Guava Cache 原理分析与最佳实践-程序员宅基地
技术标签: cache guava # 《深入理解Java虚拟机》

前言
在大部分互联网架构中 Cache 已经成为了必可不少的一环。常用的方案有大家熟知的 NoSQL 数据库(Redis、Memcached),也有大量的进程内缓存比如 EhCache 、Guava Cache、Caffeine 等。
本讲主要针对本地 Cache 的老大哥 Guava Cache 进行介绍和分析,会选取本地缓存和分布式缓存(NoSQL)的优秀框架比较他们各自的优缺点、应用场景、项目中的最佳实践以及原理分析。
一、Guava Cache介绍
Guava Cache 是 google 开源的一款本地缓存工具库,它的设计灵感来源于ConcurrentHashMap,使用多个 segments 方式的细粒度锁,在保证线程安全的同时,支持高并发场景需求,同时支持多种类型的缓存清理策略,包括基于容量的清理、基于时间的清理、基于引用的清理等。
传统的JVM 缓存,是堆缓存,其实就是创建一些全局容器,比如:List、Set、Map等。这些容器用来做数据存储还可以,却不能按照一定的规则淘汰数据,如 LRU,LFU,FIFO 等,也没有清除数据时的回调通知,而且多线程不安全。虽然针对高并发可以使用CurrentHashMap,但是过期处理和数据刷新都需要手动完成。
相比较而言,同样是基于 JVM 缓存的 Guava Cache 就显得优势明显,且很有必要:
1. 缓存过期和淘汰机制
在Guava Cache中可以设置Key的过期时间,包括访问过期和创建过期Guava Cache在缓存容量达到指定大小时,采用LRU的方式,将不常使用的键值从Cache中删除;
2. 并发处理能力
Guava Cache类似CurrentHashMap,是线程安全的。它提供了设置并发级别的API,使得缓存支持并发的写入和读取;
像ConcurrentHashMap结构类似,GuavaCache也使用Segment做分区,采用分离锁机制,分离锁能够减小锁力度,提升并发能力分离锁是分拆锁定,把一个集合看分成若干partition, 每个partiton一把锁。ConcurrentHashMap就是分了16个区域,这16个区域之间是可以并发的。
3. 更新锁定
一般情况下,在缓存中查询某个key,如果不存在,则查源数据,并回填缓存。在高并发下会出现,多次查源并重复回填缓存,可能会造成源的宕机(DB),性能下降 Guava Cache 可以在 CacheLoader 的load方法中加以控制,对同一个key,只让一个请求去读源并回填缓存,其他请求阻塞等待。
4. 集成数据源
一般我们在业务中操作缓存,都会操作缓存和数据源两部分。Guava Cache 的 get 可以集成数据源,在从缓存中读取不到时,可以从数据源中读取数据并回填缓存。
5. 监控缓存加载/命中情况
既然是缓存服务,那统计数据的功能自然也是少不了。
二、基本用法
Guava Cache 的 maven 依赖:
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>21.0</version>
</dependency>2.1 构建Cache对象
Guava Cache 通过简单好用的 Client 可以快速构造出符合需求的 Cache 对象,不需要过多复杂的配置,大多数情况就像构造一个 POJO 一样的简单。
这里介绍两种构造 Cache 对象的方式:CacheLoader 和 Callable。
2.1.1 CacheLoader
构造 LoadingCache 的关键在于实现 load 方法,也就是在需要访问的缓存项不存在的时候 Cache 会自动调用 load 方法将数据加载到 Cache 中。这里你肯定会想假如有多个线程过来访问这个不存在的缓存项怎么办,也就是缓存的并发问题如何怎么处理是否需要人工介入,这些在下文中也会介绍到。
除了实现 load 方法之外还可以配置缓存相关的一些性质,比如:过期加载策略、刷新策略 。
private static final LoadingCache<String, String> CACHE = CacheBuilder
.newBuilder()
// 最大容量为 100 超过容量有对应的淘汰机制,下文详述
.maximumSize(100)
// 缓存项写入后多久过期,下文详述
.expireAfterWrite(60 * 5, TimeUnit.SECONDS)
// 缓存写入后多久自动刷新一次,下文详述
.refreshAfterWrite(60, TimeUnit.SECONDS)
// 创建一个 CacheLoader,load 表示缓存不存在的时候加载到缓存并返回
.build(new CacheLoader<String, String>() {
// 加载缓存数据的方法
@Override
public String load(String key) {
return "cache [" + key + "]";
}
});
public void getTest() throws Exception {
CACHE.get("KEY_25487");
}2.1.2 Callable
除了在构造 Cache 对象的时候指定 load 方法来加载缓存外,我们亦可以在获取缓存项时指定载入缓存的方法,并且可以根据使用场景在不同的位置采用不同的加载方式。
比如,在某些位置可以通过二级缓存加载不存在的缓存项,而有些位置则可以直接从 DB 加载缓存项。
// 注意返回值是 Cache
private static final Cache<String, String> SIMPLE_CACHE = CacheBuilder
.newBuilder()
.build();
public void getTest1() throws Exception {
String key = "KEY_25487";
// get 缓存项的时候指定 callable 加载缓存项
SIMPLE_CACHE.get(key, () -> "cache [" + key + "]");
}2.1.3 CacheLoader和Callable的区别
CacheLoader 和 Callable 都实现了一种逻辑:先取缓存,如果取不到相关key对应的内容,再执行 load 或者 call 方法中自己实现的逻辑来获取相关数据并缓存起来,不同点是:
- CacheLoader 是按 key 统一加载,所有取不到的统一执行一种 load 逻辑;
- Callable 方法允许在 get 的时候指定 key,传入一个Callable实例并实现加载逻辑。
2.2 CacheBuilder参数介绍
CacheBuilder是一个用于构建Cache的类,是建造者模式的一个例子,主要的方法有:
- maximumSize(long maximumSize):设置缓存存储的所有元素的最大个数。(慎重设置)
- maximumWeight(long maximumWeight):设置缓存存储的所有元素的最大权重。
- expireAfterAccess(long duration, TimeUnit unit):设置元素在最后一次访问多久后过期。
- expireAfterWrite(long duration, TimeUnit unit):设置元素在写入缓存后多久过期。
- concurrencyLevel(int concurrencyLevel):设置并发水平,即允许多少线程无冲突的访问Cache,默认值是4,该值越大,LocalCache中的segment数组也会越大,访问效率越高,当然空间占用也大一些。
- removalListener(RemovalListener<? super K1, ? super V1> listener):设置元素删除通知器,在任意元素无论何种原因被删除时会调用该通知器。
- setKeyStrength(Strength strength):设置元素的key是强引用,还是弱引用,默认强引用,并且该属性也指定了EntryFactory使用是强引用还是弱引用。
- setValueStrength(Strength strength):设置元素的value是强引用,还是弱引用,默认强引用。
2.3 get和put
Cache的存放数据的方法只有一种,和map一样:put(K,V);拿取的方法有三种,区别如下:
- get(K):使用这个方法要么返回已经缓存的值,要么使用CacheLoader向缓存原子地加载新值。由于CacheLoader可能抛出异常,LoadingCache.get(K)也声明为抛出ExecutionException异常。如果你定义的CacheLoader没有声明任何检查型异常,则可以通过 getUnchecked(K) 查找缓存;但必须注意,一旦CacheLoader声明了检查型异常,就不可以调用getUnchecked(K)。
- getIfPresent(key):从现有的缓存中获取,如果缓存中有key,则返回value,如果没有则返回null,不加载load()方法;
- getAll(Iterable<? extends K>):用来执行批量查询。默认情况下,对每个不在缓存中的键,getAll方法会单独调用CacheLoader.load来加载缓存项。可以通过重写 load()方法来提高加载缓存的效率;
2.4 自动加载
Cache的get方法有两个参数,第一个参数是要从Cache中获取记录的key,第二个记录是一个Callable对象。
当缓存中已经存在key对应的记录时,get方法直接返回key对应的记录。如果缓存中不包含key对应的记录,Guava会启动一个线程执行Callable对象中的call方法,call方法的返回值会作为key对应的值被存储到缓存中,并且被get方法返回。
Guava可以保证当有多个线程同时访问Cache中的一个key时,如果key对应的记录不存在,Guava只会启动一个线程执行get方法中Callable参数对应的任务加载数据存到缓存。当加载完数据后,任何线程中的get方法都会获取到key对应的值。
String value = cache.get("key", new Callable<String>() {
public String call() throws Exception {
// 在这里写从DB获取数据的方法并返回
// 模拟加载时间
Thread.sleep(1000);
return "auto load by Callable";
}
});2.5 缓存回收策略
不管是磁盘也好,内存也罢,我们的空间都不是无限的。所以,我们必须决定:什么时候某个缓存项就不值得保留了。
Guava Cache提供了三种基本的缓存回收方式:基于容量回收、定时回收和基于引用回收。
2.5.1 基于容量的回收
如果要规定缓存项的数目不超过固定值,只需使用CacheBuilder.maximumSize(long)。缓存将尝试回收最近没有使用或总体上很少使用的缓存项。
警告:在缓存项的数目达到限定值之前,缓存就可能进行回收操作,通常来说,这种情况发生在缓存项的数目逼近限定值时。
Cache<String,String> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.build();
cache.put("key1","value1");
cache.put("key2","value2");
System.out.println("第一个值:" + cache.getIfPresent("key1"));
System.out.println("第二个值:" + cache.getIfPresent("key2"));
cache.put("key3","value3");
System.out.println("第一个值:" + cache.getIfPresent("key1"));
System.out.println("第二个值:" + cache.getIfPresent("key2"));
System.out.println("第三个值:" + cache.getIfPresent("key3"));
结果:
第一个值:value1
第二个值:value2
第一个值:null
第二个值:value2
第三个值:value32.5.2 定时回收
CacheBuilder提供两种定时回收的方法:
- expireAfterAccess(long, TimeUnit):缓存项在给定时间内没有被读/写访问,则回收。请注意这种缓存的回收顺序和基于大小回收一样。
- expireAfterWrite(long, TimeUnit):缓存项在给定时间内没有被写操作(创建或覆盖),则回收。如果认为缓存数据总是在固定时候后变得陈旧不可用,这种回收方式是可取的。
定时回收在周期性地在写操作中执行,偶尔在读操作中执行。
2.5.3 基于引用的回收
通过weakKeys和weakValues方法指定Cache只保存对缓存记录key和value的弱引用。这样当没有其他强引用指向key和value时,key和value对象就会被垃圾回收器回收。
- CacheBuilder.weakKeys():使用弱引用存储键。当键没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用键的缓存用==而不是equals比较键。
- CacheBuilder.weakValues():使用弱引用存储值。当值没有其它(强或软)引用时,缓存项可以被垃圾回收。因为垃圾回收仅依赖恒等式(==),使用弱引用值的缓存用==而不是equals比较值。
- CacheBuilder.softValues():使用软引用存储值。软引用只有在响应内存需要时,才按照全局最近最少使用的顺序回收。考虑到使用软引用的性能影响,我们通常建议使用更有性能预测性的缓存大小限定(见上文,基于容量回收)。使用软引用值的缓存同样用==而不是equals比较值。
Cache<String,Object> cache = CacheBuilder.newBuilder()
.maximumSize(2)
.weakValues()
.build();2.6 主动清除
可以调用Cache的 invalidate 或 invalidateAll 方法显示删除Cache中的记录。
- invalidate方法:一次只能删除Cache中一个记录,接收的参数是要删除记录的key。
- invalidateAll方法:可以批量删除Cache中的记录,当没有传任何参数时,invalidateAll方法将清除Cache中的全部记录。invalidateAll也可以接收一个Iterable类型的参数,参数中包含要删除记录的所有key值。
Cache<String,String> cache = CacheBuilder.newBuilder().build();
Object value = new Object();
cache.put("key1","value1");
cache.put("key2","value2");
cache.put("key3","value3");
// 1.清除指定的key
cache.invalidate("key1");
// 2.批量清除list中全部key对应的记录
List<String> list = new ArrayList<String>();
list.add("key1");
list.add("key2");
cache.invalidateAll(list);2.7 移除动作监听器
可以为Cache对象添加一个移除监听器,这样当有记录被删除时可以感知到这个事件。
RemovalListener<String, String> listener = new RemovalListener<String, String>() {
public void onRemoval(RemovalNotification<String, String> notification) {
System.out.println("[" + notification.getKey() + ":" + notification.getValue() + "] is removed!");
}
};
Cache<String,String> cache = CacheBuilder.newBuilder()
.maximumSize(3)
.removalListener(listener)
.build();2.8 统计信息
可以对Cache的命中率、加载数据时间等信息进行统计。在构建Cache对象时,可以通过CacheBuilder的recordStats方法开启统计信息的开关。开关开启后Cache会自动对缓存的各种操作进行统计,调用Cache的stats方法可以查看统计后的信息。
Cache<String,String> cache = CacheBuilder.newBuilder()
.maximumSize(3)
.recordStats() //开启统计信息开关
.build();
System.out.println(cache.stats()); //获取统计信息三、缓存项加载机制
如果某个缓存过期了或者缓存项不存在于缓存中,而恰巧此此时有大量请求过来请求这个缓存项,如果没有保护机制就会导致大量的线程同时请求数据源加载数据并生成缓存项,就算某一个线程率先获取到数据生成了缓存项,其他的线程还是继续请求 DB 而不会走到缓存,这就是所谓的 “缓存击穿” 。
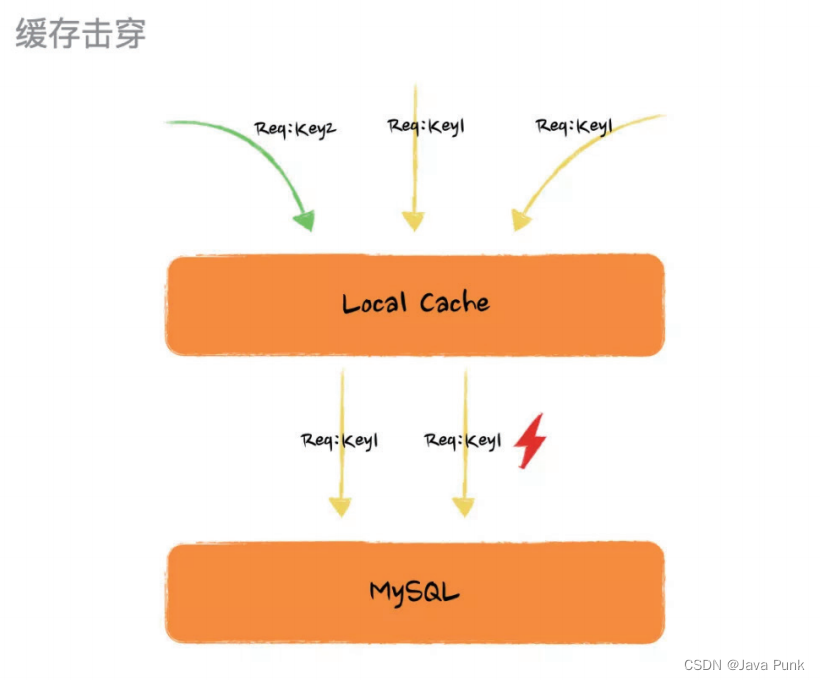
看到上面这个图或许你已经有方法解这个问题了,如果多个线程过来如果我们只让一个线程去加载数据生成缓存项,其他线程等待然后读取生成好的缓存项岂不是就完美解决。那么恭喜你在这个问题上,和 Google 工程师的思路是一致的。不过采用这个方案,解决了缓存击穿,却又会引入线程阻塞的新问题。
其实, Guava Cache 在 load 的时候做了并发控制,在多个线程请求一个不存在或者过期的缓存项时保证只有一个线程进入 load 方法,其他线程等待直到缓存项被生成,这样就避免了大量的线程击穿缓存直达 DB 。
不过,试想下如果有上万 QPS 同时过来会有大量的线程阻塞导致线程无法释放,甚至会出现线程池满的尴尬场景,这也是说为什么这个方案解了 “缓存击穿” 问题但又没完全解。
上述机制其实就是 expireAfterWrite / expireAfterAccess 来控制的,如果你配置了过期策略,对应的缓存项在过期后被访问就会走上述流程来加载缓存项。
四、缓存项刷新机制
缓存项的刷新和加载看起来是相似的,都是让缓存数据处于最新的状态。区别在于:
- 缓存项加载是一个被动的过程,而缓存刷新是一个主动触发动作。如果缓存项不存在或者过期只有下次 get 的时候才会触发新值加载。而缓存刷新则更加主动替换缓存中的老值。
- 另外一个很重要点的在于,缓存刷新的项目一定是存在缓存中的,他是对老值的替换而非是对 NULL 值的替换。
由于缓存项刷新的前提是该缓存项存在于缓存中,那么缓存的刷新就不用像缓存加载的流程一样让其他线程等待而是允许一个线程去数据源获取数据,其他线程都先返回老值直到异步线程生成了新缓存项。
这个方案完美解决了上述遇到的 “缓存击穿” 问题,不过他的前提是已经生成缓存项了。在实际生产情况下我们可以做 缓存预热 ,提前生成缓存项,避免流量洪峰造成的线程堆积。
这套机制在 Guava Cache 中是通过 refreshAfterWrite 实现的,在配置刷新策略后,对应的缓存项会按照设定的时间定时刷新,避免线程阻塞的同时保证缓存项处于最新状态。
但他也不是完美的,比如他的限制是缓存项已经生成,并且如果恰巧你运气不好,大量的缓存项同时需要刷新或者过期, 就会有大量的线程请求 DB,这就是常说的 “缓存血崩”。
五、缓存项异步刷新机制
上面说到缓存项大面积失效或者刷新会导致雪崩,那么就只能限制访问 DB 的数量了,位置有三个地方:
- 源头:因为加载缓存的线程就是前台请求线程,所以如果控制请求线程数量的确是减少大面积失效对 DB的请求,那这样一来就不存在高并发请求,就算不用缓存都可以。
- 中间层缓冲:因为请求线程和访问 DB 的线程是同一个,假如在中间加一层缓冲,通过一个后台线程池去异步刷新缓存所有请求线程直接返回老值,这样对于 DB 的访问的流量就可以被后台线程池的池大小控住。
- 底层:直接控 DB 连接池的池大小,这样访问 DB 的连接数自然就少了,但是如果大量请求到连接池发现获取不到连接程序一样会出现连接池满的问题,会有大量连接被拒绝的异常。
所以,比较合适的方式是通过添加一个异步线程池异步刷新数据,在 Guava Cache 中实现方案是重写 Cache Loader 的 reload 方法。
private static final LoadingCache<String, String> ASYNC_CACHE = CacheBuilder.newBuilder()
.build(
CacheLoader.asyncReloading(new CacheLoader<String, String>() {
@Override
public String load(String key) {
return key;
}
@Override
public ListenableFuture<String> reload(String key, String oldValue) throws Exception {
return super.reload(key, oldValue);
}
}, new ThreadPoolExecutor(5, Integer.MAX_VALUE,
60L, TimeUnit.SECONDS,
new SynchronousQueue<>()))
);六、LocalCache 源码分析
先整体看下 Cache 的类结构,下面的这些子类表示了不同的创建方式本质还都是 LocalCache。

核心代码都在 LocalCache 这个文件中,并且通过这个继承关系可以看出 Guava Cache 的本质就是 ConcurrentMap。

在看源码之前先理一下流程,先理清思路,源码太多就不一一粘贴了。这里核心理一下 Get 的流程,put 阶段比较简单就不做分析了。

总结
Guava Cache 没有额外的线程去做数据清理和刷新的,基本都是通过 Get 方法来触发这些动作,减少了设计的复杂性和降低了系统开销。
回顾下 Get 的流程以及在每个阶段做的事情,返回的值。首先判断缓存是否过期然后判断是否需要刷新,如果过期了就调用 loading 去同步加载数据(其他线程阻塞),如果是仅仅需要刷新调用 reloading 异步加载(其他线程返回老值)。
注意,如果 refreshTime > expireTime 意味着永远走不到缓存刷新逻辑,缓存刷新是为了在缓存有效期内尽量保证缓存数据一致性,所以,在配置刷新策略和过期策略时一定保证 refreshTime < expireTime 。
最后关于 Guava Cache 的使用建议 (最佳实践) :
- 如果刷新时间配置的较短一定要重载 reload 异步加载数据的方法,传入一个自定义线程池保护 DB;
- 失效时间一定要大于刷新时间;
- 如果是常驻内存的一些少量数据,失效时间可以配置的较长,刷新时间配置短一点 (根据业务对缓存失效容忍度)。
智能推荐
class和struct的区别-程序员宅基地
文章浏览阅读101次。4.class可以有⽆参的构造函数,struct不可以,必须是有参的构造函数,⽽且在有参的构造函数必须初始。2.Struct适⽤于作为经常使⽤的⼀些数据组合成的新类型,表示诸如点、矩形等主要⽤来存储数据的轻量。1.Class⽐较适合⼤的和复杂的数据,表现抽象和多级别的对象层次时。2.class允许继承、被继承,struct不允许,只能继承接⼝。3.Struct有性能优势,Class有⾯向对象的扩展优势。3.class可以初始化变量,struct不可以。1.class是引⽤类型,struct是值类型。
android使用json后闪退,应用闪退问题:从json信息的解析开始就会闪退-程序员宅基地
文章浏览阅读586次。想实现的功能是点击顶部按钮之后按关键字进行搜索,已经可以从服务器收到反馈的json信息,但从json信息的解析开始就会闪退,加载listview也不知道行不行public abstract class loadlistview{public ListView plv;public String js;public int listlength;public int listvisit;public..._rton转json为什么会闪退
如何使用wordnet词典,得到英文句子的同义句_get_synonyms wordnet-程序员宅基地
文章浏览阅读219次。如何使用wordnet词典,得到英文句子的同义句_get_synonyms wordnet
系统项目报表导出功能开发_积木报表 多线程-程序员宅基地
文章浏览阅读521次。系统项目报表导出 导出任务队列表 + 定时扫描 + 多线程_积木报表 多线程
ajax 如何从服务器上获取数据?_ajax 获取http数据-程序员宅基地
文章浏览阅读1.1k次,点赞9次,收藏9次。使用AJAX技术的好处之一是它能够提供更好的用户体验,因为它允许在不重新加载整个页面的情况下更新网页的某一部分。另外,AJAX还使得开发人员能够创建更复杂、更动态的Web应用程序,因为它们可以在后台与服务器进行通信,而不需要打断用户的浏览体验。在Web开发中,AJAX(Asynchronous JavaScript and XML)是一种常用的技术,用于在不重新加载整个页面的情况下,从服务器获取数据并更新网页的某一部分。使用AJAX,你可以创建异步请求,从而提供更快的响应和更好的用户体验。_ajax 获取http数据
Linux图形终端与字符终端-程序员宅基地
文章浏览阅读2.8k次。登录退出、修改密码、关机重启_字符终端
随便推点
Python与Arduino绘制超声波雷达扫描_超声波扫描建模 python库-程序员宅基地
文章浏览阅读3.8k次,点赞3次,收藏51次。前段时间看到一位发烧友制作的超声波雷达扫描神器,用到了Arduino和Processing,可惜啊,我不会Processing更看不懂人家的程序,咋办呢?嘿嘿,所以我就换了个思路解决,因为我会一点Python啊,那就动手吧!在做这个案例之前先要搞明白一个问题:怎么将Arduino通过超声波检测到的距离反馈到Python端?这个嘛,我首先想到了串行通信接口。没错!就是串口。只要Arduino将数据发送给COM口,然后Python能从COM口读取到这个数据就可以啦!我先写了一个测试程序试了一下,OK!搞定_超声波扫描建模 python库
凯撒加密方法介绍及实例说明-程序员宅基地
文章浏览阅读4.2k次。端—端加密指信息由发送端自动加密,并且由TCP/IP进行数据包封装,然后作为不可阅读和不可识别的数据穿过互联网,当这些信息到达目的地,将被自动重组、解密,而成为可读的数据。不可逆加密算法的特征是加密过程中不需要使用密钥,输入明文后由系统直接经过加密算法处理成密文,这种加密后的数据是无法被解密的,只有重新输入明文,并再次经过同样不可逆的加密算法处理,得到相同的加密密文并被系统重新识别后,才能真正解密。2.使用时,加密者查找明文字母表中需要加密的消息中的每一个字母所在位置,并且写下密文字母表中对应的字母。_凯撒加密
工控协议--cip--协议解析基本记录_cip协议embedded_service_error-程序员宅基地
文章浏览阅读5.7k次。CIP报文解析常用到的几个字段:普通类型服务类型:[0x00], CIP对象:[0x02 Message Router], ioi segments:[XX]PCCC(带cmd和func)服务类型:[0x00], CIP对象:[0x02 Message Router], cmd:[0x101], fnc:[0x101]..._cip协议embedded_service_error
如何在vs2019及以后版本(如vs2022)上添加 添加ActiveX控件中的MFC类_vs添加mfc库-程序员宅基地
文章浏览阅读2.4k次,点赞9次,收藏13次。有时候我们在MFC项目开发过程中,需要用到一些微软已经提供的功能,如VC++使用EXCEL功能,这时候我们就能直接通过VS2019到如EXCEL.EXE方式,生成对应的OLE头文件,然后直接使用功能,那么,我们上篇文章中介绍了vs2017及以前的版本如何来添加。但由于微软某些方面考虑,这种方式已被放弃。从上图中可以看出,这一功能,在从vs2017版本15.9开始,后续版本已经删除了此功能。那么我们如果仍需要此功能,我们如何在新版本中添加呢。_vs添加mfc库
frame_size (1536) was not respected for a non-last frame_frame_size (1024) was not respected for a non-last-程序员宅基地
文章浏览阅读785次。用ac3编码,执行编码函数时报错入如下:[ac3 @ 0x7fed7800f200] frame_size (1536) was not respected for anon-last frame (avcodec_encode_audio2)用ac3编码时每次送入编码器的音频采样数应该是1536个采样,不然就会报上述错误。这个数字并非刻意固定,而是跟ac3内部的编码算法原理相关。全网找不到,国内音视频之路还有很长的路,音视频人一起加油吧~......_frame_size (1024) was not respected for a non-last frame
Android移动应用开发入门_在安卓移动应用开发中要在活动类文件中声迷你一个复选框变量-程序员宅基地
文章浏览阅读230次,点赞2次,收藏2次。创建Android应用程序一个项目里面可以有很多模块,而每一个模块就对应了一个应用程序。项目结构介绍_在安卓移动应用开发中要在活动类文件中声迷你一个复选框变量