CPU的基本知识介绍_cpu系统简介-程序员宅基地
相信大家对CPU一定不陌生了,从小就耳濡目染了,不过想搞清楚CPU的工作原理,并不是一件简单的事情,毕竟迄今为止,CPU的制造仍然是人类科技的巅峰。下面我们以SIT测试为主,简单的介绍下CPU,至于其工作原理,就不在此做详述。
CPU(Central Processing Unit,中央处理器)是一块超大规模的集成电路,通常被称为计算机的大脑,是一台计算机的运算核心(Core)和控制核心( Control Unit),也是整个计算机系统中最重要的组成部件。
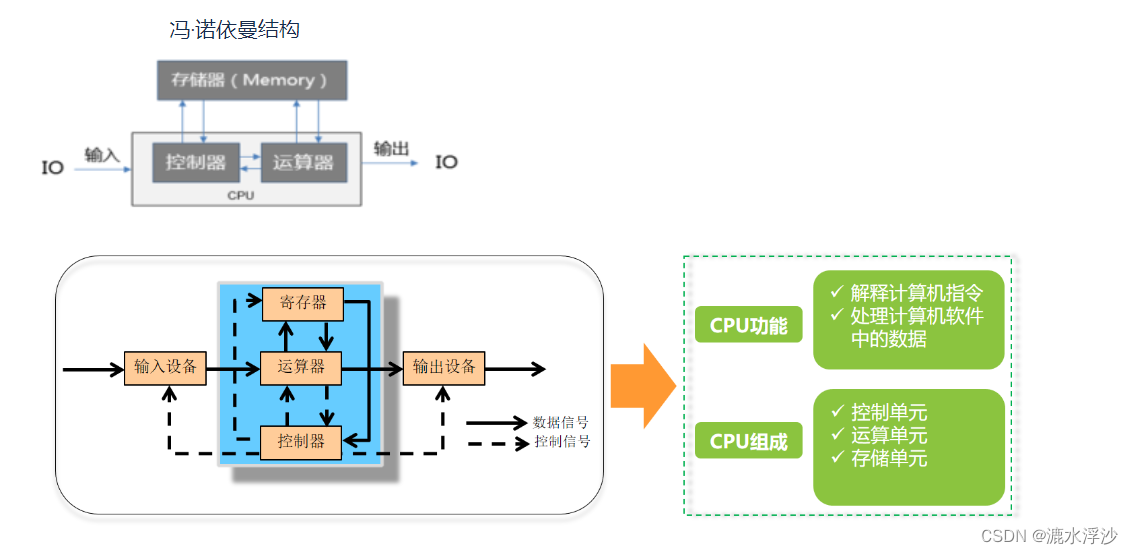
从上图可以看出,CPU在逻辑上由三部分组成。分别是控制单元、运算单元和存储单元,这三部分由CPU内部总线连接起来。如下所示:
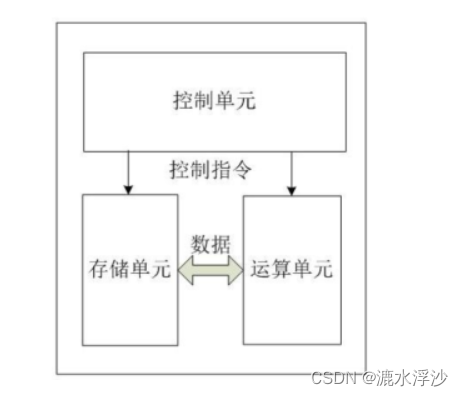
控制单元:控制单元是整个CPU的指挥控制中心,由指令寄存器IR(InstrucTIon Register)、指令译码器ID(InstrucTIon Decoder)和操作控制器OC(OperaTIon Controller)等组成,对协调整个电脑有序工作极为重要。它根据用户预先编好的程序,依次从存储器中取出各条指令,放在指令寄存器IR中,通过指令译码(分析)确定应该进行什么操作,然后通过操作控制器OC,按确定的时序,向相应的部件发出微操作控制信号。操作控制器OC中主要包括节拍脉冲发生器、控制矩阵、时钟脉冲发生器、复位电路和启停电路等控制逻辑。
运算单元:是运算器的核心。可以执行算术运算(包括加减乘数等基本运算及其附加运算)和逻辑运算(包括移位、逻辑测试或两个值比较)。相对控制单元而言,运算器接受控制单元的命令而进行动作,即运算单元所进行的全部操作都是由控制单元发出的控制信号来指挥的,所以它是执行部件。
存储单元:包括CPU片内缓存和寄存器组,是CPU中暂时存放数据的地方,里面保存着那些等待处理的数据,或已经处理过的数据,CPU访问寄存器所用的时间要比访问内存的时间短。采用寄存器,可以减少CPU访问内存的次数,从而提高了CPU的工作速度。但因为受到芯片面积和集成度所限,寄存器组的容量不可能很大。寄存器组可分为专用寄存器和通用寄存器。专用寄存器的作用是固定的,分别寄存相应的数据。
CPU指令执行的过程可以分为5个阶段:取指令、指令译码、执行指令、访存取数、结果写回。
取指令阶段就是将内存中的指令读取到CPU中寄存器的过程,程序寄存器用于存储下一条指令所在的地址;
在取指令完成后,立马进入指令译码阶段,在指令译码阶段,指令编码器按照预先的指令格式,对取回的指令进行拆分和解释,识别区分出不同的指令类别和各种获取操作数的方法;
执行指令阶段的任务是完成指令所规定的各种操作,具体实现指令的功能;
访问取数阶段的任务是:根据指令地址码,得到操作数在主存中的地址,并从主存中读取该操作数用于运算;
结果写回阶段作为最后一个阶段,把执行指令阶段的运行结果数据“写回”到某种存储形式:结果数据经常被写到CPU的内部寄存器中,以便被后续的指令快速地存取。
CPU主要技术参数
1 位,字节和字长
位:在数字电路和电脑技术中采用二进制,代码只有“0”和“1”,代表CPU的“位”。
字节 :8位二进制为一个字节
字长:CPU在单位时间内能一次处理的二进制数的位数叫字长
因此,处理字长为8位数据的CPU通常就叫8位的CPU。同理32位的CPU就能在单位时间内处理字长为32位的二进制数据。
8位的CPU一次只能处理一个字节,而32位的CPU一次就能处理4个字节,同理字长为64位的CPU一次可以处理8个字节。
常见的服务器基本上都是64位的双路CPU
2 主频,外频和倍频
CPU 频率是CPU内部的数字时钟信号频率 。单位时间(即1s)内所产生的脉冲个数称之为频率,频率的标准计量单位是Hz。比如一个CPU每秒可以发送10000个脉冲信号,那么他的频率就是10MHZ。
CPU的主频,即CPU内核工作的主时钟频率,表示在CPU内数字脉冲信号震荡的速度。比如我们平时看到的4.0GHZ、3.0GHZ等指的就是CPU主频,即每秒可以产生40亿、30亿个脉冲信号。
主频=外频×倍频系数
外频通常为系统总线的工作频率,是CPU的基准频率,单位是MHz。外频是CPU与主板之间同步运行的速度,所以也可以说CPU的外频决定着整块主板的运行速度。
自从CPU诞生后,为了追求更高的性能,更快的速度,各大巨头就开始频率大战,虽然主频提升了,但外部芯片组还是旧有的运行频率,且远低于CPU主频。比如CPU的主频是10GHZ,网卡只有1GHZ,那么CPU就好比飞机带一个自行车跑,根本带不起来。那如何解决呢?外频和倍频应运而生。
倍频是指CPU主频与外频之间的相对比例关系,主频=外频*倍频
以前没有倍频概念,外频(系统总线频率)就相当于CPU的主频,两者速度一样。随着CPU的速度越来越快,倍频技术也就随之出现。即使外频(系统总线频率)工作速度相对较低,CPU速度仍然可以通过倍频来提升。
但由于CPU与系统之间数据传输速度有限,如果一味追求高倍频CPU会出现明显的瓶颈效应,即CPU从系统中得到数据的极限速度不能够满足CPU运算的速度。所以一般Intel的CPU都锁了倍频(工程样板可能除外),AMD之前也因为不锁倍频而很受电脑发烧友的追捧。
现在CPU频率越来高,从 2.4GHz、3.0GHz 到 4.0GHz,大家很容易产生 CPU 频率越高,速度越快的想法。
严谨来说,主频和实际的运算速度存在一定的关系,并不直接代表运算速度,但提高主频对于提高CPU运算速度却是至关重要的。
在同一时钟周期内,CPU执行一条运算指令,200Mhz主频应该要比100Mhz的主频快一倍,但除了CPU内核的工作频率,CPU的运算速度还要看CPU的流水线(如缓存、指令集、CPU位数等)各方面的性能指标,所以大家好才是真的好,不能只看CPU主频。
3 前端总线(FSB)频率
前端总线(Front Side Bus)频率:CPU就是通过前端总线连接到北桥芯片,进而通过北桥芯片和内存、显卡交换数据。前端总线是CPU和外界交换数据的最主要通道,因此前端总线的数据传输能力对计算机整体性能作用很大,如果没足够快的前端总线,再强的CPU也不能明显提高计算机整体速度。
前段总线频率直接影响CPU与内存直接数据交换速度。有一条公式:
数据带宽=(总线频率*数据位宽)/8
数据传输最大带宽取决于所有同时传输的数据的宽度和传输频率。比如,现在的支持64位的至强处理器,前端总线是800MHz,按照公式,它的数据传输最大带宽是6.4GB/秒。
外频与前端总线(FSB)频率的区别
前端总线的速度指的是数据传输的速度,外频是CPU与主板之间同步运行的速度。
也就是说,100MHz外频特指数字脉冲信号在每秒钟震荡一千万次;而100MHz前端总线指的是每秒钟CPU可接受的数据传输量是100MHz*64bit÷8Byte/bit=800MB/s。
4 缓存 Cache
CPU缓存(Cache Memory)是位于CPU与内存之间的临时存储器,它的容量比内存小的多但是交换速度却比内存要快得多。CPU高速缓存的出现主要是为了解决CPU运算速度与内存读写速度不匹配的矛盾,因为CPU运算速度要比内存读写速度快很多,这样会使CPU花费很长时间等待数据到来或把数据写入内存。在缓存中的数据是内存中的一小部分,但这一小部分是短时间内CPU即将访问的,当CPU调用大量数据时,就可先缓存中调用,从而加快读取速度。
当CPU需要读取数据并进行计算时,首先需要将CPU缓存中查到所需的数据,并在最短的时间下交付给CPU。如果没有查到所需的数据,CPU就会提出“要求”经过缓存从内存中读取,再原路返回至CPU进行计算。而同时,把这个数据所在的数据也调入缓存,可以使得以后对整块数据的读取都从缓存中进行,不必再调用内存。
缓存大小是CPU的重要指标之一,而且缓存的结构和大小对CPU速度的影响非常大,CPU内缓存的运行频率极高,一般是和处理器同频运作,工作效率远远大于系统内存和硬盘。实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是从CPU芯片面积和成本的因素来考虑,缓存都很小。
L1 Cache(一级缓存)是CPU第一层高速缓存,分为数据缓存和指令缓存。
内置的L1高速缓存的容量和结构对CPU的性能影响较大,L1级高速缓存的容量不可能做得太大。一般服务器CPU的L1缓存的容量通常在32—256KB。
L2 Cache(二级缓存)是CPU的第二层高速缓存,分内部和外部两种芯片。
内部的芯片二级缓存运行速度与主频相同,而外部的二级缓存则只有主频的一半。L2高速缓存容量也会影响CPU的性能,原则是越大越好,服务器和工作站上用CPU的L2高速缓存更高达256-1MB,有的高达2MB或者3MB。
L3 Cache(三级缓存),分为两种,早期的是外置,现在的都是内置的。
而它的实际作用即是,L3缓存的应用可以进一步降低内存延迟,同时提升大数据量计算时处理器的性能。降低内存延迟和提升大数据量计算能力对游戏都很有帮助。而在服务器领域增加L3缓存在性能方面仍然有显著的提升。
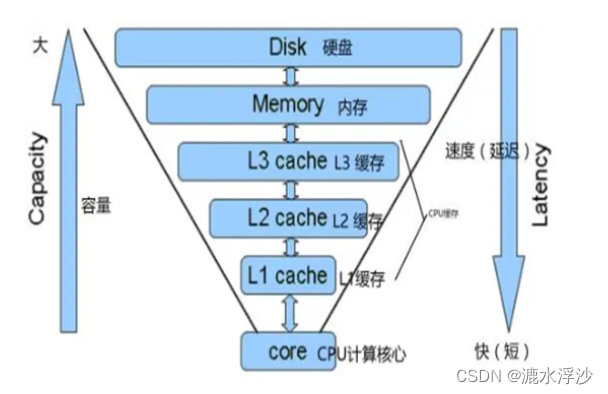
示例如下图:
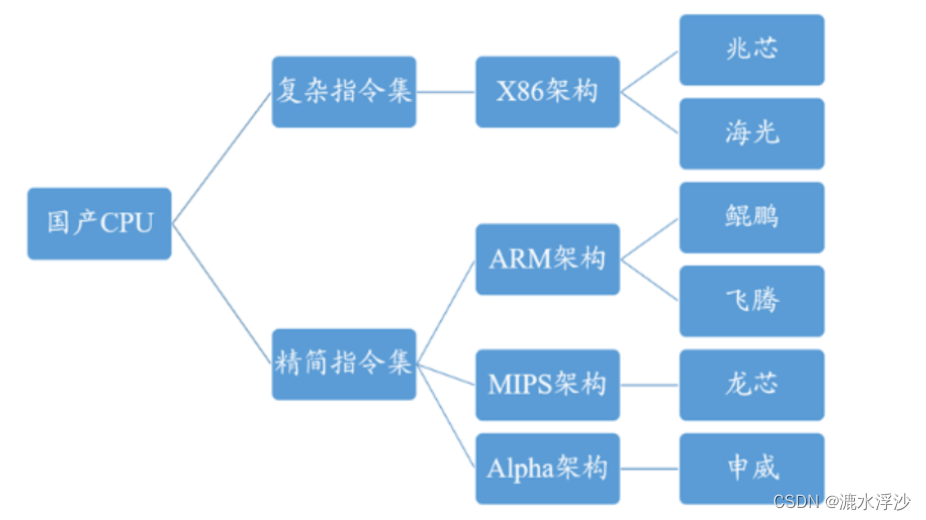
CPU的分类
CPU如果按照指令集分类的话,可以分为复杂指令集和精简指令集
CISC(complex instruction set computer),复杂指令集。早期的CPU全部是CISC架构,它的设计目的是要用最少的机器语言指令来完成所需的计算任务。这种架构会增加CPU结构的复杂性和对CPU工艺的要求,但对于编译器的开发十分有利。比如Intel和AMD的X86架构的CPU以及AMD授权的曙光研发的海光系列CPU。
RISC(Reduced Instruction Set Computer),精简指令集。RISC架构要求软件来指定各个操作步骤。这种架构可以降低CPU的复杂性以及允许在同样的工艺水平下生产出功能更强大的CPU,但对于编译器的设计有更高的要求。比如授权于ARM公司的华为鲲鹏系列的CPU。

我们在测试的时候遇到最多的就是X86和ARM的CPU,不过百分之90都是Intel和AMD,随着国产CPU的崛起,后面很有可能会遇见更多的国产CPU
智能推荐
Android实现部分文字可点击及变色_spannablestring clickspan 变色-程序员宅基地
文章浏览阅读1.4k次。可以使用SpannableString和ClickableSpan: TextView userAgreement = findViewById(R.id.user_agreement); SpannableString agreement = new SpannableString("Agree to the User Agreement and Privac..._spannablestring clickspan 变色
ollvm的ida trace操作笔记_ida trace 脚本-程序员宅基地
文章浏览阅读1.6k次。1.启动顺序操作记录1.把android_server push到手机里2.chmod 777 android_server3.adbforward tcp:11678 tcp:116784.ida->debugger->attach->arm-androddebugger5.再按f9把程序跑起来6.file->script_file->选择script.py加载ida脚本,成功后会有日志7.然后点击Debugger->breaklist里可以看到我们的断_ida trace 脚本
Mac M1 搭建 React Native 环境_mac 配置 react native 的打包环境-程序员宅基地
文章浏览阅读3.4k次。Mac M1 搭建 React Native 环境环境安装可以参考对照官方文档,本文针对M1芯片目前未完全适配情况下的方案,算是临时解决方案,不具有时效性。你需要自行准备的依赖:Xcode >10、Node >v12、Npm、Yarn、ruby、git更改编译环境首先要做的是进入 访达>应用程序>实用工具>右键 终端.app 显示简介>使用Rosetta打开勾选这一点极其重要,如果你使用的为其他终端工具,请勾选此选项,有关ffi的兼容问题,这只是临时解决方案_mac 配置 react native 的打包环境
SE壳C#程序-CrackMe-爆破 By:凉游浅笔深画眉 / Net7Cracker-程序员宅基地
文章浏览阅读644次。【文章标题】: 【SE壳C#程序-CrackMe-爆破】文字视频记录!【文章作者】: 凉游浅笔深画眉【软件名称】: CM区好冷清,我来发一个吧!小小草莓【下载地址】: http://www.52pojie.cn/thread-243089-1-1.html【加壳方式】: SE壳【使用工具】: OD+WinHex+CFF Explorer【作者声明】: 只是感兴趣,没有其他目的。失误之处敬请诸位大..._凉游浅笔画深眉是啥
安卓ttf格式的字体包_锤子科技定制字体 | Smartisan T黑-程序员宅基地
文章浏览阅读2k次。Smartisan·T黑2019年10月31日19:30分在北京工业大学奥林匹克体育馆举行的坚果手机2019新品发布会上,Smartisan OS产品经理朱海舟正式发布了Smartisan OS 7.0。随着全新的Smartisan OS 7.0一同亮相的还有锤子科技向方正字库订制的系统UI字体:Smartisan T黑(锤子T黑)。锤子T黑有着几乎完美的特质:灰度均衡、重心统一、中宫内..._smartisan t黑
Java中extends与implements使用方法_implements在java中的格式-程序员宅基地
文章浏览阅读4.8k次,点赞4次,收藏6次。一.extends关键字 extends是实现(单)继承(一个类)的关键字,通过使用extends 来显式地指明当前类继承的父类。只要那个类不是声明为final或者那个类定义为abstract的就能继承。其基本声明格式如下: [修饰符] class 子类名 extends 父类名{ 类体 }_implements在java中的格式
随便推点
r语言c1,R语言之主成分分析-程序员宅基地
文章浏览阅读568次。主成分分析R软件实现程序(一):>d=read.table("clipboard",header=T)#从剪贴板读取数据>sd=scale(d)#对数据进行标准化处理>sd#输出标准化后的数据和属性信息,把标准化的数据拷贝到剪贴板备用>d=read.table("clipboard",header=T)#从剪贴板读取标准化数据>pca=princomp(d,co..._r语言dcor什么意思
webGl学习-程序员宅基地
文章浏览阅读127次。开个新坑,不知道能不能做完学习地址:mdn地址浏览器支持范围:支持范围首先是创建一个容器,与canvas的canvas.getContext('2d')相似let canvas = document.getElementById('myCanvas');let gl = canvas.getContext('webgl');_webgl学习
基于大数据的音乐推荐系统的设计与实现-程序员宅基地
文章浏览阅读1.7w次,点赞20次,收藏328次。系统提供的功能有,音乐管理:管理员可以添加删除音乐,音乐查找:用户可以在系统中自行查找想要听的歌曲,音乐推荐:系统在收集了用户的行为数据之后为用户个性化推荐音乐,用户管理:管理员可以对用户进行删除,评论管理:管理员可以对评论进行删除,音乐下载:用户可以自行下载个人喜欢分歌曲。选择数据源要确定数据源数据是否可靠真实,要避免爬取音乐平台发布的虚伪的音乐数据,如不存在的歌唱家、专辑、音乐等。通过分析基于大数据的音乐推荐系统,即音乐推荐需要哪些数据,详细了解推荐机制,搞清楚这些数据需要被处理为什么格式。_基于大数据的音乐推荐系统的设计与实现
Nginx反向代理缓存服务器搭建-程序员宅基地
文章浏览阅读672次。Nginx反向代理代理服务可简单的分为正向代理和反向代理:正向代理: 用于代理内部网络对Internet的连接请求(如×××/NAT),客户端指定代理服务器,并将本来要直接发送给目标Web服务器的HTTP请求先发送到代理服务器上, 然后由代理服务器去访问Web服务器,并将Web服务器的Response回传给客户端:反向代理: 与正向代理相反,如果局域网向Internet提供..._o /usr/local/server/ngx_cache_purge-2.3/config was found error: failed to ru
layui用table.render加载数据 用table.reload重载里面的数据---解决table.render重新加载闪动的问题_layui table.reload 闪退-程序员宅基地
文章浏览阅读2.7w次,点赞4次,收藏30次。今天在用layui 展示数据的时候,首先想到了table.render这个插件进行数据的展示,因为数据要实时刷新,说到实时刷新,你最低要三秒刷新一次表格的数据吧!!!一开始写了个定时把table.render放到定时函数里面,三秒执行一次函数,那么问题来了,虽然效果是实现了,但这是重新加载表格啊,三秒闪一次,别说是用户了,我都看不下去了,闪的眼疼,就想有没有只让数据重新加载,表格不动。终于功夫不负..._layui table.reload 闪退
Ubuntu系统突然进不去了_ubuntu开机无法进入系统-程序员宅基地
文章浏览阅读8.7k次,点赞5次,收藏37次。ubuntu系统突然进不去了!怎么办?_ubuntu开机无法进入系统