scrapy爬取前程无忧、应届生 数据+分析_大学生就业爬虫数据-程序员宅基地
一、总体要求
利用python编写爬虫程序,从招聘网站上爬取数据,将数据存入到MongoDB数据库中,将存入的数据作一定的数据清洗后做数据分析,最后将分析的结果做数据可视化。
二、环境
pycharm、mongodb、python3.6
三、爬取字段
1、具体要求:职位名称、薪资水平、招聘单位、工作地点、工作经验、学历要求、工作内容(岗位职责)、任职要求(技能要求)。
(1)新建一个项目:scrapy startproject pawuyijob
(2)生成一个spider文件:scrapy genspider wuyi wuyi.com
结构如下:

(3)修改settings.py
BOT_NAME = 'pawuyijob'
SPIDER_MODULES = ['pawuyijob.spiders']
NEWSPIDER_MODULE = 'pawuyijob.spiders'
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.106 Safari/537.36'
DOWNLOAD_DELAY = 0.5
ITEM_PIPELINES = {
'pawuyijob.pipelines.PawuyijobPipeline': 300,
}
(4)编写items.py
代码如下:
import scrapy
class PawuyijobItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
work_place = scrapy.Field() # 工作地点
company_name = scrapy.Field() # 公司名称
position_name = scrapy.Field() # 职位名称
company_info = scrapy.Field() # 公司信息
work_salary = scrapy.Field() # 薪资情况
release_date = scrapy.Field() # 发布时间
job_require = scrapy.Field() # 职位信息
contact_way = scrapy.Field() # 联系方式
education = scrapy.Field() # 学历
work_experience = scrapy.Field()#工作经验
pass
(5)编写spiders文件
我们最关键的东西就是能够把xpath找正确,很明显我们能看见每行数据都在这个标签中,我们可以写个循环
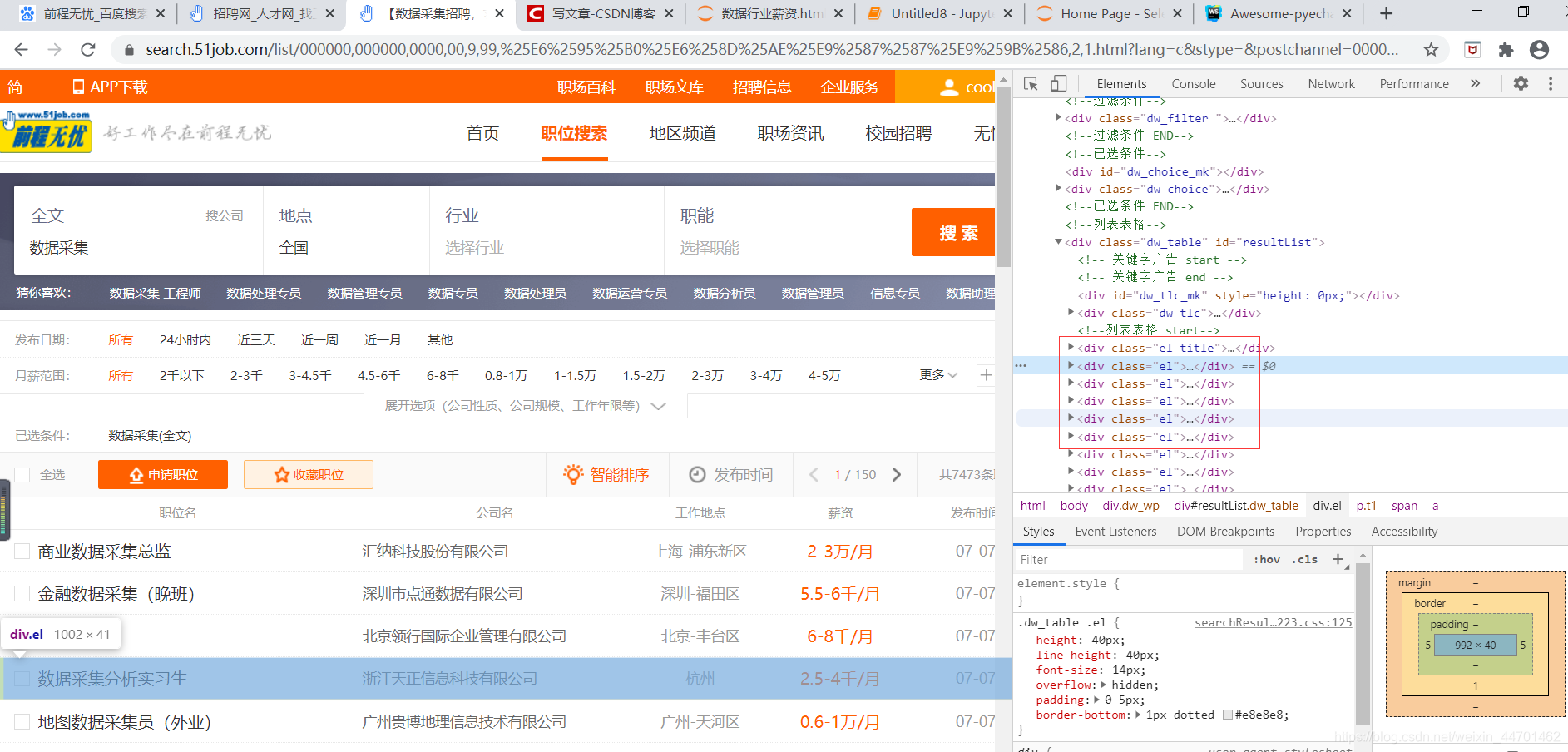
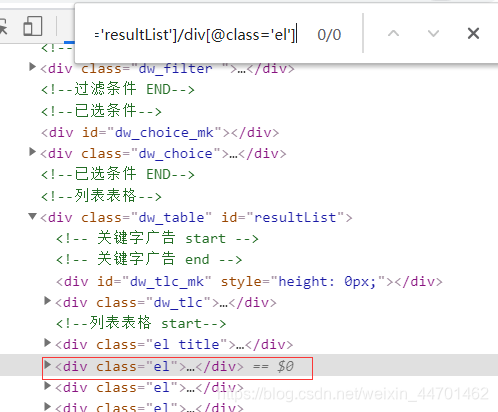
还有我们可以按住ctrl+f,看我们的xpath是否匹配到了
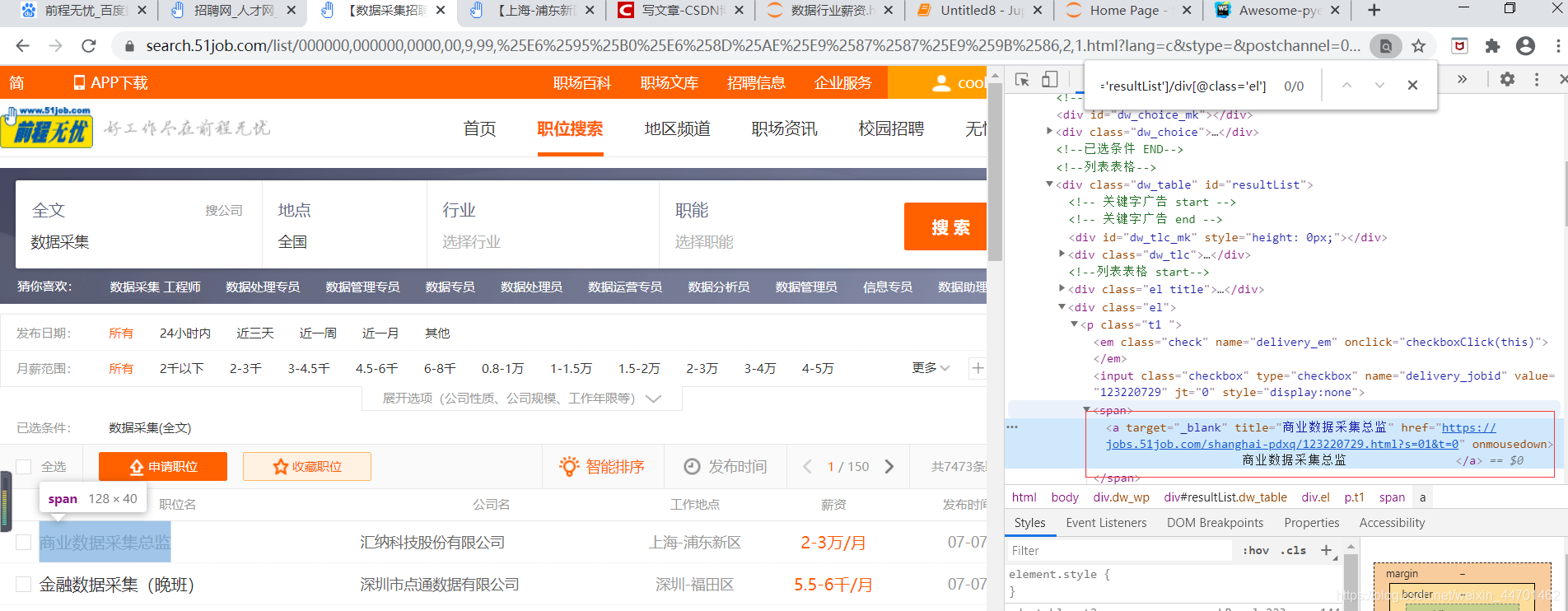
(6)详情页的url
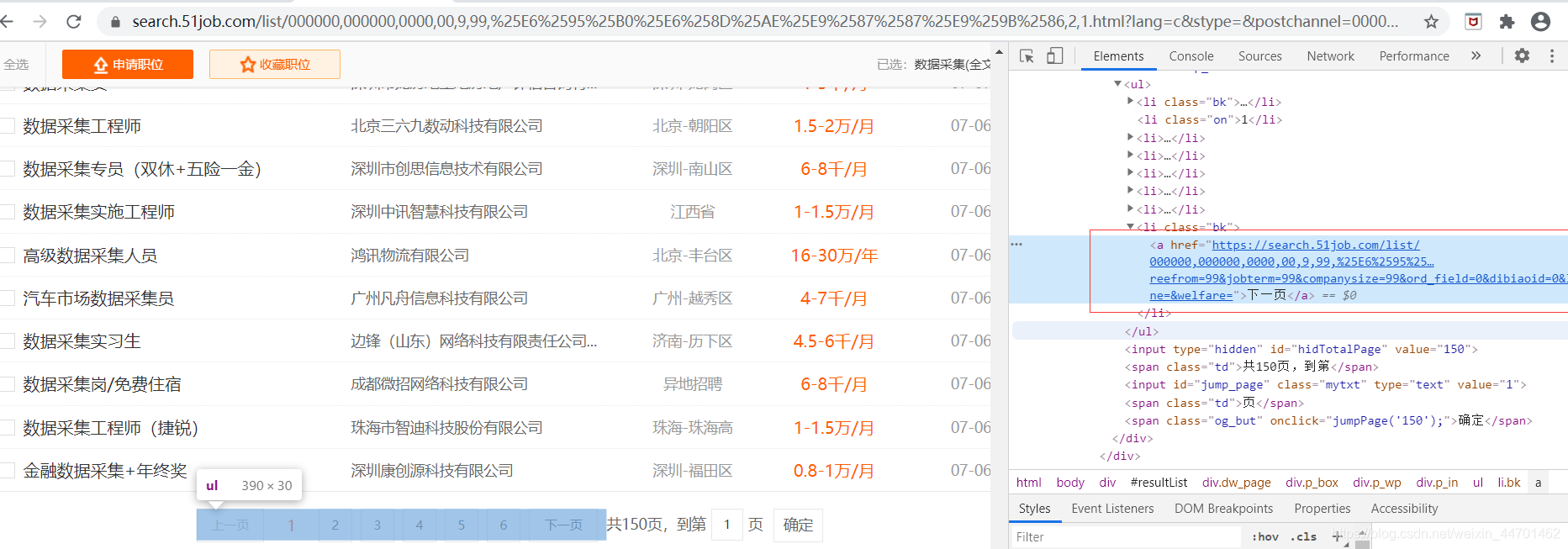
下一页的url:
spider代码如下:
# -*- coding: utf-8 -*-
import scrapy
from pawuyijob.items import PawuyijobItem
class WuyiSpider(scrapy.Spider):
name = 'wuyi'
allowed_domains = ['51job.com']
start_urls =['https://search.51job.com/list/000000,000000,0130%252C7501%252C7506%252C7502,01%252C32%252C38,9,99,%2520,2,1.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare=']
def parse(self, response):
#每条数据存放的xpath
node_list = response.xpath("//div[@id='resultList']/div[@class='el']")
# 整个for循环结束代表 当前这一页已经爬完了, 那么就该开始爬取下一页
for node in node_list:
item = PawuyijobItem()
# 职位名称
item["position_name"] = node.xpath("./p/span/a/@title").extract_first()
# 公司信息
item["company_name"] = node.xpath("./span[@class='t2']/a/@title").extract_first()
# 工作地点
item["work_place"] = node.xpath("./span[@class='t3']/text()").extract_first()
# 薪资情况
item["work_salary"] = node.xpath("./span[@class='t4']/text()").extract_first()
# 发布时间
item["release_date"] = node.xpath("./span[@class='t5']/text()").extract_first()
#详情页的url
detail_url = node.xpath("./p/span/a/@href").extract_first()
yield scrapy.Request(url=detail_url, callback=self.parse_detail, meta={
"item": item})
#下一页
next_url = response.xpath("//div[@class='p_in']//li[@class='bk'][2]/a/@href").extract_first()
#如果没有详情页的url我们就返回不再执行
if not next_url:
return
yield scrapy.Request(url=next_url, callback=self.parse)
def parse_detail(self, response):
item = response.meta["item"]
# 职位信息
item["job_require"] = response.xpath("//div[@class='bmsg job_msg inbox']/p/text()").extract()
# 联系方式
item智能推荐
TensorFlow 实现web人脸登录系统_tensorflow人脸注册-程序员宅基地
文章浏览阅读599次。作者git地址:https://github.com/chenlinzhong/face-login人脸检测MTCNN文件:fcce_detect.pymodel= os.path.abspath(face_comm.get_conf('mtcnn','model'))class Detect: def __init__(self): self.detector ..._tensorflow人脸注册
React高级特性之Context_react context-程序员宅基地
文章浏览阅读278次。Context提供了一种不需要手动地通过props来层层传递的方式来传递数据。_react context
三菱FX5U PLC与压力传感器485简单通讯_fx5u485通讯接线图-程序员宅基地
文章浏览阅读1.1w次。废话不多说,先上PLC与压力控制器485接线图对接线图不理解的可以留言.(1).压力控制器通电后设置参数,主要设置通讯参数第一:波特率,(此处我设置的是9600).第二设置通讯模式(此处设置的RTU模式)(2)5UPLC的参数设置如图上面通讯就完成了大家注意一点哦,这边是不需要你去算校验码的.如有问题,可留言探讨...._fx5u485通讯接线图
CentOS 7上部署Java项目开发环境_centos 7 部署java-程序员宅基地
文章浏览阅读857次。CentOS上部署Java项目开发环境CentOS上负责分发程序的yum命令。Ⅰ 安装软件的常用下载工具(1)yum的基本使用1)查看软件包列表(完整名称)yum list | grep [关键字]2)安装软件包 yum install [软件包完整名称]3)卸载软件包yum remove [软件包完整名称](2)wgetwget http://...hellp.zip -O down.zip(3) curlcurl 'http://...hellp.zip' -O down.zip_centos 7 部署java
LeetCode刷题笔记:Java实现选择排序_leetcode选择排序题目java-程序员宅基地
文章浏览阅读350次。选择排序_leetcode选择排序题目java
主动外观模型(AAM)_opencv 主动外观模型-程序员宅基地
文章浏览阅读3.2k次,点赞2次,收藏2次。历史AAM的思想最早可以追溯到1987年kass等人提出的snake方法,主要用于边界检定与图像分割。该方法用一条由n个控制点组成的连续闭合曲线作为snake模型,再用一个能量函数作为匹配度的评价函数,首先将模型设定在目标对象预估位置的周围,再通过不断迭代使能量函数最小化,当内外能量达到平衡时即得到目标对象的边界与特征。 1989年yuille等人此提出使用参数化的可变形模板来代替snak_opencv 主动外观模型
随便推点
【matlab】 与cell相关的转换函数_cellmat-程序员宅基地
文章浏览阅读1.1k次。**【matlab】 与cell相关的转换函数**1、cell2mat:将cell转换为mat的char型2、str2num:将mat从char转换为double型3、cellstr:将char转cell4、num2str:将double转char5、num2cell:将double直接转cell_cellmat
pyspider创建淘女郎图片爬虫任务--出师不利_pyspider 卡住任务创建-程序员宅基地
文章浏览阅读6.2k次。首先pyspider all启动pyspider的所有服务,然后访问http://localhost:5000创建一个爬虫任务:taonvlang,点开任务链接编辑http://localhost:5000/debug/taonvlang,默认模板:右侧为代码编辑区,可以在crawl_config里做一些配置,具体可以参考官网API文档:http://docs.pyspider.org/e_pyspider 卡住任务创建
python---运算规则_python中(:)的运算规则-程序员宅基地
文章浏览阅读78次。布尔"与" - 如果 x 为 False,x and y 返回 False,否则它返回 y 的计算值。(~a ) 输出结果 -61 ,二进制解释: 1100 0011,在一个有符号二进制数的补码形式。布尔"或" - 如果 x 是非 0,它返回 x 的值,否则它返回 y 的计算值。运算符:参与运算的两个值,如果两个相应位都为1,则该位的结果为1,否则为0。如果引用的不是同一个对象则返回结果 True,否则返回 False。如果在指定的序列中没有找到值返回 True,否则返回 False。_python中(:)的运算规则
记录刷题的日子2(2023.3.2)-程序员宅基地
文章浏览阅读39次。刷题记录,字符串
UE4在任意蓝图中可调用的C++函数:BlueprinFunctionLibrary_ue4 蓝图调用c++函数-程序员宅基地
文章浏览阅读4.2k次,点赞6次,收藏17次。如果蓝图是直接继承自一个C++类的,那么直接在这个C++类里面写入你需要的函数编译后就可以在蓝图里面调用了。下面讲的是一个全局的静态函数类,即不需要指定继承自某个C++类,这个全局类可以被当前工程下的所有蓝图类调用。首先新建一个c++类,选择显示所有类,在里面找到blueprintFunctionLibrary并创建一个新类:创建好之后打开VS文件,出现.h和.cpp文件。..._ue4 蓝图调用c++函数
有关linux中的文件IO的操作_服务器和客户端使用文件io操作-程序员宅基地
文章浏览阅读1.9k次。linux中一切皆文件,文件是linux系统的核心设计思想,所以掌握文件的操作是很重要的。_服务器和客户端使用文件io操作