog;
每秒 buffer 的数据生成 segment 并进入内存,此时 segment 被打开并供 search 使用查询;
buffer 清空并重复上述步骤 ;
buffer 不断添加、清空 translog 不断累加,当达到某些条件触发 commit 操作,刷到磁盘;
ES 默认的刷盘操作为 Request 但容易部分操作比较耗时,在日志型集群、允许数据在刷盘过程中少量丢失可以改成异步 async。
另外一次 commit 操作是在 translog 达到某个阈值执行的,可以把大小(flush_threshold_size )调大,刷新间隔调大。
index.translog.durability : async
index.translog.flush_threshold_size : 1gb
index.translog.sync_interval : 30s效果:
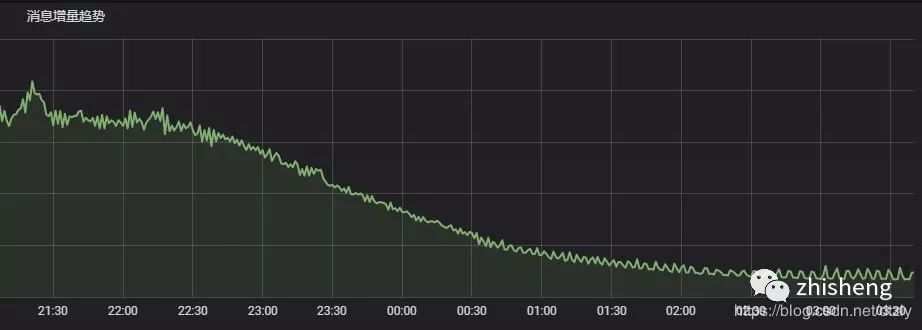
Flink 反压从打满 100% 降到 40%(output buffer usage):

kafka 消费组里的积压明显减少:
总结
当 ES 写入性能遇到瓶颈时,我总结的思路应该是这样:
看日志,是否有字段类型不匹配,是否有脏数据。
看 CPU 使用情况,集群是否异构
客户端是怎样的配置?使用的 bulk 还是单条插入
查看线程堆栈,查看耗时最久的方法调用
确定集群类型:ToB 还是 ToC,是否允许有少量数据丢失?
针对 ToB 等实时性不高的集群减少副本增加刷新时间
index buffer 优化 translog 优化,滚动重启集群
Apache Flink 及大数据领域盛会 Flink Forward Asia 2019 将于 11月28-30日在北京举办,阿里、腾讯、美团、字节跳动、百度、英特尔、DellEMC、Lyft、Netflix 及 Flink 创始团队等近 30 家知名企业资深技术专家齐聚国际会议中心,与全球开发者共同探讨大数据时代核心技术与开源生态。点击「阅读原文」了解更多精彩议程。
▼
智能推荐
艾美捷Epigentek DNA样品的超声能量处理方案-程序员宅基地
文章浏览阅读15次。空化气泡的大小和相应的空化能量可以通过调整完全标度的振幅水平来操纵和数字控制。通过强调超声技术中的更高通量处理和防止样品污染,Epigentek EpiSonic超声仪可以轻松集成到现有的实验室工作流程中,并且特别适合与表观遗传学和下一代应用的兼容性。Epigentek的EpiSonic已成为一种有效的剪切设备,用于在染色质免疫沉淀技术中制备染色质样品,以及用于下一代测序平台的DNA文库制备。该装置的经济性及其多重样品的能力使其成为每个实验室拥有的经济高效的工具,而不仅仅是核心设施。
11、合宙Air模块Luat开发:通过http协议获取天气信息_合宙获取天气-程序员宅基地
文章浏览阅读4.2k次,点赞3次,收藏14次。目录点击这里查看所有博文 本系列博客,理论上适用于合宙的Air202、Air268、Air720x、Air720S以及最近发布的Air720U(我还没拿到样机,应该也能支持)。 先不管支不支持,如果你用的是合宙的模块,那都不妨一试,也许会有意外收获。 我使用的是Air720SL模块,如果在其他模块上不能用,那就是底层core固件暂时还没有支持,这里的代码是没有问题的。例程仅供参考!..._合宙获取天气
EasyMesh和802.11s对比-程序员宅基地
文章浏览阅读7.7k次,点赞2次,收藏41次。1 关于meshMesh的意思是网状物,以前读书的时候,在自动化领域有传感器自组网,zigbee、蓝牙等无线方式实现各个网络节点消息通信,通过各种算法,保证整个网络中所有节点信息能经过多跳最终传递到目的地,用于数据采集。十多年过去了,在无线路由器领域又把这个mesh概念翻炒了一下,各大品牌都推出了mesh路由器,大多数是3个为一组,实现在面积较大的住宅里,增强wifi覆盖范围,智能在多热点之间切换,提升上网体验。因为节点基本上在3个以内,所以mesh的算法不必太复杂,组网形式比较简单。各厂家都自定义了组_802.11s
线程的几种状态_线程状态-程序员宅基地
文章浏览阅读5.2k次,点赞8次,收藏21次。线程的几种状态_线程状态
stack的常见用法详解_stack函数用法-程序员宅基地
文章浏览阅读4.2w次,点赞124次,收藏688次。stack翻译为栈,是STL中实现的一个后进先出的容器。要使用 stack,应先添加头文件include<stack>,并在头文件下面加上“ using namespacestd;"1. stack的定义其定义的写法和其他STL容器相同, typename可以任意基本数据类型或容器:stack<typename> name;2. stack容器内元素的访问..._stack函数用法
2018.11.16javascript课上随笔(DOM)-程序员宅基地
文章浏览阅读71次。<li> <a href = "“#”>-</a></li><li>子节点:文本节点(回车),元素节点,文本节点。不同节点树: 节点(各种类型节点)childNodes:返回子节点的所有子节点的集合,包含任何类型、元素节点(元素类型节点):child。node.getAttribute(at...
随便推点
layui.extend的一点知识 第三方模块base 路径_layui extend-程序员宅基地
文章浏览阅读3.4k次。//config的设置是全局的layui.config({ base: '/res/js/' //假设这是你存放拓展模块的根目录}).extend({ //设定模块别名 mymod: 'mymod' //如果 mymod.js 是在根目录,也可以不用设定别名 ,mod1: 'admin/mod1' //相对于上述 base 目录的子目录}); //你也可以忽略 base 设定的根目录,直接在 extend 指定路径(主要:该功能为 layui 2.2.0 新增)layui.exten_layui extend
5G云计算:5G网络的分层思想_5g分层结构-程序员宅基地
文章浏览阅读3.2k次,点赞6次,收藏13次。分层思想分层思想分层思想-1分层思想-2分层思想-2OSI七层参考模型物理层和数据链路层物理层数据链路层网络层传输层会话层表示层应用层OSI七层模型的分层结构TCP/IP协议族的组成数据封装过程数据解封装过程PDU设备与层的对应关系各层通信分层思想分层思想-1在现实生活种,我们在喝牛奶时,未必了解他的生产过程,我们所接触的或许只是从超时购买牛奶。分层思想-2平时我们在网络时也未必知道数据的传输过程我们的所考虑的就是可以传就可以,不用管他时怎么传输的分层思想-2将复杂的流程分解为几个功能_5g分层结构
基于二值化图像转GCode的单向扫描实现-程序员宅基地
文章浏览阅读191次。在激光雕刻中,单向扫描(Unidirectional Scanning)是一种雕刻技术,其中激光头只在一个方向上移动,而不是来回移动。这种移动方式主要应用于通过激光逐行扫描图像表面的过程。具体而言,单向扫描的过程通常包括以下步骤:横向移动(X轴): 激光头沿X轴方向移动到图像的一侧。纵向移动(Y轴): 激光头沿Y轴方向开始逐行移动,刻蚀图像表面。这一过程是单向的,即在每一行上激光头只在一个方向上移动。返回横向移动: 一旦一行完成,激光头返回到图像的一侧,准备进行下一行的刻蚀。
算法随笔:强连通分量-程序员宅基地
文章浏览阅读577次。强连通:在有向图G中,如果两个点u和v是互相可达的,即从u出发可以到达v,从v出发也可以到达u,则成u和v是强连通的。强连通分量:如果一个有向图G不是强连通图,那么可以把它分成躲个子图,其中每个子图的内部是强连通的,而且这些子图已经扩展到最大,不能与子图外的任一点强连通,成这样的一个“极大连通”子图是G的一个强连通分量(SCC)。强连通分量的一些性质:(1)一个点必须有出度和入度,才会与其他点强连通。(2)把一个SCC从图中挖掉,不影响其他点的强连通性。_强连通分量
Django(2)|templates模板+静态资源目录static_django templates-程序员宅基地
文章浏览阅读3.9k次,点赞5次,收藏18次。在做web开发,要给用户提供一个页面,页面包括静态页面+数据,两者结合起来就是完整的可视化的页面,django的模板系统支持这种功能,首先需要写一个静态页面,然后通过python的模板语法将数据渲染上去。1.创建一个templates目录2.配置。_django templates
linux下的GPU测试软件,Ubuntu等Linux系统显卡性能测试软件 Unigine 3D-程序员宅基地
文章浏览阅读1.7k次。Ubuntu等Linux系统显卡性能测试软件 Unigine 3DUbuntu Intel显卡驱动安装,请参考:ATI和NVIDIA显卡请在软件和更新中的附加驱动中安装。 这里推荐: 运行后,F9就可评分,已测试显卡有K2000 2GB 900+分,GT330m 1GB 340+ 分,GT620 1GB 340+ 分,四代i5核显340+ 分,还有写博客的小盒子100+ 分。relaybot@re...