机器学习初级算法梳理(二)_假设有 n 个样本 (1) , (2) ,… , ( )服从正态分布n(μ, -程序员宅基地
逻辑回归与线性回归的联系与区别
1.联系: 逻辑回归与线性回归都属于广义线性回归模型。
2.区别:
1)线性回归要求变量服从正态分布,logistic回归对变量分布没有要求。
2)线性回归要求因变量是连续性数值变量,而logistic回归要求因变量是分类型变量。
3)线性回归要求自变量和因变量呈线性关系,而logistic回归不要求自变量和因变量呈线性关系。
4)logistic回归是分析因变量取某个值的概率与自变量的关系,而线性回归是直接分析因变量与自变量的关系。
逻辑回归的原理
逻辑回归也被称为对数几率回归,算法名虽然叫做逻辑回归,但是该算法是分类算法,个人认为这是因为逻辑回归用了和回归类似的方法来解决了分类问题。逻辑回归模型是一种分类模型,用条件概率分布的形式表示 P(Y|X)P(Y|X),这里随机变量 X 取值为 n 维实数向量,例如x=(x(1),x(2),…,x(n))x=(x(1),x(2),…,x(n)),Y 取值为 0 或 1。即:
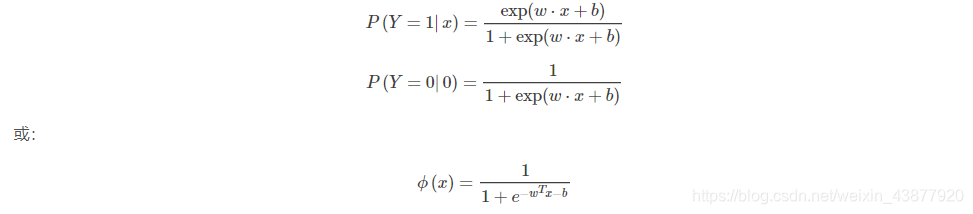
假设有一个二分类问题,输出为y∈{0,1}y∈{0,1},二线性回归模型z=wTx+bz=wTx+b是个实数值,我们希望有一个理想的阶跃函数来帮我什么实现z值到0/1值的转化,于是找到了Sigmoid函数来代替:
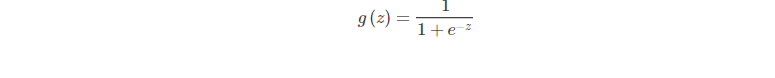
逻辑回归损失函数推导及优化
逻辑回归的公式为:
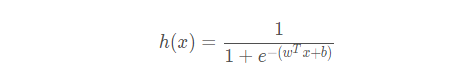
假设有N个样本,样本的标签只有0和1两类,可以用极大似然估计法估计模型参数,从而得到逻辑回归模型
设yi=1的概率为pi,yi=0的概率为1 - pi,那么观测的概率为:
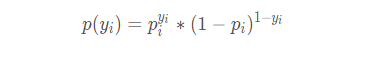
可以看到这个公式很巧妙的将0和1两种情况都包括进去,数学真是美妙的东西
概率由逻辑回归的公式求解,那么带进去得到极大似然函数:
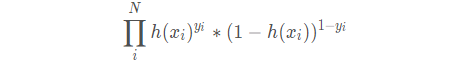
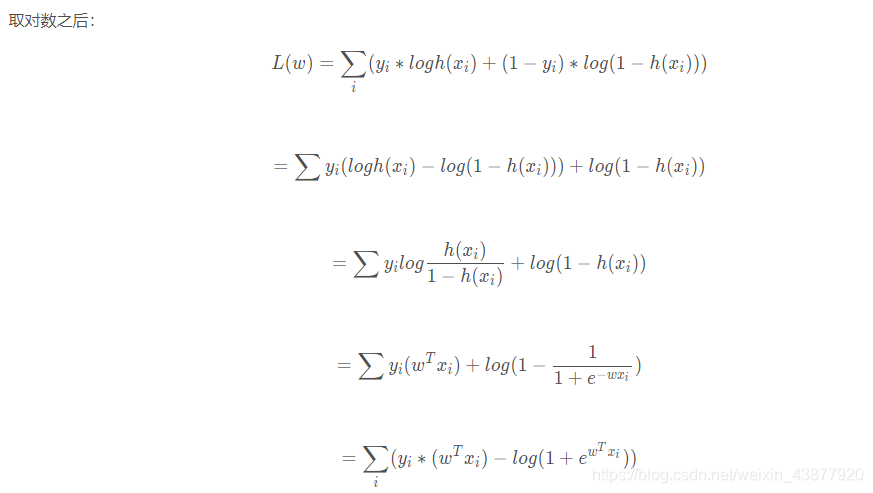
上面这个式子的计算过程还用到了对数的一些相关的性质,对L(w)求极大值,得到w的估计值
其实实际操作中会加个负号,变成最小化问题,通常会采用随机梯度下降法和拟牛顿迭代法来求解
梯度

正则化与模型评估指标
在训练数据不够多时,或者over training时,常常会导致过拟合(overfitting)。正则化方法即为在此时向原始模型引入额外信息,以便防止过拟合和提高模型泛化性能的一类方法的统称。在实际的深度学习场景中我们几乎总是会发现,最好的拟合模型(从最小化泛化误差的意义上)是一个适当正则化的大型模型。
评价指标是机器学习任务中非常重要的一环。不同的机器学习任务有着不同的评价指标,同时同一种机器学习任务也有着不同的评价指标,每个指标的着重点不一样。如分类(classification)、回归(regression)、排序(ranking)、聚类(clustering)、热门主题模型(topic modeling)、推荐(recommendation)等。并且很多指标可以对多种不同的机器学习模型进行评价,如精确率-召回率(precision-recall),可以用在分类、推荐、排序等中。像分类、回归、排序都是监督式机器学习。
常用监督式机器学习评估指标:
分类评价指标
分类评价指标
准确率(Accuracy)
平均准确率(Average Per-class Accuracy)
对数损失函数(Log-loss)
精确率-召回率(Precision-Recall)
F1-score
AUC(Area under the Curve(Receiver Operating Characteristic, ROC))
混淆矩阵(Confusion Matrix)
回归评价指标
排序评价指标
逻辑回归的优缺点
优点:
1)预测结果是界于0和1之间的概率;
2)可以适用于连续性和类别性自变量;
3)容易使用和解释;
缺点:
1)对模型中自变量多重共线性较为敏感,例如两个高度相关自变量同时放入模型,可能导致较弱的一个自变量回归符号不符合预期,符号被扭转。需要利用因子分析或者变量聚类分析等手段来选择代表性的自变量,以减少候选变量之间的相关性;
2)预测结果呈“S”型,因此从log(odds)向概率转化的过程是非线性的,在两端随着log(odds)值的变化,概率变化很小,边际值太小,slope太小,而中间概率的变化很大,很敏感。 导致很多区间的变量变化对目标概率的影响没有区分度,无法确定阀值。
样本不均衡问题解决办法
1,扩充数据集
首先想到能否获得更多数据,尤其是小类(该类样本数据极少)的数据,更多的数据往往能得到更多的分布信息。
2,对数据集进行重采样
过采样(over-sampling),对小类的数据样本进行过采样来增加小类的数据样本个数,即采样的个数大于该类样本的个数。
欠采样(under-sampling),对大类的数据样本进行欠采样来减少大类的数据样本个数,即采样的个数少于该类样本的个数。
采样算法容易实现,效果也不错,但可能增大模型的偏差(Bias),因为放大或者缩小某些样本的影响相当于改变了原数据集的分布。对不同的类别也要采取不同的采样比例,但一般不会是1:1,因为与现实情况相差甚远,压缩大类的数据是个不错的选择。
3,人造数据
一种简单的产生人造数据的方法是:在该类下所有样本的每个属性特征的取值空间中随机选取一个组成新的样本,即属性值随机采样。此方法多用于小类中的样本,不过它可能破坏原属性的线性关系。如在图像中,对一幅图像进行扭曲得到另一幅图像,即改变了原图像的某些特征值,但是该方法可能会产生现实中不存在的样本。
有一种人造数据的方法叫做SMOTE(Synthetic Minority Over-sampling Technique)。SMOTE是一种过采样算法,它构造新的小类样本而不是产生小类中已有的样本的副本。它基于距离度量选择小类别下两个或者更多的相似样本,然后选择其中一个样本,并随机选择一定数量的邻居样本对选择的那个样本的一个属性增加噪声,每次处理一个属性。这样就构造了许多新数据。
SMOTE算法的多个不同语言的实现版本:
•Python: UnbalancedDataset模块提供了SMOTE算法的多种不同实现版本,以及多种重采样算法。
•R: DMwR package。
•Weka: SMOTE supervised filter。
4,改变分类算法
①使用代价函数时,可以增加小类样本的权值,降低大类样本的权值(这种方法其实是产生了新的数据分布,即产生了新的数据集),从而使得分类器将重点集中在小类样本身上。刚开始,可以设置每个类别的权值与样本个数比例的倒数,然后可以使用过采样进行调优。
②可以把小类样本作为异常点(outliers),把问题转化为异常点检测问题(anomaly detection)。此时分类器需要学习到大类的决策分界面,即分类器是一个单个类分类器(One Class Classifier)。
③由Robert E. Schapire提出的”The strength of weak learnability”方法,该方法是一个boosting算法,它递归地训练三个弱学习器,然后将这三个弱学习器结合起形成一个强的学习器。算法流程如下:
•首先使用原始数据集训练第一个学习器L1。
•然后使用50%在L1学习正确和50%学习错误的那些样本训练得到学习器L2,即从L1中学习错误的样本集与学习正确的样本集中,循环采样一边一个。
•接着,使用L1与L2不一致的那些样本去训练得到学习器L3。
•最后,使用投票方式作为最后输出。
那么如何使用该算法来解决数据不均衡问题呢? 假设是一个二分类问题,大部分的样本都是true类。
•让L1输出始终为true。
•使用50%在L1分类正确的与50%分类错误的样本训练得到L2,即从L1中学习错误的样本集与学习正确的样本集中,循环采样一边一个。因此,L2的训练样本是平衡的。
•接着使用L1与L2分类不一致的那些样本训练得到L3,即在L2中分类为false的那些样本。
•最后,结合这三个分类器,采用投票的方式来决定分类结果,因此只有当L2与L3都分类为false时,最终结果才为false,否则true。
④以下方法同样会破坏某些类的样本的分布:
•设超大类中样本的个数是极小类中样本个数的L倍,那么在随机梯度下降(SGD,stochastic gradient descent)算法中,每次遇到一个极小类中样本进行训练时,训练L次。
•将大类中样本划分到L个聚类中,然后训练L个分类器,每个分类器使用大类中的一个簇与所有的小类样本进行训练得到。最后对这L个分类器采取少数服从多数对未知类别数据进行分类,如果是连续值(预测),那么采用平均值。
•设小类中有N个样本。将大类聚类成N个簇,然后使用每个簇的中心组成大类中的N个样本,加上小类中所有的样本进行训练。
如果不想破坏样本分布,可以使用全部的训练集采用多种分类方法分别建立分类器而得到多个分类器,投票产生预测结果。
5,尝试其它评价指标
我们已经知道了“准确度(Accuracy)”这个评价指标在数据不均衡的情况下有时是无效的。因此在类别不均衡分类任务中,需要使用更有说服力的评价指标来对分类器进行评价
智能推荐
Python网络爬虫Selenium页面等待:强制等待、隐式等待和显式等待-程序员宅基地
文章浏览阅读749次,点赞5次,收藏17次。不同于显式等待,显式等待针对的是目标元素,而隐式等待针对的是全局的所有的元素。如果设置等待十秒,可以理解为在10秒内不停刷新整个页面,看目标元素是否加载出来。显式等待是单独针对某个元素,表明某个条件成立后才执行获取元素的操作。同上如果时间还没到找到了目标元素,就不再继续等待,程序继续执行。如果时间还没到找到了目标元素,就不再继续等待,程序继续执行。以下面代码为例,即目标标签加载出来出后,开始获取该标签。如果时间到了还没找到目标元素,就报错。如果时间到了还没找到目标元素,就报错。前端开发知识点,真正体系化!
Go + Vercel 实现简易每日早报_vercel go-程序员宅基地
文章浏览阅读845次。使用go语言实现简易的"每日60s读懂世界",项目用Vercel一键部署。_vercel go
在release(发布app)中屏蔽NSLog输出语句_release 屏蔽nslog-程序员宅基地
文章浏览阅读695次。因为NSLog的输出还是比较消耗系统资源的,而且输出的数据也可能会暴露出App里的保密数据,所以发布正式版时需要把这些输出全部屏蔽掉。我们可以在发布版本前先把所有NSLog语句注释掉,等以后要调试时,再取消这些注释,这实在是一件无趣而耗时的事!还好,还有更优雅的解决方法,就是在项目的prefix.pch文件里加入下面一段代码,加入后,NSLog就只在Debug下有输出,Release下不输_release 屏蔽nslog
人大金仓数据库arm64容器镜像构建_goldendb arm64-程序员宅基地
文章浏览阅读2k次。kingbase-arm64 容器镜像用于测试人大金仓数据库容器镜像构建,arm64环境,版本v8r3Buildgit clone https://github.com/toyangdon/kingbase-arm.gitcd kingbase-armdocker build -t kingbase:v8r3 .DeployDockerdocker run -d –name xxxxx -p 54321:54321 -e SYSTEM_PWD=123456 -v /data/xxx: /ho_goldendb arm64
微信小程序登录注册流程(获取手机号)_微信小程序获取用户code 需要用户手动验证吗-程序员宅基地
文章浏览阅读2.1k次。手机号这是采用微信小程序 静默登陆 无需用户手动输入 信息 只需点击按钮进行授权,便可获取到相关信息 进行一个用户的注册和登录其实在这些登录流程中,前端能做的是比较少的,提供一个按钮去触发获取手机号 和用户信息 这里要分 两步授权如果想要获取到用户手机号 和用户信息 这里是隔离操作 相当于 不能一个按钮就完成业务需求是这样的:小程序点进来之后,需要获取手机号,发送到后台,再通过授权获取用户信息(头像和昵称),保存登录态其实对登录态尚存在一些不理解之处 后面再补充// 获取_微信小程序获取用户code 需要用户手动验证吗
idea可以开发python吗_IntelliJ IDEA必备7款Python插件-程序员宅基地
文章浏览阅读3k次。专注Python、AI、大数据,请关注公众号七步编程!提起Python IDE,很多同学首先都会想到PyCharm,毋庸置疑,PyCharm针对Python和Django很好的支持,已经在项目管理方面的强大之处,使得成为一款非常优秀的IDE,也受到很多专业开发人员的青睐。而今天要介绍的是利用与PyCharm出自同一家的Intellij IDEA作为Python开发工具。Intellij IDEA..._有idea还有必要下pycharm吗
随便推点
java.sql.SQLException: ORA-01745: invalid host/bind variable name-程序员宅基地
文章浏览阅读6.3k次。网上的这个错误解决方式如下:SQL语句中字段有关键字,ibatis配置文件中#号写多了,些少了,位置不对,多写个逗号,等等 都有可能出这个错误.该仔细检查SQL语句 比如:insert into tableXX values('TABLESEQ.NEXTVAL',#name:VARCHAR#,#sex:VARCHAR#) 这是正确的。如果写成:insert into tableXX_invalid host/bind variable
神奇的大脑 & 神经网络_人脑与神经网络-程序员宅基地
文章浏览阅读2.1k次。0序让你在操场上溜达几圈,大脑会自然的给出跑在你前面人的性别、年龄、工作等大致信息,当判定此人是你的意中人,大脑会给这个人标上优秀,传递良性信号,你就更不会反感ta。但问题来了,你是如何做出的判断,背影识人术是从哪里进修得到的技能,让你具体说出根据什么判断的还真是一时哑口无言。这时你就奇怪了:对呀,我刚才也没建模型,也没有用逻辑,然后就判断了,还89不离10,这咋回事儿啊? 或许此文读完可以略知一二。了解掌握人脑的作用机理是作为一个有探索欲望的人一生的追求,也是改进提升神经网络的一个极其重要的途径。_人脑与神经网络
Python五角星代码。_python五角星编程代码-程序员宅基地
文章浏览阅读2.6k次,点赞3次,收藏3次。之后,通过turtle.forward(200),turtle.right(144),turtle.forward(200)的命令,海龟依次向前移动200个像素,向右旋转144度,然后再次向前移动200个像素,如此循环四次。这样就完成了五角星的绘制。首先,导入turtle库。之后将画笔的大小为10像素(设置笔画和填充颜色都为红色。),将笔画的颜色设置为红色(),并将背景颜色设置为黑色(_python五角星编程代码
【XR806开发板试用】单总线协议驱动DHT11温湿度传感器-程序员宅基地
文章浏览阅读393次,点赞10次,收藏7次。昨天刚收到极速社区寄来的全志XR806开发板,之前用过很多全志的SOC芯片,但是像这种无线芯片还是第一次用。这次打算使用XR806芯片驱动一下DHT11温湿度传感器。
Java工具类:随机生成userAgent字符串_java 随机生成 user-agent-程序员宅基地
文章浏览阅读16次。用于网络请求中模拟用户代理字符串,已整合Mac电脑及国产浏览器标识。_java 随机生成 user-agent
2022,AIGC元年?-程序员宅基地
文章浏览阅读413次。文|世昕编|石灿2022年12月16日,Science杂志发布了2022年度科学十大突破,韦伯望远镜当选为年度最大科学突破,可谓实至名归。而在其他入选的科学突破中,AIGC也赫然在列。这或许是当下最炙手可热的概念了。无论是火遍全网的AI绘画,还是震惊世人的ChatGPT,都属于AIGC这一概念,即生成式AI。凭借着诸多明星技术、产品的问世,谁也没有想到,在元宇宙、web3等概念叱咤风云的2022年..._2022 元年