Hadoop +Zookeeper 实现高可用_为什么用zookeeper做hadoop高可用-程序员宅基地
实验环境
IP 主机名
172.25.38.1 server1 Namenode
172.25.38.2 server2 Journalnode
172.25.38.3 server3 Journalnode
172.25.38.4 server4 Journalnode
172.25.38.5 server5 Namenode
1、搭建zookeeper集群
[root@server1 ~]# /etc/init.d/nfs start 开启服务
[root@server1 ~]# showmount -e
Export list for server1:
/home/hadoop *
[root@server1 ~]# su - hadoop
[hadoop@server1 ~]$
[hadoop@server1 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ rm -fr /tmp/*
[hadoop@server1 ~]$ ls
hadoop java zookeeper-3.4.9.tar.gz
hadoop-2.7.3 jdk1.7.0_79
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ tar zxf zookeeper-3.4.9.tar.gz 解压zookeeper包
2、配置server5作为高可用节点
[root@server5 ~]# yum install nfs-utils -y 安装服务
[root@server5 ~]# /etc/init.d/rpcbind start 开启服务 [ OK ]
[root@server5 ~]# /etc/init.d/nfs start 开启nfs服务
[root@server5 ~]# useradd -u 800 hadoop
[root@server5 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 挂载
[root@server5 ~]# df 查看挂载
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 929548 17232804 6% /
tmpfs 380140 0 380140 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server5 ~]# su - hadoop
[hadoop@server5 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 主机均已经同步
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz
[hadoop@server5 ~]$ rm -fr /tmp/*
3、配置从节点
[root@server2 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/ 挂载
[root@server2 ~]# df 查看挂载
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1860136 16302216 11% /
tmpfs 251120 0 251120 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server2 ~]# rm -fr /tmp/*
[root@server2 ~]# su - hadoop
[hadoop@server2 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
[hadoop@server2 zookeeper-3.4.9]$ cd conf/
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo_sample.cfg
4、添加从节点信息
[hadoop@server2 conf]$ cp zoo_sample.cfg zoo.cfg
[hadoop@server2 conf]$ vim zoo.cfg
[hadoop@server2 conf]$ cat zoo.cfg | tail -n 3
server.1=172.25.38.2:2888:3888
server.2=172.25.38.3:2888:3888
server.3=172.25.38.4:2888:3888
[hadoop@server2 conf]$ mkdir /tmp/zookeeper
[hadoop@server2 conf]$ cd /tmp/zookeeper/
[hadoop@server2 zookeeper]$ ls
[hadoop@server2 zookeeper]$ echo 1 > myid
[hadoop@server2 zookeeper]$ ls
myid
[hadoop@server2 zookeeper]$ cd
[hadoop@server2 ~]$ cd zookeeper-3.4.9/conf/
[hadoop@server2 conf]$ ls
configuration.xsl log4j.properties zoo.cfg zoo_sample.cfg
[hadoop@server2 conf]$ cd ..
[hadoop@server2 zookeeper-3.4.9]$ cd bin/
- 各节点配置文件相同,并且需要在/tmp/zookeeper 目录中创建 myid 文件,写入一个唯一的数字,取值范围在 1-255
[hadoop@server2 zookeeper-3.4.9]$ cd bin/
[hadoop@server2 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server2 bin]$ ./zkServer.sh start 开启服务
- 依次按照同样的方法配置其他节点
server3
[root@server3 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/
[root@server3 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1537052 16625300 9% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server3 ~]# rm -fr /tmp/*
[root@server3 ~]# su - hadoop
[hadoop@server3 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server3 ~]$ mkdir /tmp/zookeeper
[hadoop@server3 ~]$ cd /tmp/zookeeper/
[hadoop@server3 zookeeper]$ ls
[hadoop@server3 zookeeper]$ echo 2 > myid
[hadoop@server3 zookeeper]$ cd
[hadoop@server3 ~]$ cd zookeeper-3.4.9/bin/
[hadoop@server3 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server3 bin]$ ./zkServer.sh start
server4
[root@server4 ~]# mount 172.25.38.1:/home/hadoop/ /home/hadoop/
[root@server4 ~]# df
Filesystem 1K-blocks Used Available Use% Mounted on
/dev/mapper/VolGroup-lv_root 19134332 1350656 16811696 8% /
tmpfs 251124 0 251124 0% /dev/shm
/dev/vda1 495844 33478 436766 8% /boot
172.25.38.1:/home/hadoop/ 19134336 3289728 14872704 19% /home/hadoop
[root@server4 ~]# rm -fr /tmp/*
[root@server4 ~]# su - hadoop
[hadoop@server4 ~]$ mkdir /tmp/zookeeper
[hadoop@server4 ~]$ cd /tmp/zookeeper/
[hadoop@server4 zookeeper]$ ls
[hadoop@server4 zookeeper]$ echo 3 >myid
[hadoop@server4 zookeeper]$ ls
myid
[hadoop@server4 zookeeper]$ cd
[hadoop@server4 ~]$ cd zookeeper-3.4.9/bin/
[hadoop@server4 bin]$ ./zkServer.sh start
ZooKeeper JMX enabled by default
server2
[hadoop@server2 bin]$ ls
README.txt zkCli.cmd zkEnv.cmd zkServer.cmd zookeeper.out
zkCleanup.sh zkCli.sh zkEnv.sh zkServer.sh
[hadoop@server2 bin]$ pwd
/home/hadoop/zookeeper-3.4.9/bin
[hadoop@server2 bin]$ ./zkCli.sh 连接zookeeper
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper]
[zk: localhost:2181(CONNECTED) 1] ls /zookeeper
[quota]
[zk: localhost:2181(CONNECTED) 2] ls /zookeeper/quota
[]
[zk: localhost:2181(CONNECTED) 3] get /zookeeper/quota
cZxid = 0x0
ctime = Thu Jan 01 08:00:00 CST 1970
mZxid = 0x0
mtime = Thu Jan 01 08:00:00 CST 1970
pZxid = 0x0
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 0
numChildren = 0
5、hadoop的配置详解
core-site.xml
[hadoop@server1 ~]$ ls
hadoop java zookeeper-3.4.9
hadoop-2.7.3 jdk1.7.0_79 zookeeper-3.4.9.tar.gz
hadoop-2.7.3.tar.gz jdk-7u79-linux-x64.tar.gz
[hadoop@server1 ~]$ cd hadoop/etc/hadoop/
[hadoop@server1 hadoop]$ vim core-site.xml
<configuration>
指定 hdfs 的 namenode 为 masters (名称可自定义)
<property>
<name>fs.defaultFS</name>
<value>hdfs://masters</value>
</property>
<property>
指定 zookeeper 集群主机地址
<name>ha.zookeeper.quorum</name>
<value>172.25.38.2:2181,172.25.38.3:2181,172.25.38.4:2181</value>
</property>
</configuration>
hdfs-site.xml
[hadoop@server1 hadoop]$ vim hdfs-site.xml
[hadoop@server1 hadoop]$ cat hdfs-site.xml | tail -n 74
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
指定 hdfs 的 nameservices 为 masters,和 core-site.xml 文件中的设置保持一致
<name>dfs.nameservices</name>
<value>masters</value>
</property>
masters 下面有两个 namenode 节点,分别是 h1 和 h2
<property>
<name>dfs.ha.namenodes.masters</name>
<value>h1,h2</value>
</property>
指定 h1 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h1</name>
<value>172.25.38.1:9000</value>
</property>
指定 h1 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h1</name>
<value>172.25.38.1:50070</value>
</property>
指定 h2 节点的 rpc 通信地址
<property>
<name>dfs.namenode.rpc-address.masters.h2</name>
<value>172.25.38.5:9000</value>
</property>
指定 h2 节点的 http 通信地址
<property>
<name>dfs.namenode.http-address.masters.h2</name>
<value>172.25.38.5:50070</value>
</property>
指定 NameNode 元数据在 JournalNode 上的存放位置
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://172.25.38.2:8485;172.25.38.3:8485;172.25.38.4:8485/masters</value>
</property>
指定 JournalNode 在本地磁盘存放数据的位置
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/tmp/journaldata</value>
</property>
开启 NameNode 失败自动切换
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
配置失败自动切换实现方式
<property>
<name>dfs.client.failover.proxy.provider.masters</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
配置隔离机制方法,每个机制占用一行
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
使用 sshfence 隔离机制时需要 ssh 免密码
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
配置 sshfence 隔离机制超时时间
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop/etc/hadoop
[hadoop@server1 hadoop]$ vim slaves
[hadoop@server1 hadoop]$ cat slaves
172.25.38.2
172.25.38.3
172.25.38.4
- 在三个 DN 上依次启动 journalnode(第一次启动 hdfs 必须先启动 journalnode)
[hadoop@server2 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server2 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server2 hadoop]$ sbin/hadoop-daemon.sh start journalnode
starting journalnode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-journalnode-server2.out
[hadoop@server2 hadoop]$ jps
1459 JournalNode
1508 Jps
1274 QuorumPeerMain
- server3和server4重复以上操作
6、测试与server5的免密连接,传递配置文件搭建高可用
[hadoop@server1 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ bin/hdfs namenode -format
[hadoop@server1 hadoop]$ ssh server5
[hadoop@server5 ~]$ exit
logout
Connection to server5 closed.
[hadoop@server1 hadoop]$ ssh 172.25.38.5
Last login: Tue Aug 28 10:40:53 2018 from server1
[hadoop@server5 ~]$ exit
logout
Connection to 172.25.38.5 closed.
[hadoop@server1 hadoop]$ scp -r /tmp/hadoop-hadoop/ 172.25.38.5:/tmp/
fsimage_0000000000000000000 100% 353 0.3KB/s 00:00
VERSION 100% 202 0.2KB/s 00:00
seen_txid 100% 2 0.0KB/s 00:00
fsimage_0000000000000000000.md5 100% 62 0.1KB/s 00:00
格式化 zookeeper (只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server1 hadoop]$ bin/hdfs zkfc -formatZK
启动 hdfs 集群(只需在 h1 上执行即可)
[hadoop@server1 hadoop]$ sbin/start-dfs.sh 免密没有做好的话需要卡住的时候输入yes
server2
[hadoop@server2 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server2 ~]$ cd zookeeper-3.4.9
[hadoop@server2 zookeeper-3.4.9]$ ls
bin dist-maven LICENSE.txt src
build.xml docs NOTICE.txt zookeeper-3.4.9.jar
CHANGES.txt ivysettings.xml README_packaging.txt zookeeper-3.4.9.jar.asc
conf ivy.xml README.txt zookeeper-3.4.9.jar.md5
contrib lib recipes zookeeper-3.4.9.jar.sha1
[hadoop@server2 zookeeper-3.4.9]$ bin/zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[zookeeper, hadoop-ha]
[zk: localhost:2181(CONNECTED) 1] ls /hadoop-ha
[masters]
[zk: localhost:2181(CONNECTED) 2] ls
[zk: localhost:2181(CONNECTED) 3] ls /hadoop-ha/masters
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 4] ls /hadoop-ha/masters/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 4] ls /hadoop-ha/masters/ActiveBreadCrumb
[]
[zk: localhost:2181(CONNECTED) 5] get /hadoop-ha/masters/ActiveBreadCrumb
mastersh2server5 �F(�> 当前master为server5
cZxid = 0x10000000a
ctime = Tue Aug 28 10:46:47 CST 2018
mZxid = 0x10000000a
mtime = Tue Aug 28 10:46:47 CST 2018
pZxid = 0x10000000a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 28
numChildren = 0
7、在网页查看server1和server5的状态,一个为active,一个为standby
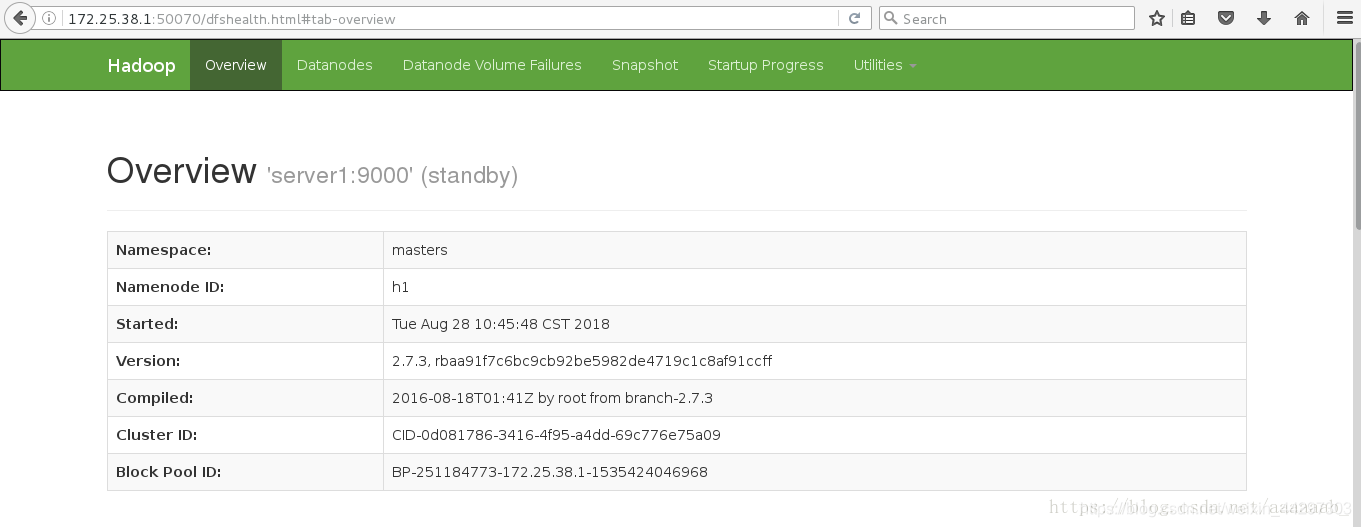
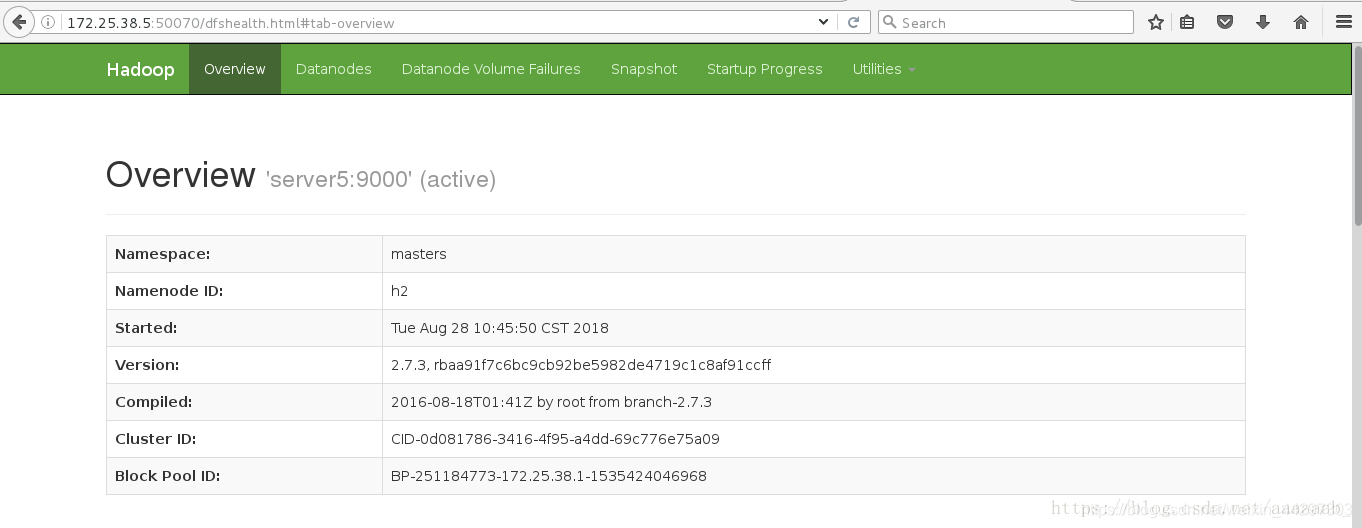
8、测试故障自动切换
[hadoop@server5 ~]$ ls
hadoop hadoop-2.7.3.tar.gz jdk1.7.0_79 zookeeper-3.4.9
hadoop-2.7.3 java jdk-7u79-linux-x64.tar.gz zookeeper-3.4.9.tar.gz
[hadoop@server5 ~]$ cd hadoop
[hadoop@server5 hadoop]$ ls
bigfile etc input libexec logs output sbin
bin include lib LICENSE.txt NOTICE.txt README.txt share
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user
[hadoop@server5 hadoop]$ bin/hdfs dfs -mkdir /user/hadoop
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
[hadoop@server5 hadoop]$ bin/hdfs dfs -put etc/hadoop/ input
[hadoop@server5 hadoop]$ bin/hdfs dfs -ls
Found 1 items
drwxr-xr-x - hadoop supergroup 0 2018-08-28 10:59 input
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
1382 NameNode
1945 Jps
[hadoop@server5 hadoop]$ kill -9 1382 直接结束进程
server2
[zk: localhost:2181(CONNECTED) 6] get /hadoop-ha/masters/ActiveBreadCrumb
mastersh1server1 �F(�> master已经变成了server1
cZxid = 0x10000000a
ctime = Tue Aug 28 10:46:47 CST 2018
mZxid = 0x10000000f
mtime = Tue Aug 28 11:00:22 CST 2018
pZxid = 0x10000000a
cversion = 0
dataVersion = 1
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 28
numChildren = 0
server5
[hadoop@server5 hadoop]$ pwd
/home/hadoop/hadoop
[hadoop@server5 hadoop]$ jps
1479 DFSZKFailoverController
1991 Jps
[hadoop@server5 hadoop]$ sbin/hadoop-daemon.sh start namenode 恢复节点
starting namenode, logging to /home/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-server5.out
[hadoop@server5 hadoop]$ jps 查看进程已经恢复
1479 DFSZKFailoverController
2020 NameNode
2100 Jps
智能推荐
Afaria MDM服务器enroll iPad失败 The SCEP server configuration is not supported_mdm不支持scep服务器配置-程序员宅基地
文章浏览阅读5.5k次。在注册Profile的时候失败,提示中文:不支持SCEP服务器配置英文:The SCEP server configuration is not supported用iTools工具连线查看iPad日志:Oct 16 07:41:35 iPad profiled[585] : (Note ) MC: Checking for MDM installation...Oct 16 07:41:35 i_mdm不支持scep服务器配置
PAT乙级——1009(字符串拆解)_pat乙字符串-程序员宅基地
文章浏览阅读445次。PAT乙级1009题目:说反话 (20 分)代码实现题目:说反话 (20 分)给定一句英语,要求你编写程序,将句中所有单词的顺序颠倒输出。输入格式:测试输入包含一个测试用例,在一行内给出总长度不超过 80 的字符串。字符串由若干单词和若干空格组成,其中单词是由英文字母(大小写有区分)组成的字符串,单词之间用 1 个空格分开,输入保证句子末尾没有多余的空格。输出格式:每个测试用例的输出占..._pat乙字符串
Android内嵌Unity混合开发 + Unity与Android通信 + Touch的坑_androidstudio嵌入unity-程序员宅基地
文章浏览阅读5.5k次,点赞3次,收藏26次。Android与Unity的混合开发_androidstudio嵌入unity
echarts学习笔记(1) ---- 使用模块化单文件引入_echarts 部分模块引入-程序员宅基地
文章浏览阅读2.1k次。这是笔者第一篇科技的博客文章,因为最近需要用到e_echarts 部分模块引入
基于ssm的校园驿站管理系统论文-程序员宅基地
文章浏览阅读869次,点赞17次,收藏18次。只有MySQL数据库,安装包小,安装速度快,操作简单,哪怕安装出问题也好解决,不用重装操作系统,也不影响电脑上运行的其他软件,消耗资源也少,最重要的是在功能方面完全的符合设计需要,所以最后选择了MySQL数据库作为应用软件开发需要的数据库。因为系统能够制作完成则是经历了很多阶段,正如文中所展示的那样,先有可行性分析,对功能的分析,对功能的设计,对数据库的设计,对程序功能的编码实现,对完成编码程序的测试等,这些环节缺一不可,而且还都需要认真对待,大学学到的所有知识在制作系统时,才会发现不够用。
基于Java+Springboot+Vue的响应式企业员工绩效考评系统设计和实现_员工绩效管理系统程序代码-程序员宅基地
文章浏览阅读1.7k次,点赞3次,收藏13次。此项目使用响应式开发技术进行PC和Phone之间自动适配。本网站最大的特点就功能全面,结构清晰、简单,将通过以普通员工身份、主管身份以及系统管理员身份模块,实现以下基本功能。普通员工公告板块:在公告板块中,用户可以添加公告内容,点击添加公告按钮,会以模态框的形式展示给用户输入的表单数据,用户输入相应的数据,便可以添加成功。然后可以对数据进行删除操作。同时,也可根据公告的发布时间进行搜索查询相对应的公告具体内容,从而进行后续操作。日志板块:在日志板块中,不仅可以查看日志的标题、具体内容以及创建时间,而且管_员工绩效管理系统程序代码
随便推点
java——java使用poi操作excel,java excel读写_outworkbook.write(outputfilestream)-程序员宅基地
文章浏览阅读2.2k次。maven依赖:<!-- https://mvnrepository.com/artifact/org.apache.poi/poi --> <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId>..._outworkbook.write(outputfilestream)
stm32CubeMX的FreeRtos基于103系列的电灯入门_stm32 freertos 点灯-程序员宅基地
文章浏览阅读294次。FreeRtos基于STM32CUBEMX的103系列电灯操作_stm32 freertos 点灯
Apache Oozie调度_oozie 面试题-程序员宅基地
文章浏览阅读232次。1.Oozie概述Oozie 是一个用来管理 Hadoop生态圈job的工作流调度系统。由Cloudera公司贡献给Apache。Oozie是运行于Java servlet容器上的一个java web应用。Oozie的目的是按照DAG(有向无环图)调度一系列的Map/Reduce或者Hive等任务。Oozie 工作流由hPDL(Hadoop Process Definition Language..._oozie 面试题
数据结构练习题之---链表_定义一个包含图书信息(书号、书名、价格)的链表,读入相应的图书数据来完成图书信-程序员宅基地
文章浏览阅读1.9k次,点赞7次,收藏26次。1、描述定义一个包含图书信息(书号、书名、价格)的链表,读入相应的图书数据来完成图书信息表的创建,然后统计图书表中的图书个数,同时逐行输出每本图书的信息。输入9787302257646 Data-Structure 35.009787302164340 Operating-System 50.009787302219972 Software-Engineer 32.009787302203513 Database-Principles 36.009787810827430 Discre_定义一个包含图书信息(书号、书名、价格)的链表,读入相应的图书数据来完成图书信
KT1025A蓝牙音频ble芯片功耗实测说明_蓝牙芯片功耗-程序员宅基地
文章浏览阅读1.7k次。KT1025A芯片功耗测试说明测试环境:BT201模块_蓝牙芯片功耗
DAC数模转换总结_数模转换里,a*500/255.0是什么-程序员宅基地
文章浏览阅读9.3k次,点赞3次,收藏11次。 数模转换就是将离散的数字量转换为连接变化的模拟量,实现该功能的电路或器件称为数模转换电路,通常称为D/A转换器或DAC(Digital Analog Converter)。 我们知道数分可为有权数和无权数,所谓有权数就是其每一位的数码有一个系数,如十进制数的45中的4表示为4×10,而5为5×1,即4的系数为10,而5的系数为1, 数模转换从某种意义上讲就是把二进制的数转换_数模转换里,a*500/255.0是什么